Python を使用して Web スクレイピングで CAPTCHA を回避する方法
Advanced Bot Mitigation Engineer
はじめに
CAPTCHA の完全な形式を知っている人はほとんどいません。
実際、CAPTCHA の略語は「コンピューターと人間を区別するための完全に自動化された公開チューリングテスト」の略です。
CAPTCHA は、解決が難しい問題をコンピューターに提示することで、疑わしいユーザーや最新のボットを識別するように設計されており、Web サイトの所有者がスクレイピングやクロールを防止するのに役立ちます。テキストを読み取り、HTML フォームを操作し、高度な HTML 構造をスクレイピングできるサードパーティのライブラリが多数あるため、Python は Web スクレイピングの一般的な選択肢です。そこで、この記事では、Python を使用して Web スクレイピング中に CAPTCHA の問題を克服する方法を説明します。
データ収集プロセスに組み込む実用的な CAPTCHA 対策ソリューションについて説明するだけでなく、今日のオンライン環境で見られるさまざまな CAPTCHA の種類についても説明します。
reCAPTCHA
これは、Google が開発した無料の CAPTCHA ソリューションで、hCAPTCHA と同様に、ボットのような動作を識別する最先端の方法を採用し、ウェブサイトのセキュリティを提供します。Google reCAPTCHA は、ユーザーからの入力がなくても人間のユーザーを識別できるようになりました。認識の基準として、ユーザーの他のウェブサイトでの過去の経験のみを使用します。Google 検索、マップ、Play、ショッピングなど、多くのサービスや製品で reCAPTCHA が広く採用されています。
ImageToText CAPTCHA

通常、ImageToText CAPTCHA は、文字がさまざまな方法で回転、サイズ変更、歪曲され、判読できないスタイルで表示される無関係な文字の寄せ集めです。
オーディオ CAPTCHA
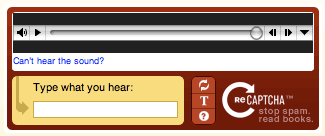
「サウンドベースの CAPTCHA」とも呼ばれ、ユーザーは音声録音を通じて一連の文字または数字を入力する必要があります。難易度を上げるために、音声にはバックグラウンド ノイズが頻繁に追加されます。
hCAPTCHA
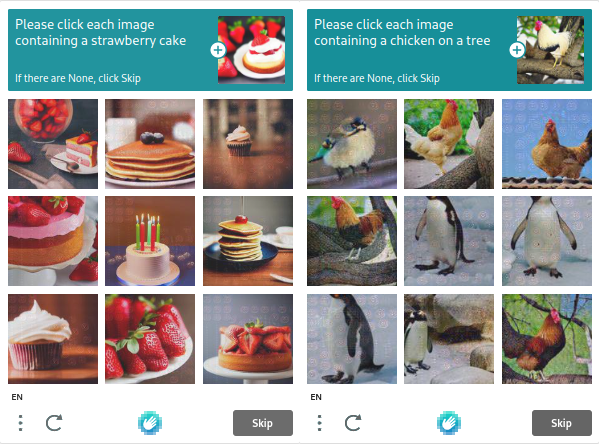
Intuition Machines は、ユーザーのプライバシーを重視し、不要なデータを収集しない hCaptcha の所有者です。その結果、その人気は高まっています。チェックボックスのチェックや画像の認識などの標準的なボット評価タスクは、hCaptcha を使用して実行されます。hCaptcha のテストは reCAPTCHA のテストよりも複雑ですが、パラメータを変更して難易度を上げたり下げたりすることができます。
Web スクレイピングとは?
Web サイトからデータを取得する手法は、Web スクレイピングと呼ばれます。Web スクレイピングでは、Web スクレイパーまたはクローラーと呼ばれることもある自動化デバイスを使用して Web サイトからデータを抽出します。これらのプログラムは、Web サイトの階層を移動して HTML コードを取得し、定義済みのパターンまたはガイドラインを使用して必要なデータを抽出します。
ウェブスクレイピングには、次のような用途があります。
-
競合他社の分析: 競合他社のインターネット上の存在と戦術を監視する
-
データ収集: ウェブサイトからテキスト、画像、その他のメディア コンテンツをコンパイルする
-
価格監視: さまざまなインターネット マーチャントの製品価格を監視し、比較する
-
資料の集約: 多くのソースから資料を収集して、統合データベースまたはウェブサイトを作成する
-
市場調査: 市場の動向、傾向、消費者のフィードバック、その他の関連データを把握するために分析する。
ウェブスクレイピングは、データ収集のための強力な手段ではありますが、倫理的かつ合法的な方法で実行する必要があることに注意してください。個人情報や機密情報のスクレイピングは違法である可能性があり、多くのウェブサイトでは利用規約で明示的に禁止しています。オンライン スクレイピング活動に参加するときは、ウェブサイトの使用条件と適用される法律に常に従うようにしてください。
Web スクレイピングの例
Web スクレイピングは、通常はツールやプログラミング スクリプトを使用して自動的に Web サイトからデータを取得するプロセスです。これは、Web スクレイピング アクティビティでよく使用されるオプションである BeautifulSoup パッケージと Python を使用する基本的な例です。
ここでは、架空のニュース ソースから最新の記事の名前を取得したいと仮定します。 HTML の構造は次のようになります:
language
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sample News Website</title>
</head>
<body>
<div class="article">
<h2 class="title">Breaking News 1</h2>
<p class="content">This is the content of the first article.</p>
</div>
<div class="article">
<h2 class="title">Latest Update: Important Event</h2>
<p class="content">Details about the important event.</p>
</div>
</body>
</html>それでは、BeautifulSoup と Python を利用して、これらの記事の見出しをスクレイピングしてみましょう:
language
import requests
from bs4 import BeautifulSoup
# URL of the sample news website
url = 'https://www.example-news-website.com'
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all div elements with the class 'article' and extract the titles
article_divs = soup.find_all('div', class_='article')
# Extract and print the titles
for article_div in article_divs:
title = article_div.find('h2', class_='title').text
print(f"Title: {title}")
```(f"Title: {title}")HTML コンテンツを取得するには、requests ライブラリを使用して、ウェブサイト。次に、BeautifulSoup を使用して HTML コンテンツを解析します (この場合は 'html.parser' を使用します)。クラス article を持つすべての div 要素を検出するには、find_all を使用します。すべての記事のクラス title を持つ h2 要素を見つけて、そのテキスト コンテンツを取得します。
Scrapeless を使用して Web スクレイピング中に CAPTCHA を回避する方法
絶え間ない Web スクレイピング ブロックと CAPTCHA にうんざりしていませんか?
究極のオールインワン Web スクレイピング ソリューション、Scrapeless をご紹介します!
強力なツール スイートを使用して、データ抽出の可能性を最大限に引き出します:
最高の CAPTCHA ソルバー
高度な CAPTCHA を自動的に解決し、スクレイピングをシームレスかつ中断のない状態に保ちます。
違いを体験してください - 無料でお試しください!
結論
公開データ収集の最も一般的な障害の 1 つは CAPTCHA であるため、それを乗り越えるための信頼性が高く優れた方法を見つけることが重要です。この記事では、現在利用可能なさまざまな CAPTCHA タイプについて説明し、Web スクレイピング アクティビティで使用できる CAPTCHA 対策ソリューションをいくつか紹介しました。
この件に関してご質問がある場合、または Web Unlocker や CAPTCHA Solver などの Scrapeless の CAPTCHA 回避のベスト プラクティスについて詳しく知りたい場合は、公式 Web サイトからお問い合わせください。
FAQ
Web スクレイピング中に CAPTCHA を回避するにはどうすればよいですか?
Web データを取得するときに、CAPTCHA を回避する方法は複数あります。便利な方法は、User-Agent ヘッダーを変更してスクレイパーのフィンガープリントを微調整することです。さらに、Web Unlocker などの自動プログラムの使用を検討することもできます。これは、CAPTCHA の問題に対処するのに役立つ場合があります。
ウェブサイトの所有者がスクレイピングを防止するために CAPTCHA を使用するのはなぜですか?
CAPTCHA は、危険なボットと本物の訪問者を区別するためにウェブサイトで使用されます。これらは、スパムや不正な取引など、敵対的または潜在的に破壊的なボットの行動を防ぐための安全対策として機能します。
Web スクレイピング中に CAPTCHA をバイパスする方法はありますか?
はい、CAPTCHA をバイパスするために特別に作られたさまざまなサービスが市場に出回っています。例としては、Web Unlocker や CAPTCHA ソルバーなどがあります。たとえば、Scrapeless のツールは、適切なヘッダー、Cookie、ブラウザー プロパティなどのセットを選択して、正当なユーザーとして表示し、最終的にターゲット Web サイトの障壁をすべて通過します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


