
ヘッドレスブラウザとは何か、そしてスクレイピングに最適なヘッドレスブラウザ
Specialist in Anti-Bot Strategies
この記事では、ヘッドレスブラウザとは何か、その用途、ヘッドレスChromeとは何か、ヘッドレスモードで最も人気のある他のブラウザについて学習します。また、ヘッドレスブラウザテストの主な制限についても説明します。
さあ、スクロールを続けましょう!
なぜ2000万人の開発者に信頼されているのか?
複雑なヘッドレスブラウザの世界をどのようにナビゲートしますか?多くの困難を乗り越えて勝利した、熟練のガイドが必要です。それが私たちの出番です!
Scrapelessでは、長年にわたりウェブスクレイピングと自動化技術を探求してきました。私たちのチームは、PhantomJSのような従来のソリューションからPlaywrightのような新しいソリューションまで、さまざまなヘッドレスブラウザソリューションの研究に15,000時間以上を費やしてきました。
ヘッドレスブラウザがプロジェクトを成功させるか失敗させるかを、私たちは直接見てきました。無数の問題をデバッグし修正し、大規模なスクレイピング操作のパフォーマンスを最適化し、既製のオプションでは不十分な場合でもカスタムソリューションを開発しました。
テストの自動化、大規模なデータスクレイピング、またはヘッドレスブラウジングの仕組みを学ぶことを目的としている場合でも、お手伝いできます!
ヘッドレスブラウザとは?
まず、これらの目に見えないパワフルなツールが何であり、どのように機能するかを理解しましょう!
ヘッドレスブラウザは、ウェブ世界の忍者のようなものです。ステルス性があり、効率的で、強力です。基本的に、グラフィカルユーザーインターフェース(GUI)を備えていないウェブブラウザです。GUIのないブラウザは視覚コンテンツを描画する必要がないため、高速に動作するため、主にソフトウェアテストエンジニアによって使用されます。ヘッドレスブラウザの最大の利点の1つは、GUIサポートなしでサーバー上で実行できることです。
ChromeやFirefoxを想像してみてください。ただし、ページデータの読み込みや表示はまったく見えず、コードまたはコマンドラインインターフェースを介して完全に制御できます。
そのようなブラウザの能力を疑ったことはありませんか?もう誤解しないでください!これらは、従来のブラウザのほとんどすべての機能を実行できます。
- ウェブページのレンダリング
- JavaScriptの実行
- Cookieとセッションの管理
- ネットワークリクエストの処理
唯一の違いは、画面に何も表示せずにこれらすべてを実行することです。これにより、自動化、テスト、データ抽出タスクに最適です。
ヘッドレスブラウザの主要コンポーネント
注記: ヘッドレスブラウザを使用する際は、JavaScriptエンジンに特に注意してください。JSエンジンの違いは、特に最新のウェブアプリケーションを扱う場合、予期しない動作につながることがあります。
- ブラウザエンジン: HTML、CSS、JavaScriptを解釈する中核コンポーネント。一般的なエンジンには、Blink(Chrome)、Gecko(Firefox)、WebKit(Safari)などがあります。
- JavaScriptエンジン: JavaScriptコードを実行する役割を担います。例としては、V8(Chrome)とSpiderMonkey(Firefox)などがあります。
- レンダリングエンジン: ヘッドレスブラウザでは、このコンポーネントは依然としてページレイアウトを処理しますが、視覚的な出力を生成しません。
- ネットワークスタック: HTTPリクエストやレスポンスなど、すべてのネットワーク通信を処理します。
- APIまたはコマンドインターフェース: ヘッドレスブラウザはGUIを提供しませんが、代わりに制御と対話のためのAPIまたはコマンドラインインターフェースを提供します。
- DOM(ドキュメントオブジェクトモデル): ウェブページの構造のプログラムによる表現です。
ヘッドレスブラウザの主な用途
- ウェブクロール: JavaScriptレンダリングを実行する必要がある動的なコンテンツやページをクロールするために使用されます。例:製品情報のクロール、動的に生成される価格など。
- 自動テスト: 実際のウィンドウを開かずに、ウェブアプリケーションのユーザーインターフェースの動作をテストします。CI/CDプロセスでフロントエンド機能を確認するために一般的に使用されます。
- パフォーマンス監視: ウェブページの読み込み時間、レンダリングパフォーマンスなどを検出します。
- スクリーンショットの生成とPDFエクスポート: ウェブページのスクリーンショットを生成したり、PDFに変換したりします。
- ウェブサイト監視: ウェブサイトが期待通りに動作しているかどうか、エラーや変更がないかどうかを検出します。
欠点と制限
- デバッグの課題: 視覚的なフィードバックがないため、一部の問題の診断が困難になる場合があります。主流のブラウザとは異なるデバッグアプローチが必要です。
- リソース集約型: フルブラウザよりも効率的ですが、大規模な操作では依然としてリソース集約型になる可能性があります。
- レンダリングの不完全さ: 一部の複雑な視覚要素やアニメーションは正しくレンダリングされない場合があります。
- ウェブサイトによる検出: 高度なウェブサイトは、ヘッドレスブラウザを検出してブロックする場合があります。「リアル」なブラウザの動作を模倣する追加の技術が必要です。
- 学習曲線: プログラミングの知識とウェブ技術の理解が必要です。各ヘッドレスブラウザソリューションには、習得する必要がある独自のAPIと機能があります。
ヘッドレスブラウザと通常のブラウザの違い:5つの主要な違い
| 属性 | ヘッドレスブラウザ | 通常のブラウザ |
|---|---|---|
| ユーザーインターフェース | ユーザーインターフェースなし(非表示) | 完全なユーザーインターフェース(ウィンドウ、メニューなど) |
| インタラクティビティ | マウスやキーボードで直接操作できない | ユーザーは直接操作できます(クリック、入力など) |
| パフォーマンス | グラフィックやページコンテンツを表示しないため軽量 | ページグラフィックやアニメーションを表示するため重い |
| ユースケース | 自動テスト、ウェブスクレイピング、監視など | 日常的なブラウジング、操作、インタラクション |
| リソース消費 | 比較的低く、サーバーまたはスクリプト環境に適している | 比較的高く、より多くのシステムリソースを必要とする |
5つの一般的なヘッドレスブラウザ
トップ1. Scrapelessスクレイピングブラウザ - 2025年最高のヘッドレスブラウザ
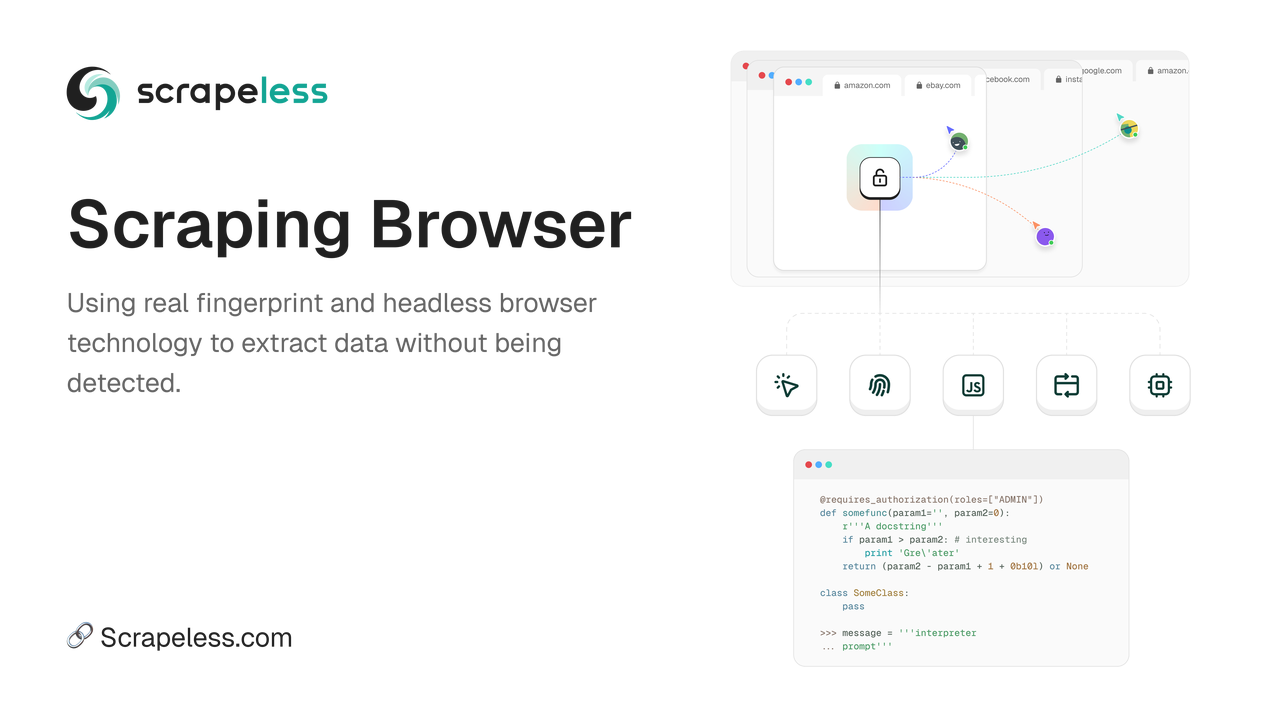
Scrapelessスクレイピングブラウザは、動的なウェブサイトからデータを抽出するプロセスを合理化するために設計された、高性能なヘッドレスブラウザです。開発者は、専用のサーバーを必要とせずに、効率的にヘッドレスブラウザを操作および監視できるため、ウェブ自動化とデータ収集がよりアクセスしやすくなります。
使用方法:
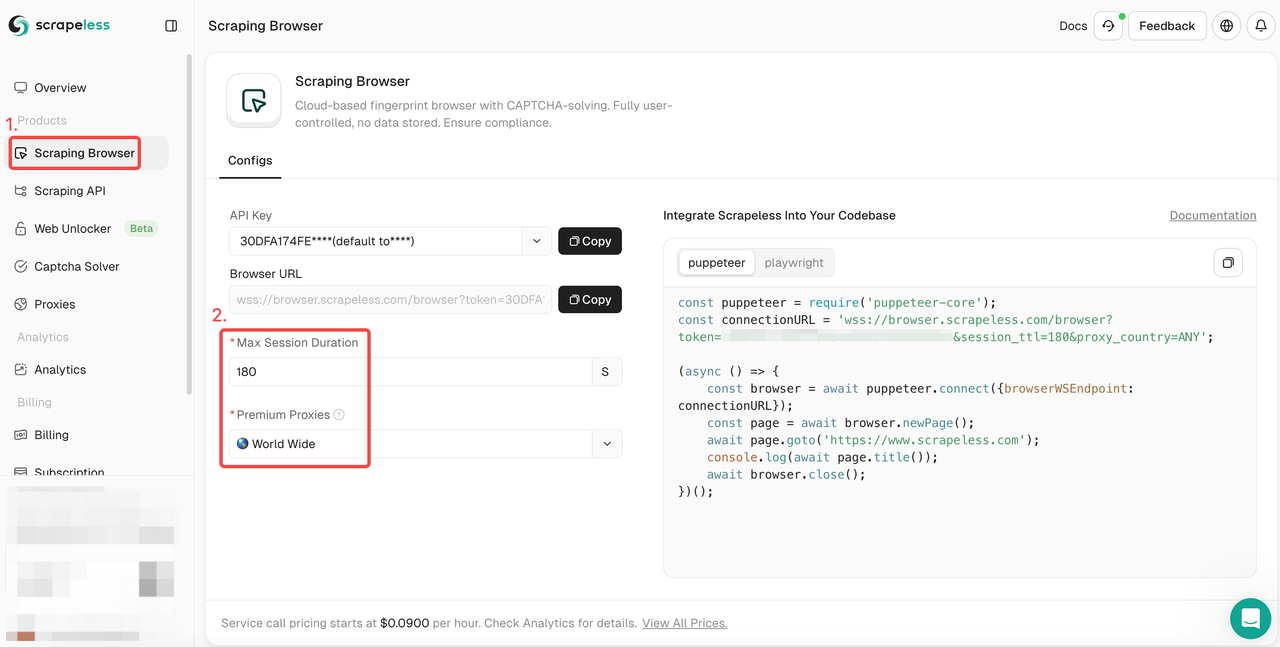
- 手順1. Scrapelessにサインインします。
- 手順2. 「スクレイピングブラウザ」に入力します。
- 手順3. 必要に応じてパラメータを設定します。
- 手順4. プロジェクトに統合するためのサンプルコードをコピーします。
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //APIトークンを入力
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //APIトークンを入力
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();詳細については、ドキュメントが役立ちます。
Puppeteer:
- 必要なライブラリのインストール
まず、既存のブラウザインスタンスに接続するために設計された、軽量バージョンのPuppeteerであるpuppeteer-coreをインストールします。
Bash
npm install puppeteer-core- スクレイピングブラウザに接続するためのコードの記述
Puppeteerコードで、次の方法を使用してスクレイピングブラウザに接続します。
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();これにより、スケーラビリティ、IPローテーション、グローバルアクセスなど、スクレイピングブラウザのインフラストラクチャを活用できます。
- 例:
スクレイピングブラウザと統合した後の一般的なPuppeteer操作をいくつか示します。
- ナビゲーションとページコンテンツの抽出
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- スクリーンショット
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- カスタムスクリプトの実行
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Playwright:
- 必要なライブラリのインストール
まず、既存のブラウザインスタンスに接続するPlaywrightの軽量バージョンであるplaywright-coreをインストールします。
Bash
npm install playwright-core- スクレイピングブラウザに接続するためのコードの記述
Playwrightコードで、次の方法を使用してスクレイピングブラウザに接続します。
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();これにより、スケーラビリティ、IPローテーション、グローバルアクセスなど、スクレイピングブラウザのインフラストラクチャを活用できます。
- 例
スクレイピングブラウザと統合した後の一般的なPlaywright操作をいくつか示します。
- ナビゲーションとページコンテンツの抽出
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- スクリーンショット
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- カスタムスクリプトの実行
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();トップ2. Playwright
Microsoftによって開発されたPlaywrightは、Chromium、Firefox、WebKitベースのブラウザを管理するための単一のAPIを提供します。高レベルのAPIを使用して、複数のブラウザを自動化するために使用できます。ヘッドレスブラウザテスト用にPlaywrightを設定する前に、システムに最新バージョンのNode.JSとnpmがインストールされていることを確認してください。
Playwrightは、その独自の機能により、自動化コミュニティで急速に普及しています。
- クロスブラウザサポート(Chrome、Firefox、Safari)。
- 強力な自動待ち時間メカニズム。
- 強力なネットワークインターセプト機能。
- 複数の言語(JavaScript、Python、.NET、Java)のサポート。
トップ3. Puppeteer
Googleによって開発されたPuppeteerは、DevToolsプロトコルを介してChromeまたはChromiumを制御するための高レベルAPIを提供します。多くのJavaScript開発者の好ましい選択肢です。
- Chrome/Chromiumとの深い統合
- ブラウザ制御のための包括的なAPI
- PDFとスクリーンショットを生成するための組み込みサポート
トップ4. Selenium
Seleniumは、自動化に最適な無料のオープンソースツールです。さまざまなオペレーティングシステムで実行されているさまざまなブラウザをサポートします。Selenium Web Driverは、動的なウェブページに対する強化されたサポートを提供し、Selenium Headlessを使用することで優れた結果を得ることができます。さらに、ヘッドレスChromeまたはヘッドレスFirefoxを使用して、ヘッドレスブラウザSeleniumを実行できます。
- 複数のプログラミング言語のサポート
- さまざまなブラウザとの互換性(Chrome、Firefox、Safari、Edge)
- ツールと拡張機能の巨大なエコシステム
トップ5. Cypress
Cypreeは、特にシングルページアプリケーションのウェブアプリケーションのエンドツーエンドテストに優れています。Cypressは主にエンドツーエンドテストに焦点を当てていますが、開発者フレンドリーなアプローチと強力なデバッグ機能で人気があります。
- ライブリロード
- タイムトラベルデバッグ
- DOMとネットワークレイヤーへのネイティブアクセス
ヘッドレスChromeテストとは?
開発者であれば、アプリケーションが時間の経過とともに正しく機能することを保証するUI駆動型テストに精通している可能性があります。ただし、UI駆動型テストの大きな課題の1つは、安定性です。特に、テストがブラウザと一貫して対話できない場合です。
ヘッドレスブラウザテストはこの問題に対する解決策を提供します。UI駆動型テストとは異なり、アプリケーションのユーザーインターフェースを読み込むことなくエンドツーエンドテストを可能にします。このアプローチは、テストプロセスを高速化するだけでなく、ページとの直接的な対話を保証し、不安定性を軽減します。その結果、テストはより高速になり、より信頼性が高く、非常に効率的になります。
ヘッドレスブラウザテストを使用する必要がある場合
ヘッドレスブラウザテストは、リソースが制約されている場合、または自動化タスクを効率的に実行する必要がある場合に特に役立ちます。一般的なユースケースをいくつか示します。
- 自動化されたHTML操作
フォームの送信、ボタンのクリック、ドロップダウンメニューの選択などのユーザー操作をシミュレートします。ヘッドレスブラウザを使用すると、これらの操作への応答を効果的に検証できます。 - JavaScript実行テスト
ウェブページでのJavaScriptの実行をテストして、動的なコンテンツを検証します。これは、クライアント側のレンダリングが非常に多いアプリケーションに特に役立ちます。 - ウェブスクレイピング
基本的なアンチスクレイピング対策を回避し、動的なコンテンツを読み込み、ウェブページからデータを抽出します。ヘッドレスブラウザは、複雑なフロントエンドレンダリングを伴うスクレイピングタスクに最適です。 - ネットワーク監視とパフォーマンステスト
ネットワークリクエストを監視し、ロード時間を分析し、パフォーマンスのボトルネックを特定します。これは、ウェブサイトのパフォーマンス最適化に役立ちます。 - Ajaxリクエストの処理
データの読み込みにAjaxに依存しているページが正しく表示されるように、これらのリクエストを取得して処理します。 - ウェブページのスクリーンショットの生成
テスト中のレイアウトやコンテンツの問題を特定したり、ドキュメントを生成したり、ウェブページの視覚的なチェックを実行したりするために、スクリーンショットを作成します。
まとめ
素晴らしい一日でした!ヘッドレスブラウジングの船を停泊させると、ウェブ自動化とデータ抽出の革命の最前線にいることが明らかになりました。
ヘッドレスブラウザテストは、ブラウザでウェブアプリケーションをテストするための、より高速で、より信頼性が高く、より効率的な方法です。ただし、実際のデスクトップブラウザでテストを行うと、ウェブサイトの真の姿が示されます。
同時にヘッドレスで現実的であることはできますか?もちろんできます!Scrapelessスクレイピングブラウザは、両方の長所を兼ね備えています。ウェブページを簡単に自動化できます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


