
MCP統合ガイド:Chrome DevTools MCP、Playwright MCP、およびScrapeless Browser MCP
Expert Network Defense Engineer
このガイドでは、3つのモデルコンテキストプロトコル(MCP)サーバー—Chrome DevTools MCP、Playwright MCP、Browser MCP—を紹介します。
概要: 適切なMCPの選択
| MCPタイプ | テックスタック | 利点 | 主なエコシステム | 最適な用途 |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | 公式標準、堅牢で深いパフォーマンス分析ツール。 | 幅広い (Gemini, Copilot, Cursor) | CI/CDの自動化、IDEを横断するワークフロー、詳細なパフォーマンス監査。 |
| Playwright MCP | Node.js / Playwright | ピクセルの代わりにアクセシビリティツリーを使用; 視覚なくても決定論的でLLMフレンドリー。 | 幅広い (VS Code, Copilot) | 信頼性が高く、構造化された自動化で、マイナーなUIの変更によるブレに強い。 |
| Scrapeless Browser MCP | クラウドサービス | ローカルのセットアップゼロ、スケーラブルなクラウドブラウザ、複雑なサイトやボット対策を処理。 | API駆動型 (任意のクライアント) | 大規模で並行な自動化タスク、強力なボット検出を持つウェブサイトとのインタラクション。 |
クラウドブラウザ、無限の統合
3つのMCP—Chrome DevTools MCP、Playwright MCP、Scrapeless Browser MCP—は共通の基盤を持っています: すべてScrapelessクラウドブラウザに接続します。
従来のローカルブラウザ自動化とは異なり、Scrapeless Browserは完全にクラウド内で動作し、開発者とAIエージェントに対して比類のない柔軟性とスケーラビリティを提供します。
これが真に強力な理由です:
- シームレスな統合: Puppeteer、Playwright、CDPと完全に互換性があり、既存プロジェクトからの移行が1行のコードで簡単にできます。
- グローバルIPカバレッジ: 195カ国以上で住宅用、ISP、および無制限のIPプールにアクセスでき、透明でコスト効果の高い料金($0.6–1.8/GB)。大規模なウェブデータ自動化に最適。
- 隔離されたプロファイル: 各タスクは専用の永続環境で実行され、セッションの隔離、マルチアカウント管理、長期的な安定性を確保します。
- 無限の同時スケーリング: 自動スケーリングインフラストラクチャを利用して、50–1000以上のブラウザインスタンスを瞬時に立ち上げます—サーバーのセットアップなし、性能ボトルネックなし。
- 世界中のエッジノード: 他のクラウドブラウザよりも超低遅延で2〜3倍の迅速な起動が可能です。
- 検出防止: reCAPTCHA、Cloudflare Turnstile、AWS WAFのための組み込みソリューションにより、厳しい保護層の下でも自動化が途切れることがありません。
- ビジュアルデバッグ: 人間と機械のインタラクティブなデバッグとリアルタイムのプロキシトラフィックモニタリングをLive Viewを介して実現します。セッション記録を通じてページごとにセッションを再生し、迅速に問題を特定し、操作を最適化します。
Chrome DevTools MCP
Chrome DevTools MCPは、AIコーディングアシスタント—Gemini、Claude、Cursor、またはCopilot—がライブChromeブラウザを制御し、検査するためのモデルコンテキストプロトコル(MCP)サーバーです。信頼性の高い自動化、高度なデバッグ、およびパフォーマンス分析を提供します。
主な機能
- パフォーマンスの洞察を取得: Chrome DevToolsを使用してトレースを記録し、実行可能なパフォーマンスの洞察を抽出します。
- 高度なブラウザデバッグ: ネットワークリクエストを分析し、スクリーンショットを撮影し、ブラウザコンソールを確認します。
- 信頼性の高い自動化: Puppeteerを使用してChromeでのアクションを自動化し、自動的にアクション結果を待機します。
要件
- Node.js v20.19または最新のメンテナンスLTSバージョン。
- npm。
はじめに
Scrapelessにログインし、APIキーを取得します。
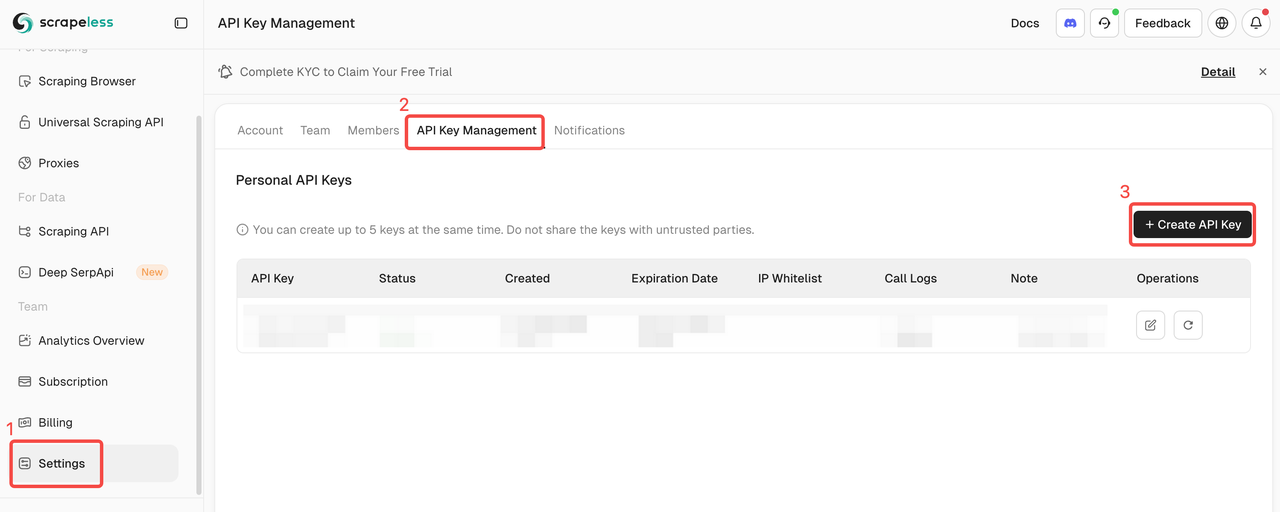
クイックスタート
このJSON構成は、MCPクライアントがChrome DevTools MCPサーバーに接続し、リモートScrapelessクラウドブラウザインスタンスを制御するために使用されます。
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": [
"chrome-devtools-mcp@latest",
"--wsEndpoin=wss://browser.scrapeless.com/api/v2/browser?token=scrapeless api key&proxyCountry=US&sessionRecording=true&sessionTTL=900&sessionName=CDPDemo"
]
}
}
}ショーケース
使用例
- ウェブパフォーマンス分析: CDPを使用してトレースを記録し、ページの読み込み、ネットワークリクエスト、JavaScriptの実行に関する実行可能な洞察を抽出し、AIアシスタントがパフォーマンスの最適化を提案できるようにします。
- 自動デバッグ: コンソールログをキャプチャし、ネットワークトラフィックを検査し、スクリーンショットを撮影し、バグを自動再現して迅速なトラブルシューティングを実現します。
- エンドツーエンドテスト: Puppeteerを使用して複雑なワークフローを自動化し、ページインタラクションを検証し、Chromeでの動的コンテンツレンダリングを確認します。
- AIアシスト自動化: GeminiやCopilotのような大規模言語モデル(LLM)は、信頼性と精度を持ってフォームを記入し、ボタンをクリックし、Chromeページから構造化データをスクレイピングすることができます。
Playwright MCP
Playwright MCP は、Playwrightに基づくブラウザ自動化機能を提供するModel-Context-Protocol (MCP)サーバーです。これにより、大規模言語モデル(LLM)やAIコーディングアシスタントがウェブページと対話することが可能になります。
主な機能
- 高速で軽量。ピクセルベースの入力ではなく、Playwrightのアクセシビリティツリーを使用します。
- LLMに優しい。視覚モデルは不要で、構造化データのみで機能します。
- 決定論的なツール適用。スクリーンショットベースのアプローチに共通する曖昧さを避けます。
要件
- Node.js 18以上
- VS Code、Cursor、Windsurf、Claude Desktop、Gooseまたはその他のMCPクライアント
はじめに
ScrapelessにログインしてAPIキーを取得してください。
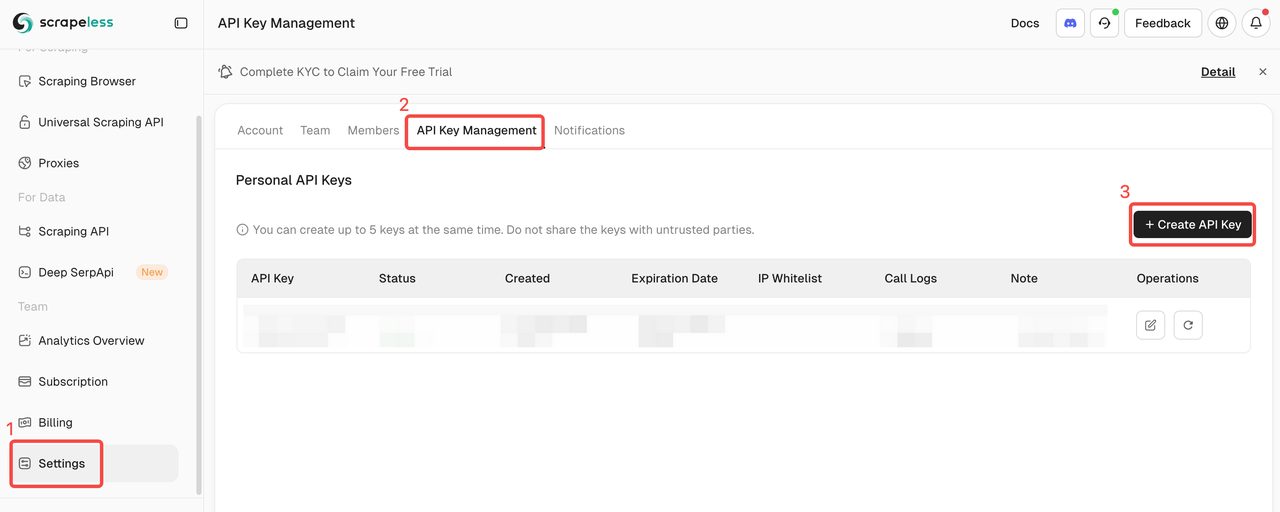
クイックスタート
このJSON構成は、MCPクライアントがPlaywright MCPサーバーに接続し、リモートのScrapelessクラウドブラウザインスタンスを制御するために使用されます。
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--headless",
"--cdp-endpoint=wss://browser.scrapeless.com/api/v2/browser?token=Your_Token&proxyCountry=ANY&sessionRecording=true&sessionTTL=900&sessionName=playwrightDemo"
]
}
}
}ショーケース
ユースケース
-
ウェブスクレイピングとデータ抽出: Playwright MCPを利用したLLMは、ウェブサイトをナビゲートし、構造化データを抽出し、リアルブラウザ環境内での複雑なスクレイピングタスクを自動化できます。これにより、市場調査、コンテンツ集約、競争情報の収集を大規模に支援します。
-
自動ワークフロー実行: Playwright MCPを使用すると、AIエージェントがデータ入力、レポート生成、ダッシュボードの更新など、繰り返し行われるウェブベースのワークフローを実行することができます。特にビジネスプロセスの自動化、人事オンボーディング、その他の高頻度の操作に効果的です。
-
パーソナライズされた顧客サービスとサポート: AIエージェントはPlaywright MCPを使用して直接ウェブポータルと対話し、ユーザー固有のデータを取得し、トラブルシューティングのアクションを実行できます。これにより、注文の詳細を取得したり、ログインの問題を自動的に解決したりするなど、パーソナライズされた文脈を考慮したサポート体験を提供します。
ブラウザMCP
ScrapelessブラウザMCPサーバーは、ChatGPTやClaudeのようなモデルとCursorやWindsurfなどのツールを、ページレベルのナビゲーションや操作のためのブラウザ自動化を含む幅広い外部機能にシームレスに接続します。
- ページレベルのナビゲーションとインタラクションのためのブラウザ自動化
- 動的でJavaScriptが多く使われているサイトをスクレイピング— HTML、Markdown、またはスクリーンショットとしてエクスポート
サポートされているMCPツール
| 名前 | 説明 |
|---|---|
| browser_create | Scrapelessを使用してクラウドブラウザセッションを作成または再利用します。 |
| browser_close | クラウドブラウザの接続を切って現在のセッションを閉じます。 |
| browser_goto | 指定したURLにブラウザをナビゲートします。 |
| browser_go_back | ブラウザの履歴で1ステップ戻ります。 |
| browser_go_forward | ブラウザの履歴で1ステップ進みます。 |
| browser_click | ページの特定の要素をクリックします。 |
| browser_type | 指定された入力フィールドにテキストを入力します。 |
| browser_press_key | キー押下をシミュレートします。 |
| browser_wait_for | 特定のページ要素が表示されるまで待機します。 |
| browser_wait | 固定期間の実行を一時停止します。 |
| browser_screenshot | 現在のページのスクリーンショットをキャプチャします。 |
| browser_get_html | 現在のページの完全なHTMLを取得します。 |
| browser_get_text | 現在のページからすべての表示テキストを取得します。 |
| browser_scroll | ページの下部にスクロールします。 |
| browser_scroll_to | 特定の要素を表示するためにスクロールします。 |
| scrape_html | URLをスクレイピングし、その完全なHTMLコンテンツを返します。 |
| scrape_markdown | URLをスクレイピングし、そのコンテンツをMarkdown形式で返します。 |
| scrape_screenshot | ウェブページの高品質なスクリーンショットをキャプチャします。 |
はじめに
Scrapelessにログインして、APIトークンを取得します。
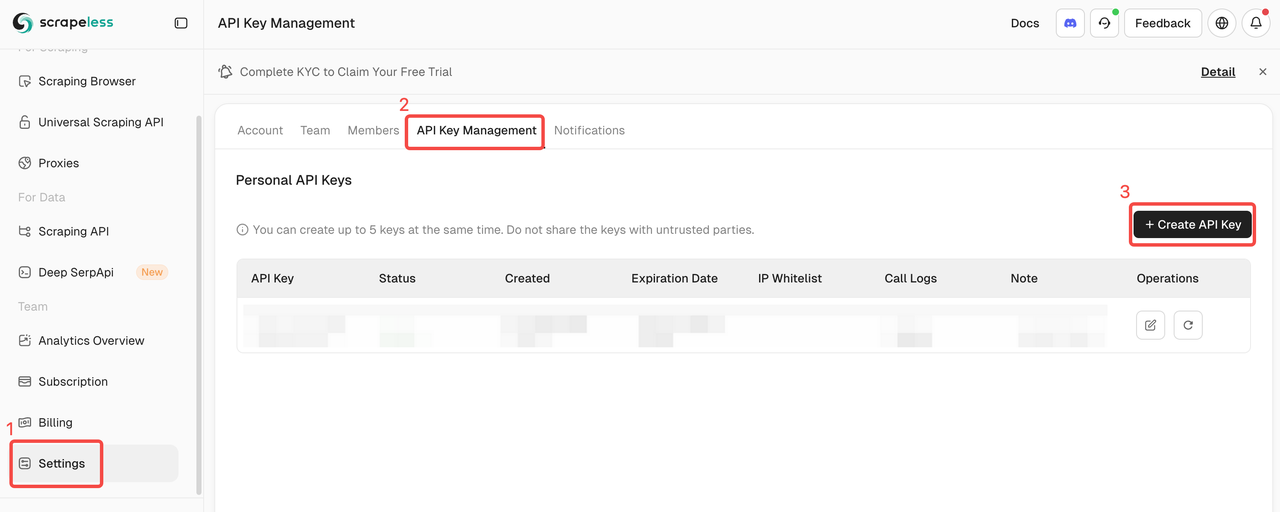
MCPクライアントの設定
Scrapeless MCPサーバーは、StdioとStreamable HTTPの両方のトランスポートモードをサポートしています。
🖥️ Stdio(ローカル実行)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}🌐 Streamable HTTP(ホスティングAPIモード)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}高度なオプション
オプションのパラメーターを使用してブラウザセッションの動作をカスタマイズします。これらは、環境変数(Stdioの場合)またはHTTPヘッダー(Streamable HTTPの場合)を介して設定できます。
| Stdio(環境変数) | Streamable HTTP(HTTPヘッダー) | 説明 |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | セッションの継続性のために再利用可能なブラウザプロファイルIDを指定します。 |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | クッキー、ローカルストレージなどのために永続的な保存を可能にします。 |
| BROWSER_SESSION_TTL | x-browser-session-ttl | 最大セッションタイムアウトを秒単位で定義します。この無活動の期間が経過すると、セッションは自動的に期限切れになります。 |
使用例
ウェブスクレイピングとデータ収集
- Eコマースの監視: 製品ページに自動的にアクセスして価格、在庫状況、説明を収集します。
- 市場調査: 分析と比較のためにニュース、レビュー、企業ページをバッチでスクレイピングします。
- コンテンツの集約: ページコンテンツ、投稿、コメントを抽出して集中管理します。
- リード生成: 企業のウェブサイトやディレクトリから連絡先情報や企業情報を収集します。
テストと品質保証
- 機能確認: クリック、入力、要素の待機を使ってページが期待通りに動作することを確認します。
- ユーザージャーニーテスト: 実際のユーザーのインタラクション(入力、クリック、スクロール)をシミュレートしてワークフローを検証します。
- リグレッションテストのサポート: 主要ページのスクリーンショットをキャプチャし、UIやコンテンツの変更を検出します。
タスクとワークフローの自動化
- フォーム入力: ウェブフォーム(例:登録、アンケート)を自動的に完了し、送信します。
- データキャプチャとレポート生成: ページデータを定期的に抽出し、HTMLまたはスクリーンショットとして保存して分析します。
- 簡単な管理業務: シミュレートされたクリックや入力を使用して、繰り返し行うバックエンドまたはウェブベースの操作を自動化します。
ショーケース
ケース1: Claudeによるウェブインタラクションとデータ抽出の自動化
Browser MCPサーバーを使用すると、Claudeは会話コマンドを通じて、ナビゲーション、クリック、スクロール、データスクレイピングなどの複雑なウェブ操作を実行できます。リアルタイムの実行プレビューがライブセッションで確認できます。
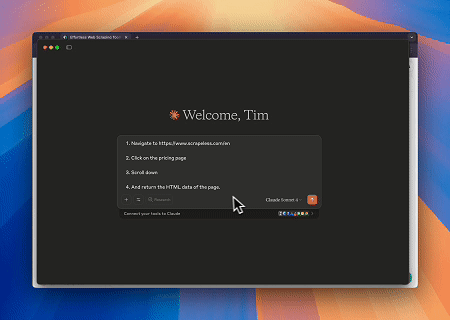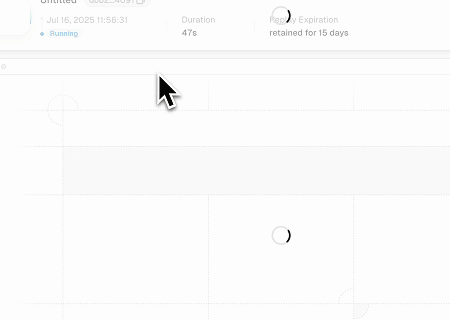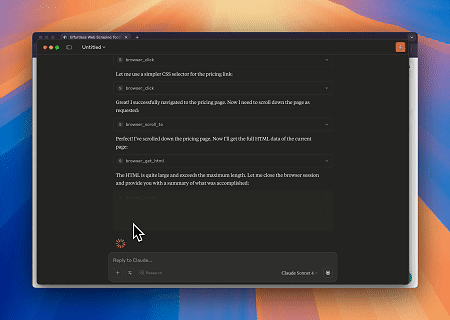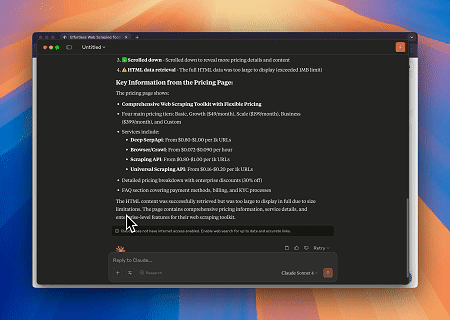
ケース2: Cloudflareをバイパスしてターゲットページコンテンツを取得
Browser MCPサーバーを使用すると、Cloudflareで保護されたページに自動的にアクセスし、完了後にページコンテンツが抽出され、Markdown形式で返されます。
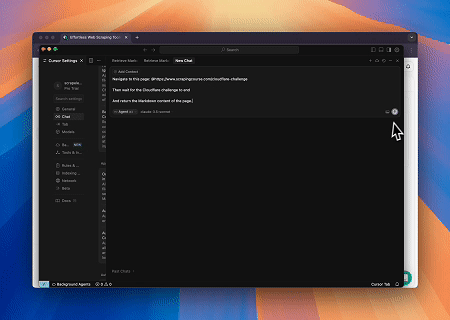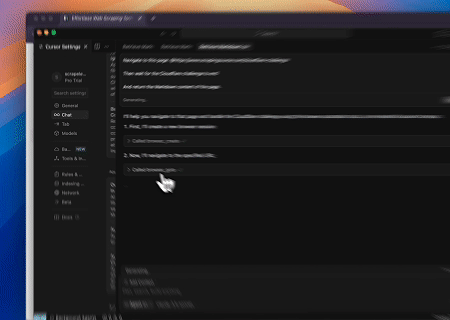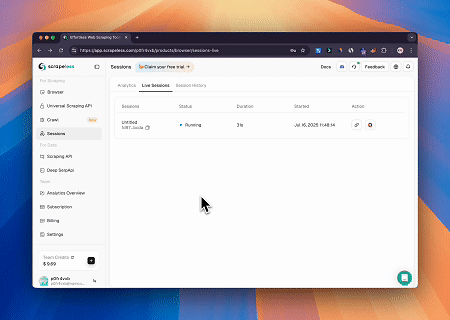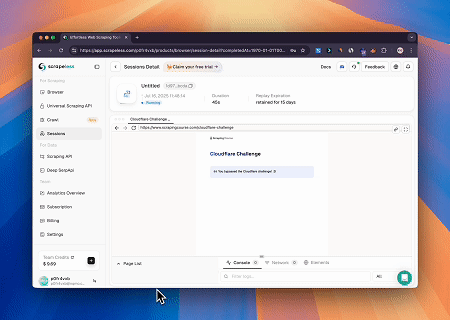
統合
Claude Desktop
- Claude Desktopを開く
- 設定 → ツール → MCPサーバーに移動
- **「MCPサーバーを追加」**をクリック
- 上記のStdioまたはStreamable HTTPの設定を貼り付けます
- サーバーを保存して有効にします
- Claudeはウェブクエリを発行し、コンテンツを抽出し、Scrapelessを使用してページとインタラクションできるようになります。
Cursor IDE
- Cursorを開く
- Cmd + Shift + P を押して、MCPサーバーの構成を検索します
- 上記の形式を使用して、Scrapeless MCP 設定を追加します
- ファイルを保存し、Cursor を再起動します(必要に応じて)
- これで、Cursor に次のようなことを尋ねることができます:
- 「このエラーの解決策を StackOverflow で検索して」
- 「このページから HTML をスクレイプして」
- そうすれば、バックグラウンドで Scrapeless を使用します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


