
PythonでGoogle Scholarをスクレイピングする方法
Expert Network Defense Engineer
Google Scholarは、学術データにアクセスするための検索エンジンです。Google Scholarを使用すると、科学論文、研究論文、学位論文を取得できます。しかし、学術研究では、Google Scholarの検索結果から大量のデータを収集して分析することがよくあります。
無数の結果を手動で精査することは、大変な作業です。だからこそ、信頼できるGoogle Scholarスクレイパーが、このプロセスを容易にするのに役立ちます。自動化により、Google Scholarをスクレイピングして、Google Scholarページの各結果からタイトル、著者、引用などのデータを数秒で抽出できます。
このチュートリアルでは、Scrapeless Google Scholar APIとPythonを使用してHTTPリクエストを行うことで、効果的なGoogle Scholarスクレイパーを構築する方法を学習します。
詳細については、スクロールを続けてください!
🎓 Google Scholarスクレイパーとは?
Google Scholarスクレイパーは、研究論文、引用、著者、出版詳細など、Google Scholarから公開されている学術データを抽出するように設計されたツールです。研究者、学者、組織が、分析、トレンド追跡、学術研究のために貴重な洞察を収集することを可能にします。ただし、Google Scholarの堅牢な反スクレイピングメカニズムにより、Google Scholarのウェブスクレイピングには大きな課題が伴います。
なぜGoogle Scholarのデータは貴重なのか?
- レビューと研究: 学術研究やプロジェクトに関連する論文、記事、論文、書籍を見つけます。さまざまな方法や理論的枠組みを比較します。
- 学術分析: 学術出版物における新たなトレンドやトピックを特定し、H指数や被引用回数などの学術指標を計算します。
- 潜在的な共同研究: 特定分野の専門家を特定し、潜在的な共同研究、会議、または査読のために活用します。
- 製品開発: 研究開発の専門家は、Google Scholarをスクレイピングして、詳細な研究、画期的な発見、関連する科学技術分野における競合他社の出版物を追跡することができます。
Google Scholarクローリングの課題と解決策
Google Scholarは、多数の学術論文、特許、書籍、会議論文を提供する強力な学術検索エンジンです。しかし、Google Scholarデータをスクレイピングするには、多くの技術的および法的課題があります。Google Scholarのウェブスクレイピングで発生する可能性のある主な問題とその解決策を以下に示します。
| 課題 | 説明 | 解決策 |
|---|---|---|
| IPブロック | 頻繁なリクエストによりIPブロックが発生します。 | プロキシを使用します。メインのIPがブロックされないように、複数のIPアドレスをローテーションします。 |
| CAPTCHA | Googleは、ユーザーが人間であることを確認するためにCAPTCHAの入力を求める場合があります。 | CAPTCHAを自動的に解決できるサービスを選択してください。 |
| リクエストレート制限 | 過剰なリクエストレートが検出され、ブロックされます。 | ユーザーエージェントを変更し、リクエスト間で数秒間待機して、人間の行動を模倣します。 |
| 動的コンテンツの読み込み | Google ScholarはJavaScriptを使用して動的にコンテンツを読み込みます。 | PuppeteerやSeleniumなどのヘッドレスブラウザを使用してJavaScriptをレンダリングし、コンテンツを抽出します。 |
さらに、Google ScholarのスクレイピングにはAPI制限があります。Google Scholarには公式APIがないため、Google Scholarのウェブスクレイピングではウェブページを直接解析する必要があり、複雑さと不安定性が増加します。
幸いなことに、強力なサードパーティのAPIサービスを使用できます。それらは、便利で高速で正確なデータ抽出を保証します。さらに、多くのAPIサービスプロバイダーの中でも、ScrapelessにはCAPTCHAデコードサービス、ローテーションプロキシ、Webアンロッカーが組み込まれています。
ステップバイステップ:Python Google Scholarスクレイパーの構築
次に、Python Google Scholarスクレイパーを使用してGoogle Scholarのクロールを開始します。記事のタイトル、出版情報、記事のタイトルなどのデータの取得方法を確認できます。
ステップ1. 環境の設定
Python: ソフトウェアhttps://www.python.org/downloads/は、Pythonを実行するためのコアです。以下に示すように、公式ウェブサイトから必要なバージョンをダウンロードできます。ただし、最新バージョンをダウンロードすることはお勧めしません。最新バージョンより前の1.2バージョンをダウンロードできます。
Python IDE: PythonをサポートするIDEであればどれでも機能しますが、PyCharmをお勧めします。これはPython用に特別に設計された開発ツールです。PyCharmのバージョンについては、無料のPyCharm Community Editionをお勧めします。
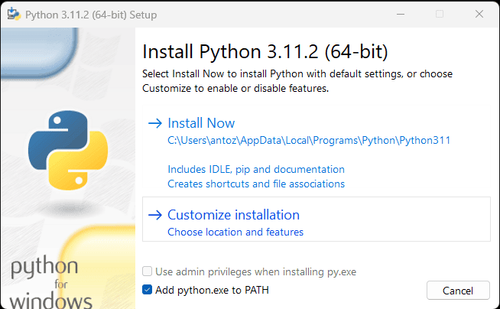
注記: Windowsユーザーの場合は、インストールウィザード中に「Add python.exe to PATH」オプションを必ず選択してください。これにより、WindowsはターミナルでPythonとコマンドを使用できるようになります。Python 3.4以降にはデフォルトで含まれているため、手動でインストールする必要はありません。
これで、ターミナルまたはコマンドプロンプトを開いて次のコマンドを入力することで、Pythonがインストールされているかどうかを確認できます。
Bash
python --versionステップ2. 依存関係のインストール
プロジェクトの依存関係を管理し、他のPythonプロジェクトとの競合を回避するために、仮想環境を作成することをお勧めします。ターミナルでプロジェクトディレクトリに移動し、次のコマンドを実行してgoogle_scholar_envという名前の仮想環境を作成します。
Bash
python -m venv google_scholar_envシステムに基づいて仮想環境をアクティブ化します。
- Windows:
Bash
google_scholar_env\Scripts\activate- MacOS/Linux:
Bash
source google_scholar_env/bin/activate仮想環境をアクティブ化した後、ウェブスクレイピングに必要なPythonライブラリをインストールします。Pythonでrequestsを送信するためのライブラリはrequestsであり、データをスクレイピングするための主なライブラリはBeautifulSoup4です。次のコマンドを使用してインストールします。
Bash
pip install requests
pip install beautifulsoup4ステップ3. データのスクレイピング
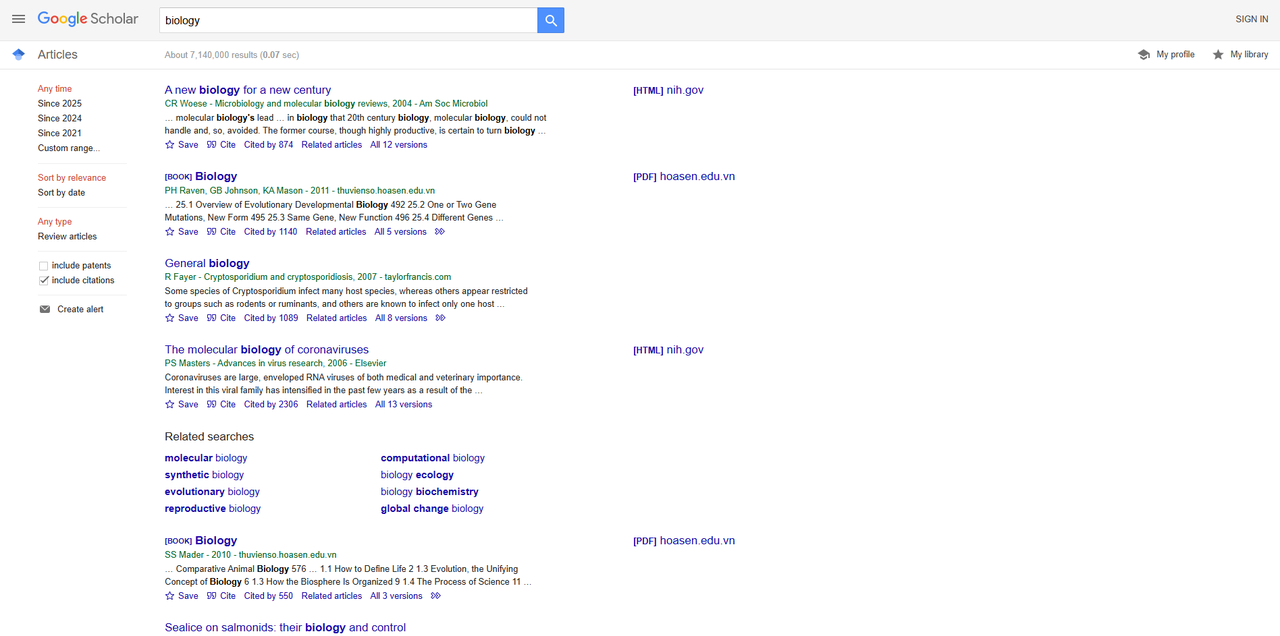
ブラウザでGoogle Scholarを開き、「biology」を検索します。検索結果を以下に示します。
- タイトルのスクレイピング:
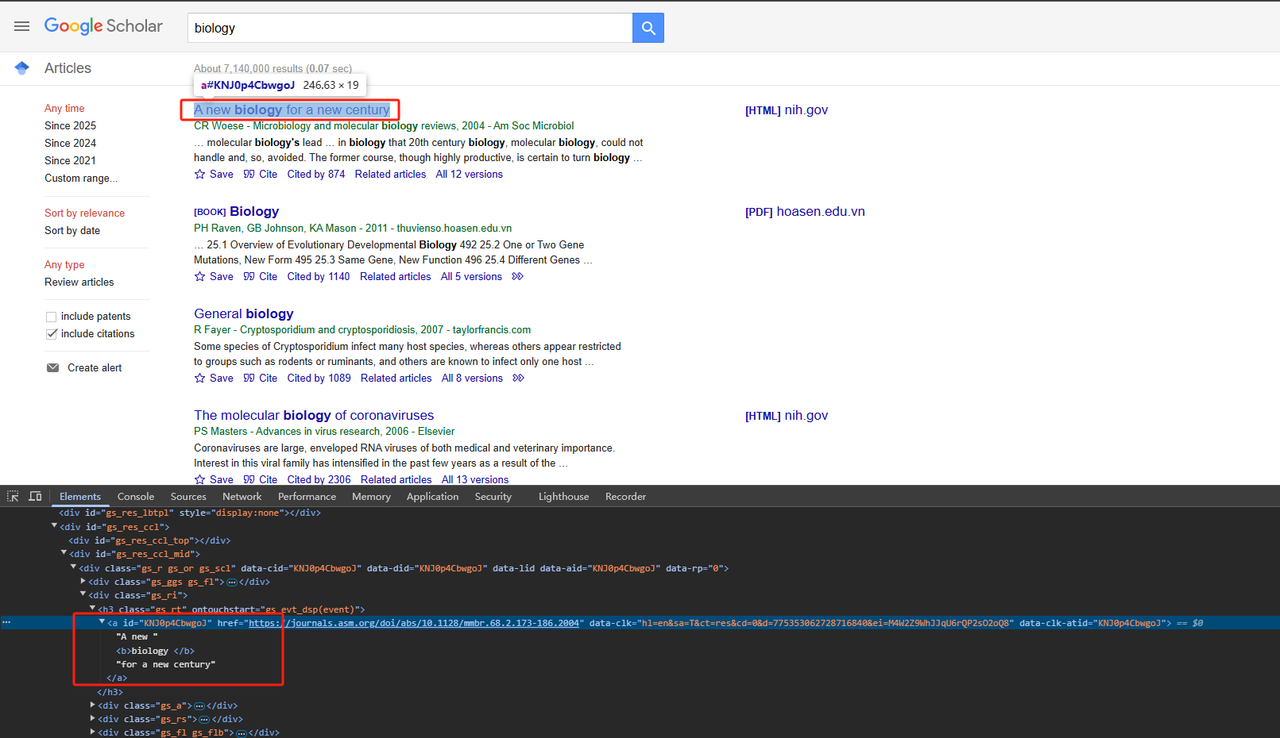
関連するHTMLページ要素を解析します。詳細なPythonコードは以下のとおりです。
Python
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt a')
return title_element .text.strip()- 出版情報のスクレイピング:
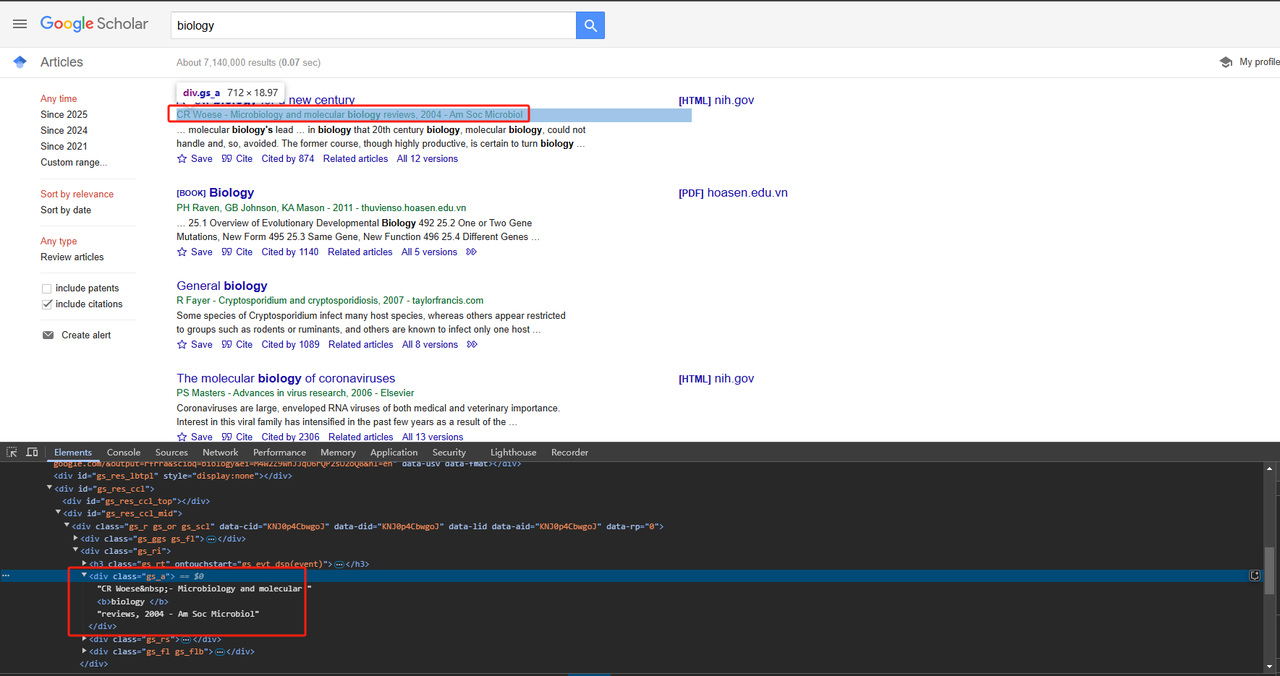
divクラス属性を使用して、出版情報を直接スクレイピングできます。詳細なPythonコードは以下のとおりです。
Python
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
return publication_info_element .text.strip()- 記事スニペットのスクレイピング:
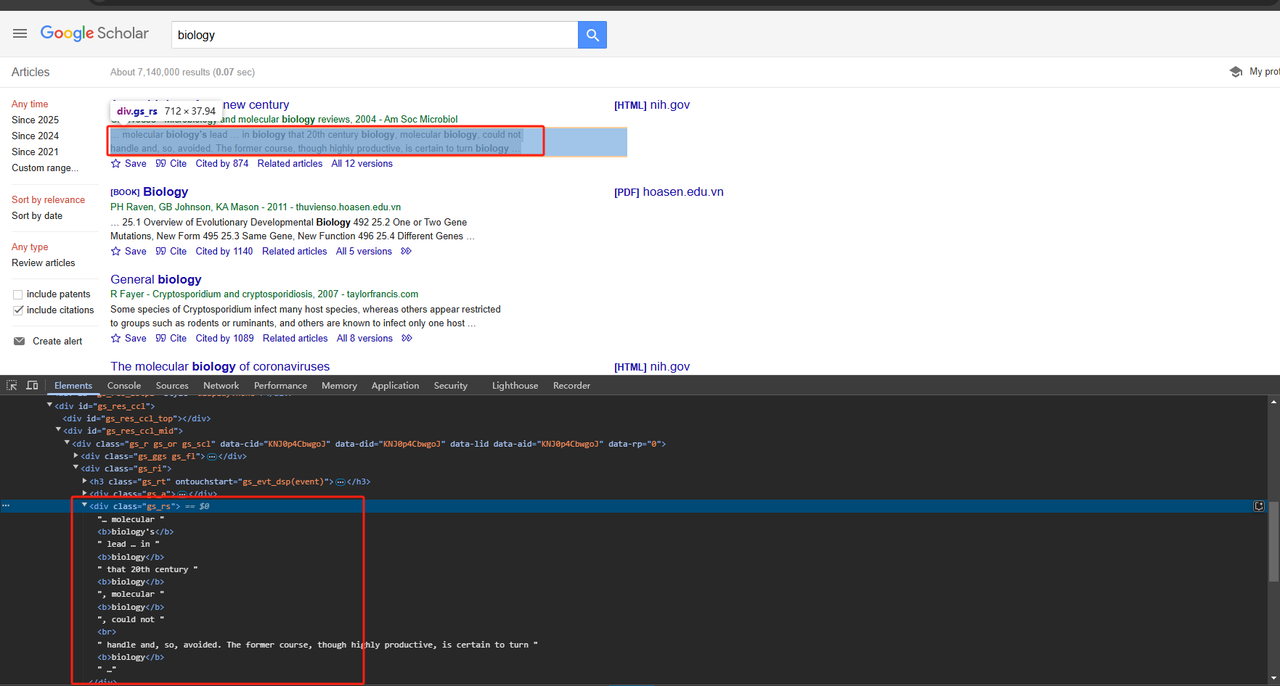
divクラス属性を使用して、記事スニペットも直接スクレイピングできます。詳細なPythonコードは以下のとおりです。
Python
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
return snippet_element .text.strip()ページ上の1つだけでなく、すべてのデータをスクレイピングする必要があるため、上記のデータをループしてスクレイピングする必要があります。完全なコードは以下のとおりです。
Python
# 必要なライブラリのインポート
import time
import requests
from bs4 import BeautifulSoup
import json
# google_scholarからリスト要素をスクレイピングする関数
def scrape_listings(soup):
return soup.select('div.gs_r.gs_or.gs_scl')
# google_scholarからタイトルをスクレイピングする関数
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt > a')
print(title_element.text)
return title_element.text.strip()
# google_scholarからpublication_infoをスクレイピングする関数
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
print(publication_info_element.text)
return publication_info_element.text.strip()
# google_scholarからスニペットをスクレイピングする関数
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
print(snippet_element.text)
return snippet_element.text.strip()
# メイン関数
def main():
# google_scholar URLへのリクエストを行い、HTMLを解析します
url = 'https://scholar.google.com/scholar?hl=en&q=biology'
response = requests.get(url, verify=False)
time.sleep(2)
soup = BeautifulSoup(response.text, 'html.parser')
# scholarリストのスクレイピング
listings = scrape_listings(soup)
print(listings)
# 各リストを反復処理し、scholar情報を抽出します
scholar_data = []
for listing in listings:
title = scrape_scholar_title(listing)
publication_info = scrape_scholar_publication_info(listing)
snippet = scrape_scholar_snippet(listing)
# scholar情報を辞書に格納します
scholar_info = {
'title': title,
'publication_info': publication_info,
'snippet': snippet
}
scholar_data.append(scholar_info)
# 結果をJSONファイルに保存します
with open('google_scholar_data.json', 'w') as json_file:
json.dump(scholar_data, json_file, indent=4)
if __name__ == "__main__":
main()ステップ4. 結果の出力
PyCharmディレクトリにgoogle_scholar_data.jsonという名前のファイルが生成されます。出力は以下のとおりです。
JSON
[
{
"title": "A new biology for a new century",
"publication_info": "CR Woese\u00a0- Microbiology and molecular biology reviews, 2004 - Am Soc Microbiol",
"snippet": "\u2026 molecular biology's lead \u2026 in biology that 20th century biology, molecular biology, could not \nhandle and, so, avoided. The former course, though highly productive, is certain to turn biology \u2026"
},
{
"title": "Biology",
"publication_info": "PH Raven, GB Johnson, KA Mason - 2011 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 25.1 Overview of Evolutionary Developmental Biology 492 25.2 One or Two Gene \nMutations, New Form 495 25.3 Same Gene, New Function 496 25.4 Different Genes\u00a0\u2026"
},
{
"title": "General biology",
"publication_info": "R Fayer\u00a0- Cryptosporidium and cryptosporidiosis, 2007 - taylorfrancis.com",
"snippet": "Some species of Cryptosporidium infect many host species, whereas others appear restricted \nto groups such as rodents or ruminants, and others are known to infect only one host \u2026"
},
{
"title": "The molecular biology of coronaviruses",
"publication_info": "PS Masters\u00a0- Advances in virus research, 2006 - Elsevier",
"snippet": "Coronaviruses are large, enveloped RNA viruses of both medical and veterinary importance. \nInterest in this viral family has intensified in the past few years as a result of the \u2026"
},
{
"title": "Biology",
"publication_info": "SS Mader - 2010 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 Comparative Animal Biology 576 \u2026 1.1 How to Define Life 2 1.3 Evolution, the Unifying \nConcept of Biology 6 1.3 How the Biosphere Is Organized 9 1.4 The Process of Science 11\u00a0\u2026"
},
{
"title": "Sealice on salmonids: their biology and control",
"publication_info": "AW Pike, SL Wadsworth\u00a0- Advances in parasitology, 1999 - Elsevier",
"snippet": "\u2026 This review examines the voluminous literature on the biology and control of sealice and \nbrings together ideas for developing our knowledge of these organisms. Research on the \u2026"
},
{
"title": "Biology data book",
"publication_info": "PL Altman, DS Dittmer - 1972 - bionumbers.hms.harvard.edu",
"snippet": "Embryos were raised at constant temperature in circulating nalis\" u 10% smaller. For \nadditional information on salmowater, from three hours after fertilization. Age= time from nids, \u2026"
},
{
"title": "The biology of Pseudocalanus",
"publication_info": "CJ Corkett, IA McLaren\u00a0- Advances in marine biology, 1979 - Elsevier",
"snippet": "Publisher Summary Pseudocalanus is typical of most crustaceans in that after hatching at \nan early stage of development it adds successively new segments and appendages. \u2026"
},
{
"title": "Introduction to a submolecular biology",
"publication_info": "A Szent-Gyorgyi - 2012 - books.google.com",
"snippet": "\u2026 Biology is the science of the improbable and I think it is on principle that the body works \nonly with reactions which are statistically improbable. If metabolism were built of a series of \u2026"
},
{
"title": "The biology of mycorrhiza.",
"publication_info": "JL Harley - 1959 - cabidigitallibrary.org",
"snippet": "Since Dr. Rayner published her book on mycorrhiza in 1927 there has not been a comprehensive \naccount of this subject, although the need for a critical re-appraisal of the extensive \u2026"
}
]Scrapeless Google Scholar APIを簡単に展開
なぜScrapeless Scholar APIが重要なのか?
もちろん!手頃な価格で、安定していて安全なAPIサービスが必要なだけです。しかし、これらの基準をすべて満たすものを見つけるのは非常に困難です!幸いにも、Scrapeless Google Scholar APIは、多くのAPI製品の中でも際立っています。
- 🔴 コスト削減: Google Scholar APIはわずか0.80ドルで、49ドルのサブスクリプションでは10%の割引が受けられます!
- 🔴 正確なデータ: 開発者は、Googleのスクレイピングアルゴリズムと制限を継続的に分析して、APIが更新され、最適化されていることを確認します。
- 🔴 安定性と高い成功率: Scrapelessは99%の成功率と信頼性を保証します。Googleトレンドのスクレイピングの安定性と精度はほぼ100%に達しました!現在、平均応答時間は約3秒で、ほとんどのAPIプロバイダーよりもはるかに高速です。さらに、データは標準化されたJSON形式で返されるため、すぐに使用できます。
Scrapelessはすでに2,000人以上のエンタープライズユーザーの信頼を獲得しています!今すぐDiscordに参加して無料トライアルを獲得しましょう! 期間限定で1,000席のみ—お早めに!
さらに読む:
使用手順:
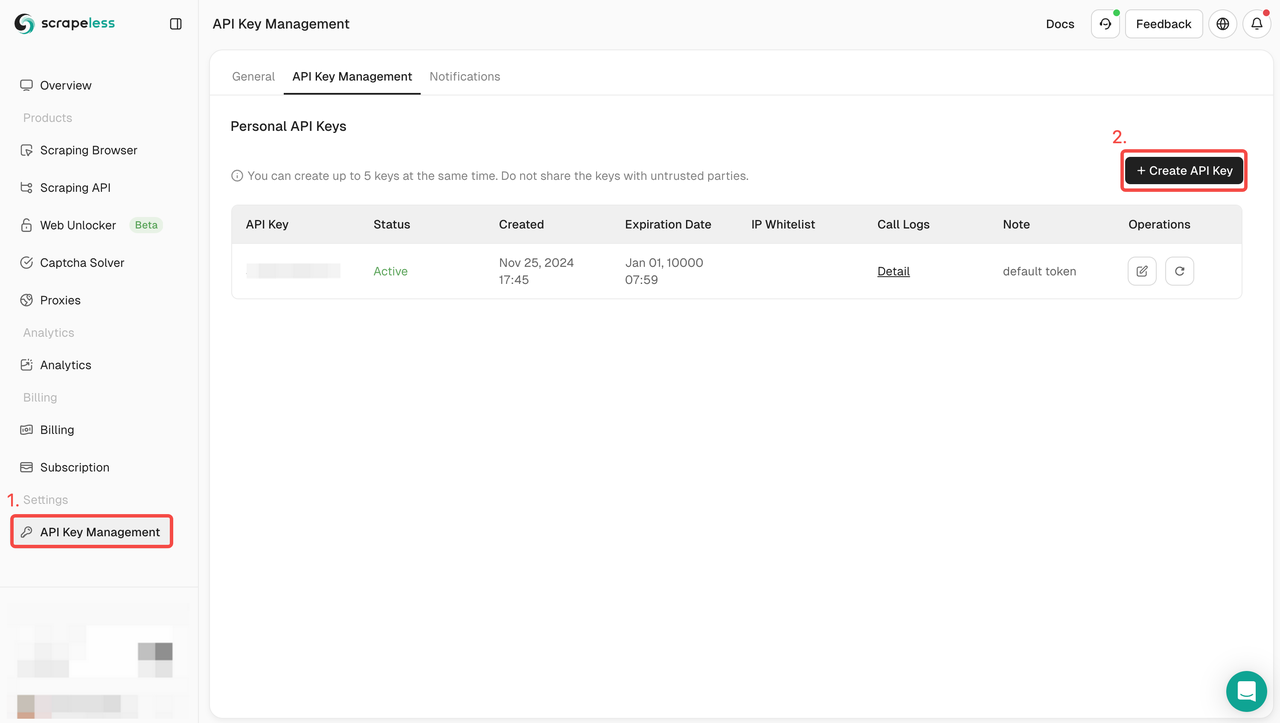
ステップ1. APIトークンの取得
- ダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、独自のAPIキーを生成します。
- APIキーをクリックしてコピーするだけです。
ステップ2:コードでAPIキーを使用する
必要なGoogle Scholarデータをスクレイピングするには、APIドキュメントのパラメーターを設定するだけです。
- APIドキュメントにアクセスします。
- 目的のエンドポイントで「試してみる」をクリックします。
- コード本体に必要なパラメーターを設定します。
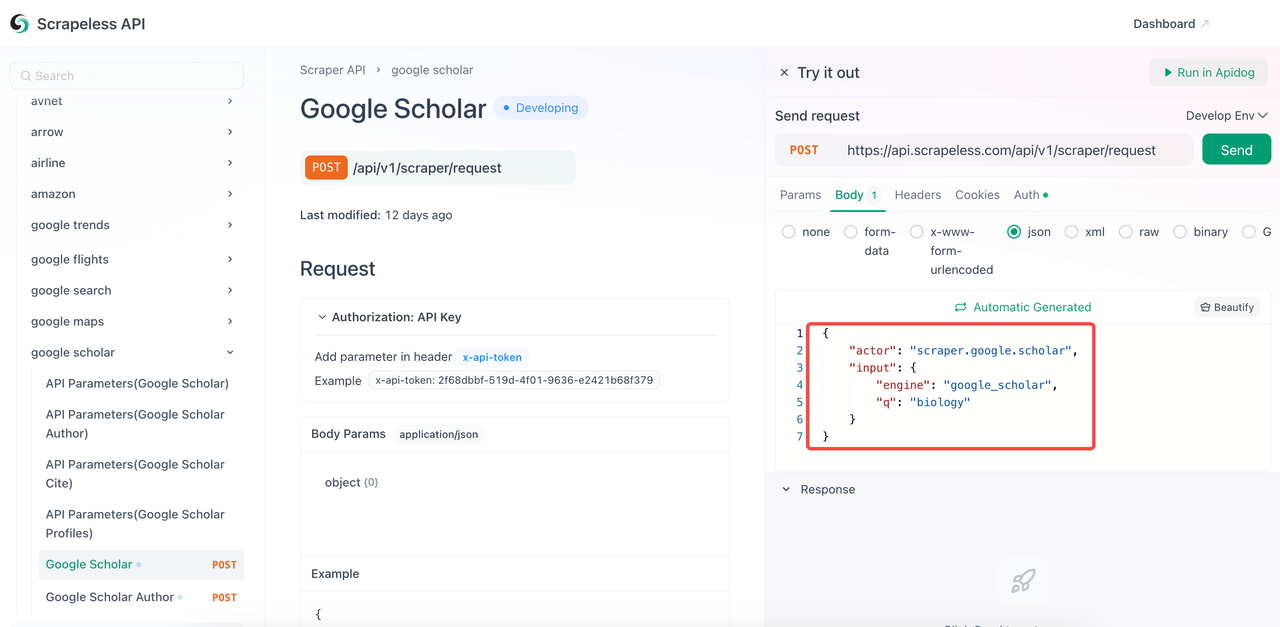
- キーワード
qをクエリしたいものに変更します。 engineパラメーターは必須であり、その値はgoogle_scholarでなければなりません。ただし、google_scholar_authorなど、より具体的なパラメーターを追加できます。- 一般的なパラメーター:
| パラメーター | 必須 | 説明 |
|---|---|---|
engine |
TRUE | このAPIを使用するにはgoogle_scholarに設定します。 |
q |
TRUE | 検索クエリ(例:「機械学習」)。 |
cites |
FALSE | 引用記事を見つけるための固有ID。 |
as_ylo |
FALSE | 特定の年から結果をフィルタリングします。 |
as_yhi |
FALSE | 特定の年までの結果をフィルタリングします。 |
hl |
FALSE | 言語設定(デフォルト:en)。 |
num |
FALSE | 結果の数(1〜20、デフォルト:10)。 |
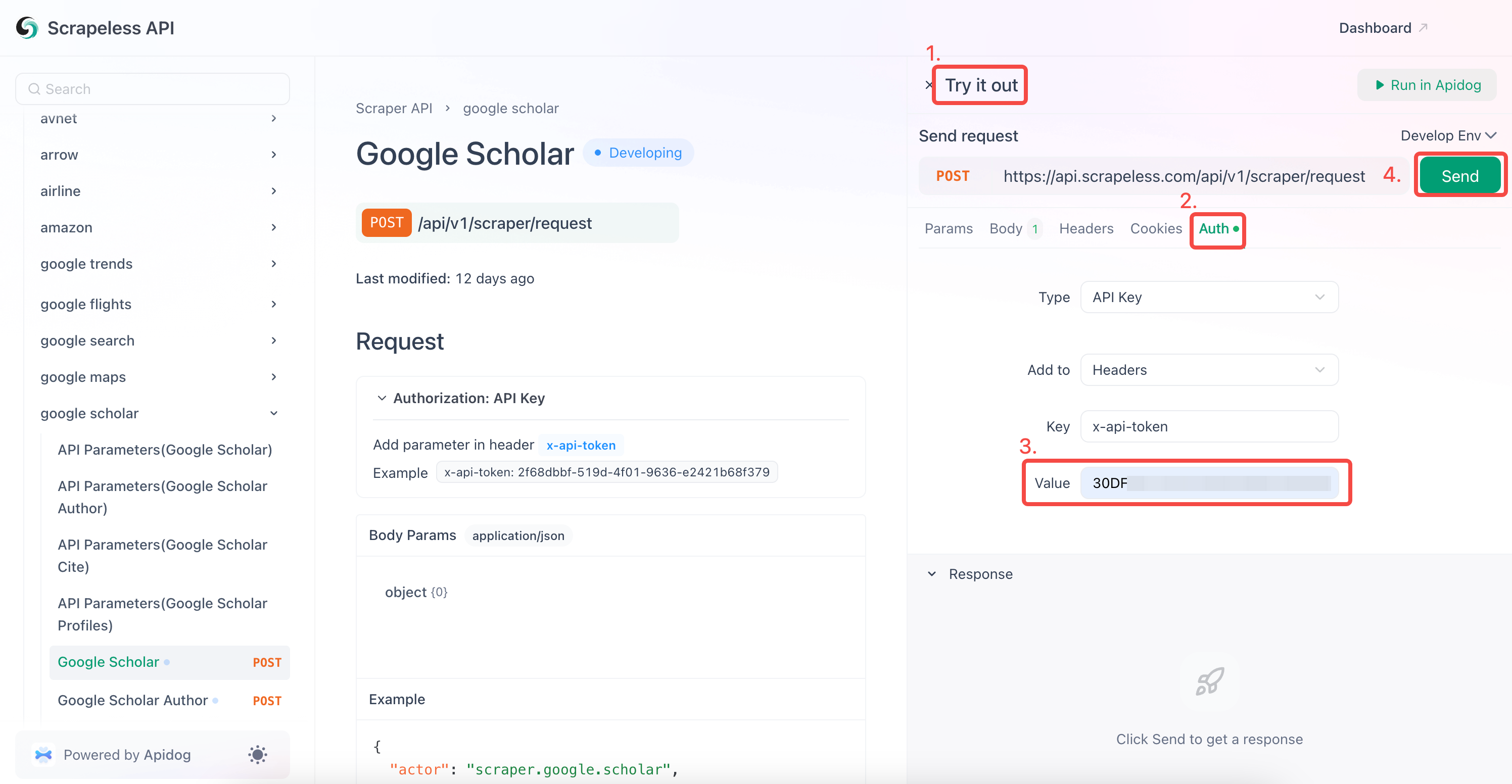
- 「認証」フィールドにAPIキーを入力します。
- 「送信」をクリックして、スクレイピング応答を取得します。
Scrapeless Google Scholarは、以下のクロールもサポートしています。
- Google Scholar Author
- Google Scholar Cite
- Google Scholar Profiles
参照コードをプログラムに直接統合することもできます。your_tokenを申請したトークンに置き換えるだけです。
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = your_token ## APIトークンに置き換えます
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar",
"q": "biology",
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()今すぐGoogle Scholarスクレイパーを構築しましょう!
Google Scholarのスクレイピングは、学術情報を抽出する優れた方法です。Google Scholarやその他の検索エンジンをスクレイピングするためのコードまたはノーコードの方法を探している場合でも、シンプルで高速なソリューションを提供します。
Scrapelessは、すべてのサービスを利用してデータ収集できる1ヶ月の無料トライアルを提供しています。Google Scholarから詳細なデータを見つける方法?Scrapelessを使用すると、非常に短時間で大量のデータを集めることができます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


