
Makeで自動的にデータをスクレイピングする方法は?
Senior Web Scraping Engineer
最近、公式のMakeでの統合を開始し、今では公開アプリとして利用可能です。このチュートリアルでは、私たちのGoogle Search APIとWeb Unlockerを組み合わせて検索結果からデータを抽出し、それをClaude AIで処理してWebhookに送信する強力な自動化ワークフローを作成する方法を示します。
作成するもの
このチュートリアルでは、以下のようなワークフローを作成します:
- 統合スケジューリングを使用して毎日自動的にトリガーされる
- Scrapeless Google Search APIを使用して特定のクエリをGoogleで検索する
- Iteratorを使用して各URLを個別に処理する
- Scrapeless WebUnlockerを使用して各URLからコンテンツをスクレイピングする
- Anthropic Claude AIでコンテンツを分析する
- 処理されたデータをWebhook(Discord、Slack、データベースなど)に送信する
前提条件
- Make.comアカウント
- Scrapeless APIキー(scrapeless.comで取得できます)
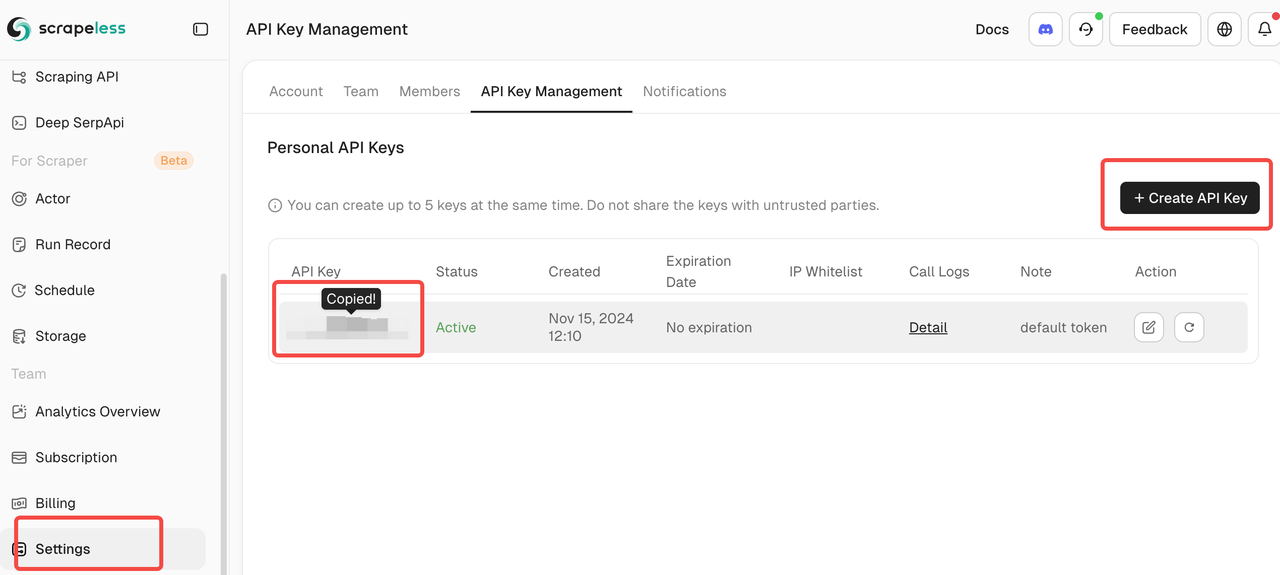
- Anthropic Claude APIキー
- Webhookエンドポイント(Discord Webhook、Zapier、データベースエンドポイントなど)
- Make.comのワークフローに関する基本的な理解
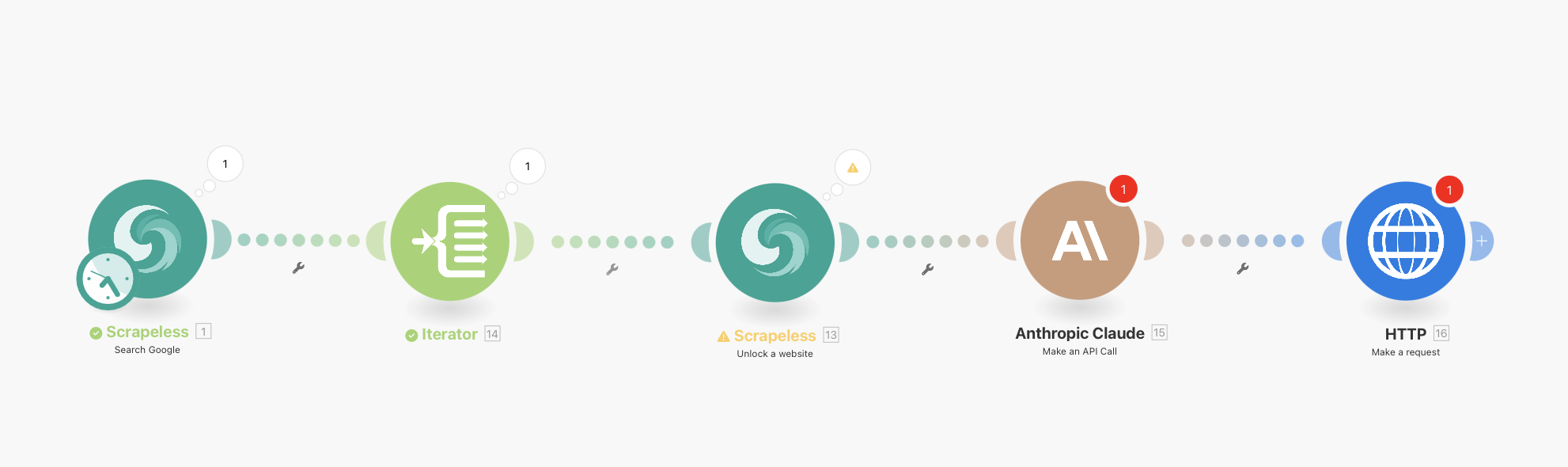
完全なワークフロー概要
最終的なワークフローは次のようになります:
Scrapeless Google Search(統合スケジューリング付き) → Iterator → Scrapeless WebUnlocker → Anthropic Claude → HTTP Webhook
ステップ1:統合スケジューリングを使ったScrapeless Google Searchの追加
まず、組み込みスケジューリング機能を持つScrapeless Google Searchモジュールを追加します。
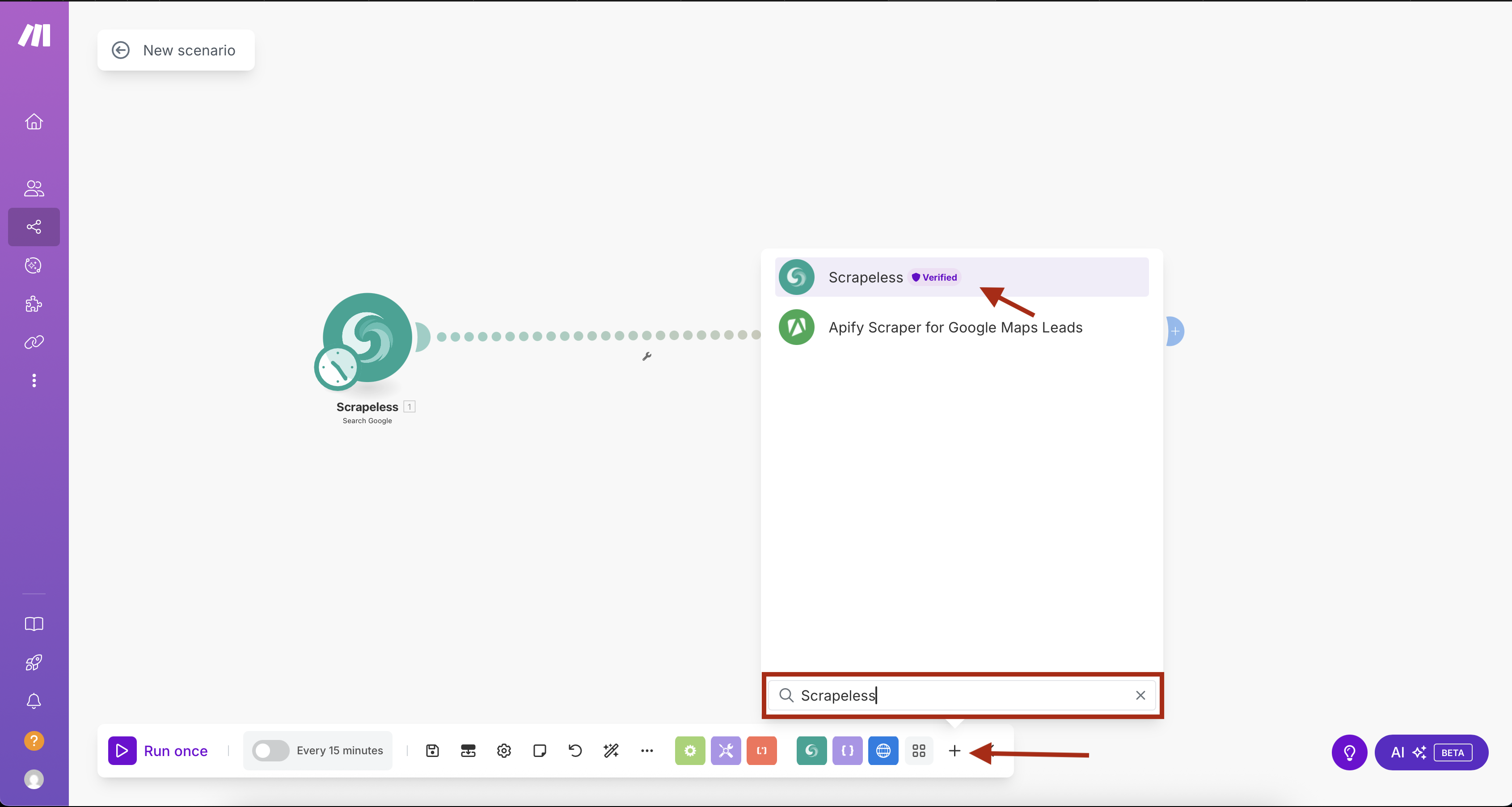
- Make.comで新しいシナリオを作成する
- 最初のモジュールを追加するために「+」ボタンをクリックする
- モジュールライブラリで「Scrapeless」を検索する
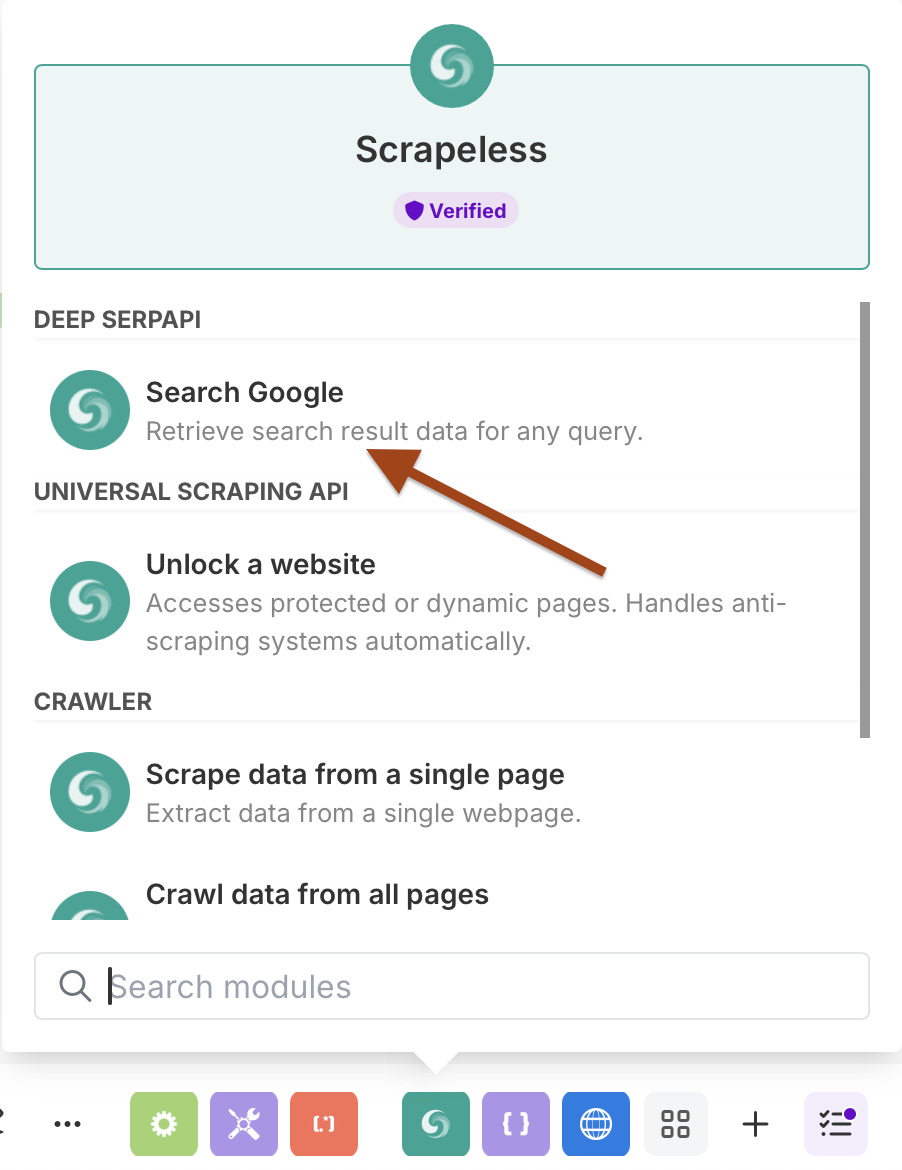
- Scrapelessを選択し、Search Googleアクションを選択
スケジューリング付きGoogle検索の設定
接続設定:
- 接続を作成し、Scrapeless APIキーを入力
- 「追加」をクリックし、接続設定に従う
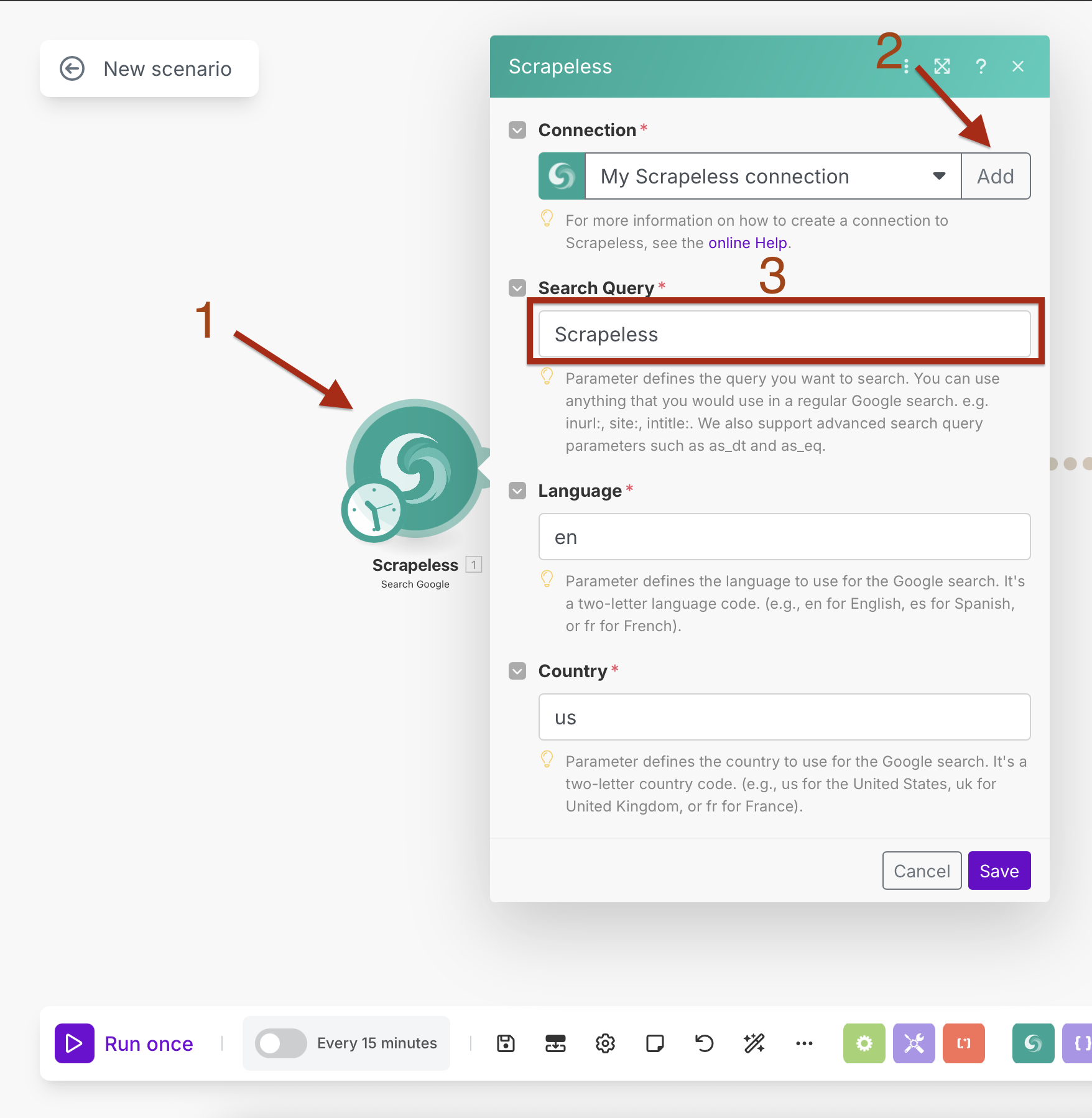
検索パラメータ:
- 検索クエリ:ターゲットクエリを入力(例:「人工知能ニュース」)
- 言語:
en(英語) - 国:
US(アメリカ合衆国)
スケジューリング設定:
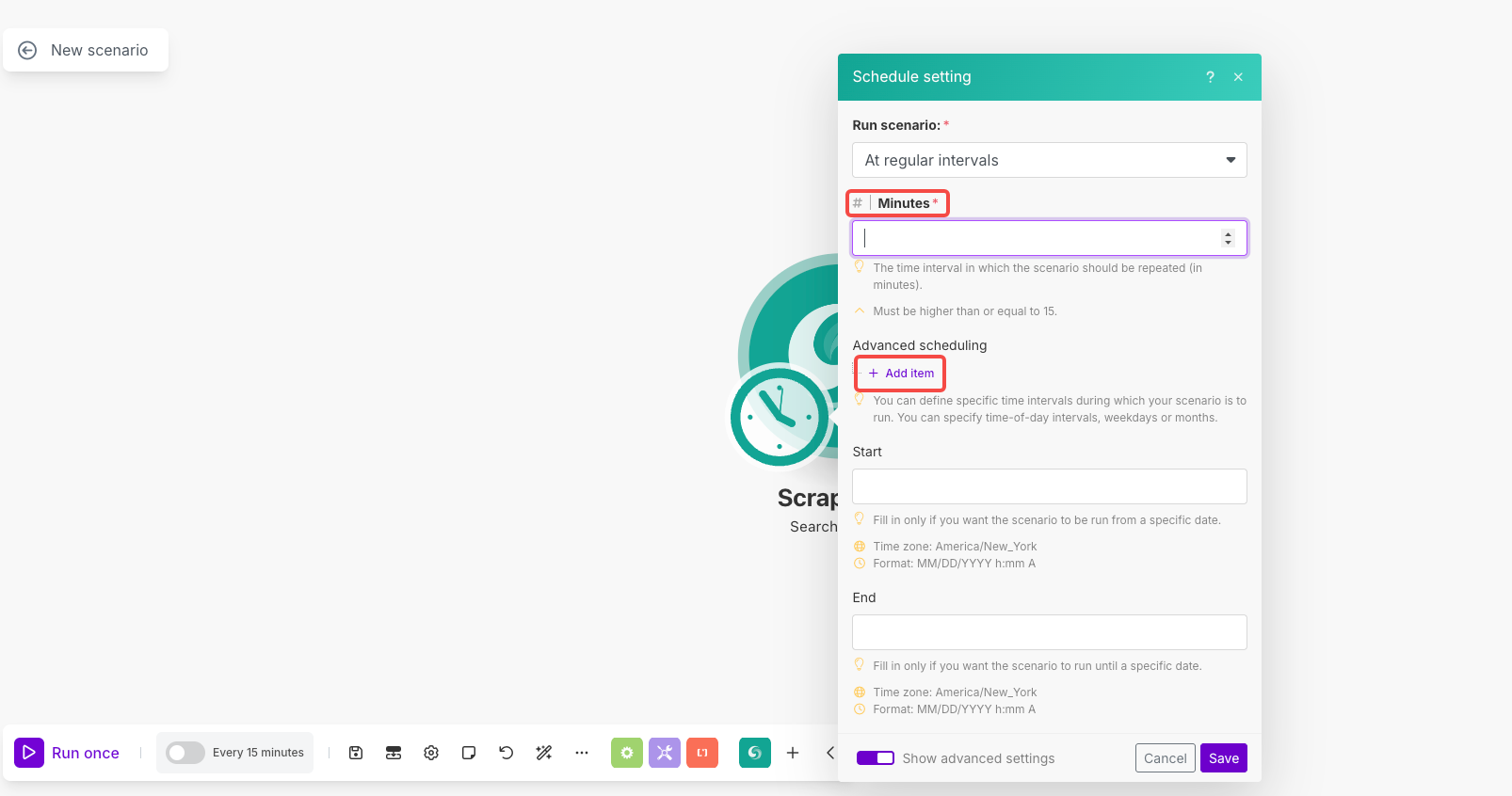
- モジュールの時計アイコンをクリックしてスケジューリングを開く
- シナリオを実行: 「定期的に」を選択
- 分:
1440(毎日実行するため)またはお好みの間隔を設定 - 高度なスケジューリング:必要に応じて「アイテムを追加」を使用して特定の時間/曜日を設定
ステップ2:Iteratorで結果を処理
Google検索は複数のURLを配列で返します。Iteratorを使用して各結果を個別に処理します。
- Google Searchの後にIteratorモジュールを追加する
- 検索結果を処理するために配列フィールドを設定
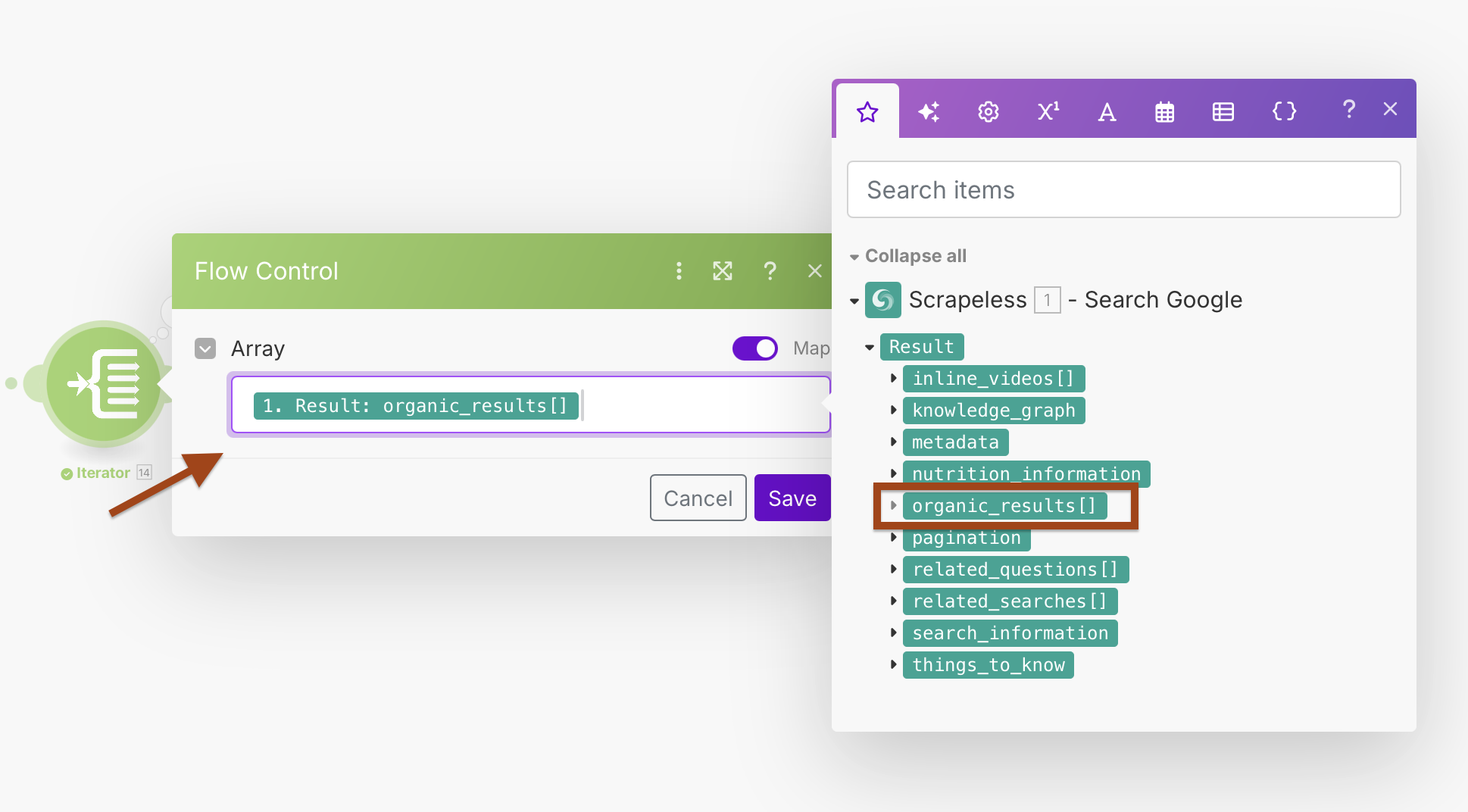
Iterator設定:
- 配列:
{{1.result.organic_results}}
これにより、各検索結果を個別に処理するループが作成され、エラー処理が向上し、個別処理が可能になります。
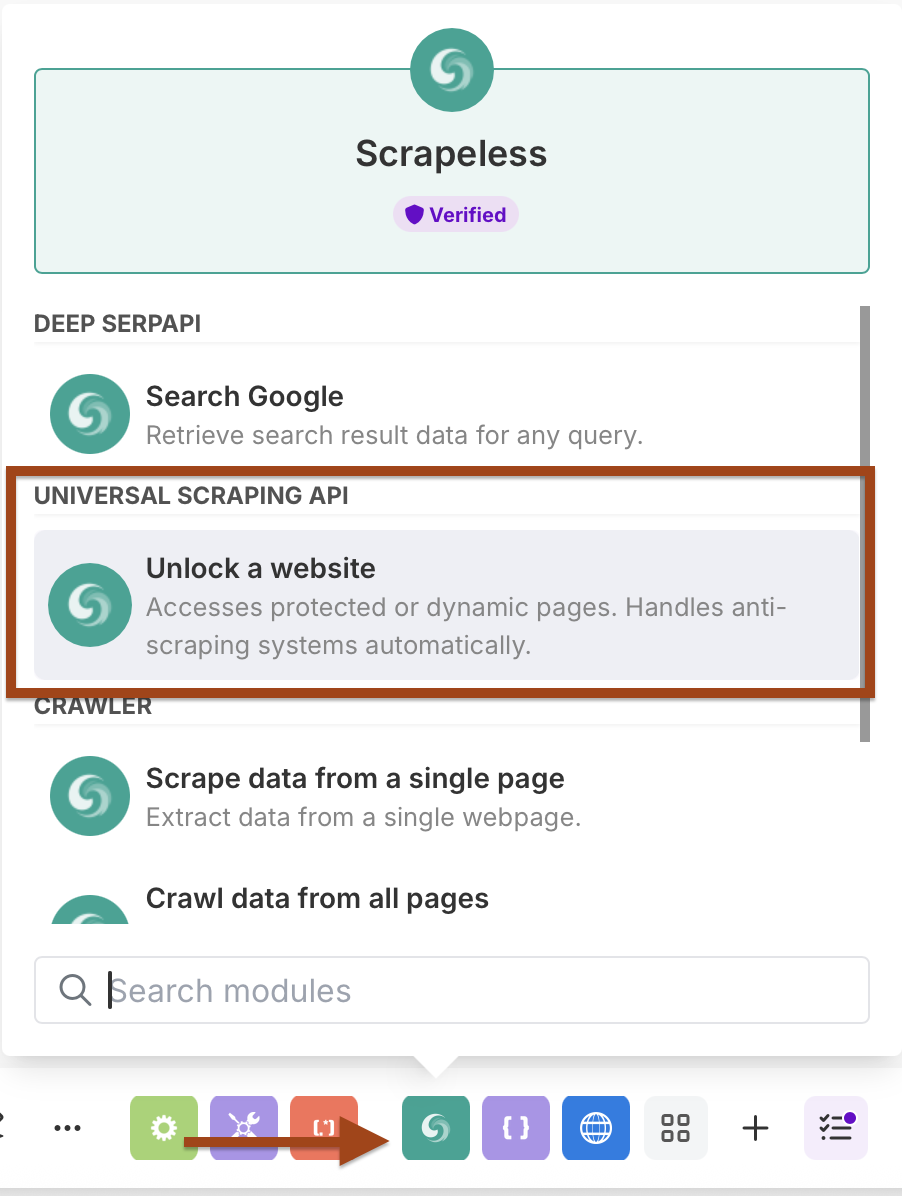
ステップ3:Scrapeless WebUnlockerの追加
次に、各URLからコンテンツをスクレイピングするためにWebUnlockerモジュールを追加します。
- もう1つのScrapelessモジュールを追加する
- Scrape URL(WebUnlocker)アクションを選択
- 同じScrapeless接続を使用
WebUnlocker設定:
- 接続:既存のScrapeless接続を使用
- ターゲットURL:
{{2.link}}(Iteratorの出力からマッピング) - Jsレンダリング:はい
- ヘッドレス:はい
- 国:全世界
- Js指示:
[{"wait":1000}](ページロードを待機) - ブロック:より速いスクレイピングのために不要なリソースをブロックするように設定
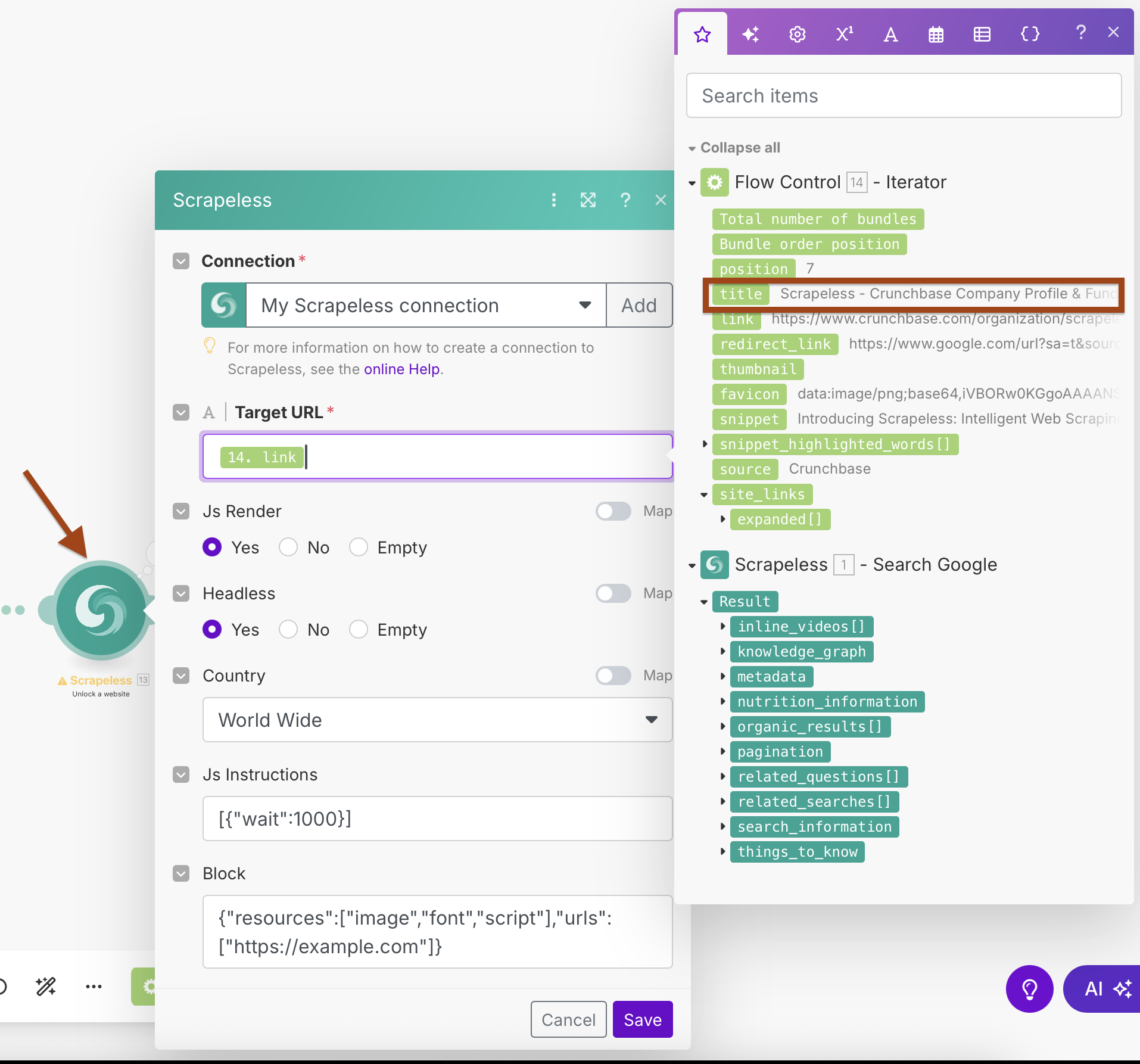
ステップ4:Anthropic ClaudeによるAI処理
Claude AIを追加して、スクレイピングしたコンテンツを分析・要約します。
- Anthropic Claudeモジュールを追加する
- API呼び出しを行うアクションを選択
- Claude APIキーで新しい接続を作成する
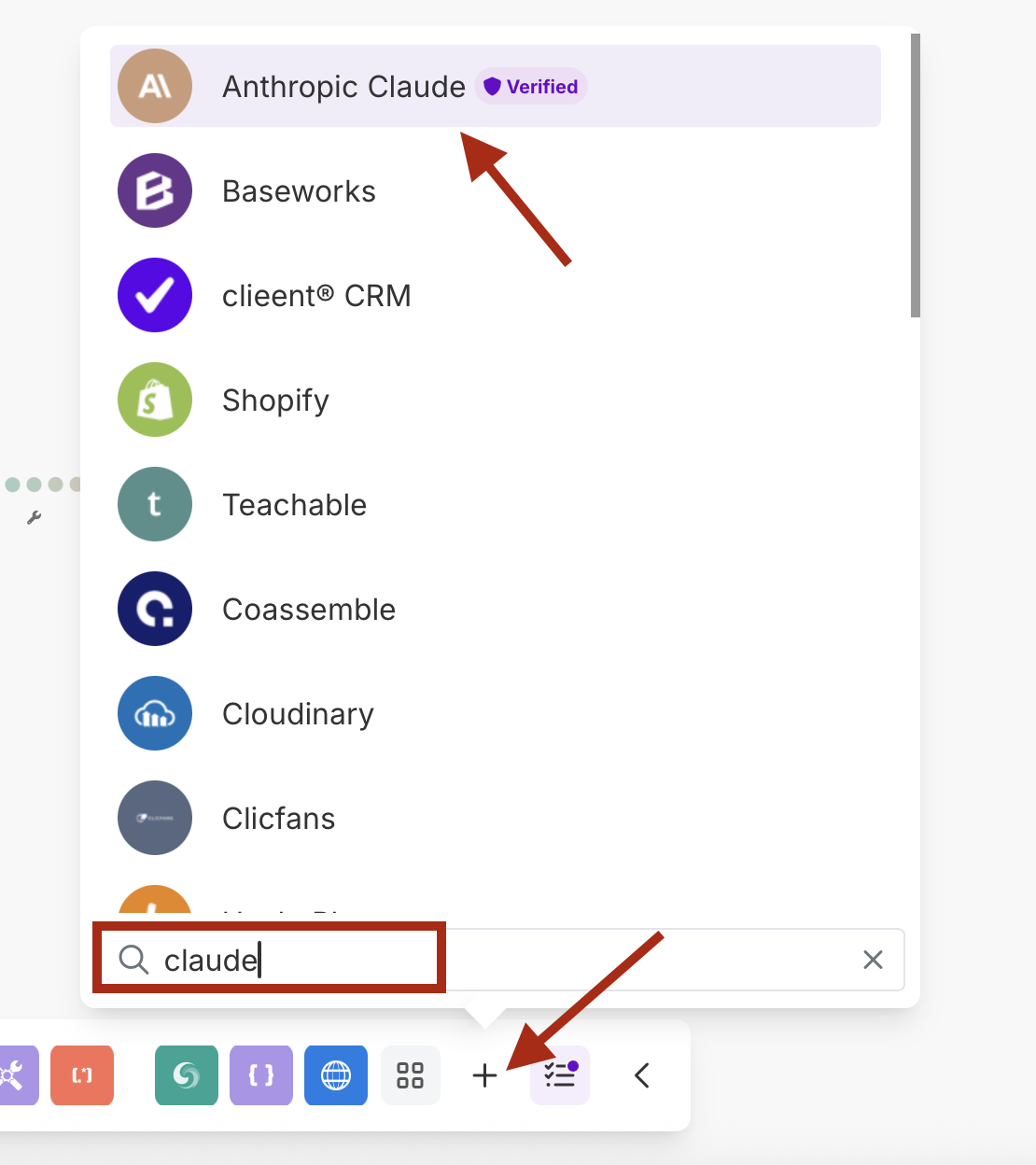
Claude設定:
- 接続:Anthropic APIキーで接続を作成
- プロンプト: スクレイピングしたコンテンツを分析するように設定する
- モデル: claude-3-sonnet-20240229 / claude-3-opus-20240229 またはお好みのモデル
- 最大トークン数: 1000-4000 は必要に応じて
URL
/v1/messagesヘッダー 1
キー : Content-Type値 : application/json
ヘッダー 2
キー : anthropic-version値 : 2023-06-01
例のプロンプトをボディにコピー&ペースト:
{
"model": "claude-3-sonnet-20240229",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "このウェブコンテンツを分析し、英語で重要なポイントを含む要約を提供してください:\n\nタイトル: {{14.title}}\nURL: {{14.link}}\n説明: {{14.snippet}}\nコンテンツ: {{13.content}}\n\n検索クエリ: {{1.result.search_information.query_displayed}}"
}
]
}- モジュール番号の
14を忘れずに変更してください。
ステップ 5: Webhook 統合
最終的に、処理されたデータをあなたのWebhookエンドポイントに送信します。
- HTTP モジュールを追加
- POSTリクエストをあなたのWebhookに送信するように構成する
HTTP設定:
- URL: あなたのWebhookエンドポイント (Discord, Slack, データベースなど)
- メソッド: POST
- ヘッダー:
Content-Type: application/json - ボディタイプ: 生 (JSON)
例のWebhookペイロード:
{
"embeds": [
{
"title": "{{14.title}}",
"description": "*{{15.body.content[0].text}}*",
"url": "{{14.link}}",
"color": 3447003,
"footer": {
"text": "分析完了"
}
}
]
}モジュールリファレンスおよびデータフロー
モジュールを通るデータフロー:
- モジュール 1 (Scrapeless Google Search):
result.organic_results[]を返す - モジュール 14 (イテレーター): 各結果を処理し、個別のアイテムを出力する
- モジュール 13 (WebUnlocker):
{{14.link}}をスクレイピングし、コンテンツを返す - モジュール 15 (Claude AI):
{{13.content}}を分析し、要約を返す - モジュール 16 (HTTP Webhook): 最終的な構造化データを送信する
キーマッピング:
- イテレーター配列:
{{1.result.organic_results}} - WebUnlocker URL:
{{14.link}} - Claude コンテンツ:
{{13.content}} - Webhook データ: 全ての前のモジュールの結合
ワークフローのテスト
- 一度実行して完全なシナリオをテストする
- 各モジュールをチェック:
- Google検索はオーガニック結果を返す
- イテレーターは各結果を個別に処理する
- WebUnlockerはコンテンツを正常にスクレイピングする
- Claudeは意味のある分析を提供する
- Webhookは構造化データを受信する
- Webhook送信先でデータの質を確認する
- スケジューリングをチェック - あなたの希望する間隔で実行されることを確認する
高度な設定のヒント
エラーハンドリング
- 各モジュールの後に エラーハンドラー ルートを追加する
- フィルターを使って無効なURLや空のコンテンツをスキップする
- 一時的な失敗のために 再試行 ロジックを設定する
このワークフローの利点
- 完全自動化: 手動介入なしで毎日実行される
- AIによる強化: コンテンツが自動的に分析され要約される
- 柔軟な出力: Webhookはどんなシステムとも統合できる
- スケーラブル: 複数のURLを効率的に処理する
- 品質管理: 複数のフィルタリングと検証ステップ
- リアルタイム通知: 希望するプラットフォームへの即時配信
使用例
完璧な用途:
- コンテンツモニタリング: 自社または競合の言及を追跡
- ニュース集約: 特定トピックに関する自動ニュース要約
- マーケットリサーチ: 業界のトレンドや動向を監視
- リードジェネレーション: 潜在的ビジネス機会を見つけて分析
- SEOモニタリング: 目標キーワードの検索結果の変化を追跡
- 研究の自動化: 学術的または業界コンテンツを収集し要約する
結論
この自動化されたワークフローは、ScrapelessのGoogle検索とWebUnlockerの力を結集し、Claude AIの分析能力を利用して、Makeのビジュアルインターフェースを通じて調整されています。その結果、自動的に実行され、Webhookを通じて希望するプラットフォームに直接配信される強化された分析データを提供する知的コンテンツ発見システムです。
このワークフローは、手動介入なしで、自動的に関連するコンテンツの洞察を発見、スクレイピング、分析、および配信します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


