
Scrapelessを使ったCloudflareとTurnstileのバイパス方法|完全ガイド
Advanced Data Extraction Specialist
はじめに
Cloudflare ProtectionやCloudflare Turnstileなどの高度なセキュリティ機構により、Webスクレイピングはますます困難になっています。これらの課題は、自動アクセスをブロックし、ボットによるデータ取得を困難にするように設計されています。しかし、**Scrapeless Scraping Browser**を使用することで、これらの制限を効率的に回避し、中断することなくスクレイピングを続けることができます。
このガイドでは、Cloudflareの課題を回避するための3つの重要な側面について説明します。
- Scrapeless Browserを使用したCloudflare Protectionの回避方法 – CAPTCHAやボット検出などのセキュリティ対策を回避する方法を学びます。
- cf_clearance Cookieとリクエストヘッダーの取得と使用方法 – セッションの永続性を維持するために、cf_clearance Cookieとリクエストヘッダーを抽出および使用する方法を理解します。
- Scrapeless Browserを使用したCloudflare Turnstileの回避方法 – Turnstileチャレンジを回避し、スクレイピングタスクを自動化する方法を発見します。
このチュートリアルの最後までに、Cloudflare Protectionを効果的に処理するための完全な戦略を習得します。始めましょう!
パート1:Scrapelessを使用したCloudflare Protectionの回避方法
このガイドでは、ScrapelessとPuppeteer-coreを使用して、WebサイトのCloudflare Protectionを回避する方法を示します。
ステップ1:準備
1.1 プロジェクトフォルダの作成
-
プロジェクト用の新しいフォルダを作成します(例:scrapeless-bypass)。
-
ターミナルでフォルダに移動します。
cd path/to/scrapeless-bypass1.2 Node.jsプロジェクトの初期化
package.jsonファイルを作成するには、次のコマンドを実行します。
npm init -y1.3 必要な依存関係のインストール
ブラウザインスタンスへのリモート接続を可能にするPuppeteer-coreをインストールします。
npm install puppeteer-coreシステムにPuppeteerがまだインストールされていない場合は、フルバージョンをインストールします。
npm install puppeteer puppeteer-coreステップ2:Scrapeless APIキーの取得
2.1 Scrapelessへの登録
-
Scrapelessにアクセスしてアカウントを作成します。
-
APIキー管理セクションに移動します。
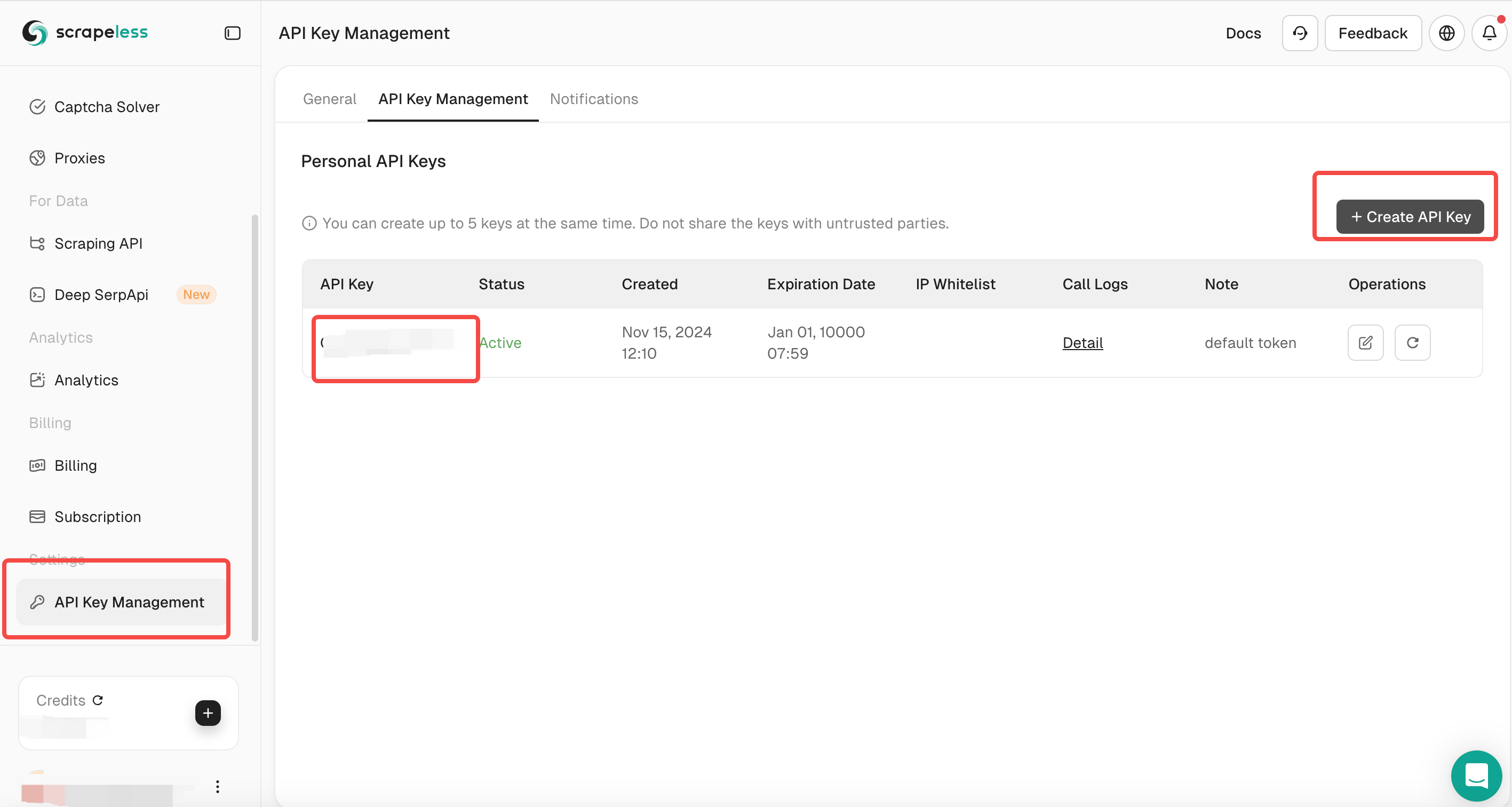
- 新しいAPIキーを生成してコピーします。
🚀 Cloudflareプロテクションの回避をさらに深く掘り下げたいですか?
👉 **今すぐログイン**して、高度な機能とチュートリアルにアクセスしましょう!
🔒 追加のヘルプが必要ですか? リアルタイムのサポートとアップデートのために、Discordコミュニティに参加しましょう!
📈 今すぐScrapeless Browserでスマートなスクレイピングを始めましょう!
ステップ3:Scrapeless Browserlessへの接続
3.1 WebSocket接続URLの取得
Scrapelessは、Puppeteerがクラウドベースのブラウザと対話するためのWebSocket接続URLを提供します。
フォーマットは次のとおりです。
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYAPIKeyを実際のScrapeless APIキーに置き換えます。
3.2 接続パラメータの設定
-
token:Scrapeless APIキー
-
session_ttl:ブラウザセッションの期間(秒)(例:180秒)
-
proxy_country:プロキシサーバーの国コード(例:英国の場合はGB、米国の場合はUS)
ステップ4:Puppeteerスクリプトの作成
4.1 スクリプトファイルの作成
プロジェクトフォルダ内に、bypass-cloudflare.jsという名前の新しいJavaScriptファイルを作成します。
4.2 Scrapelessへの接続とPuppeteerの起動
bypass-cloudflare.jsに次のコードを追加します。
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // 実際のAPIキーに置き換えます
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // ブラウザセッションの期間(秒)
proxy_country: 'GB', // プロキシの国コード
proxy_session_id: 'test_session', // プロキシセッションID(同じIPを維持)
proxy_session_duration: '5' // プロキシセッションの期間(分)
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Scrapelessに接続しました');4.3 Webページを開いてCloudflareを回避する
Cloudflareで保護されたWebサイトに新しいページを開いて移動するスクリプトを拡張します。
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });4.4 ページ要素の読み込みを待機する
続行する前に、Cloudflareプロテクションが回避されていることを確認します。
javascript
await page.waitForSelector('main.page-content .challenge-info', { timeout: 30000 }); // 必要に応じてセレクターを調整します4.5 スクリーンショットのキャプチャ
Cloudflareプロテクションの回避が成功したことを確認するために、ページのスクリーンショットを撮ります。
javascript
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('スクリーンショットをchallenge-bypass.pngとして保存しました');4.6 完全なスクリプト
完全なスクリプトを以下に示します。
javascript
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'; // 実際のAPIキーに置き換えます
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180',
proxy_country: 'GB',
proxy_session_id: 'test_session',
proxy_session_duration: '5'
}).toString();
const connectionURL = `${host}/browser?${query}`;
(async () => {
try {
// Scrapelessに接続
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Scrapelessに接続しました');
// 新しいページを開いてターゲットWebサイトに移動
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', { waitUntil: 'domcontentloaded' });
// ページが完全に読み込まれるのを待つ
await page.waitForTimeout(5000); // 必要に応じて遅延を調整
await page.waitForSelector('main.page-content', { timeout: 30000 });
// スクリーンショットをキャプチャ
await page.screenshot({ path: 'challenge-bypass.png' });
console.log('スクリーンショットをchallenge-bypass.pngとして保存しました');
// ブラウザを閉じる
await browser.close();
console.log('ブラウザを閉じました');
} catch (error) {
console.error('エラー:', error);
}
})();ステップ5:スクリプトの実行
5.1 スクリプトの保存
スクリプトがbypass-cloudflare.jsとして保存されていることを確認します。
5.2 スクリプトの実行
Node.jsを使用してスクリプトを実行します。
node bypass-cloudflare.js5.3 期待される出力
すべてが正しく設定されている場合、ターミナルに次が表示されます。
Scrapelessに接続しました
スクリーンショットをchallenge-bypass.pngとして保存しました
ブラウザを閉じましたchallenge-bypass.pngファイルがプロジェクトフォルダに表示され、Cloudflareプロテクションが正常に回避されたことが確認されます。
🌟 Cloudflareプロテクションを簡単に回避したいですか?
🔑 **ここでログインして、Scrapeless Browserの強力なツールを活用しましょう!
🚀 専門家のガイダンスが必要ですか? 独占的なヒントとトラブルシューティングのヘルプのために、Discordコミュニティ**に参加しましょう!
💡 Scrapeless BrowserでWebスクレイピングを先取りしましょう - セキュアで高速、信頼性があります!
ステップ6:追加の考慮事項
6.1 APIキーの使用
-
APIキーが有効であり、リクエストクォータを超えていないことを確認します。
-
公開リポジトリ(例:GitHub)でAPIキーを公開しないでください。セキュリティのために環境変数を使用します。
6.2 プロキシ設定
-
異なる場所を選択するために
proxy_countryパラメータを調整します(例:米国の場合はUS、ドイツの場合はDE)。 -
リクエスト間で同じIPアドレスを維持するために、一貫性のある
proxy_session_idを使用します。
6.3 ページセレクタ
-
ターゲットWebサイトの構造は異なる場合があり、
waitForSelector()の調整が必要になる場合があります。 -
page.evaluate()を使用してページ構造を検査し、セレクターを適宜更新します。
このガイドでは、ScrapelessとPuppeteer-coreを使用してCloudflareプロテクションを回避する段階的な方法を提供しました。WebSocket接続、プロキシ設定、要素監視を活用することで、Cloudflareによってブロックされることなく、Webスクレイピングを効率的に自動化できます。
パート2:cf_clearance Cookieとリクエストヘッダーの取得と使用方法
Cloudflareチャレンジを正常に回避した後、成功したページレスポンスからリクエストヘッダーとcf_clearance Cookieを取得できます。これらの要素は、セッションの永続性を維持し、繰り返しのチャレンジを回避するために非常に重要です。
1. cf_clearance Cookieの取得
javascript
const cookies = await browser.cookies();
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.value;目的:
-
このコードは、Cloudflareのセキュリティチャレンジに合格した後発行されるcf_clearanceを含む、すべてのCookieを取得します。
-
cf_clearance Cookieを使用すると、後続のリクエストでCloudflareのプロテクションを回避できるため、繰り返しのチャレンジが不要になります。
2. リクエストインターセプトの有効化とヘッダーのキャプチャ
javascript
await page.setRequestInterception(true);
page.on('request', request => {
// Cloudflareチャレンジ後のページリクエストに一致
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});目的:
-
ネットワークリクエストを監視および変更するために、リクエストインターセプトを有効にします(
setRequestInterception(true))。 -
Puppeteerがネットワークリクエストを送信するたびにトリガーされるリクエストイベントをリッスンします。
-
Cloudflareチャレンジリクエストを識別します。
-
request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge')は、関連するリクエストのみがインターセプトされることを保証します。 -
request.headers()?.['origin']は、正当なアクセスを確認するのに役立ちます。
-
後で実際のブラウザリクエストをシミュレートするために使用できるリクエストヘッダーを抽出して印刷します。
-
ページの読み込みの中断を防ぐために、リクエストを続行します(
request.continue())。
🔍 Cloudflareのcf_clearance Cookieを効果的にキャプチャして使用したいですか?
💪 **今すぐログイン**して、よりスムーズなスクレイピングのためのすべての高度な機能にアクセスしましょう。
3. cf_clearanceとヘッダーを取得する理由
- セッションの永続性:
-
cf_clearance Cookieを使用すると、後続のHTTPリクエストでCloudflareチャレンジをスキップできます。
-
このCookieは複数のリクエストで再利用できるため、検証プロンプトが最小限になります。
- 実際のブラウザリクエストのシミュレーション:
-
Cloudflareは、User-Agent、Referer、Originなどのリクエストヘッダーを調べます。
-
成功したリクエストからヘッダーをキャプチャすることで、将来のリクエストで正当なトラフィックを模倣できるため、検出のリスクが軽減されます。
- クローリング効率の向上:
- これらの詳細はデータベースまたはファイルに保存して再利用できるため、不要なチャレンジを防ぎ、リクエストの成功率を最適化できます。
これらのテクニックを実装することで、Webスクレイピングの信頼性と効率を向上させ、Cloudflareのセキュリティ対策を効果的に回避できます。🚀
パート3:Scrapeless Browserを使用したCloudflare Turnstileの回避方法
このチュートリアルのパートでは、Puppeteerを使用してScrapeless BrowserでCloudflare Turnstileプロテクションを回避する方法を学びます。Cloudflare Turnstileは、ボットと自動スクレイピングをブロックするために使用されるより高度なセキュリティメカニズムです。Scrapeless Browserの助けを借りて、まるで本当のユーザーであるかのようにWebサイトと対話して、このプロテクションを回避できます。
注記:
「Cloudflare Protectionの回避」と「Cloudflare Turnstileの回避」は、異なるセキュリティメカニズムを対象としています。
- Cloudflare Protectionの回避には、CAPTCHA、JavaScriptチェック、IPレート制限などの一般的なCloudflareセキュリティ対策を回避することが含まれます。
- Cloudflare Turnstileの回避は、従来のCAPTCHAに依存しない、人間の操作を保証する独自のアンチボットチャレンジであるCloudflareのTurnstileを具体的にターゲットとしています。Turnstileを回避すると、この特定のセキュリティメカニズムが無効になります。
ステップ1:ターゲットページを開く
Cloudflare Turnstileによって保護されている(通常は人間の検証が必要な)Webページを開くことから始めます。Webページを開くコードを以下に示します。
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });このコードはpage.goto()を使用してページに移動し、DOMコンテンツが読み込まれるまで待機します。
ステップ2:ログイン資格情報の入力
ページが読み込まれたら、ログインページを通過するためにログイン資格情報(ユーザー名やパスワードなど)の入力プロセスを自動化できます。
javascript
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');ステップ3:Turnstileのロック解除を待つ
Cloudflare Turnstileは、人間のユーザーだけが続行できるように機能します。このステップでは、Turnstile検証プロセスからレスポンスが受信されたかどうかを確認することで、Turnstileがロック解除されるのを待ちます。
javascript
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});このコード行は、window.turnstile.getResponse()からのレスポンスを待ちます。これは、Turnstile検証が正常に回避されたことを示しています。
💥 Cloudflare Turnstileの背後にあるコンテンツを簡単にアンロックします。
🔓 **ログインして、強力なスクレイピング機能にアクセスしましょう。
💬 パーソナルなヘルプ、ヒント、ユーザーのインサイトについては、Discordコミュニティ**に参加しましょう!
🚀 Scrapeless BrowserでWebスクレイピングを合理化しましょう - Cloudflareの最も厳しい課題を含む、あらゆる障壁を克服しましょう!
ステップ4:検証のためのスクリーンショットの撮影
バイパスが成功したことを確認するために、ページのスクリーンショットを撮ることができます。これにより、Turnstileが正常にバイパスされたことを確認できます。
javascript
await page.screenshot({ path: 'challenge-bypass-success.png' });ステップ5:ログインボタンをクリックする
Turnstileチャレンジを正常に回避した後、ユーザーがログインボタンをクリックしてフォームを送信するのをシミュレートできます。
javascript
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();このコードは送信ボタンをクリックし、ログイン後のページへの移動を待ちます。
ステップ6:次のページのスクリーンショットを撮る
最後に、ログインしたら、次のページへの移動が成功したことを確認するために、別のスクリーンショットを撮ります。
javascript
await page.screenshot({ path: 'next-page.png' });完全なコード例
上記で概説したすべてのステップを組み込んだ完全なコードを以下に示します。
javascript
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com');
await page.locator('input[type="password"]').fill('password');
// Turnstileが正常にロック解除されるのを待つ
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
// バイパス後のスクリーンショットを撮る
await page.screenshot({ path: 'challenge-bypass-success.png' });
// ログインボタンをクリックする
await page.locator('button[type="submit"]').click();
await page.waitForNavigation();
// 次のページのスクリーンショットを撮る
await page.screenshot({ path: 'next-page.png' });このチュートリアルに従うことで、Scrapeless BrowserとPuppeteerを使用してCloudflare Turnstileプロテクションを回避する方法を学びました。このアプローチにより、Webサイトと対話して、ログインフォームに入力し、Cloudflareのセキュリティメカニズムを回避しながらコンテンツを移動できます。このテクニックを拡張して、Turnstileによって保護されている他のWebサイトでも機能させることができます。
Scrapeless Browserを使用したCloudflareの回避とWebスクレイピングをマスターする準備はできましたか?
🚀 今すぐScrapeless Browserの全機能をアンロックして、Cloudflareプロテクションの回避、Cookieとヘッダーの取得、Turnstileチャレンジの回避を簡単に始めましょう!
🔑 **ここでログイン**して、限定機能にアクセスし、自信を持ってスクレイピングを始めましょう。
💬 他のスクレイピングのエキスパートとつながり、トラブルシューティングのヘルプを受け、最新のヒントとコツを最新の状態に保つために、**Discordコミュニティ**に参加しましょう。
💡 Scrapeless BrowserでWebスクレイピングを次のレベルに引き上げるための強力なツールとインサイトを見逃さないでください。
まとめ
Cloudflareセキュリティを正常に回避するには、適切なツールと戦略が必要です。Scrapeless Browserを使用すると、Cloudflareの防御を簡単に回避し、必要なCookieとヘッダーを取得し、手動で介入することなくTurnstileチャレンジを克服できます。
🔑 **今すぐ登録**して、Webスクレイピングを次のレベルに引き上げましょう!
💬 ヘルプが必要ですか? エキスパートのインサイト、トラブルシューティングのサポート、最新のWebスクレイピングテクニックの最新情報を入手するために、**Discordコミュニティ**に参加しましょう。
Cloudflareに遅れることはありません - 今すぐシームレスなスクレイピングをアンロックしましょう!
よくある質問:Cloudflareの回避、cf_clearance Cookie、Turnstileチャレンジ
1. Cloudflare Protectionとは何か、なぜWebスクレイパーをブロックするのか?
Cloudflare Protectionは、自動化されたトラフィックを検出して軽減するセキュリティサービスです。CAPTCHA、JavaScriptチャレンジ、IPレート制限などの技術を使用して、ボットが保護されたコンテンツにアクセスするのを防ぎます。
2. cf_clearanceとは何か、どのようにCloudflareの回避に役立つのか?
cf_clearance Cookieは、Cloudflareチャレンジに成功した後発行されます。これにより、特定の期間、ブラウザセッションが検証されたままになるため、さらなるチャレンジを防ぎます。このCookieを取得して再利用することで、スクレイパーは途切れることなくアクセスを維持できます。
3. Cloudflare Turnstileは標準のCloudflare Protectionとどのように異なるのか?
Cloudflare Turnstileは、従来のCAPTCHAを使用せずに人間の存在を確認するように設計された高度なチャレンジです。ボットをブロックするために、行動分析やその他の検証テクニックを使用します。Turnstileを回避するには、実際のユーザーの操作を模倣する自動化されたワークフローが必要です。
4. Scrapeless Browserを使用してCloudflareを回避することは合法か?
Cloudflareを回避することの合法性は、Webサイトの利用規約と現地の規制によって異なります。スクレイピング活動がWebサイトのポリシーおよび適用される法律に準拠していることを常に確認してください。
5. Cloudflareの回避にScrapeless Browserの使用を開始するにはどうすればよいか?
**Scrapeless Browserにログイン**して、このガイドの手順に従って自動回避ソリューションを実装することで、開始できます。
6. Scrapeless Browserのサポートはどこで入手できるか?
他の開発者とつながり、トラブルシューティングのヘルプを受け、新機能とベストプラクティスの最新情報を入手するには、**Discordコミュニティ**に参加してください。
その他の資料
セキュリティチャレンジをトリガーすることなく、Puppeteerを使用してCloudflareのプロテクションを回避し、Webコンテンツにアクセスする方法を学びます。
Webスクレイピングに検出されないChromeDriverを使用する方法
Webサイトをスクレイピングする際に検出を回避するための、検出されないChromeDriverインスタンスの使用に関するテクニックを発見してください。
Node.jsでGoogleホテルの価格をスクレイピングする方法
Node.jsを使用してGoogleホテルの価格データをスクレイピングし、アンチボットメカニズムを効果的に処理する手順ガイド。
PythonでGoogle Financeティッカーの株価データをスクレイピングする方法
JavaScriptでレンダリングされたデータの処理を含む、Google Financeティッカーの株価を抽出するPythonベースのチュートリアル。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


