
ウェブスクレイピング中に CAPTCHA を回避する 7 つの方法
Web Data Collection Specialist
ウェブサイトをスクレイピングしようとしているのに、CAPTCHA がブロックしていますか? ウェブ スクレイピングの取り組みは、CAPTCHA によって妨げられる可能性があります。CAPTCHA は解読がますます難しくなっています。
ありがたいことに、ウェブ スクレイピング時に CAPTCHA を回避する方法がいくつかあり、この記事では 7 つの実証済みの方法について説明します。
CAPTCHA: とは?
CAPTCHA は、「コンピューターと人間を区別するための完全に自動化された公開チューリング テスト」の略です。ウェブサイトを損害やスクレイピングなどのボットのような動作から保護するために、自動化されたプログラムがウェブサイトにアクセスするのをブロックしようとします。保護された Web サイトにアクセスする前に、ユーザーは CAPTCHA と呼ばれるテストを完了しなければならないことがよくあります。
Web スクレイパーは CAPTCHA を回避するのが困難です。ロボットには理解しにくいものの、人間には簡単に克服できるからです。ユーザーは、たとえば下の画像のボックスをチェックして、自分が人間であることを確認する必要があります。このコマンドは、ボットが直感的に実行できるものではありません。
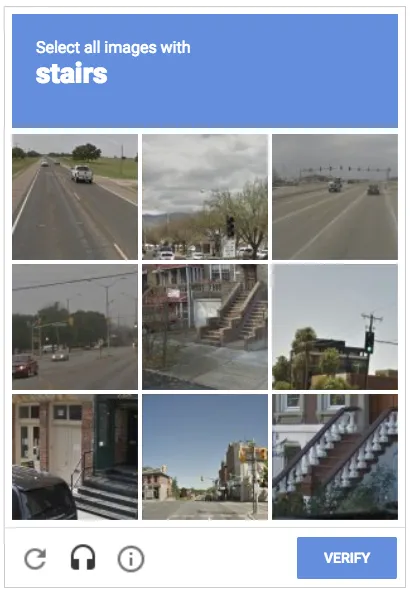
Web スクレイピングは CAPTCHA によってどのようにブロックされるのか?
Web サイトの実装によって、CAPTCHA の形状が決まります。Web サイトにアクセスしたときに常に表示されるものもありますが、ほとんどは Web スクレイピングなどの自動アクションの結果です。
CAPTCHA は、以下のいずれかの理由で Web スクレイピング中に表示されることがあります:
- 同じ IP から短時間に複数のクエリを送信する
- 同じリンクをクリックしたり、同じページにアクセスしたりするなど、自動化されたアクションが繰り返される
- 疑わしい自動化されたインタラクション (インタラクションなしで多くのページをすばやく閲覧する、すばやくクリックする、フォームをすばやく完了するなど)
- 禁止されている Web サイトを使用し、robots.txt ファイルを無視する。
CAPTCHA をバイパスすることは可能ですか?
簡単な操作ではありませんが、CAPTCHA をバイパスすることもできます。CAPTCHA がブロックされている場合は、リクエストを再送信して、そもそも CAPTCHA が表示されないようにすることをお勧めします。
CAPTCHA に回答することもできますが、その場合、コストがかなりかかり、成功率も大幅に低くなります。ほとんどの CAPTCHA 解決サービスでは、人間のソルバーを使用してクエリを処理し、回答を提供します。この方法は、スクレイパーの有効性を大幅に低下させ、速度を低下させます。
CAPTCHA をバイパスすると、CAPTCHA の原因となる自動動作を停止するために必要なすべての予防措置を講じるため、より信頼性が高まります。以下では、Web スクレイピング時に CAPTCHA を回避するための最良の方法について説明し、必要な情報を取得できるようにします。
Web スクレイピング時に CAPTCHA をバイパスする方法
このセクションでは、Python で Web スクレイピング中に煩わしい CAPTCHA バリアを回避する 7 つの方法について説明します。
方法 1. IP をローテーションする
URL およびデータ抽出用のクローラーを開発する際に、防御システムがアクセスを停止するための最も簡単な方法は、IP を禁止することです。サーバーが短期間に同じ IP アドレスから多数のリクエストを受信すると、そのアドレスにフラグが付けられます。
これを回避するには、複数の IP アドレスを使用するのが最も簡単な解決策です。ただし、サーバーに関しては、それを変更するのは困難、または不可能です。したがって、IP を循環させるには、プロキシ サーバーを使用してリクエストを処理する必要があります。これらを使用すると、最初のリクエストは変更されませんが、宛先サーバーはあなたの IP アドレスではなく、宛先サーバーの IP アドレスを認識します。
方法 2. ユーザー エージェントをローテーションする
ユーザーの Web ブラウザーがサーバーに送信する文字列は、ユーザー エージェント (UA) と呼ばれます。これは HTTP ヘッダーにあり、オペレーティング システム、ブラウザーの種類とバージョンに関する情報を提供します。クライアント側のナビゲータと JavaScript を使用してアクセスします。コンテンツは、userAgent 属性を使用して、リモート Web サーバーによって識別され、ユーザーの仕様に準拠した方法でレンダリングされます。
さまざまな構造とデータが含まれていますが、ほとんどの Web ブラウザーは通常、同じ形式に従います:
(<system-information>) Mozilla/5.0 <extensions> <platform> (<platform-details>)
たとえば、Chrome (Chromium) の場合、ユーザー エージェント文字列は Mozilla/5.0 (Windows NT 10.0; Win64; x64) になります。 AppleWebKit/537.36 (KHTML の Gecko に類似) 109.0.0.0 Safari/537.36; Chrome。詳しくは、ブラウザの名前 (Chrome)、実行されているバージョン (109.0.0.0)、実行されているオペレーティング システム (Windows NT 10.0、64 ビット CPU) が示されています。
スクレイピングに UA 文字列を使用すると、Web サーバーがブラウザ (およびボット) からのリクエストの種類を識別するのに役立つため、スパイダーを Web ブラウザとして偽装するのに役立ちます。
注意: 正しく構成されていないユーザー エージェントを使用すると、データ抽出スクリプトが停止します。
方法 3. CAPTCHA ソルバーを使用する
CAPTCHA ソルバーと呼ばれるサービスを使用すると、CAPTCHA を自動的に解決して Web ページを継続的にスクレイピングできます。よく知られている例の 1 つに Scrapeless があります。
CAPTCHA や継続的な Web スクレイピング ブロックにうんざりしていませんか?
Scrapeless: 最高のオールインワン オンライン スクレイピング ソリューション!
データ抽出の可能性を最大限に引き出すために、当社の強力なツールキットをご利用ください:
最高の CAPTCHA ソルバー
複雑な CAPTCHA を自動的に解決し、継続的でスムーズなスクレイピングを実現します。
無料でお試しください!
方法 4. 隠れた罠を避ける
知らないうちに、Web サイトはボットを識別するために巧妙な罠を仕掛けています。たとえば、ハニーポット トラップは、リンクや非表示のフォーム フィールドなどの隠れた機能とやり取りするように機械を騙します。
人間のユーザーにはこれらの罠は見えません。ボットだけが見ることができます。ユーザーがこれらの罠とやり取りすると、Web サイトは異常なアクティビティを識別し、ボットの IP アドレスに警告することができます。
ただし、これらの罠を認識して操作する方法を学ぶことはできます。1 つの方法は、Web サイトの HTML で非表示の要素を探し、奇妙な名前や値を持つ要素を避けることです。
方法 5. 人間の行動をシミュレートする
Web スクレイピング時に CAPTCHA を回避するには、人間の行動を正確に再現する必要があります。たとえば、数ミリ秒以内に複数のリクエストを送信すると、レート制限のある IP 制限が発生する可能性があります。
リクエスト間に時間を追加してクエリの頻度を下げることは、人間の行動を模倣する 1 つの方法です。より論理的にするには、タイミングを変えることができます。指数バックオフを使用することは、失敗したリクエストの後の待機期間を長くするための追加の戦略です。
方法 6. Cookie を保存する
Web スクレイピングに最適な隠れた武器は、Cookie かもしれません。これらの小さなファイルには、設定やログイン ステータスなど、Web サイトとのやり取りに関する情報が保持されます。
ログイン後にスクレイピングを行う場合、Cookie は繰り返しサインインする手間を省き、発見される可能性を低くするため役立ちます。さらに、Cookie を使用すると、後で Web スクレイピング セッションを一時停止したり、続行したりできます。
Selenium などのヘッドレス ブラウザーや Requests などの HTTP クライアントを使用すると、プログラムで Cookie を保存および読み込み、気付かれずにデータを取得できます。
方法 7. 自動化インジケーターを非表示にする
ヘッドレス ブラウザーを使用している場合でも、Web サイトはブラウザーのフィンガープリントなどの自動化の兆候をスキャンして自動化トラフィックを検出できるため、注意が必要です。
一方、Selenium Stealth などのプラグインを使用すると、人の動きに似たマウスとキーボードの動きを自動化し、注意を引かないようにすることができます。
まとめ
CAPTCHA が Web スクレイピングを妨害するのを防ぐのは難しい作業ですが、これでこの問題に取り組むために必要なツールを手に入れました。ただし、大規模な取り組みでは、前述の戦略を完全に実行するには、より多くの時間と作業が必要になる場合があります。
Scrapeless を使用すると、CAPTCHA やその他のアンチボットを効率的に回避するために必要なすべてのツールを入手できます。
Scrapeless を無料で使用して、実際にご確認ください。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


