
最高のGoogle検索スクレイパーとSERP API - Google検索結果スクレイパー
Senior Web Scraping Engineer
SERPはSEOとブランド認知度分野で一般的に使用される業界用語であり、各検索結果のランキングを表します。しかし、これらの結果をGoogleの検索ページからどのようにクロールするのでしょうか?
Googleは多くの難読化と反クロール技術を使用しているため、Googleの検索結果データを直接クロールすることは非常に困難です。URLフォーマット、動的HTMLパース、クロールブロックの回避など、いくつかの技術的な点を掘り下げる必要があります。
この記事では、Google SERPを多角的に分析し、Googleの検索結果をできるだけ早くクロールするお手伝いをします!
スクロールを続けて、最高のGoogle SERPスクレイパーを今すぐ入手しましょう!
Google SERP:概要
WebスクレイピングでGoogleの検索結果について議論する際は、「SERP」という略語によく出会うでしょう。SERPはSearch Engine Results Page(検索エンジン結果ページ)の略です。これは、検索バーにクエリを入力した後に表示されるページです。Google SERPには6つの主要なカテゴリがあります。
- 強調スニペット
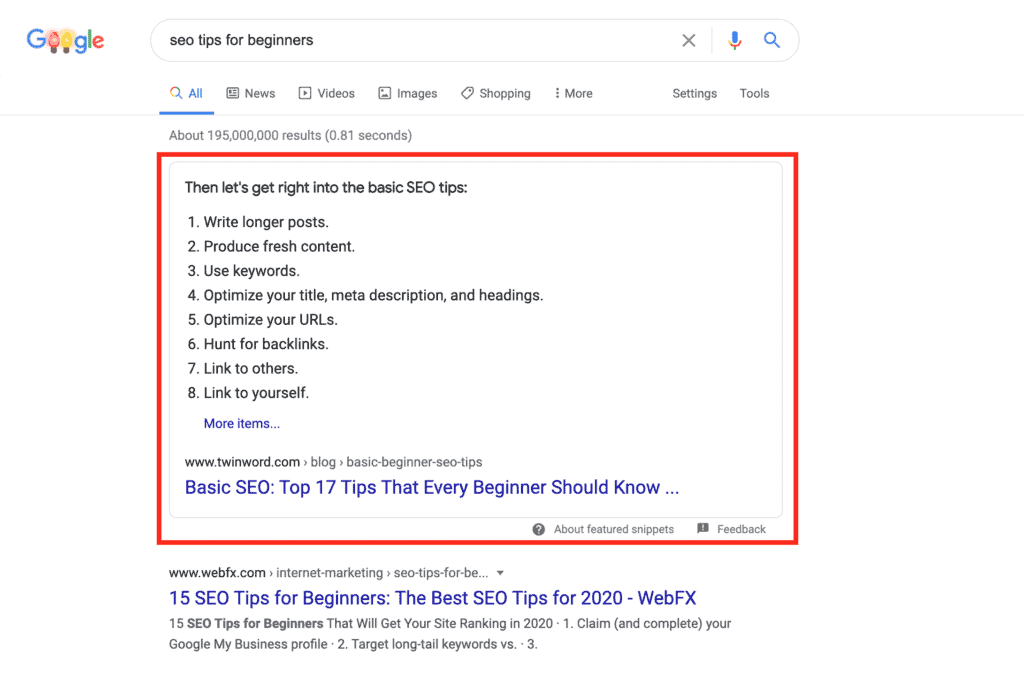
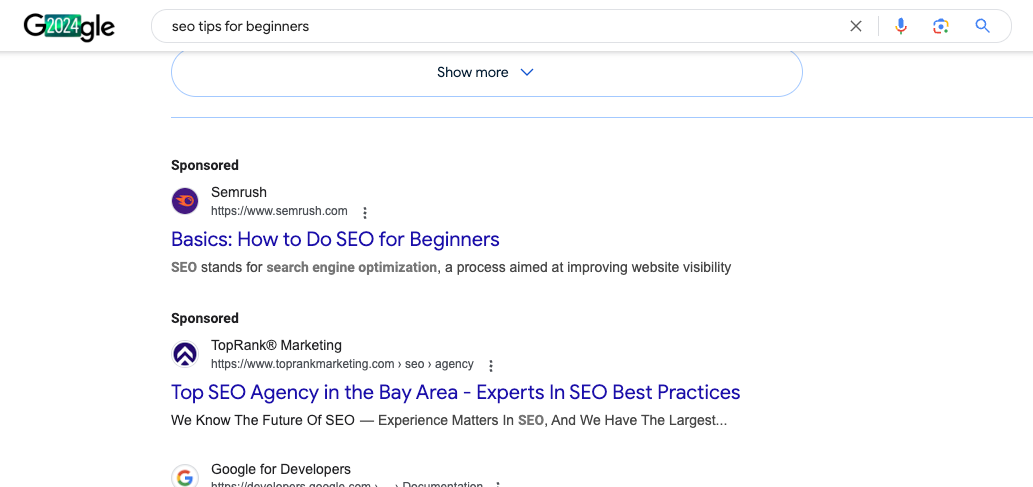
- 有料広告
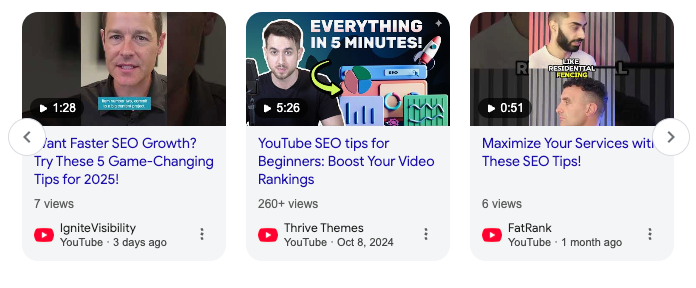
- 動画カルーセル
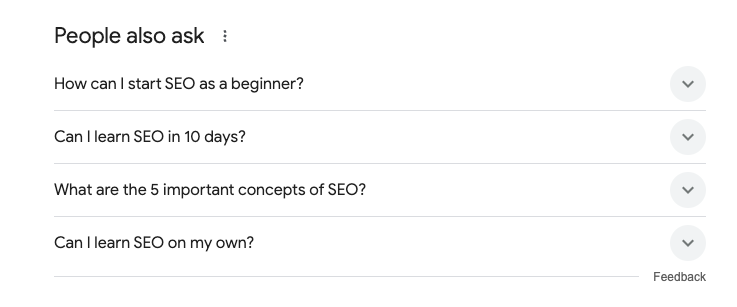
- 関連性の高い質問
- ローカルパック
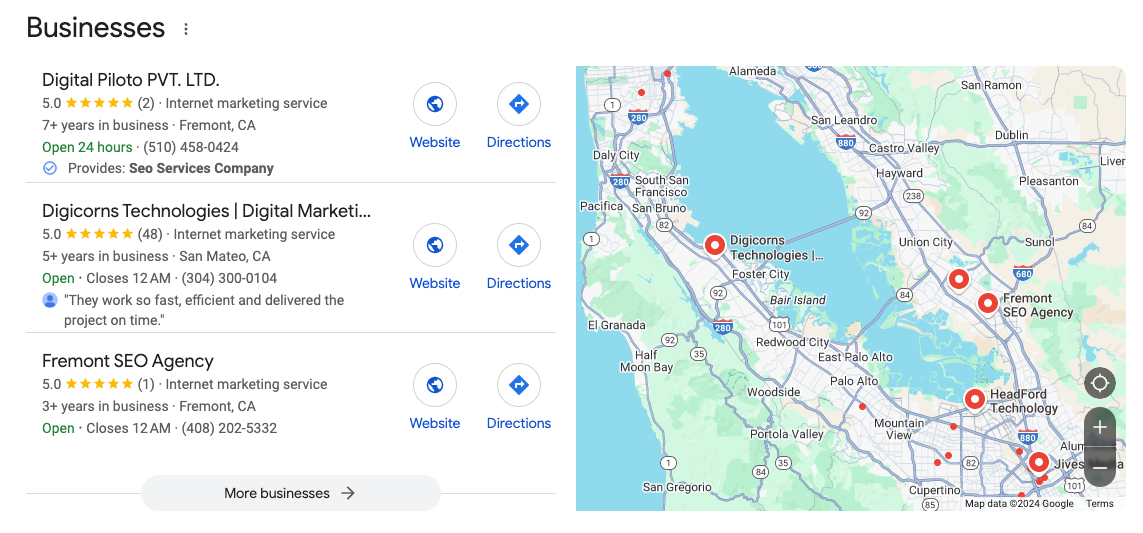
- 関連検索
Googleスクレイパーとは?
Google SERPスクレイパーは、Googleの検索エンジン結果ページ(SERP)からデータを抽出するために使用されるツールまたはソフトウェアです。このデータには、特定のクエリに対して表示される結果に関する情報が含まれており、タイトル、URL、説明、強調スニペット、広告、関連検索などの要素が含まれます。
なぜGoogleの検索結果をスクレイピングするのですか?
Googleは、ほとんどの公開Webページをインデックスに登録しているため、Google検索をクロールすることで、豊富なデータセットにアクセスできます。市場トレンド分析、消費者行動の洞察、大規模な調査作業など、このアプローチは幅広い可能性を提供します。
一方、SEOも企業がGoogle検索をクロールする重要なユースケースの1つです。検索結果を分析することで、企業は以下を行うことができます。
- 競合他社が高順位を獲得しているキーワードを特定する。
- 独自のランキングパフォーマンスを評価する。
- 市場需要に応じてコンテンツ戦略を最適化し、可視性を向上させる。
さらに、Googleのスニペットシステム(ナレッジグラフや強調スニペットなど)は、権威のある情報源(IMDbやWikipediaなど)からの情報を統合しています。Googleの検索結果からこのデータをクロールして、構造化され簡素化された重要な情報を直接取得することで、元のデータソースからの手動抽出の作業負荷を軽減できます。
Googleの検索結果をスクレイピングすることは合法ですか?
Googleの検索結果をスクレイピングすることは、Googleのサービス利用規約に違反します。Googleは、サービスへの自動アクセスを明示的に禁止しています。具体的には、Googleの規約には次のように記載されています。
「Googleの明示的な書面による許可なしに、ロボット、スパイダー、クロールなどの自動ツールを使用してサービスにアクセスすることはできません。」
しかし、心配しないでください!Scrapeless SERP APIを使用すれば、合法的にGoogleの検索データを取得できます。
Google SERPスクレイピング時の課題
- 反スクレイピング対策: Googleは、CAPTCHA、IPブロック、レート制限を使用して、自動クロールを防止しています。
- 動的コンテンツ: GoogleはJavaScriptを通じて動的にコンテンツをロードし、クロールはこれらの動的要素を処理する必要があります。
- SERPレイアウトの変更: Googleは検索結果ページを絶えず更新しているため、クロールスクリプトが失敗する可能性があります。
- 法的および倫理的な問題: スクラピングはGoogleのサービス利用規約に違反し、法的リスクに直面する可能性があります。
- データ抽出の複雑さ: 広告や強調スニペットなどのSERPの動的要素により、データ抽出の難易度が高まります。
Scrapeless SERP API - 最高のGoogle SERPスクレイパー
SEOとデジタルマーケティングの競争の激しい世界では、正確で信頼性の高いGoogle SERPデータへのアクセスが不可欠です。そこで登場するのがScrapeless SERP APIです。これは、データ抽出の取り組みを合理化するために設計された、強力で手頃な価格で非常に効率的なツールです。
**1,000 URLあたりわずか1ドル(購読でさらに割引)**から、競争力のある価格に驚かれること間違いなしです。透明性の高い価格プランと従量制オプションにより、Scrapelessでは使用した分だけ料金を支払うことができます。
Scrapeless SERP APIが効果的な理由
Scrapelessは、Googleの検索エンジン結果ページ(SERP)のスクレイピングの課題に対処するために特別に構築されています。高度な不正検知メカニズム、高速パフォーマンス、非常に高い成功率により、Scrapelessはデータ収集が中断や禁止なしにスムーズに実行されるようにします。
キーワードランキングの追跡、競合他社の監視、市場情報の収集を行う場合でも、Scrapelessは常に正確な結果を提供します。
ScrapelessスクレイピングAPIの利点
- 手頃な価格: Scrapelessは、優れた価値を提供するように設計されています。
- 安定性と信頼性: 実績のあるScrapelessは、高いワークロード下でも安定したAPIレスポンスを提供します。
- 高い成功率: 失敗した抽出に別れを告げ、ScrapelessはGoogle SERPデータへの99.99%の成功率アクセスを約束します。
- スケーラビリティ: Scrapelessを支える堅牢なインフラストラクチャのおかげで、数千のクエリを簡単に処理できます。
Scrapeless Google検索APIの使い方
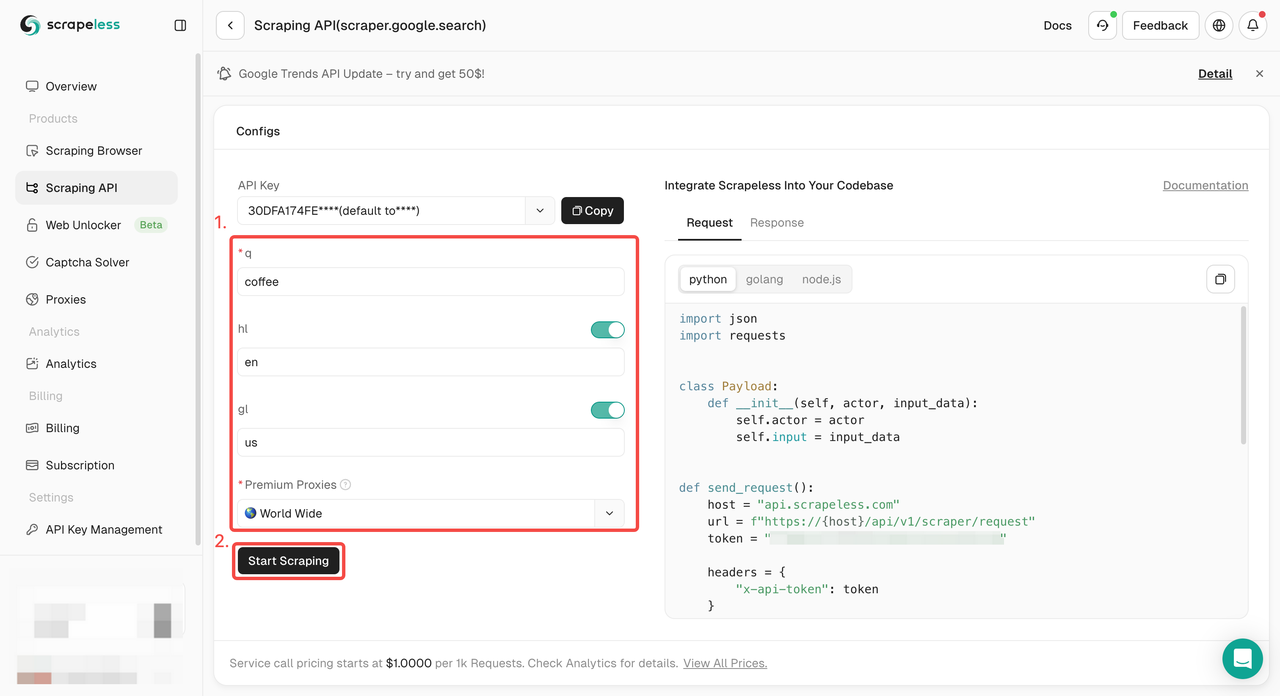
ステップ1. Scrapelessダッシュボードにログインし、「Google検索API」に進みます。
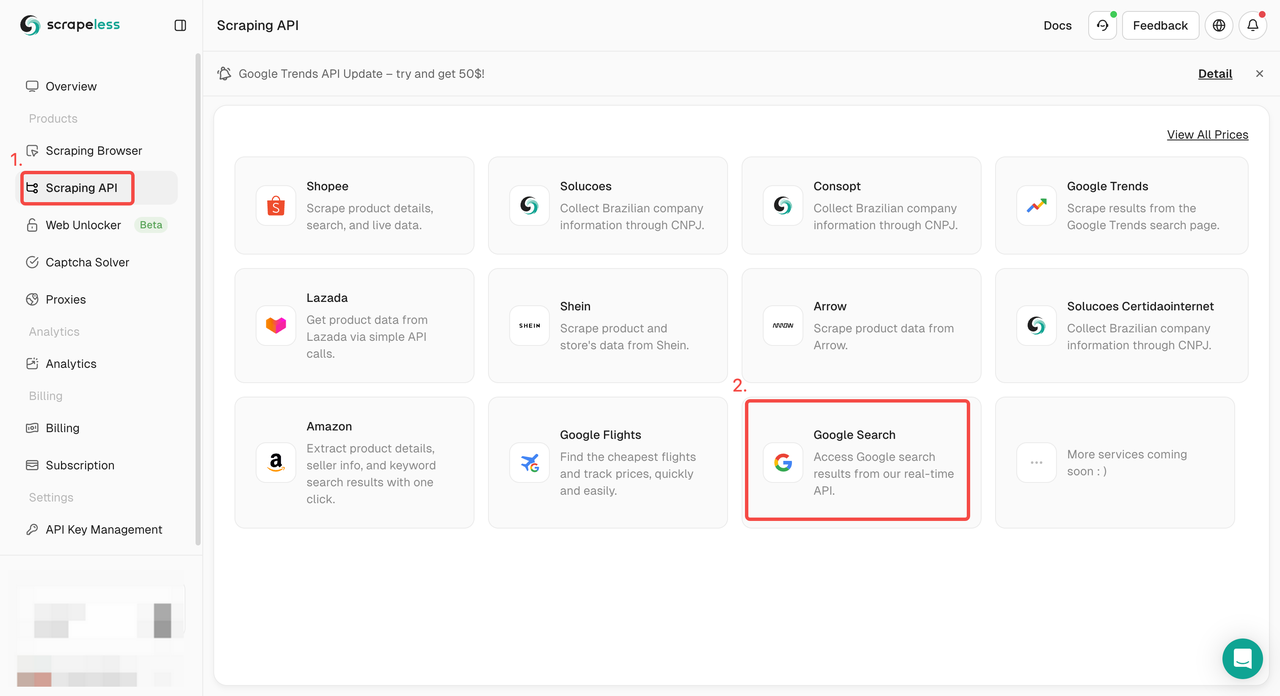
ステップ2. 左側で、必要なキーワード、地域、言語、プロキシなどの情報を設定します。すべてが問題ないことを確認したら、「スクレイピング開始」をクリックします。
q:検索するクエリを定義するパラメータ。gl:Google検索に使用する国を定義するパラメータ。hl:Google検索に使用する言語を定義するパラメータ。
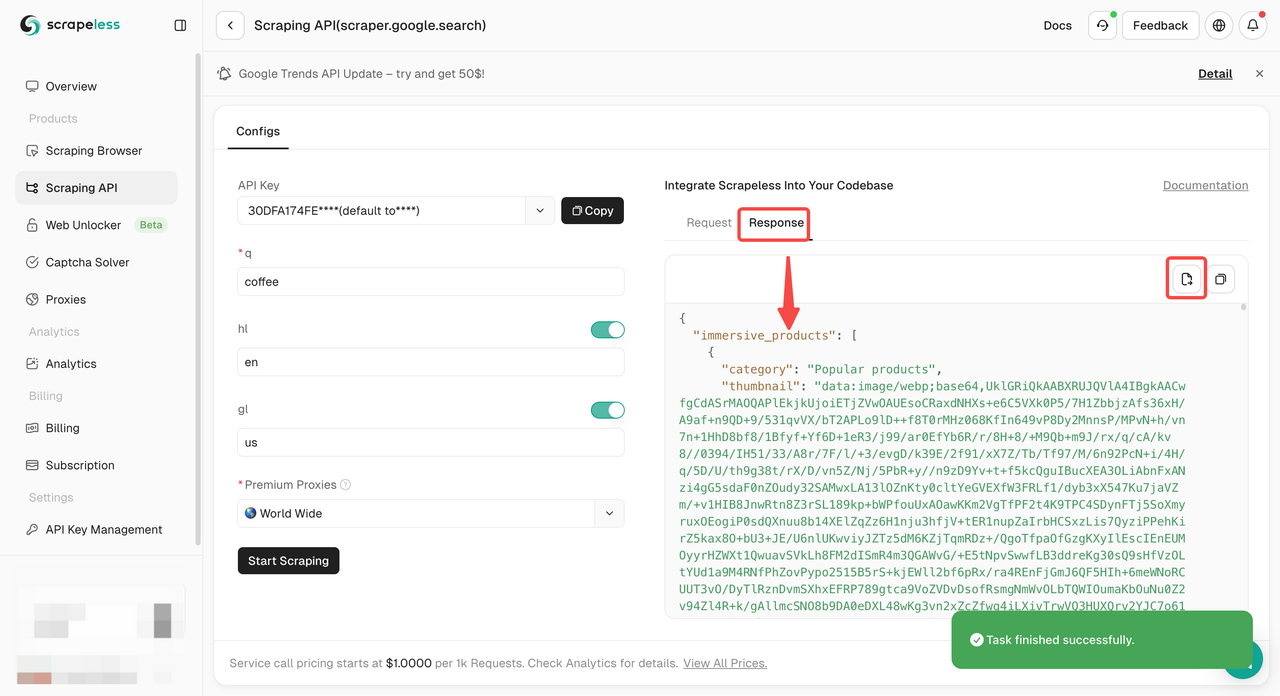
ステップ3. クロール結果を取得してエクスポートします。
プロジェクトに統合するためのサンプルコードが必要ですか?ご用意しております!または、必要な言語のAPIドキュメントをご覧ください。
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang:
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}5つの一般的なGoogle SERPスクレイピングAPI
1. Google Flights
Google Flights APIを使用すると、航空券の価格、ルート、空席状況など、Google Flightsのフライトデータにアクセスできます。旅行関連のサービスやアプリケーションのために、企業や開発者がフライト情報を集約および分析するのに役立ちます。
2. Google Maps
Google Maps APIは、地図、場所の詳細、地理情報など、地理位置データへのアクセスを提供します。このAPIを使用すると、場所、レビュー、住所に関するデータをスクレイピングして、位置情報ベースのアプリケーションやサービスを構築できます。
3. Google ニュース
Google ニュースAPIを使用すると、Google ニュースからのリアルタイムのニュース記事や見出しにアクセスできます。これは、現在の出来事を監視し、特定のトピックを追跡し、分析や集約のためにニュースデータを収集するのに最適です。
4. Google ショッピング
Google ショッピングAPIを使用すると、価格、説明、在庫状況など、Google ショッピングからのeコマース製品リストをスクレイピングできます。製品比較サイト、市場調査、価格追跡に最適です。
5. Google レンズ
Google レンズAPIは画像認識機能を提供し、オブジェクト、ランドマーク、テキストなどをスクレイピングおよび分析できます。このAPIは、高度な画像処理と認識機能を備えたアプリを構築するのに役立ちます。
まとめ
このチュートリアルでは、以下について詳しく説明しました。
- Google SERPとは何か、そしてGoogle SERPの利点。
- Google SERPをスクレイピングする方法。
Google SERPクロールが直面する最大の課題は、複雑なHTMLページのパース、IPバンとCAPTCHAの確認の3つのカテゴリに分類できます。
データ収集の課題に遅れを取らないようにしましょう!Scrapeless SERP APIを選択して、すべてのGoogle SERPスクレイピングニーズに対する費用対効果が高く、安定した高性能なソリューションを実現しましょう。
さあ、始めましょう!
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


