
Google Lensの商品検索結果をスクレイピングする方法
Specialist in Anti-Bot Strategies
Google Lensは、テキストの抽出や物、人、動物、植物などの識別など、画像を分析するための無料ツールです。提供された画像と類似した視覚的な一致を検索するためにも使用できます。
この強力なツールは、消費者と企業の両方にとって非常に価値があり、製品の在庫状況、価格、レビューに関する洞察を提供します。しかし、Google Lensからデータを手動で抽出することは、時間と効率の点で非効率です。
このガイドでは、Scrapeless Google Lens APIを使用してGoogle Lensの製品検索結果をスクレイピングする手順を説明し、このタスクを効果的に自動化するツールと技術を提供します。
さあ、スクロールしましょう!
Google Lensによる製品検索について
Google Lensは、高度な画像認識技術を使用して、画像内の製品を識別します。製品が認識されると、Google Lensは製品名、価格、小売業者、レビューなど、関連する結果のリストを表示します。このデータは、市場調査、価格比較、競合他社分析に不可欠です。
しかし、Google Lensの動的な性質とその潜在的なアンチスクレイピング対策により、自動データ抽出は困難です。
Google Lensスクレイピングにおける課題
- 動的コンテンツ: Google LensはJavaScriptを使用してデータを動的に読み込みます。SeleniumやPuppeteerなどのツールを使用して、スクレイパーが情報を抽出する前にすべての要素の読み込みが完了するまで待機するようにします。
- アンチスクレイピング対策: ユーザーエージェントをローテーションし、プロキシを使用して複数のIPアドレスにリクエストを分散することで、検出を回避します。
- レート制限: IPアドレスのブロックを回避するために、制御されたペースでリクエストを送信します。人間の行動を模倣するために、リクエスト間に遅延を導入します。
なぜAPIを使用する必要があるのか?
特にScrapeless Google Lens APIを使用する理由がいくつかあります。
- パース部分をゼロから作成および維持する必要がありません。
- Googleのブロックを回避します: CAPTCHAの解決またはIPブロックの解決。
- プロキシとCAPTCHAソルバーの料金を支払う必要がありません。
- ブラウザの自動化を使用する必要がありません。
Scrapeless APIはバックエンドですべてを処理し、応答時間は非常に高速で、リクエストごとに約3.3秒未満であり、ブラウザの自動化は必要ないため、はるかに高速になります。
Google Lens製品検索結果のスクレイピング方法?
最初の反応は、プログラミングを使用してクロールタスクを実行しようとするかもしれません。しかし、時間とエネルギーの制約🚫によります。ほとんどのスマートユーザーは、安価で高速なAPIを使用して複雑なデータ抽出を実行することを選択しています。これは、簡単な設定で完了できます。
当社はウェブサイトのプライバシーを堅く守ります。このブログ内のすべてのデータは公開されており、クロールプロセスのデモンストレーションのみに使用されます。いかなる情報やデータも保存しません。
前提条件
まず、Google Lens APIに接続し、google_lensソースを使用しましょう。ドキュメントに記載されている手順に従ってください。
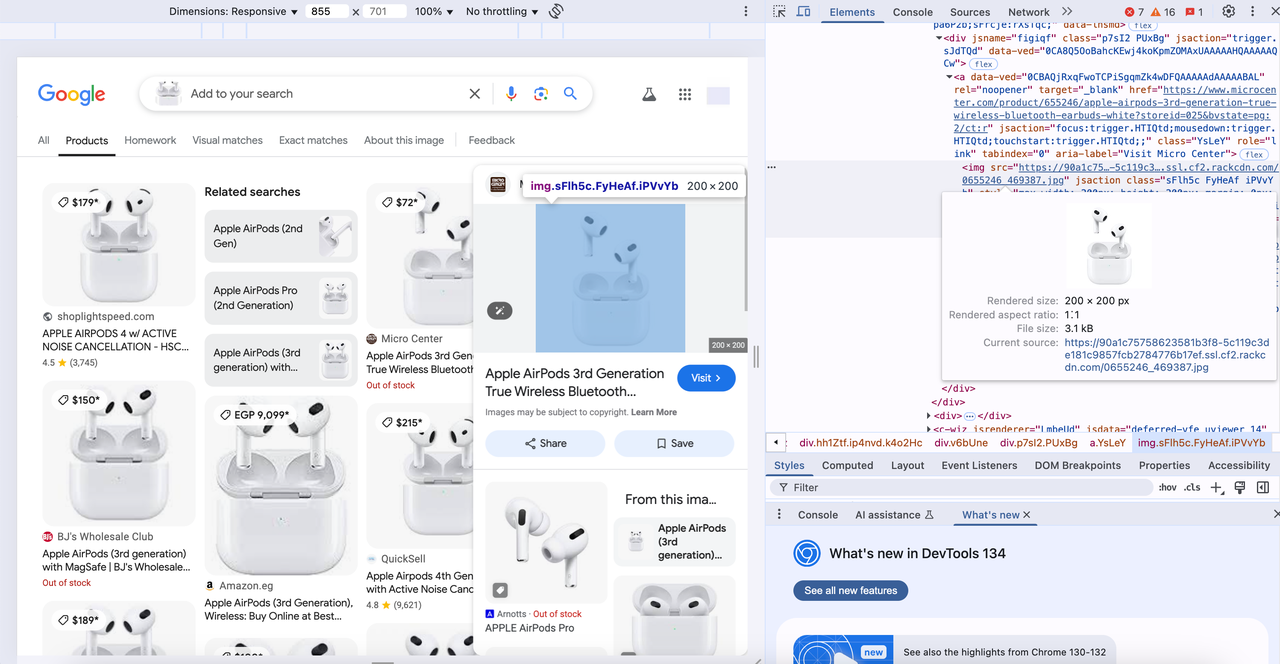
手順1:Google Lens APIトークンの作成
開始するには、ScrapelessダッシュボードからAPIキーを取得する必要があります。
- Scrapelessダッシュボードにログインします。
- APIキー管理に移動します。
- 作成をクリックして、独自のAPIキーを生成します。
- 作成したら、APIキーをクリックしてコピーします。
手順2:Scrapeless APIを統合するPythonスクリプトを作成する
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_lens",
"hl": "en",
"country": "us",
"search_type": "products",
"url": "https://m.media-amazon.com/images/I/61iBtxCUabL._AC_UF894,1000_QL80_.jpg",
}
payload = Payload("scraper.google.lens", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()別の方法:Playgroundの使用
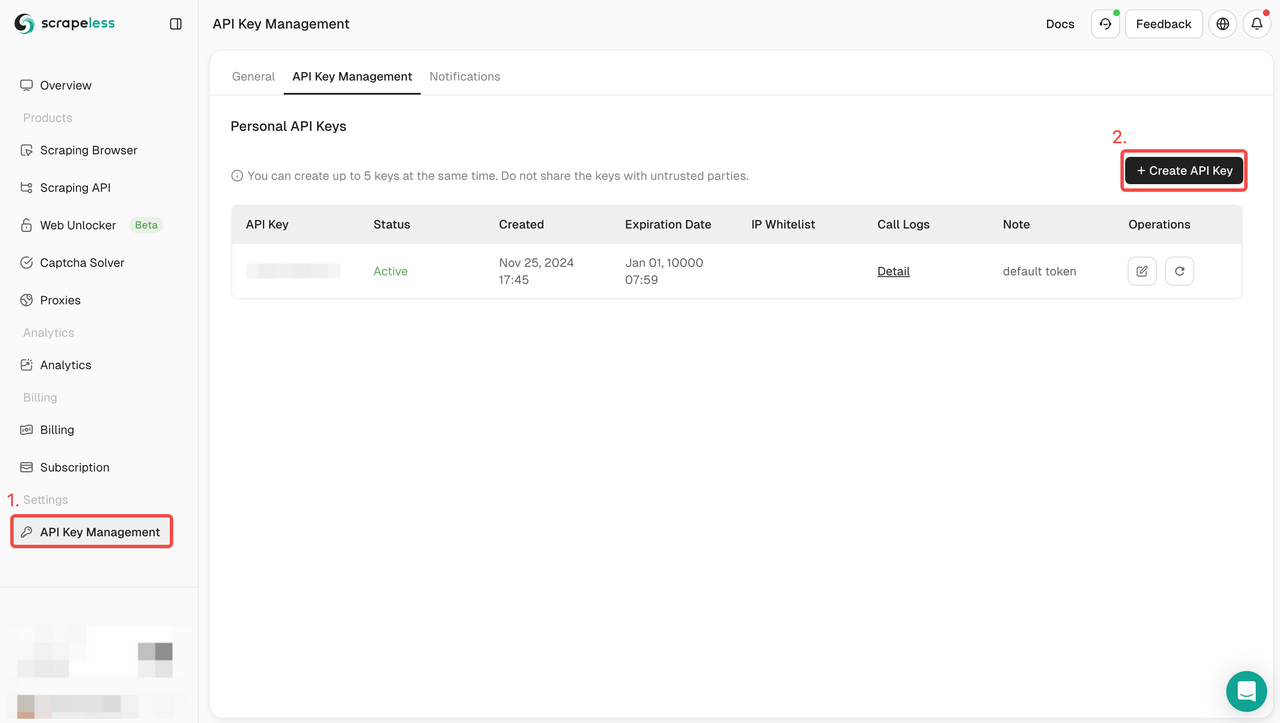
Scrapeless Playgroundを使用して、Google Lens製品のデータ抽出を完了することもできます。
- APIトークンを作成したら、Deep SerpApiをクリックします。
- Google Lens アクターを見つけます。
- リクエスト設定を完了するために必要なパラメーターを追加します。
- 検索開始をクリックして、結果の読み込みを待ちます。
- 結果をエクスポートします。
手順3. スクレイピング結果を取得する
以下は、クロール結果の一部であり、デモンストレーションの参照のみを目的としています。
JSON
{
"search_metadata": {
"status": "success",
"created_at": "2025-03-18 09:11:05 UTC",
"processed_at": "2025-03-18 09:11:05 UTC",
"google_lens_url": "https://lens.google.com/uploadbyurl?hl=en-sg&url=https%3A%2F%2Fm.media-amazon.com%2Fimages%2FI%2F61iBtxCUabL._AC_UF894%2C1000_QL80_.jpg",
"total_time_taken": 6.667
},
"search_parameters": {
"engine": "google_lens",
"url": "https://m.media-amazon.com/images/I/61iBtxCUabL._AC_UF894,1000_QL80_.jpg",
"search_type": "products"
},
"visual_matches": [
{
"position": 1,
"title": "Apple Airpods 4 : Target",
"link": "https://www.target.com/p/ap2022-true-wireless-bluetooth-headphones/-/A-85978615",
"currency": "USD",
"price": "$130*",
"extracted_price": 130,
"stock_information": "In stock",
"source": "Target",
...Google Lensからデータをスクレイピングすることは合法ですか?
Google Lensのデータをスクレイピングすることは違法ではありませんが、従う必要があるさまざまな法的および倫理的なガイドラインがあります。ユーザーは、Googleの利用規約、データプライバシー法、知的財産権を理解して、アクティビティが準拠していることを確認する必要があります。ベストプラクティスに従い、法的な発展について常に情報を得ることで、ウェブスクレイピングに関連する法的問題のリスクを最小限に抑えることができます。
Scrapeless Deep SerpAPI:強力なリアルタイム検索データソリューション
Deep SerpApiは、AIアプリケーションと検索拡張生成(RAG)モデル向けに設計されたリアルタイム検索データプラットフォームであり、リアルタイムで正確かつ構造化されたGoogle検索結果データを提供し、Google検索、Googleトレンド、Googleショッピング、Googleフライト、Googleホテル、Googleマップなど、20種類以上のGoogle SERPをサポートしています。
Deep SerpApiの利点は何ですか?
- リアルタイムデータ更新: 過去24時間以内のデータ更新に基づいており、情報のタイムリーさと正確性を確保します。
- 多言語およびジオロケーションサポート: 複数の言語とジオロケーションをサポートし、ユーザーの場所、デバイスの種類、言語に基づいて検索結果をカスタマイズできます。
- 1〜2秒の応答: 平均応答時間はわずか1〜2秒で、高頻度および大規模なデータ取得に適しています。
- シームレスな統合: Python、Node.js、Golangなどの主流のプログラミング言語と互換性があり、既存のプロジェクトに簡単に統合できます。
- 高い費用対効果: 価格は1,000クエリあたりわずか0.1ドルで、市場で最も費用対効果の高いSERPソリューションです。
今すぐボーナスを獲得しましょう!
スポンサー開発者プログラムが進行中です!最初の100ユーザーは、50万件の無料APIコールを受け取ります。これは、プロジェクトのテストとスケーリングに最適です。
Deep SerpApiをAIツール、アプリケーション、または作業中のプロジェクトに統合できます。Dify(Langchain、Langflow、FlowiseAIなど、まもなく追加されるものもあります!)などのフレームワークをサポートしています。Scrapelessを他の方法でプロジェクトに適した方法で統合することもできます。
統合が完了したら、GitHubまたはソーシャルメディアを通じて作業を共有し、統合の証拠を提供してください。見返りに、製品のメリットを最大限に活用するために、1か月間50万件の無料クエリを提供します。
まとめ
このチュートリアルでは、ScrapelessのGoogle Lens APIを使用して結果をスクレイピングする方法を紹介しました。手順に従うことで、Scrapeless APIを使用して環境を簡単に設定し、関連データを抽出し、ファイルに保存して簡単にアクセスできます。
さらに、Deep SerpApi Playgroundは、多くの不要な複雑な手順を省きます。正確なデータ結果を取得するには、簡単なパラメーター設定を行うだけです。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


