
Difyでインテリジェントなビジネスニュースモニターを構築する方法は?
Advanced Data Extraction Specialist
今日の競争が激しい環境では、ブランドの評判、業界の動向、競合情報をリアルタイムで把握することが、効果的な意思決定のために欠かせません。しかし、ニュースや情報を手動で監視するのは時間がかかり、労力を要し、重要なインサイトを見逃すことがあります。
このソリューションは、ノーコードのAIオートメーションプラットフォームであるDifyと、エンタープライズ向けのGoogle検索データインターフェースであるScrapeless Deep SerpApiを統合し、企業が以下を可能にするスマートでスケーラブルなビジネスニュース監視システムを構築します:
- リアルタイムのニュースを自動で収集・フィルタリング
- AIを活用したインテリジェントな分析と実行可能なインサイト
- 複数のチャネルで自動的にアラートやレポートを配信
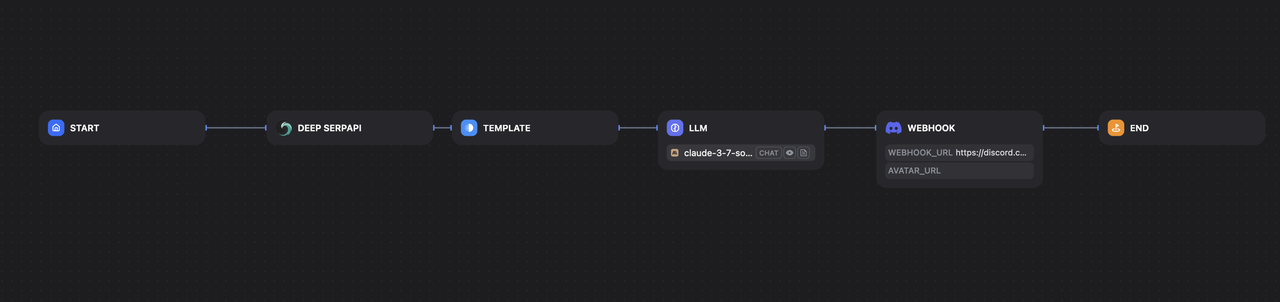
1. ソリューション概要
| コンポーネント | 説明 |
|---|---|
| Difyインテリジェントワークフロープラットフォーム | ノーコードのワークフロー設計と実行、AIとAPI統合のためのドラッグアンドドロップサポート |
| Scrapeless Deep SerpApi | 高速で安定した、ブロック対策を施したGoogle検索APIで、多地域かつ多言語のクエリをサポート |
| AIモデル(例:GPT-4 / Claude) | 自動的な意味分析を行い、インテリジェントなニュース要約やビジネスインサイトを生成 |
| 通知プラグイン(例:Discord Webhook) | モニタリングレポートをリアルタイムでプッシュし、迅速な情報提供を確保 |
2. エンタープライズグレードのツール概要
Difyインテリジェントワークフロープラットフォーム
柔軟でエンタープライズ向けのワークフロー用に設計されたノーコードAIオートメーションプラットフォーム
- ドラッグアンドドロップでワークフローを構築するためのビジュアルインターフェイス—コーディング不要
- 主流のAIモデル(GPT-4、Claude 3、Geminiなど)とのシームレスな統合
- APIや外部データソースとの接続のためのプラグインエコシステム
- 詳細なログとエラートレースを備えたリアルタイムモニタリング
- ロールベースのアクセス制御とチームコラボレーションサポート
- セキュアなエンタープライズ環境でのプライベートデプロイメントに適した
Scrapeless Deep SerpApi
AIワークフローとビジネスインテリジェンスのために設計されたリアルタイム、高忠実度のGoogle SERP API
Scrapeless Deep SerpApiは、ブランドモニタリング、市場インテリジェンス、コンテンツ生成、AI駆動の意思決定などのエンタープライズ向けユースケースに特化して設計されています。Googleの検索結果(HTML解析)からリアルタイムで構造化データを抽出し、正確性、新鮮さ、信頼性を確保します。
主な利点
- リアルタイムのGoogle SERPデータへの即時アクセス(応答時間3秒未満)
- 包括的な結果カバレッジ:オーガニック結果、Googleローカル、Google画像、Googleニュースなど
- キャッシング不要:直接のHTML解析による最新の検証可能な結果
- アンチスクレイピング技術:成功率99.9%、手動プロキシ設定不要
- 195以上の国と言語をサポートし、グローバルモニタリングを実現
- 共通データフォーマットでの構造化出力により、AIモデルや自動化ワークフローが解析しやすい
- 透明な使用ベースの請求で隠れた制限やフィールド制限なし
📌 理想的な用途:
- エンタープライズグレードのメディア監視とアラートシステムの構築
- 競合アクティビティと市場動向をグローバルに追跡
- 検索調整されたデータセットの作成(RAG)
- SEOやコンテンツの自動化を大規模に推進
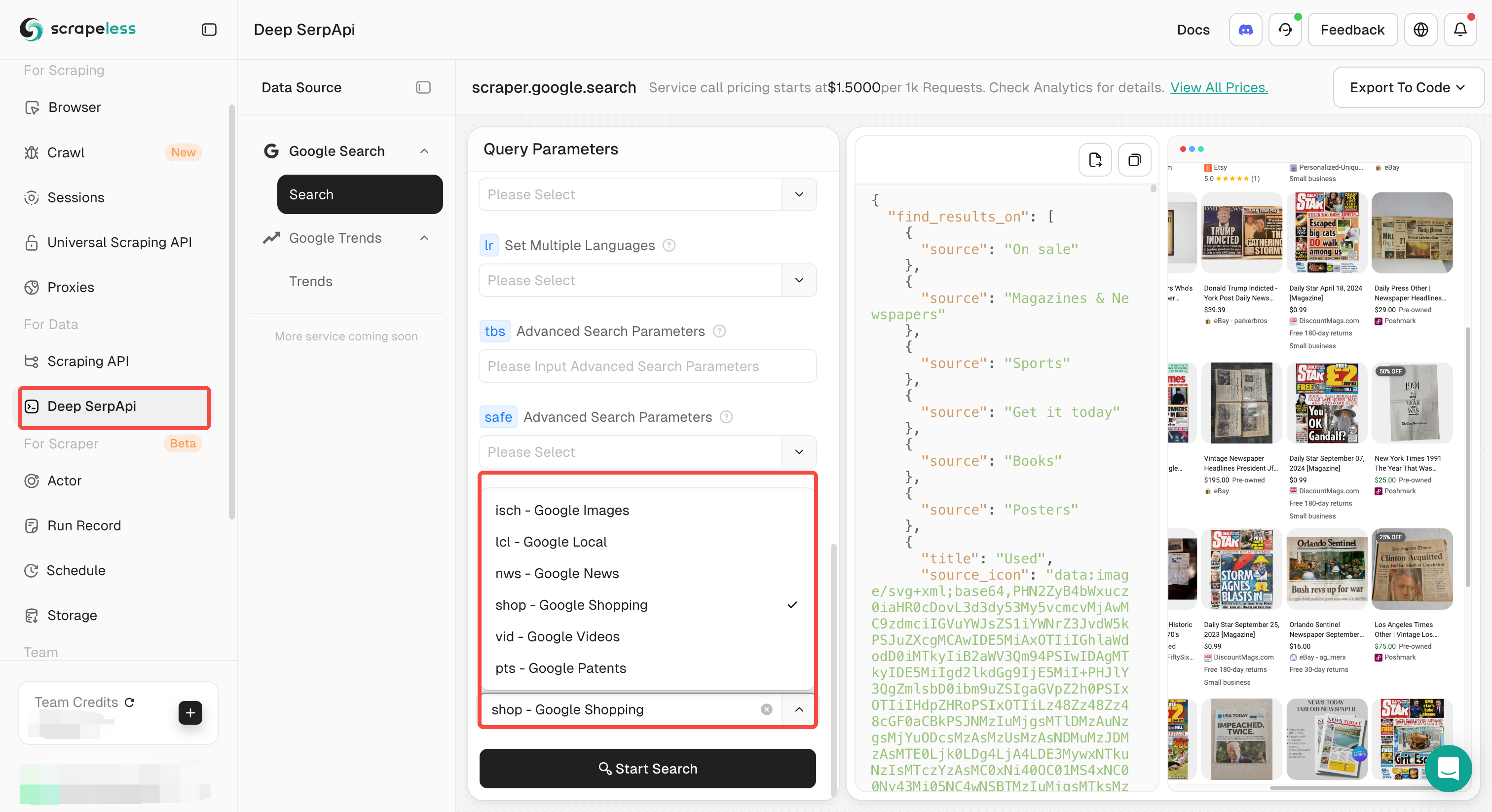
3. 環境設定とアカウント登録
3.1 Scrapelessアカウントを登録し、APIトークンを取得する
- Scrapelessダッシュボードにアクセス
- ビジネスアカウントを登録
- ログイン後、API管理ページに移動してAPIトークンを取得
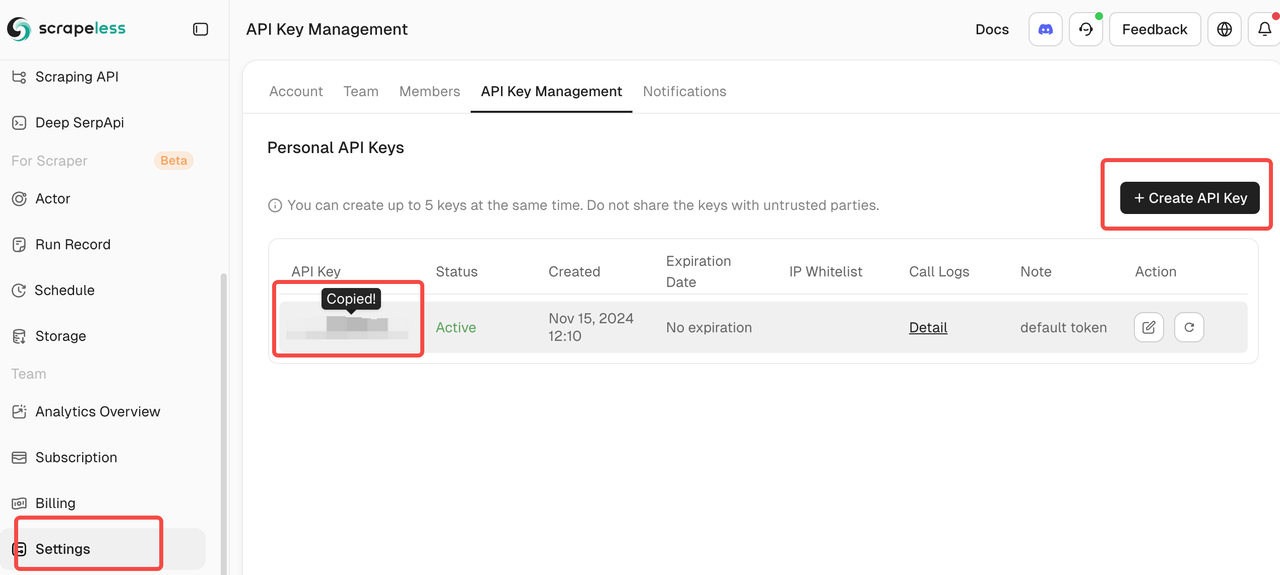
⚠️ 重要:APIトークンを安全に保管し、決して公開しないでください。
3.2 Difyアカウントを登録し、Deep SerpApiプラグインをインストール
-
まだサインアップしていない場合は、Difyにサインアップし、https://marketplace.dify.ai/plugins/scrapelesshq/deep_serpapiをインストールします。
-
新しいアプリケーションを作成し、「ワークフロー」を選択
-
ワークフロースタジオで「+」ボタンをクリックして新しいツールを追加
-
パネルの「ツール」タブに移動
-
ツールリストに表示されている「Deep SerpApi」を探します(scrapelesshqによる)。
-
「Deep SerpApi」をクリックしてワークフローに追加します。
4. 詳細な設定プロセス
ステップ1: Deep SerpApiノードを追加
-
ワークフローエディターの「+」ボタンをクリックします。
-
ツールタブを選択します。
-
**Deep SerpApi (Scrapeless)**を選択し、ワークフローに追加します。
-
設定パネルで、事前にコピーしたAPIトークンを貼り付けます。
ステップ2: 検索パラメータを設定
- Deep SerpApiノードのクエリ文字列フィールドに検索クエリを入力します。例えば:
"あなたの会社名" ニュース
- 次のような高度な検索構文もサポートしています:
"あなたの会社名" OR "業界キーワード""会社名" AND (発表 OR パートナーシップ)
- この例では次のように使用します:
{{ company }} 最新のビジネスニュース 2025年6月 site:reuters.com OR site:bloomberg.com OR site:cnn.comステップ3: 検索結果をフォーマットするテンプレートノードを追加
-
Deep SerpApiノードの後に**“+”**ボタンをクリックします。
-
利用可能なブロックから**“テンプレート”**を選択します。
-
テンプレートフィールドに次のフォーマットテンプレートを入力します:
検索結果:
{% for item in arg1[0].organic_results %}
- タイトル: {{ item.title }}
- リンク: {{ item.link }}
{% endfor %}- このテンプレートは、検索結果を構造化された方法で表示し、後続のAI分析を容易にします。
ステップ4: AI分析ノードを設定
- Deep SerpApiノードの後に**“+”**ボタンをクリックします。
- 利用可能なブロックから**“LLM”**を選択します。
- お好みのAIモデルを選択します(GPT-4を推奨)。
**“モデルプロバイダー設定”**をクリックしてモデルをインストールまたはアクティブにする必要があります。
-
LLMの選択画面に移動します。好きなものを選んでください。私たちの例ではClaudeを使用します。
-
システムプロンプトに検索結果を参照します:
あなたはビジネスインテリジェンスアナリストです。
以下の検索結果に基づいて、会社『{{ company }}』に関する簡潔なB2Bインテリジェンスレポートを生成してください。レポートには次の内容を含めるべきです:
1. 全体の感情(ポジティブ/ニュートラル/ネガティブ)
2. 主なニュースの発展または更新
3. ビジネスリスクまたは機会
4. 会社の戦略的含意
5. 緊急または注目すべき項目
検索結果が一般的すぎる場合や会社特有の内容が不足している場合は、その点を指摘し、クエリの改善方法を提案してください。
適切な箇条書きを使用してください。トーンは専門的かつ実行可能なものにしてください。- ユーザープロンプトにフォーマットされたテンプレート結果を参照します:
次の会社に関する検索結果を分析してください:ニュースのタイトル、コンテンツ、提供元に基づく洞察。- その後、プロンプトテキストボックスで「/」を使用して変数セレクターを呼び出し、出力、テキスト、sysなどの変数のリストを呼び出してテンプレートに挿入するか、変数を設定できます。
ステップ5: ワークフローを実行しデバッグ
-
インターフェースの右上隅にある実行ボタンをクリックします。
-
ワークフローの実行を待ち、出力結果を確認します。
-
分析結果に基づいて、検索キーワードとAIプロンプトを調整してパフォーマンスを最適化します。
ステップ6:エンタープライズ通知チャネルを統合する(例:Discord Webhook) (オプション)
ワークフローが完了したときにDiscordサーバーに直接通知を受け取るには、Webhook統合を追加できます。
- 新しいブロックを追加します:
- LLM分析ステップの後に**「+」**ボタンをクリックします
- ブロックメニューから**「ツール」**を選択します
- マーケットプレイスでDiscord Webhookを見つけます:
- ツールセクションで**「マーケットプレイス」**をクリックします
- **「Discord」または「webhook」**を検索します
- Discord webhookツールをまだインストールしていない場合はインストールします
- Webhookを設定します:
- Discord Webhookツールを選択します
- Discord Webhook URLを入力します(このURLはDiscordサーバー設定で取得できます)
- 分析結果を含むメッセージ形式をカスタマイズします
- 前のステップからの変数を使用して動的コンテンツを含めます
- メッセージのカスタマイズ:
- 通知に検索クエリを含めます
- 主要な発見の要約を追加します
- Discordでの読みやすさのためにメッセージをフォーマットします
🔍 **デイリービジネスインテリジェンスレポート**
/ context
---
📊 *Dify + Scrapeless Deep SerpAPIによって生成*注意: 他のWebhookサービス(Slack、Microsoft Teamsなど)を使用することもできます。同様のプロセスに従って、マーケットプレイスで適切なツールを検索してください。
ステップ7:ワークフロー構成を完了するために終了ノードを追加します
ワークフローを正しく完了するには、終了ブロックを追加します:
1. 最終ブロックを追加します:
- Webhookステップの後(Webhookをスキップした場合はLLMステップ)の**「+」**ボタンをクリックします
- ブロックメニューから**「終了」**を選択します
2. 終了ブロックを設定します:
- 終了ブロックはワークフローの完了を示します
- ワークフローが完了したときに返される出力変数をオプションで設定できます
- これは、このワークフローをより大きな自動化の一部として使用する場合に便利です
あなたの完全なワークフローは次のようになります:
ステップ8:結果を出力します
🚀 インテリジェンスワークフローを強化する準備はできましたか?
今日Scrapeless Google SERP APIにサインアップし、2,500件の無料APIコールを即座に受け取ります—クレジットカードは不要です。
スケール、精度、AIネイティブワークフローのために構築されたリアルタイムで構造化された検索データを体験してください。👉 無料で始める そして次のプロジェクトをスーパー充電しましょう!
ワークフローデモ
このスマートビジネスニュースモニタリングワークフローがどう機能するかをよりよく理解するために、短いGIFデモを作成しました。リアルタイムの検索結果をDeep SerpApiで取得し、テンプレートブロックでフォーマットし、LLMを使用してデータを分析し、最後にDiscord Webhookを介してインサイトを送信する各ステップを示しています。
5. 成功事例 & パフォーマンス影響
主要金融機関
「反応から先見へ」— 95%の精度によるリアルタイムニュースモニタリング
ある大手金融機関は、銀行規制、評判リスク、マクロ経済イベントに関連する急速に動くニュースサイクルのモニタリングに課題を抱えていました。システムを導入する前、彼らのコンプライアンスとリスクチームは手動メディアトラッキングに大きく依存しており、それは時間がかかり、重要な対応が遅れることがしばしばありました。
Dify + Scrapelessモニタリングシステムを統合した後:
- ニュース検出の待機時間が**80%**削減され、規制または評判リスクへのほぼリアルタイムの認識が可能になりました。
- センチメントベースのアラートモデルの精度が**95%**に向上し、高品質な構造化SERPデータがAI分類器に供給されました。
- アラートが内部のSlackチャンネルやBIダッシュボードに直接プッシュされたため、部門間のコラボレーションが改善されました。
- 結果: リスク軽減のためのウィンドウが数時間から数分に短縮され、ネガティブな報道や誤情報からの潜在的な損害が減少しました。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


