ブログに戻ります

Scrapelessとn8nワークフローを使って不動産リスティングのスクレイピングを自動化する
Emily Chen
Advanced Data Extraction Specialist
11-Jul-2025
不動産業界では、最新の物件リストをスクレイピングし、分析のために構造化された形式で保存するプロセスを自動化することが効率を向上させる鍵となります。本記事では、低コード自動化プラットフォームn8nとウェブスクレイピングサービスScrapelessを使って、LoopNet不動産ウェブサイトから定期的に賃貸リストをスクレイピングし、構造化された物件データをGoogle Sheetsに自動的に書き込む方法についての手順を説明します。
1. ワークフローの目標とアーキテクチャ
目標:商業不動産プラットフォーム(例:Crexi / LoopNet)から最新の販売/賃貸リストを毎週自動的に取得する。
アンチスクレイピングメカニズムを回避し、データをGoogle Sheetsに構造化された形式で保存して、報告やBIビジュアライゼーションを容易にする。
最終ワークフローアーキテクチャ:
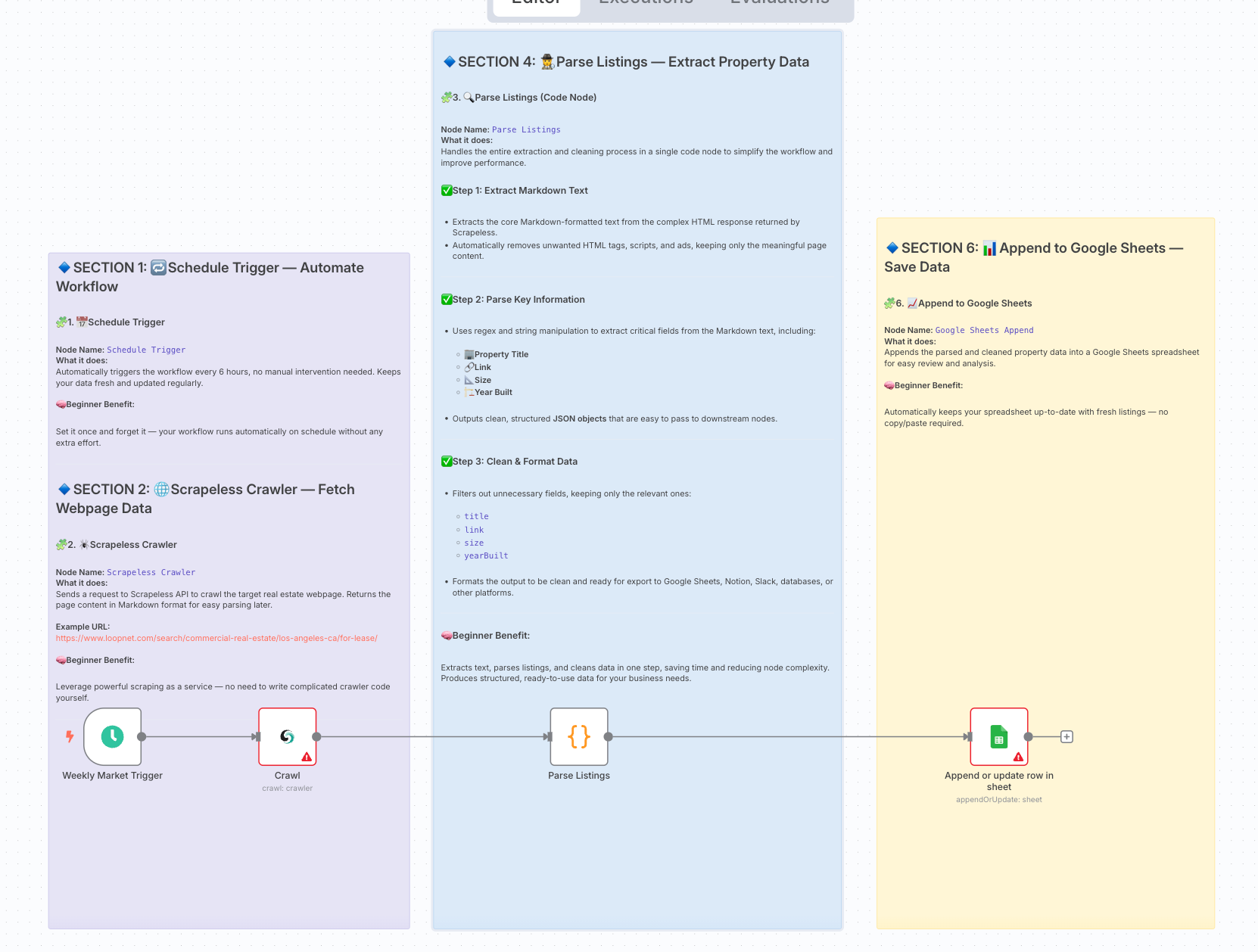
2. 準備
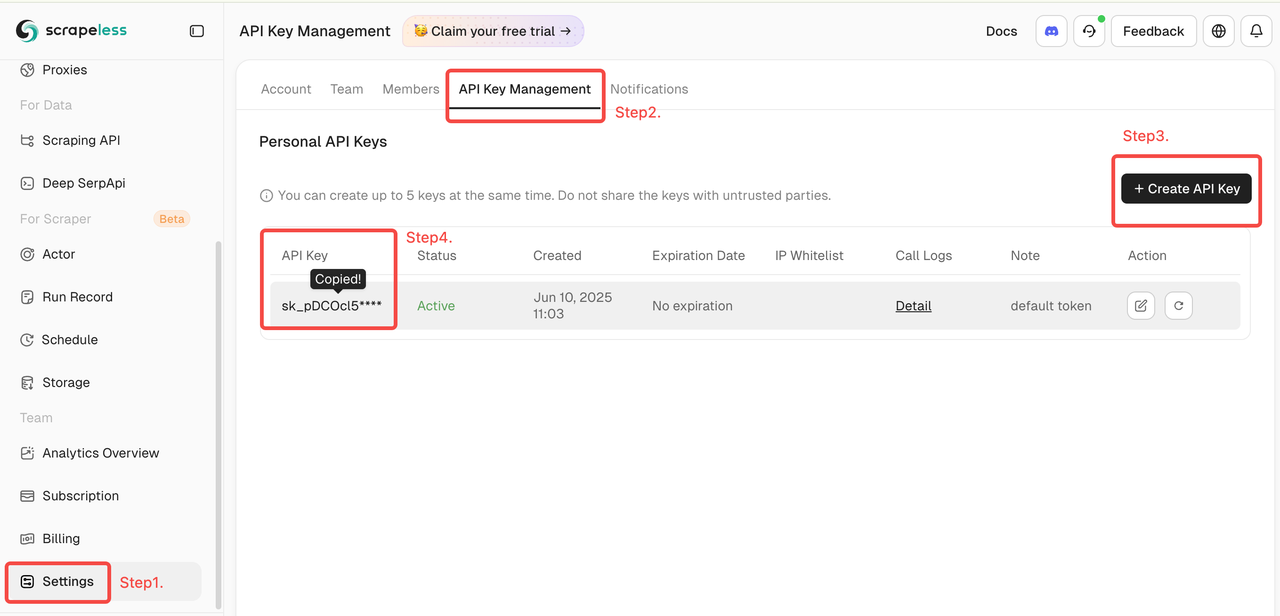
- Scrapeless公式ウェブサイトでアカウントにサインアップし、APIキーを取得する(1ヶ月に2,000件の無料リクエスト)。
- Scrapelessダッシュボードにログイン
- 次に、左側の「設定」をクリック -> 「APIキー管理」を選択 -> 「APIキーを作成」をクリックします。最後に、作成したAPIキーをクリックしてコピーします。
- n8nにScrapelessノードのコミュニティ版がインストールされていることを確認します。
- 記入可能な権限を持つGoogle Sheetsドキュメントと対応するAPI資格情報。
3. ワークフローステップの概要
| ステップ | ノードタイプ | 目的 |
|---|---|---|
| 1 | スケジュールトリガー | 6時間ごとにワークフローを自動的にトリガーします。 |
| 2 | Scrapelessクローラー | LoopNetページをスクレイピングし、取得したコンテンツをマークダウン形式で返します。 |
| 4 | コードノード(リストの解析) | Scrapelessの出力からマークダウンフィールドを抽出し、正規表現を使用してマークダウンを解析し、構造化された物件リストデータを抽出します。 |
| 6 | Google Sheets追加 | 構造化された物件データをGoogle Sheetsドキュメントに書き込みます。 |
4. 詳細な設定とコード説明
1. スケジュールトリガー
- ノードタイプ: スケジュールトリガー
- 設定: インターバルを週次に設定(必要に応じて調整)。
- 目的: スケジュールに従って自動的にスクレイピングワークフローをトリガーし、手動操作は不要です。
2. Scrapelessクローラーノード
- ノードタイプ: Scrapeless APIノード(
crawler - crawl) - 設定:
- URL: 対象のLoopNetページ、例:
https://www.loopnet.com/search/commercial-real-estate/los-angeles-ca/for-lease/ - APIキー: 自分のScrapeless APIキーを入力します。
- ページ制限: 2(必要に応じて調整)。
- URL: 対象のLoopNetページ、例:
- 目的: ページコンテンツを自動的にスクレイピングし、ウェブページをマークダウン形式で出力します。

3. リストの解析
- 目的: Scrapelessによってスクレイピングされたマークダウン形式のウェブページコンテンツから主要な商業不動産データを抽出し、構造化されたデータリストを生成します。
- コード:
const markdownData = [];
$input.all().forEach((item) => {
item.json.forEach((c) => {
markdownData.push(c.markdown);
});
});
const results = [];
function dataExtact(md) {
const re = /\[More details for ([^\]]+)\]\((https:\/\/www\.loopnet\.com\/Listing\/[^\)]+)\)/g;
let match;
while ((match = re.exec(md))) {
const title = match[1].trim();
const link = match[2].trim()?.split(' ')[0];
// マッチ周辺のコンテキストを抽出
const context = md.slice(match.index, match.index + 500);
// サイズ範囲を抽出、例: "10,000 - 20,000 SF"
const sizeMatch = context.match(/([\d,]+)\s*-\s*([\d,]+)\s*SF/);
const sizeRange = sizeMatch ? `${sizeMatch[1]} - ${sizeMatch[2]} SF` : null;
// 建築年を抽出、例: "Built in 1988"
const yearMatch = context.match(/Built in\s*(\d{4})/i);
const yearBuilt = yearMatch ? yearMatch[1] : null;
// 画像URLを抽出
ja
const imageMatch = context.match(/!\[[^\]]*\]\((https:\/\/images1\.loopnet\.com[^\)]+)\)/);
const image = imageMatch ? imageMatch[1] : null;
results.push({
json: {
title,
link,
size: sizeRange,
yearBuilt,
image,
},
});
// マッチが見つからない場合は、元のMarkdownを返す(デバッグ用)
if (results.length === 0) {
return [
{
json: {
error: '一致するリストがありません',
raw: md,
},
},
];
}
markdownData.forEach((item) => {
dataExtact(item);
});
return results;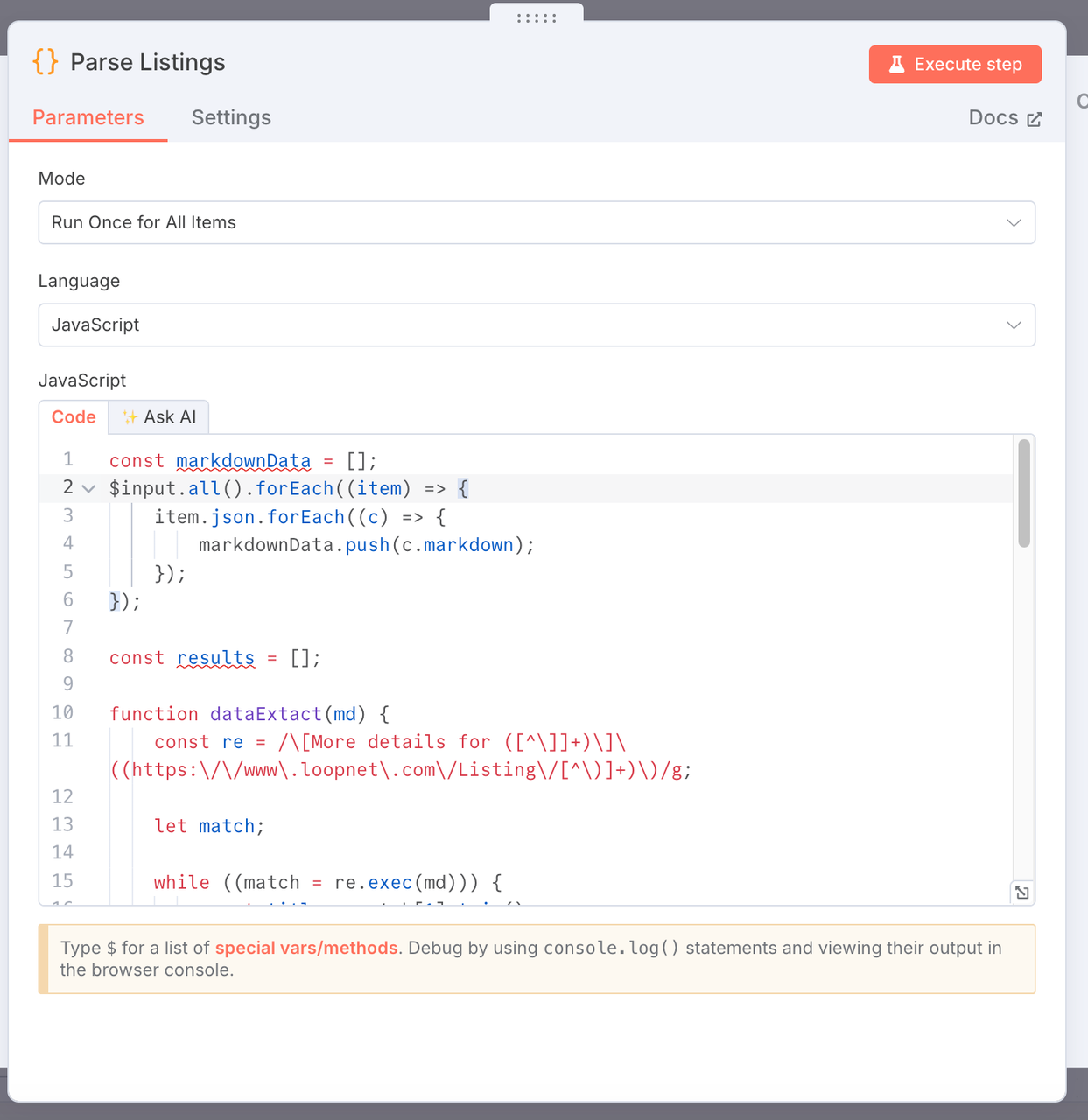
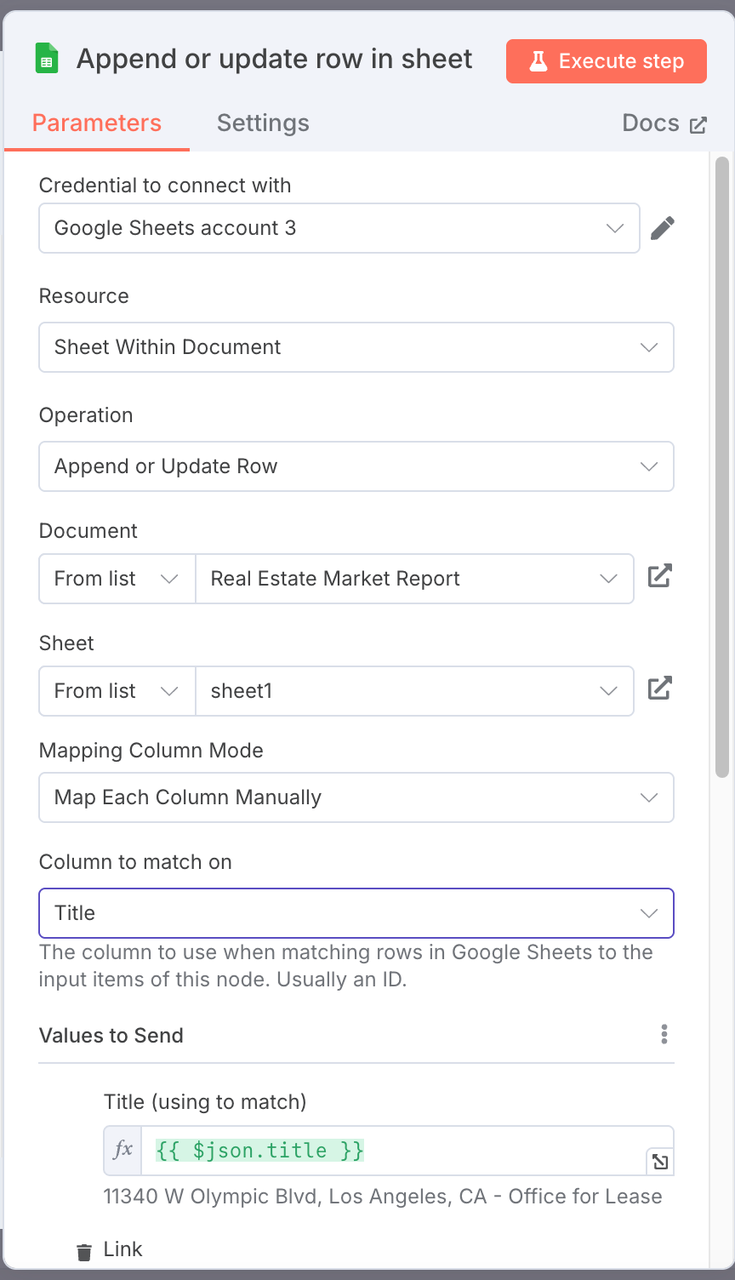
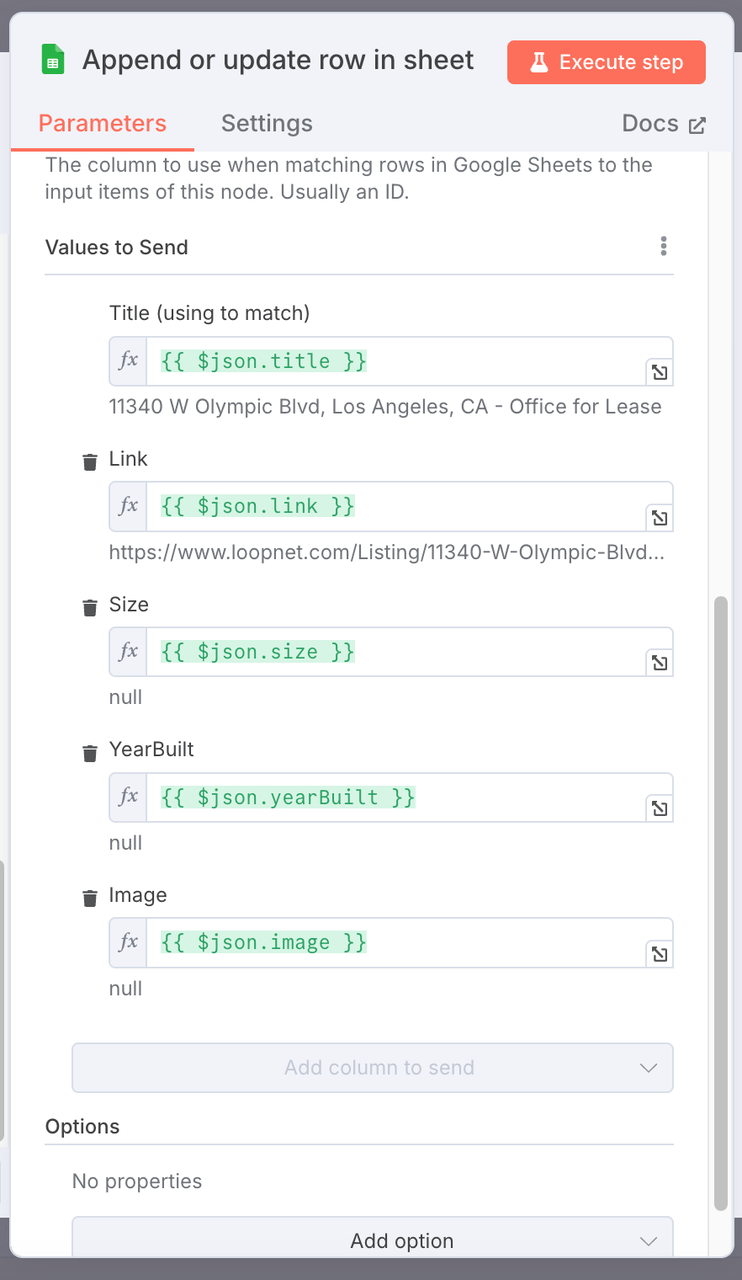
4. Google Sheets 追加(Google Sheetsノード)
- 操作: 追加
- 設定:
- 対象のGoogle Sheetsファイルを選択します。
- シート名: 例えば、
不動産市場レポート。 - 列マッピング設定: 構造化されたプロパティデータフィールドをシートの対応する列にマッピングします。
| Google Sheets列 | マッピングされたJSONフィールド |
|---|---|
| タイトル | {{ $json.title }} |
| リンク | {{ $json.link }} |
| サイズ | {{ $json.size }} |
| 年築 | {{ $json.yearBuilt }} |
| 画像 | {{ $json.image }} |
注:
ワークシート名は私たちのものと一致させることをお勧めします。特定の名前を変更する必要がある場合、マッピング関係に注意を払う必要があります。
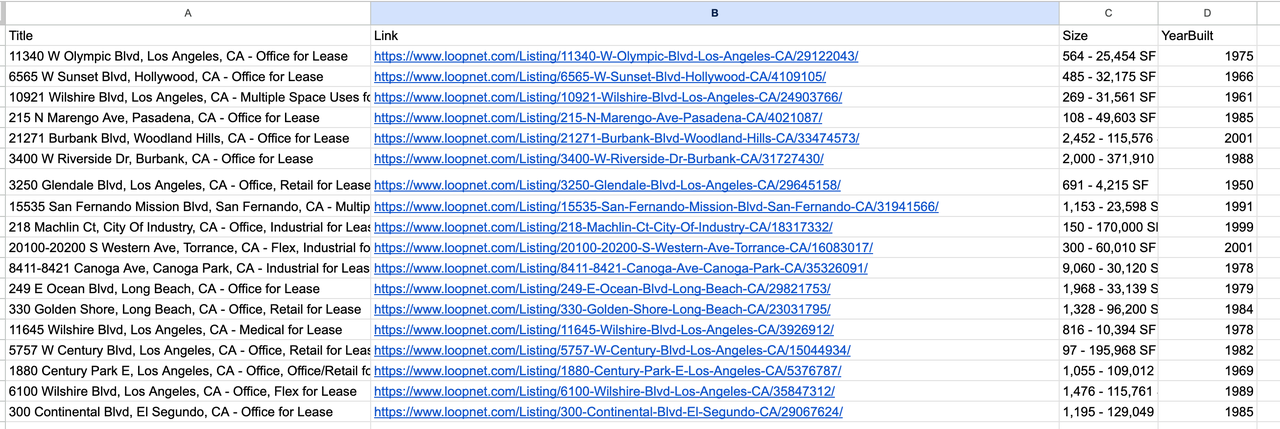
5. 結果出力
5. ワークフローフローチャート

6. デバッグのヒント
- 各 コードノードを実行するときは、ノード出力を開いて抽出されたデータフォーマットを確認してください。
- リスティングの解析ノードがデータを返さない場合は、Scrapelessの出力に有効なMarkdownコンテンツが含まれているか確認してください。
- 出力フォーマットノードは、出力をクリーンアップおよび標準化し、正しいフィールドマッピングを保証するために主に使用されます。
- Google Sheets追加ノードを接続する際は、OAuth認証が正しく設定されていることを確認してください。
7. 将来の最適化
- 重複排除: 重複プロパティリストの書き込みを避ける。
- 価格またはサイズによるフィルタリング: 特定のリスティングをターゲットにするフィルターを追加。
- 新しいリスティング通知: メールやSlackなどでアラートを送信。
- 複数都市および複数ページの自動化: 異なる都市やページにわたるスクレイピングを自動化。
- データの視覚化と報告: 構造化データからダッシュボードを作成し、レポートを生成。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。
最も人気のある記事



カタログ