
MCP-RAG サーバー: 完全な設定と使用ガイド
Advanced Data Extraction Specialist
急速に進化するAIアプリケーションの時代において、静的なドメイン知識とリアルタイムのウェブ情報を組み合わせることができるシステムの必要性はかつてないほど高まっています。従来の情報取得を強化した生成(RAG)モデルは、しばしば事前にインデックスされたデータに依存しており、新しい開発への応答性が制限されています。MCP-RAGサーバーは、意味ベクトル検索(Qdrantを使用)とリアルタイムウェブ検索機能(Scrapelessを使用)を統合することで、このギャップを埋め、インテリジェントな質問応答システムのための生産準備が整った基盤を提供します。企業が内部知識エージェントを構築する場合でも、LLM統合を試みる開発者である場合でも、このガイドはMCP-RAGの完全なセットアップと使用方法を案内し、最新の応答性の高いAI知識システムを展開するための準備が整っていることを保証します。
MCP-RAGサーバーとは?
MCP-RAGサーバーは、タイプスクリプトに基づくシステムで、ベクトル検索機能とリアルタイムウェブ検索を組み合わせて、強化されたAI知識システムを作成します。3つの主要なツールを提供します:
- 機械学習FAQ取得 - ベクトルデータベースを通じた意味検索
- ドキュメント追加 - 新しい情報で知識ベースを拡張
- ウェブ検索 - インターネットからの最新情報を取得
このシステムは、時代遅れの知識、ドメイン専門知識の欠如、非効率的な情報取得といったAIの重要な制限を解決します。
Scrapeless紹介:RAGのウェブインテリジェントエンハンスメントエンジン
Scrapeless Google Search Scraping APIは、従来のクローラーによるブロックのリスクなしに、検索エンジン結果への安定したアクセスを提供する強力なウェブスクレイピングAPIです。
ScrapelessがRAGシステムにとって不可欠な理由
従来のRAGシステムは、静的な知識ベースによって制限されています。Scrapelessは、MCP-RAGサーバーを次のように変革します:
- リアルタイム情報取得:ウェブから最新情報にアクセス
- 知識ベースの強化:現在のデータでベクトルデータベースを継続的に更新
- 補完的検索:内部知識が不足している場合にギャップを埋める
- 多様な視点:異なる地理的地域と言語からの検索
ScrapelessはMCP-RAGでどのように機能しますか?
Scrapelessは、TypeScriptカプセル化クラスScrapelessClientを介してMCP-RAGサーバーと統合し、以下の機能を実現します:
export class ScrapelessClient {
private api: AxiosInstance;
constructor(config: ScrapelessConfig) {
this.api = axios.create({
baseURL: config.baseURL,
headers: {
"Content-Type": "application/json",
"x-api-token": config.token,
},
});
}
async searchWeb(params: WebSearchParams) {
try {
const response = await this.api.post("/api/v1/scraper/request", {
actor: "scraper.google.search",
input: {
q: params.query,
gl: params.country || "us",
hl: params.language || "en",
google_domain: params.domain || "google.com"
}
});
return {
query: params.query,
results: response.data
};
} catch (error) {
// エラーハンドリング...
}
}
}サポートされる高度な機能
| 特徴 | 説明 |
|---|---|
| Google検索統合 | scraper.google.searchアクターを使用して検索結果を取得 |
| 地理ターゲティング | glパラメータを使用して国/地域を制御 |
| 多言語サポート | hlパラメータを使用して異なる言語で結果を返す |
| 検索エンジンドメイン切り替え | google.de、google.frなどの複数のドメインをサポート |
| プロキシ自動管理 | デフォルトでプロキシローテーションを有効にしてIPブロックを回避 |
インテリジェント質問応答システムの展開ガイド(ベクトル検索 + リアルタイムウェブ検索ベース)
ステップ1:プロジェクト構造を初期化し、依存関係をインストールする
プロジェクトをクローンしてセットアップする:
git clone git@github.com:scrapeless-ai/mcp-rag-server.git
cd mcp-rag-serverプロジェクト構造を分析する:
mcp-rag-server/
├── src/
│ ├── config.ts
│ ├── index.ts
│ ├── server.ts
│ ├── qdrant-client.ts
│ └── scrapeless-client.ts
├── package.json
├── tsconfig.json
└── .env依存関係をインストールする:
npm install💡問題解決:
TypeScriptプロジェクト環境が準備され、必要な依存関係(@modelcontextprotocol/sdk、axios、zodなど)が統合され、開発に必要な型定義も自動的に設定されています。
ステップ2:環境設定
`.env`ファイルを作成する:
QDRANT_URL=http://localhost:6333
QDRANT_API_KEY=
QDRANT_COLLECTION=ml_faq_collection
SCRAPELESS_KEY=あなたの_scrapeless_api_key
SCRAPELESS_BASE_URL=https://api.scrapeless.com
設定の理解 (config.ts から):
const QDRANT_URL = process.env.QDRANT_URL?.trim() || "http://localhost:6333";
const QDRANT_API_KEY = process.env.QDRANT_API_KEY?.trim() || "";
const QDRANT_COLLECTION = process.env.QDRANT_COLLECTION?.trim() || "ml_faq_collection";
const SCRAPELESS_KEY = process.env.SCRAPELESS_KEY?.trim();
const SCRAPELESS_BASE_URL = process.env.SCRAPELESS_BASE_URL?.trim() || "https://api.scrapeless.com";
**💡問題解決:**
外部依存関係(QdrantベクトルデータベースとScrapelessリアルタイム検索)の正しい接続パラメータを提供します。デフォルト値とtrim()処理は、変数フォーマットエラーを防ぐために設定コードに組み込まれています。Scrapeless Key が欠落している場合は警告が発行されます。
### ステップ 3: Qdrant ベクトルデータベースのセットアップ
**DockerでQdrantを起動:**Qdrantイメージをプル
docker pull qdrant/qdrant
データ永続性でQdrantコンテナを実行
docker run -d
--name qdrant-server
-p 6333:6333
-p 6334:6334
-v $(pwd)/qdrant_storage:/qdrant/storage
qdrant/qdrant
**FAQベクトルコレクションの作成:**curl -X PUT 'http://localhost:6333/collections/ml_faq_collection'
-H 'Content-Type: application/json'
--data-raw '{
"vectors": {
"size": 1536,
"distance": "Cosine"
}
}'
**💡問題解決:**
意味論的ベクトル検索ストレージを設定し、1536次元およびコサイン類似度を使用し、埋め込みジェネレーターの出力とQdrantClient呼び出しに互換性を持たせます。
### ステップ 4: ScrapelessリアルタイムWeb検索の統合
**Scrapeless APIキーの取得:**
1. [Scrapeless](https://app.scrapeless.com/passport/login?utm_source=official&utm_medium=blog&utm_campaign=mcprag)にアクセスしてアカウントを作成
2. ダッシュボードからAPIトークンを取得
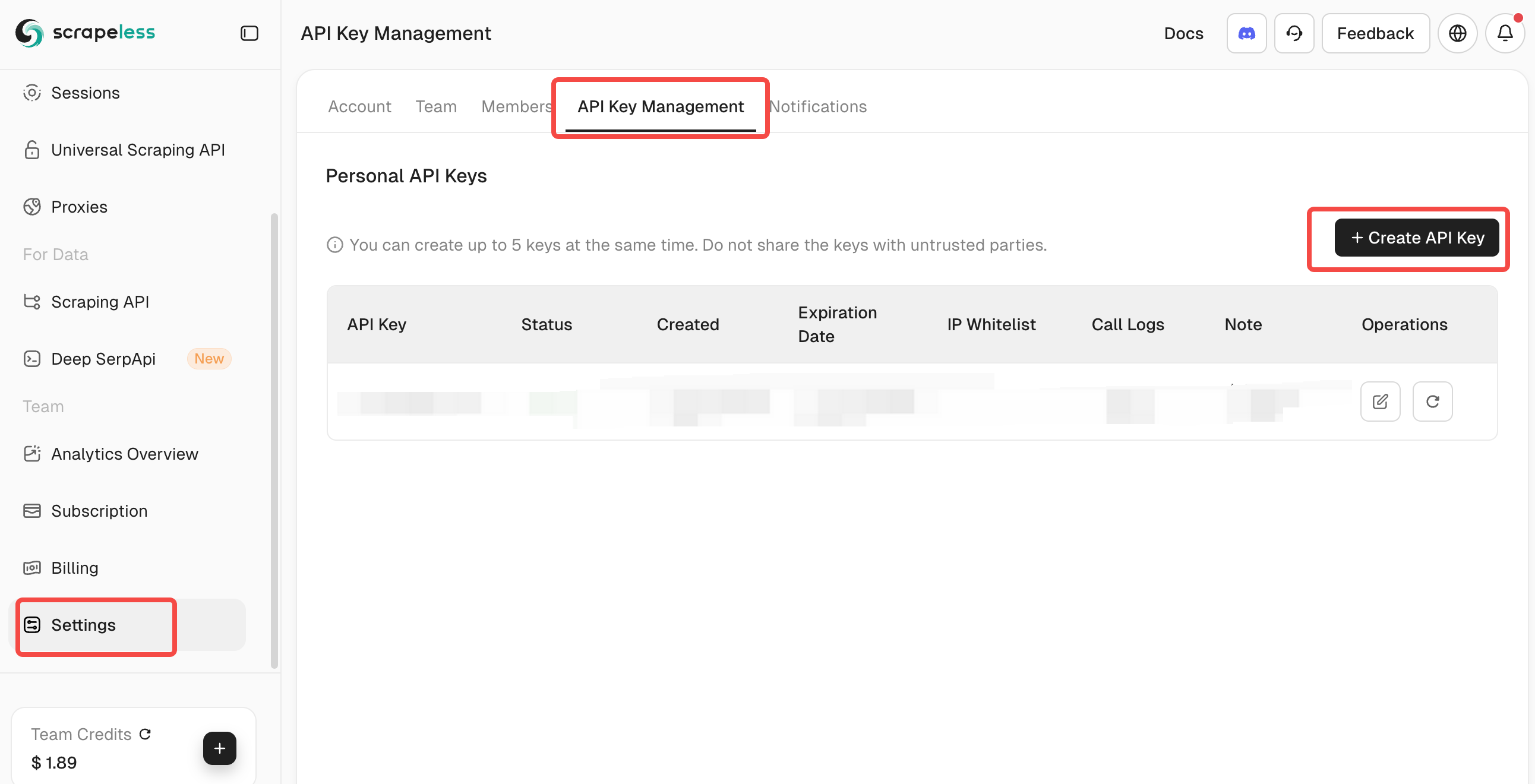
3. SCRAPELESS_KEYの下に.envファイルに追加
**Scrapeless接続のテスト:**API接続をテスト (任意)
curl -X POST 'https://api.scrapeless.com/api/v1/scraper/request'
-H 'Content-Type: application/json'
-H 'x-api-token: YOUR_API_KEY'
-d '{"actor": "scraper.google.search", "input": {"q": "test query"}}'
問題解決: このステップは、Scrapeless APIが正しく設定されていることを確認します。システムには、APIキーが設定されているかを確認するための検証が含まれ、ウェブ検索中のランタイムエラーを防ぎます。
### ステップ 5: TypeScriptプロジェクトのビルド
TypeScriptをJavaScriptにコンパイル:npm run build
ビルド時に何が起こるか (package.jsonから):
```language
{
"scripts": {
"build": "tsc && chmod 755 build/index.js",
"start": "node build/index.js"
}
}ビルド出力を確認:
language
ls build/
# 表示されるべき: index.js, server.js, config.js, qdrant-client.js, scrapeless-client.js問題解決:
このステップは、TypeScriptをJavaScriptにコンパイルし、メインエントリポイントが実行可能であることを確認します。ビルドプロセスは、Node.jsと互換性のあるESモジュール(package.jsonの "type": "module" で指定)を出力します。
ステップ 6: MCPサーバーの開始
language
サーバーを起動:
npm start起動時に何が起こるか (index.tsから):
async function main() {
try {
console.log("MCPエージェントRAGサーバーを起動中...");
const transport = new StdioServerTransport();
await server.connect(transport);
console.log("MCPサーバーはポート8080で稼働中です");
} catch (error) {
console.error("main()で致命的なエラー:", error);
process.exit(1);
}
}問題解決:
このステップは、通信のためにSTDIOトランスポートを使用してMCPサーバーを起動します。サーバーは適切なエラーハンドリングとロギングで初期化されます。
上記の6つのステップに従うことで、次の機能を備えたAI駆動の質問応答システムを構築することができます:
- 意味論的QA機能(Qdrantベクトルデータベースによって駆動される)
- リアルタイムWeb補強(Scrapeless API統合を介して)
- LLM対応インフラストラクチャ(MCPプロトコル標準に基づく)
これは、企業や開発者が迅速に生産準備が整ったRAG(Retrieval-Augmented Generation)システムを展開するための堅実な基盤を形成します。
コアコンポーネントの詳細な説明
QdrantClient: ベクトル処理エンジン
QdrantClientは、埋め込み生成とベクトルデータベースの相互作用機能を提供します。この例では、デモのためにシンプルな決定論的埋め込みメソッドを使用しています:
private generateEmbedding(text: string): number[] {
const seed = [...text].reduce((sum, char) => sum + char.charCodeAt(0), 0) % 10000;
const vector: number[] = [];
let value = seed;
for (let i = 0; i < 1536; i++) {
value = (value * 48271) % 2147483647;
vector.push((value / 2147483647) * 2 - 1);
}
return vector;
}主な機能:
- シンプルな決定論的埋め込み生成
- ドキュメントを追加するためのアップサート操作
- 設定可能なスコアリング閾値を持つ意味的検索
- 適切なエラーハンドリングとフォールバックレスポンス
ScrapelessClient: ウェブ検索エンジンインターフェース
ScrapelessClientはScrapeless APIにアクセスしてウェブ検索を実装し、高度な検索パラメータをサポートしています:
async searchWeb(params: WebSearchParams) {
try {
if (!this.api.defaults.headers.common["x-api-token"]) {
throw new Error("Scrapeless APIキーが設定されていません");
}
const response = await this.api.post("/api/v1/scraper/request", {
actor: "scraper.google.search",
input: {
q: params.query,
gl: params.country || "us",
hl: params.language || "en",
google_domain: params.domain || "google.com"
}
});
return {
query: params.query,
results: response.data
};
} catch (error) {
// エラーハンドリング...
}
}主な機能:
- Scrapeless経由のGoogle検索統合
- 設定可能な国、言語、およびドメイン
- 包括的なエラーハンドリング
- APIキーの検証
MCPサーバーツール
server.tsファイルは3つの主要なツールを定義しています:
- machine-learning-faq-retrieval:
- MLコンセプトのベクターデータベースを検索
- セマンティック類似性マッチングを使用
- スコア付きのフォーマットされた結果を返す
- add-document-to-faq:
- 知識ベースに新しいドキュメントを追加
- メタデータ(カテゴリー、ソース、タグ)をサポート
- 詳細なレスポンスによる適切なエラーハンドリング
- scrapeless-web-search:
- Scrapeless APIを介してウェブ検索を実行
- 設定可能な検索パラメータ
- リアルタイムの情報取得
使い方ガイド: Scrapelessを使用する
基本的な使用例
知識ベースを検索:
machine-learning-faq-retrievalを使用してニューラルネットワークに関する情報を見つける新しい情報を追加:
add-document-to-faqを使用してこれを追加:
テキスト: "ランダムフォレストはアンサンブル学習手法です..."
カテゴリー: "アンサンブル手法"
タグ: ["ランダムフォレスト", "アンサンブル学習"]Scrapelessでウェブを検索:
language
scrapeless-web-searchを使用してAIの最近の進展を見つける高度なScrapelessの使用:
language
scrapeless-web-searchを使用して:
クエリ: "最新のPyTorch機能"
国: "uk"
言語: "en"
ドメイン: "google.co.uk"Scrapeless統合による高度なワークフロー
知識ベースの強化:
1. scrapeless-web-searchを使用して「最新のトランスフォーマーモデル2024」を見つける
2. add-document-to-faqを使用して関連する発見を追加
3. machine-learning-faq-retrievalを使用して情報が検索可能であることを確認情報の検証:
1. machine-learning-faq-retrievalを使用して既存の知識を確認
2. scrapeless-web-searchを使用して最新の情報を探す
3. 知識ベースを比較して更新する多言語知識の構築:
1. scrapeless-web-searchを使用して国="de"および言語="de"でドイツのAI研究を見つける
2. add-document-to-faqを使用して翻訳された要約を追加
3. 多言語の知識ベースを構築するClaude Desktopとの統合
プロジェクトにはClaude Desktop統合のサンプル設定が含まれています:
{
"mcpServers": {
"MCP-RAG-app": {
"command": "node",
"args": ["your-path/to/build/index.js"],
"host": "127.0.0.1",
"port": 8080,
"timeout": 30000,
"env": {
"QDRANT_URL": "http://localhost:6333",
"QDRANT_API_KEY": "",
"QDRANT_COLLECTION": "ml_faq_collection",
"SCRAPELESS_KEY": "SCRAPELESS_KEY"
}
}
}
}よくある問題と解決策
- ビルドエラー:
- Node.jsのバージョン >= 18を確認
- TypeScriptのコンパイルをチェック:npx tsc --noEmit
- ランタイムエラー:
- Qdrantが実行中であることを確認:curl http://localhost:6333/health
- 環境変数が正しく設定されていることを確認
- Scrapeless APIキーが有効であることを確認
- Scrapeless特有の問題:
- APIキーが環境に正しく設定されていることを確認
- ScrapelessダッシュボードでAPIのクォータと制限を確認
- 正しいAPIエンドポイントの設定を確認
- 接続の問題:
- ポートが利用可能であることを確認(Qdrant用に6333)
- ファイアウォール設定を確認
- Dockerコンテナが実行中であることを確認
統合システムの利点
ScrapelessとQdrantの統合によって強力なハイブリッドシステムが構築されます:
- 静的+動的知識:キュレーションされた知識ベースとリアルタイムのウェブデータを組み合わせる
- インテリジェント検索:内部データにはセマンティック検索、ウェブコンテンツにはキーワード検索を使用
- 継続的な強化:新しい情報で自動的に知識ベースを更新
- グローバルな視点:異なる地域と言語から情報にアクセス
- 信頼性:Scrapelessはブロック問題のない一貫したウェブアクセスを保証
結論
MCP-RAGサーバーとScrapelessは、高度にスケーラブルでリアルタイムで更新されるインテリジェントな質問応答システムを実装します。コアバリューには以下が含まれます:
- セマンティック理解:ベクトル類似性を通じたコンテキストの理解
- リアルタイムの情報アクセス:Scrapelessにアクセスして最新のウェブコンテンツを取得
- 標準プロトコルの統合:MCPプロトコルを使用して、Claudeなどのプラットフォームに簡単に接続できる
- 柔軟な構成:カスタマイズ可能なナレッジベースのコレクションと検索ツール
- 未来志向のインテリジェントプラットフォーム:動的な知識強化、多言語サポート、ウェブインテリジェントクローリングをサポート。
Scrapelessの追加により、システムはもはや単なる静的なナレッジベースではなく、グローバルな視野と継続的な学習能力を持つAIナレッジエンジンとなりました。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


