
n8nとScrapelessを使用してインテリジェントなB2Bリードジェネレーションワークフローを構築する方法
Advanced Data Extraction Specialist
あなたの営業プロスペクティングを、Google Search、Crawler、およびClaude AI分析を使用してB2Bリードを見つけ、資格を確認し、強化する自動化ワークフローで変革しましょう。このチュートリアルでは、n8nとScrapelessを使用して強力なリード生成システムを作成する方法を示します。
何を構築するか
このチュートリアルでは、次の機能を持つインテリジェントなB2Bリード生成ワークフローを作成します:
- 定期的または手動で自動的にトリガーされる
- Scrapelessを使用してターゲット市場の企業をGoogleで検索する
- 各企業URLを個別にItem Listsで処理する
- 企業のウェブサイトをクローリングして詳細情報を抽出する
- Claude AIを使用してリードデータの資格を確認し、構造化する
- 資格を確認したリードをGoogle Sheetsに保存する
- Discordに通知を送信する(Slack、メールなどに適応可能)
前提条件
- n8nインスタンス(クラウドまたはセルフホスティング)
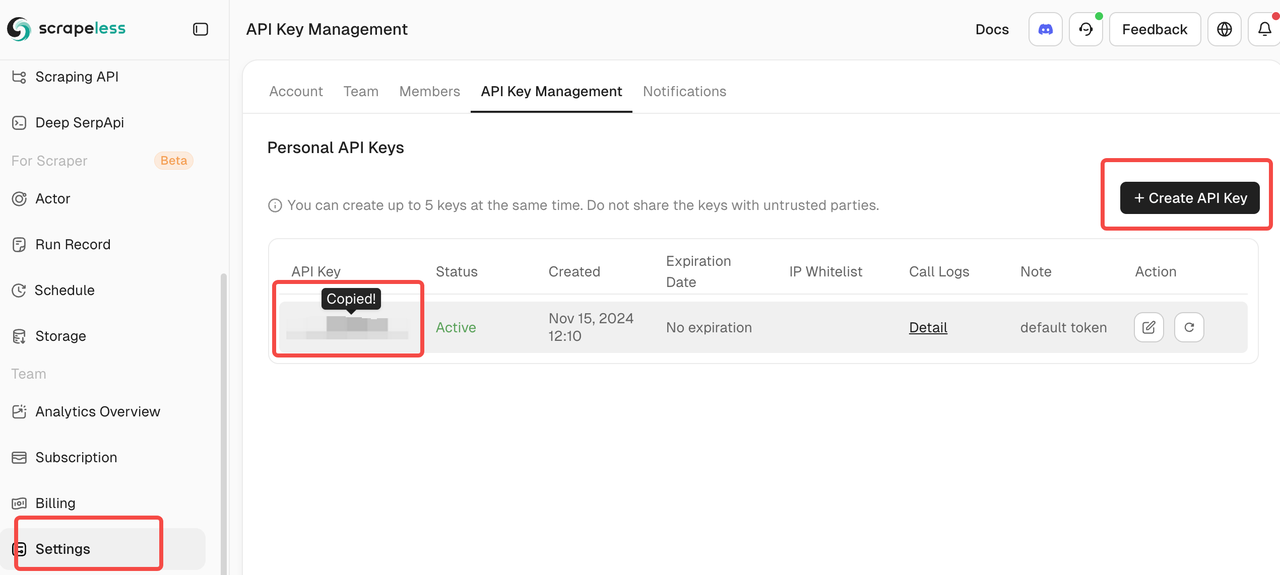
- Scrapeless APIキー(scrapeless.comで取得)
Scrapeless DashboardにログインするだけでAPIキーを取得できます。Scrapelessは無料トライアルクォータを提供します。
- AnthropicからのClaude APIキー
- Google Sheetsへのアクセス
- DiscordウェブフックURL(またはお好みの通知サービス)
- n8nワークフローの基本的な理解
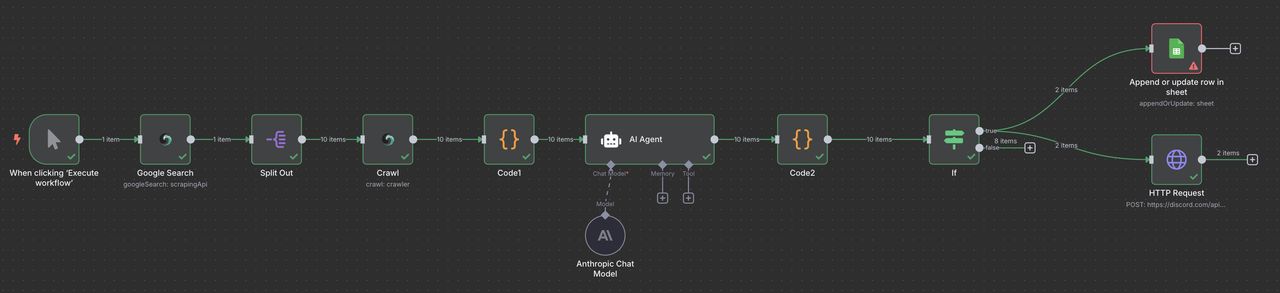
完全なワークフロー概要
最終的なn8nワークフローは以下のようになります:
手動トリガー → Scrapeless Google検索 → Item Lists → Scrapeless Crawler → コード(データ処理) → Claude AI → コード(レスポンスパーサー) → フィルター → Google Sheetsまたは/およびDiscordウェブフック
ステップ1: 手動トリガーの設定
テスト用に手動トリガーから始め、後でスケジュールを追加します。
- n8nで新しいワークフローを作成する
- スタートポイントとして手動トリガーノードを追加する
- これにより、ワークフローを自動化する前にテストできます
なぜ手動から始めるのか?
- 各ステップをテストしてデバッグする
- 自動化前にデータの質を確認する
- 初期結果に基づいてパラメータを調整する
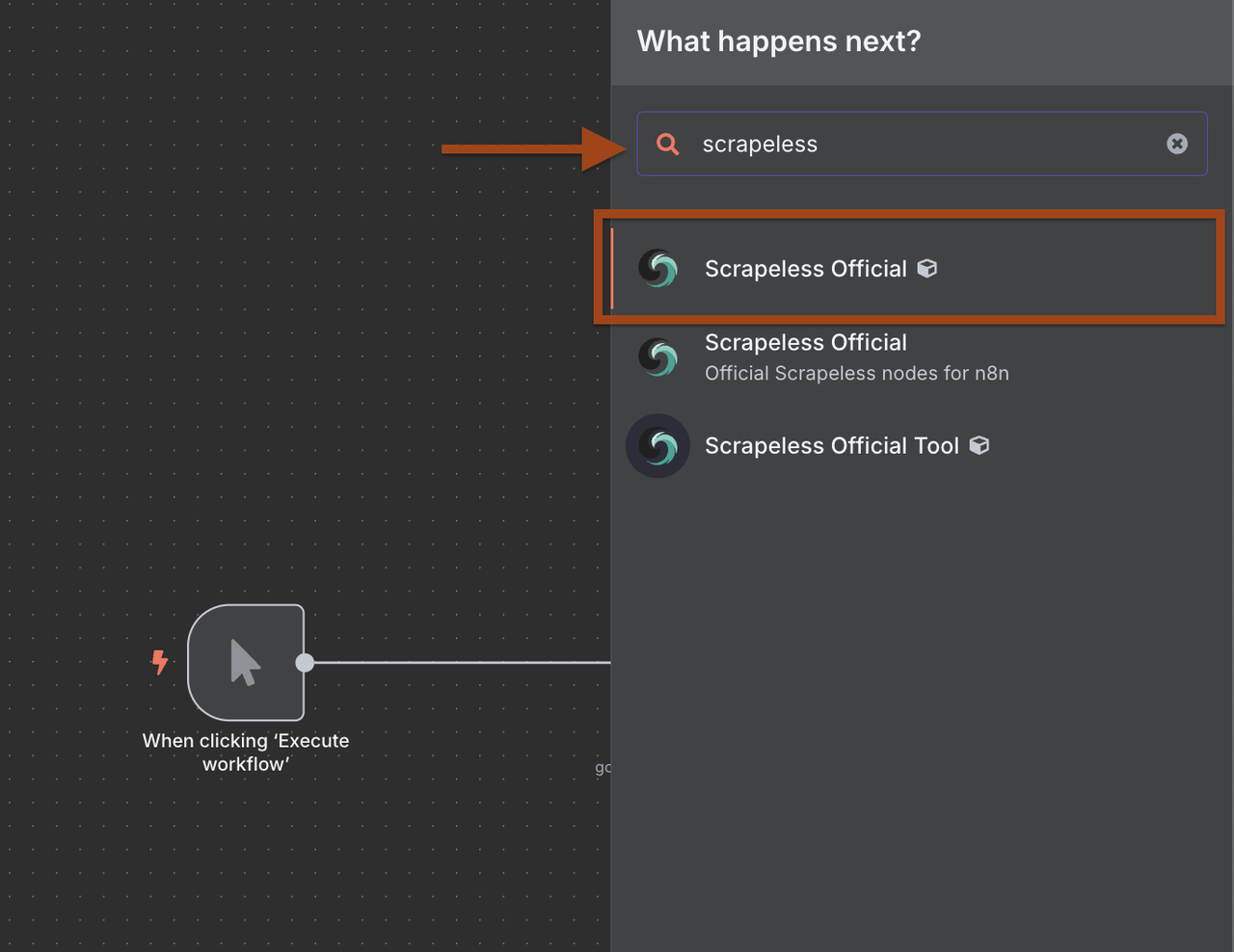
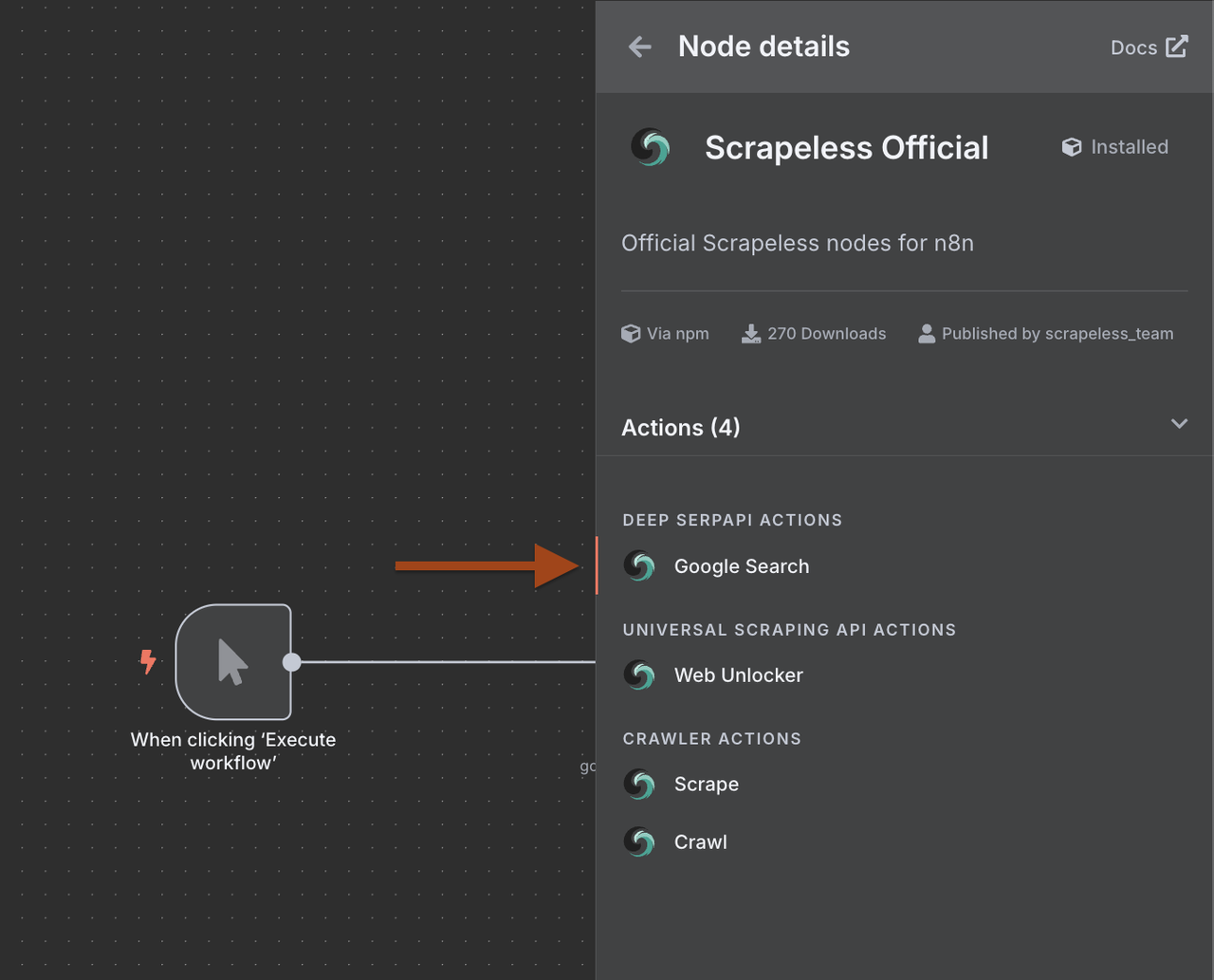
ステップ2: Scrapeless Google検索の追加
次に、ターゲット企業を見つけるためにScrapeless Google検索ノードを追加します。
- トリガーの後に新しいノードを追加するために+をクリック
- ノードライブラリでScrapelessを検索
- Scrapelessを選択し、Google検索操作を選ぶ
1. なぜn8nとScrapelessを使用するのか?
Scrapelessとn8nを統合することで、コードを書かずに高度で耐障害性のあるウェブスクレイパーを作成できます。
利点は次のとおりです:
- Deep SerpApiにアクセスして、1回のリクエストでGoogle SERPデータを取得および抽出。
- Universal Scraping APIを使用して制限を回避し、任意のウェブサイトにアクセス。
- Crawler Scrapeを使用して個別のページを詳細にスクレイピング。
- Crawler Crawlを使用して再帰的にクローリングし、すべてのリンクされたページからデータを取得。
これらの機能により、Scrapelessをn8nでサポートされている350以上のサービス(Google Sheets、Airtable、Notion、Slackなど)とリンクさせるエンドツーエンドのデータフローを構築できます。
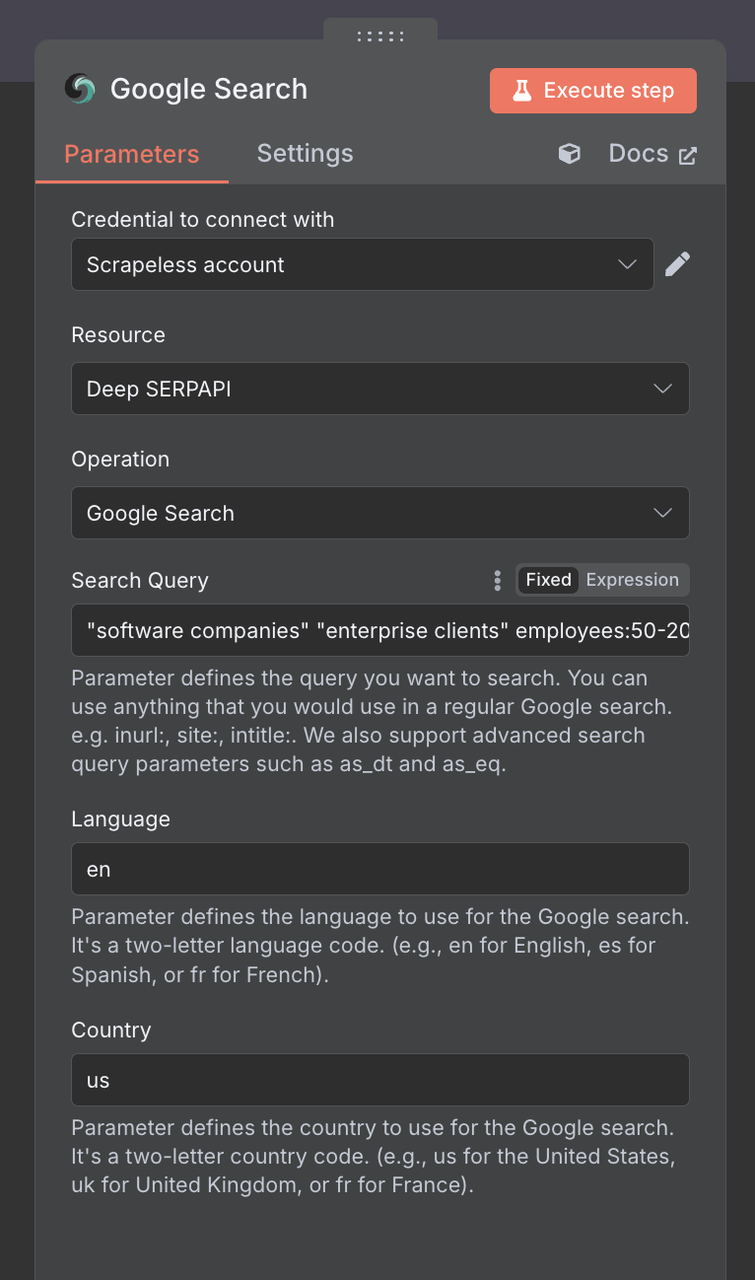
2. Google検索ノードの設定
次に、Scrapeless Google検索ノードを設定する必要があります
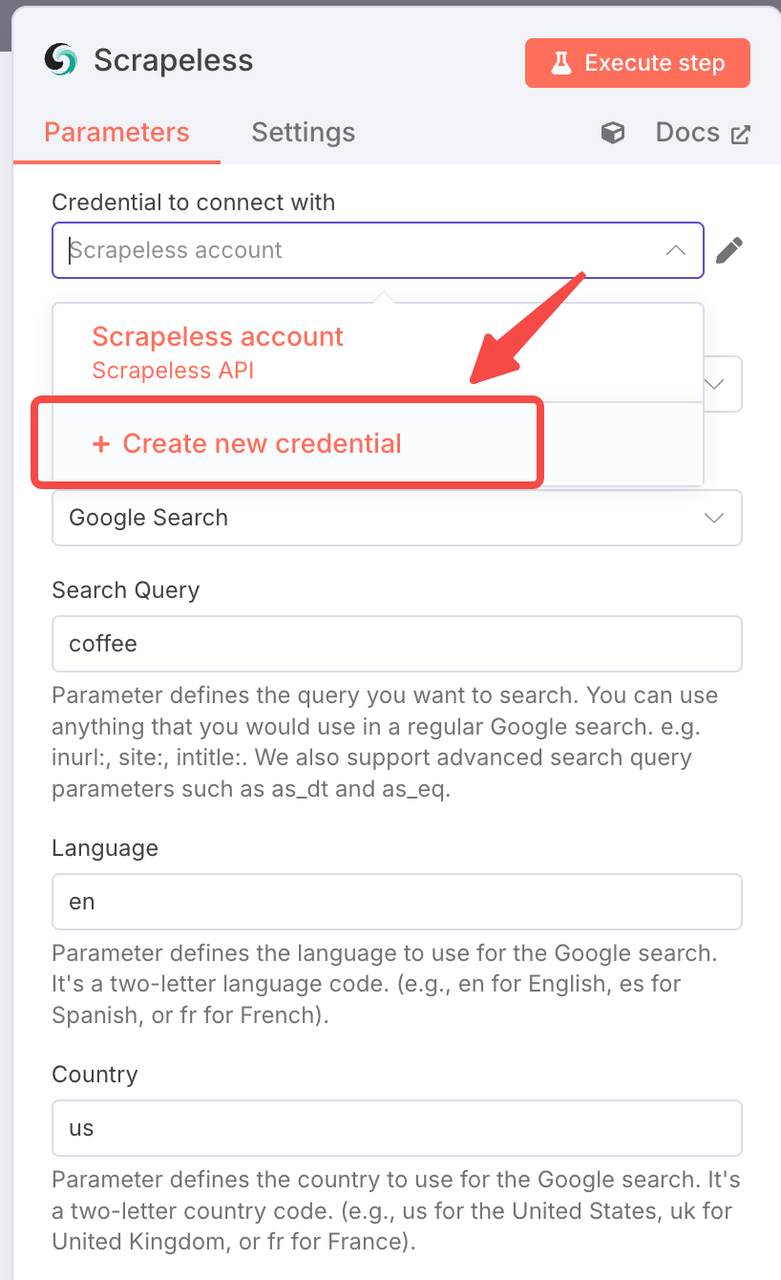
接続設定:
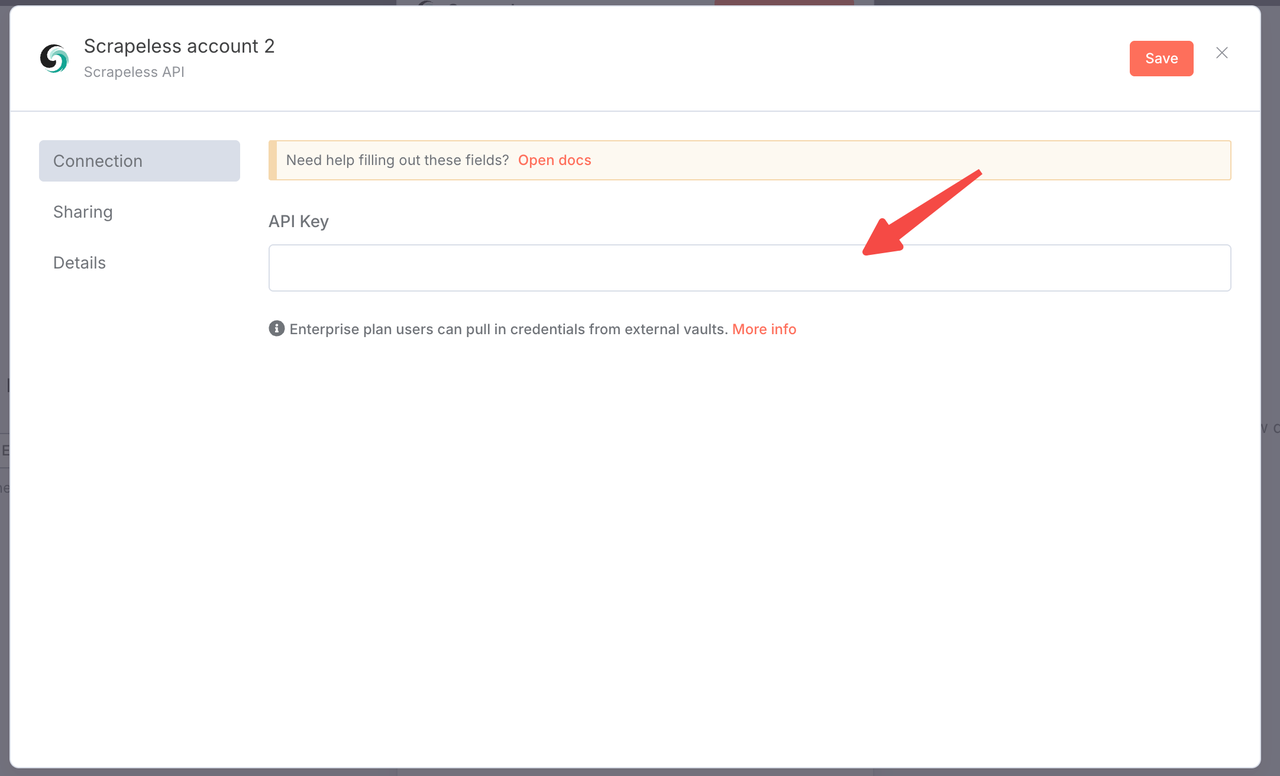
- Scrapeless APIキーを使用して接続を作成
- 「追加」をクリックし、認証情報を入力
検索パラメータ:
検索クエリ:B2Bに焦点を当てた検索語を使用:
"ソフトウェア企業" "企業クライアント" 従業員:50-200
"マーケティング代理店" "B2Bサービス" "デジタルトランスフォーメーション"
"SaaSスタートアップ" "シリーズA" "ベンチャー支援"
"製造業" "デジタルソリューション" ISO国:米国(またはあなたのターゲット市場)
言語:英語
プロのB2B検索戦略:
- 企業規模ターゲティング:従業員:50-200、"ミッドマーケット"
- 資金調達段階: "シリーズA"、 "ベンチャー支援"、 "ブートストラップ"
- 業界特有: "フィンテック"、 "ヘルステック"、 "エドテック"
- 地理: "ニューヨーク", "サンフランシスコ", "ロンドン"
ステップ3: アイテムリストでの結果処理
Google検索は結果の配列を返します。各会社を個別に処理する必要があります。
- Google検索の後にアイテムリストノードを追加します。
- これにより、検索結果を個別のアイテムに分割します。
ヒント: Google検索ノードを実行する
1. アイテムリストの設定:
- 操作: "アイテムを分割"
- 分割フィールド: organic_results - Link
- バイナリデータを含める: いいえ
これにより、各検索結果のための別々の実行分岐が作成され、並行処理が可能になります。
ステップ4: Scrapelessクローラーの追加
今度は、各会社のウェブサイトをクロールして詳細情報を抽出します。
- もう一つのScrapelessノードを追加します。
- クロール操作を選択します(Web Unlockerではありません)。
Crawler Crawlを使用して、再帰的にクロールし、すべてのリンクされたページからデータを取得します。
- 会社データの抽出のために設定します
1. クローラーの設定
- 接続: 同じScrapeless接続を使用
- URL: {{ $json.link }}
- クロール深度: 2(ホームページ + 1レベル深い)
- 最大ページ数: 5(より迅速な処理のための制限)
- 含むパターン: about|contact|team|company|services
- 除外パターン: blog|news|careers|privacy|terms
- フォーマット: markdown(AI処理が容易)
2. CrawlerとWeb Unlockerの比較理由
- Crawlerは複数のページと構造化データを取得
- B2Bに適しており、連絡先情報が/aboutや/contactページに存在する可能性あり
- 会社情報がより包括的
- サイト構造をインテリジェントに追跡
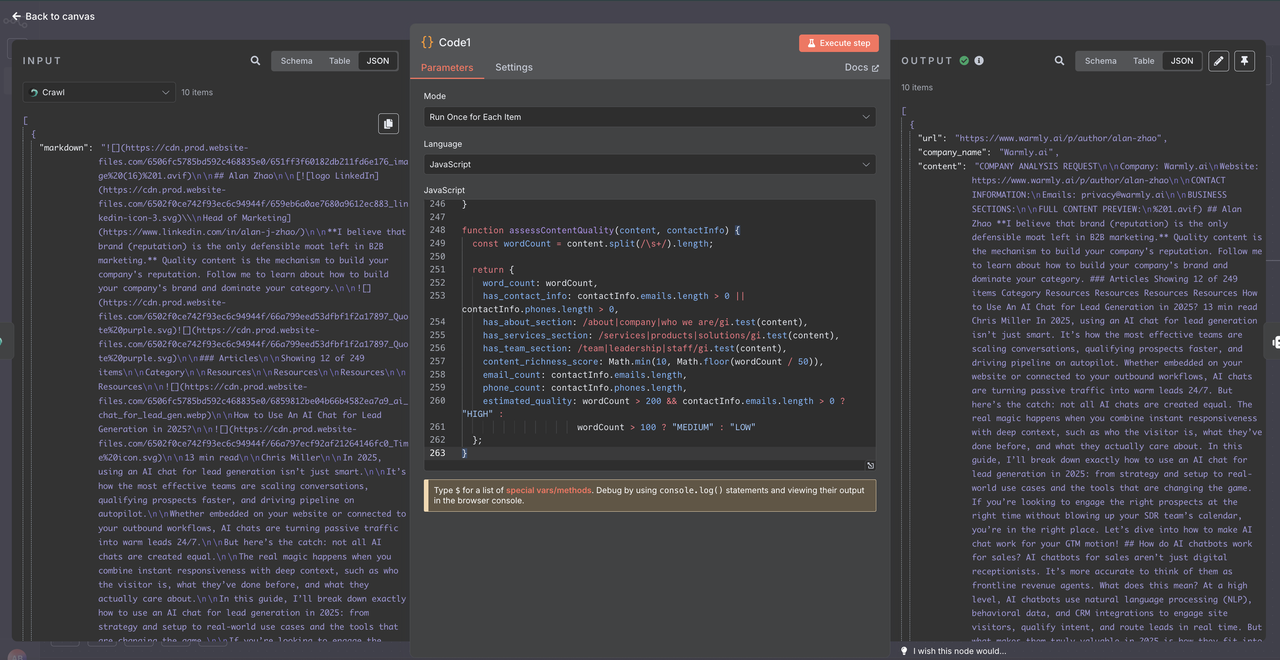
ステップ5: コードノードでのデータ処理
クロールされたデータをClaude AIに送信する前に、適切にクリーンアップし、構造を整える必要があります。Scrapelessクローラーは特定のフォーマットでデータを返すため、注意深い解析が必要です。
- Scrapelessクローラーの後にコードノードを追加します。
- JavaScriptを使って生のクロールデータを解析し、クリーンアップします。
- これにより、AI分析のための一貫したデータ品質が確保されます。
1. Scrapelessクローラーのデータ構造の理解
Scrapelessクローラーはデータを単一のオブジェクトではなく、オブジェクトの配列として返します。
[
{
"markdown": "# 会社のホームページ\n\n私たちの会社へようこそ...",
"metadata": {
"title": "会社名 - ホームページ",
"description": "会社の説明",
"sourceURL": "https://company.com"
}
}
]2. コードノードの設定
console.log("=== SCRAPELESS CRAWLER DATA の処理 ===");
try {
// データは配列として到着します
const crawlerDataArray = $json;
console.log("データタイプ:", typeof crawlerDataArray);
console.log("配列か:", Array.isArray(crawlerDataArray));
console.log("配列の長さ:", crawlerDataArray?.length || 0);
// 配列が空か確認
if (!Array.isArray(crawlerDataArray) || crawlerDataArray.length === 0) {
console.log("❌ 空または無効なクローラーデータ");
return {
url: "不明",
company_name: "データなし",
content: "",
error: "空のクローラー応答",
processing_failed: true,
skip_reason: "クローラーからデータが返されませんでした"
};
}
// 配列の最初の要素を取得
const crawlerResponse = crawlerDataArray[0];
// マークダウンサムコンテンツの抽出
const markdownContent = crawlerResponse?.markdown || "";
// メタデータの抽出(利用可能な場合)
const metadata = crawlerResponse?.metadata || {};
// 基本情報
const sourceURL = metadata.sourceURL || metadata.url || extractURLFromContent(markdownContent);
const companyName = metadata.title || metadata.ogTitle || extractCompanyFromContent(markdownContent);
const description = metadata.description || metadata.ogDescription || "";
console.log(`処理中: ${companyName}`);
console.log(`URL: ${sourceURL}`);
console.log(`コンテンツ長: ${markdownContent.length}文字`);
// コンテンツの品質検証
ja
if (!markdownContent || markdownContent.length < 100) {
return {
url: sourceURL,
company_name: companyName,
content: "",
error: "クローラーからのコンテンツが不十分です",
processing_failed: true,
raw_content_length: markdownContent.length,
skip_reason: "コンテンツが短すぎるか空です"
};
}
// マークダウンコンテンツのクリーンアップと構造化
let cleanedContent = cleanMarkdownContent(markdownContent);
// 連絡先情報の抽出
const contactInfo = extractContactInformation(cleanedContent);
// 重要なビジネスセクションの抽出
const businessSections = extractBusinessSections(cleanedContent);
// Claude AIのためのコンテンツを構築
const contentForAI = buildContentForAI({
companyName,
sourceURL,
description,
businessSections,
contactInfo,
cleanedContent
});
// コンテンツの質に関するメトリクス
const contentQuality = assessContentQuality(cleanedContent, contactInfo);
const result = {
url: sourceURL,
company_name: companyName,
content: contentForAI,
raw_content_length: markdownContent.length,
processed_content_length: contentForAI.length,
extracted_emails: contactInfo.emails,
extracted_phones: contactInfo.phones,
content_quality: contentQuality,
metadata_info: {
has_title: !!metadata.title,
has_description: !!metadata.description,
site_name: metadata.ogSiteName || "",
page_title: metadata.title || ""
},
processing_timestamp: new Date().toISOString(),
processing_status: "成功"
};
console.log(`✅ ${companyName}の処理が成功しました`);
return result;
} catch (error) {
console.error("❌ クローラーデータの処理中にエラーが発生しました:", error);
return {
url: "不明",
company_name: "処理エラー",
content: "",
error: error.message,
processing_failed: true,
processing_timestamp: new Date().toISOString()
};
}
// ========== ユーティリティ関数 ==========
function extractURLFromContent(content) {
// マークダウンコンテンツからURLを抽出しようとする
const urlMatch = content.match(/https?:\/\/[^\s\)]+/);
return urlMatch ? urlMatch[0] : "不明";
}
function extractCompanyFromContent(content) {
// コンテンツから会社名を抽出しようとする
const titleMatch = content.match(/^#\s+(.+)$/m);
if (titleMatch) return titleMatch[1];
// ドメインを抽出するためにメールアドレスを検索
const emailMatch = content.match(/@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,})/);
if (emailMatch) {
const domain = emailMatch[1].replace('www.', '');
return domain.split('.')[0].charAt(0).toUpperCase() + domain.split('.')[0].slice(1);
}
return "不明な会社";
}
function cleanMarkdownContent(markdown) {
return markdown
// ナビゲーション要素を削除
.replace(/^\[Skip to content\].*$/gmi, '')
.replace(/^\[.*\]\(#.*\)$/gmi, '')
// マークダウンリンクを削除するがテキストは保持
.replace(/\[([^\]]+)\]\([^)]+\)/g, '$1')
// 画像とBase64を削除
.replace(/!\[([^\]]*)\]\([^)]*\)/g, '')
.replace(/<Base64-Image-Removed>/g, '')
// クッキー/プライバシーに関する言及を削除
.replace(/.*?(cookie|privacy policy|terms of service).*?\n/gi, '')
// 複数のスペースをクリーンアップ
.replace(/\s+/g, ' ')
// 複数の空行を削除
.replace(/\n\s*\n\s*\n/g, '\n\n')
.trim();
}
function extractContactInformation(content) {
// メール用の正規表現
const emailRegex = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}/g;
// 電話のための正規表現(国際サポート付き)
const phoneRegex = /(?:\+\d{1,3}\s?)?\d{3}\s?\d{3}\s?\d{3,4}|\(\d{3}\)\s?\d{3}-?\d{4}/g;
const emails = [...new Set((content.match(emailRegex) || [])
.filter(email => !email.includes('example.com'))
.slice(0, 3))];
const phones = [...new Set((content.match(phoneRegex) || [])
.filter(phone => phone.replace(/\D/g, '').length >= 9)
.slice(0, 2))];
return { emails, phones };
}
function extractBusinessSections(content) {
const sections = {};
// 重要なセクションを検索
const lines = content.split('\n');
let currentSection = '';
let currentContent = '';
for (let i = 0; i < lines.length; i++) {
const line = lines[i].trim();
// ヘッダー検出
if (line.startsWith('#')) {
// 前のセクションを保存
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
// 新しいセクション
const title = line.replace(/^#+\s*/, '').toLowerCase();
if (title.includes('about') || title.includes('service') ||
title.includes('contact') || title.includes('company')) {
currentSection = title.includes('about') ? 'about' :
title.includes('service') ? 'services' :
title.includes('contact') ? 'contact' : 'company';
currentContent = '';
} else {
currentSection = '';
}
} else if (currentSection && line) {
currentContent += line + '\n';
}}
// 最後のセクションを保存
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
return sections;
}
function buildContentForAI({ companyName, sourceURL, description, businessSections, contactInfo, cleanedContent }) {
let aiContent = `会社の分析リクエスト\n\n`;
aiContent += `会社名: ${companyName}\n`;
aiContent += `ウェブサイト: ${sourceURL}\n`;
if (description) {
aiContent += `説明: ${description}\n`;
}
aiContent += `\n連絡先情報:\n`;
if (contactInfo.emails.length > 0) {
aiContent += `メール: ${contactInfo.emails.join(', ')}\n`;
}
if (contactInfo.phones.length > 0) {
aiContent += `電話: ${contactInfo.phones.join(', ')}\n`;
}
aiContent += `\nビジネスセクション:\n`;
for (const [section, content] of Object.entries(businessSections)) {
if (content) {
aiContent += `\n${section.toUpperCase()}:\n${content}\n`;
}
}
// メインコンテンツを追加(制限あり)
aiContent += `\nフルコンテンツプレビュー:\n`;
aiContent += cleanedContent.substring(0, 2000);
// Claude APIの最終制限
return aiContent.substring(0, 6000);
}
function assessContentQuality(content, contactInfo) {
const wordCount = content.split(/\s+/).length;
return {
word_count: wordCount,
has_contact_info: contactInfo.emails.length > 0 || contactInfo.phones.length > 0,
has_about_section: /about|company|私たちについて/gi.test(content),
has_services_section: /services|products|solutions/gi.test(content),
has_team_section: /team|leadership|staff/gi.test(content),
content_richness_score: Math.min(10, Math.floor(wordCount / 50)),
email_count: contactInfo.emails.length,
phone_count: contactInfo.phones.length,
estimated_quality: wordCount > 200 && contactInfo.emails.length > 0 ? "高" :
wordCount > 100 ? "中" : "低"
};
}3. コード処理ステップを追加する理由
- データ構造の適応: Scrapeless配列形式をClaudeに適した構造に変換
- コンテンツ最適化: ビジネス関連セクションを抽出し、優先順位を付ける
- 連絡先発見: 自動でメールアドレスと電話番号を識別
- 品質評価: コンテンツの豊かさと完全性を評価
- トークン効率: 重要な情報を保持しつつ、コンテンツサイズを削減
- エラーハンドリング: 失敗したクローリングや不十分なコンテンツを優雅に管理
- デバッグサポート: トラブルシューティングのための包括的なロギング
4. 期待される出力構造
処理後、各リードはこの構造化フォーマットを持つことになります:
{
"url": "https://company.com",
"company_name": "会社名",
"content": "会社の分析リクエスト\n\n会社名: ...",
"raw_content_length": 50000,
"processed_content_length": 2500,
"extracted_emails": ["contact@company.com"],
"extracted_phones": ["+1-555-123-4567"],
"content_quality": {
"word_count": 5000,
"has_contact_info": true,
"estimated_quality": "高",
"content_richness_score": 10
},
"processing_status": "成功"
}
これにより、データフォーマットを検証し、処理の問題をトラブルシューティングできます。
5. コードノードの利点
- コスト削減: より小さく、クリーンなコンテンツ = より少ないClaude APIトークン
- より良い結果: 集中したコンテンツがAI分析の精度を向上
- エラー回復: 空の応答と失敗したクローリングを処理
- 柔軟性: 結果に基づいて解析ロジックを簡単に調整
- 品質指標: リードデータの完全性を内蔵評価
ステップ6: ClaudeによるAI駆動のリード資格認定
Claude AIを使用して、処理され構造化されたクローリングコンテンツからリード情報を抽出し、資格を認定します。
- コードノードの後にAIエージェントノードを追加
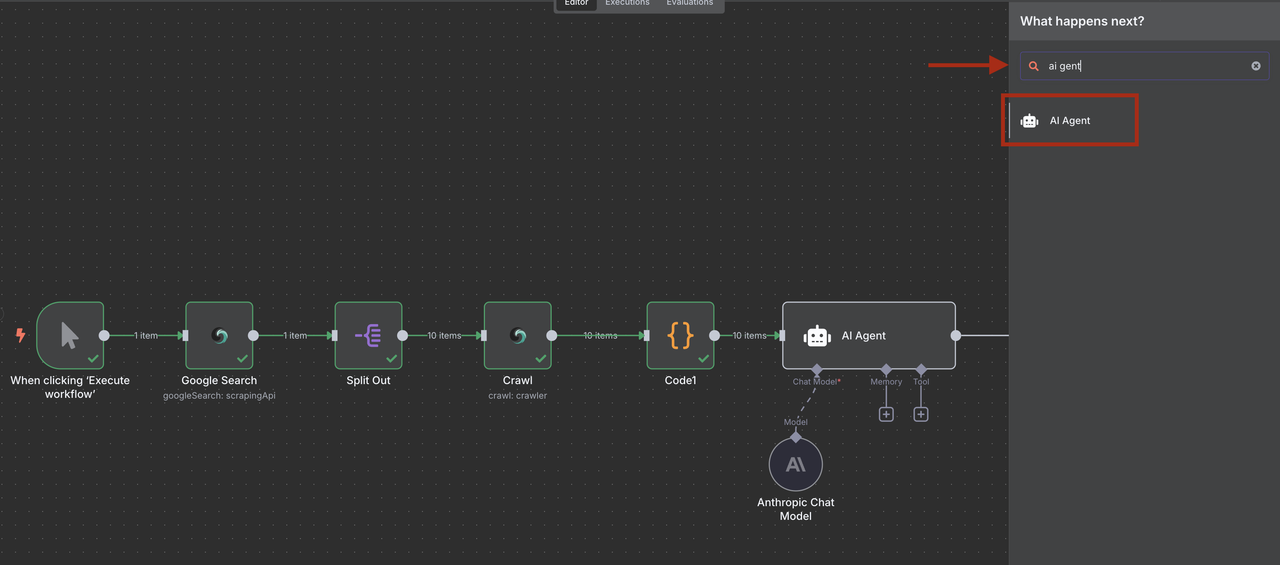
- Anthropic Claudeノードを追加し、リード分析のために設定
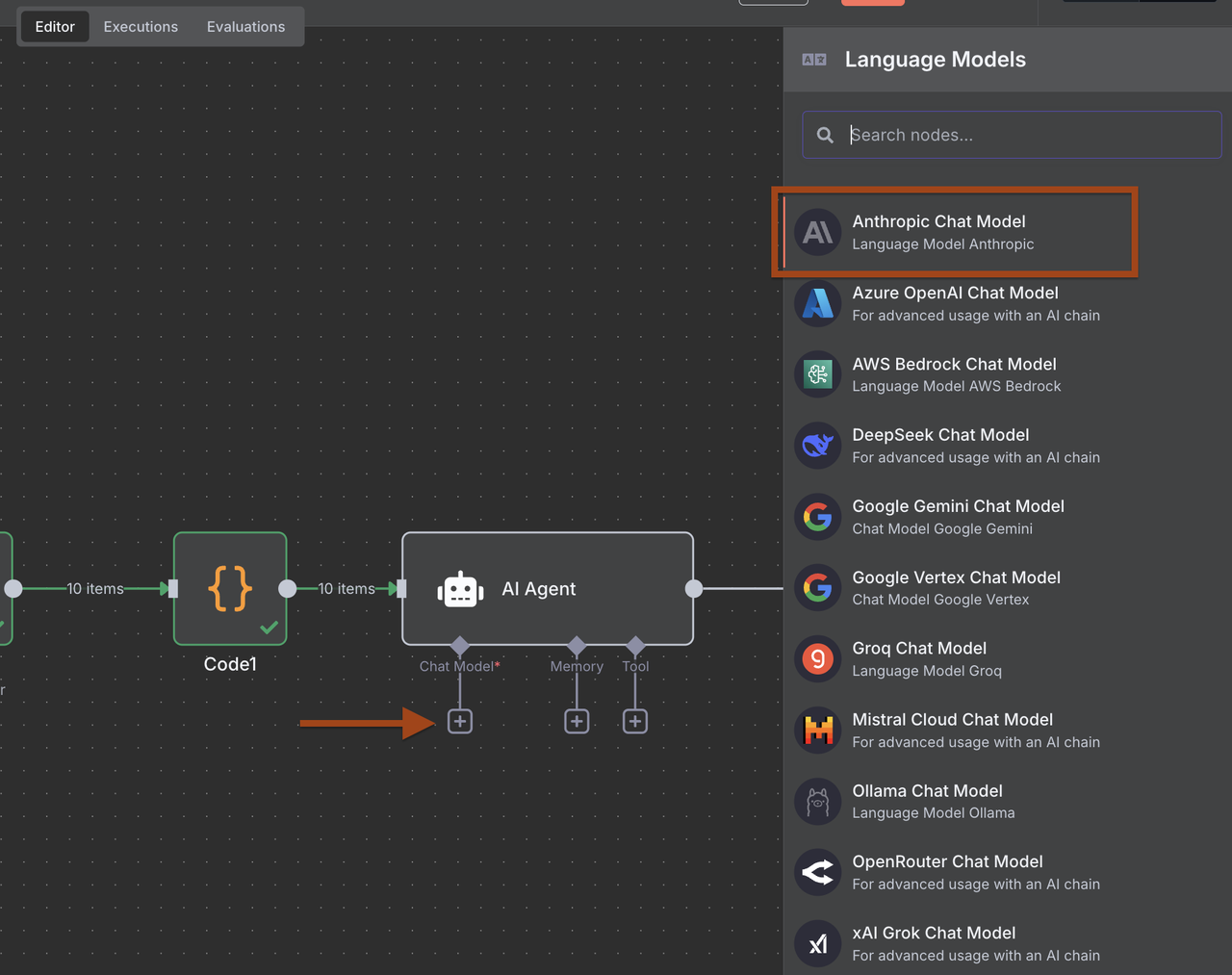
- 構造化されたB2Bリードデータを抽出するプロンプトを設定
AIエージェントをクリック -> オプションを追加 -> システムメッセージをコピー&ペースト
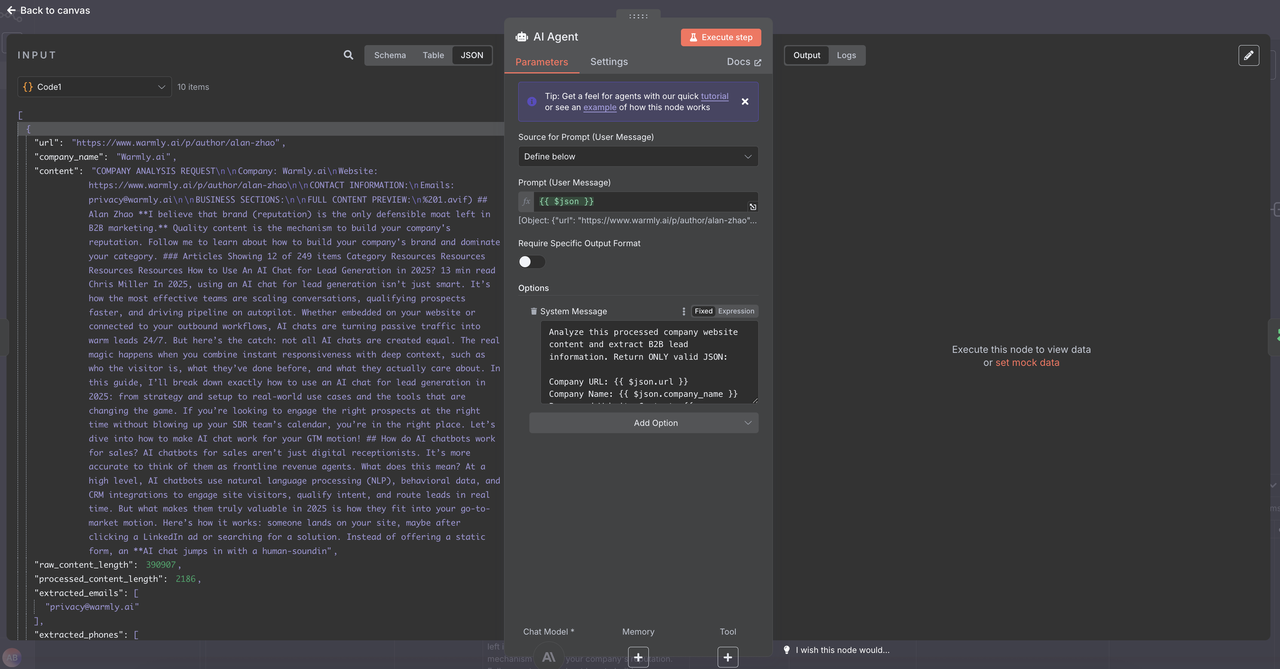
システムリード抽出プロンプト:
この処理された会社のウェブサイトコンテンツを分析し、B2Bリード情報を抽出してください。正しいJSONのみを返してください:
会社のURL: {{ $json.url }}
会社名: {{ $json.company_name }}
処理されたウェブサイトのコンテンツ: {{ $json.content }}
コンテンツ品質評価: {{ $json.content_quality }}
事前に抽出された連絡先情報:
メール: {{ $json.extracted_emails }}
電話: {{ $json.extracted_phones }}
メタデータ情報: {{ $json.metadata_info }}処理の詳細:
生のコンテンツの長さ: {{ $json.raw_content_length }} 文字
処理されたコンテンツの長さ: {{ $json.processed_content_length }} 文字
処理のステータス: {{ $json.processing_status }}
この構造化データに基づいて、このB2Bリードを抽出して評価します。正しいJSONのみを返します:
{
"company_name": "コンテンツからの公式な会社名",
"industry": "特定された主要な業界/セクター",
"company_size": "従業員数またはサイズカテゴリ(スタートアップ/中小企業/中堅/大企業)",
"location": "本社の場所または主要市場",
"contact_email": "抽出されたメールからの最良の一般的または営業用メール",
"phone": "抽出された電話からの主要な電話番号",
"key_services": ["コンテンツに基づいて提供される主要なサービス/製品"],
"target_market": "対象とする市場(B2B/B2C、中小企業/大企業、特定の業界)",
"technologies": ["言及された技術スタック、プラットフォーム、ツール"],
"funding_stage": "言及されている場合の資金調達段階(シード/シリーズA/B/C/公開/非公開)",
"business_model": "収益モデル(SaaS/コンサルティング/製品/マーケットプレイス)",
"social_presence": {
"linkedin": "コンテンツ内で見つかったLinkedIn会社URL",
"twitter": "見つかったTwitterハンドル"
},
"lead_score": 8.5,
"qualification_reasons": ["このリードが適格であるかどうかの具体的な理由"],
"decision_makers": ["見つかった主要な連絡先の名前と肩書き"],
"next_actions": ["会社プロフィールに基づく推奨フォローアップ戦略"],
"content_insights": {
"website_quality": "コンテンツの豊かさに基づく専門的/基本的/貧弱",
"recent_activity": "言及された最近のニュース、資金調達、またはアップデート",
"competitive_positioning": "競合に対しての位置づけ"
}
}
強化スコア基準(1-10):
9-10: 完璧なICPフィット + 完全な連絡先情報 + 高成長シグナル + プロフェッショナルなコンテンツ
7-8: 良いICPフィット + 一部の連絡先情報 + 安定した会社 + 質の高いコンテンツ
5-6: 中程度のフィット + 限られた連絡先情報 + 基本的なコンテンツ + 研究の必要性
3-4: 低いフィット + 最小限の情報 + 低品質のコンテンツ + 誤った対象市場
1-2: 不適格 + 連絡先情報なし + 処理失敗 + 無関係
考慮すべきスコアリング要因:
コンテンツ品質スコア: {{ $json.content_quality.content_richness_score }}/10
連絡先情報: {{ $json.content_quality.email_count }} のメール, {{ $json.content_quality.phone_count }} の電話
コンテンツの完全性: {{ $json.content_quality.has_about_section }}, {{ $json.content_quality.has_services_section }}
処理の成功: {{ $json.processing_status }}
コンテンツのボリューム: {{ $json.content_quality.word_count }} 単語
指示:
抽出された_emailsおよび_extracted_phonesからの事前抽出された連絡情報のみを使用
company_nameは、生のコンテンツではなく処理されたcompany_nameフィールドに基づく
lead_scoreを決定する際にcontent_qualityメトリックを考慮
processing_statusが「SUCCESS」でない場合は、スコアを大幅に下げる
欠落している情報にはnullを使用 - データを幻想しない
スコアリングには慎重を期す - 過少評価が過大評価よりも良い
提供された構造化コンテンツに基づいて、B2Bの関連性とICPフィットに焦点を当てる
プロンプトの構造により、フィルタリングがより信頼性の高いものになり、Claudeが一貫した構造化入力を受け取るようになります。これにより、リードスコアがより正確になり、ワークフローの次のステップでの適格性判断が改善されます。
## ステップ7: Claude AI応答の解析
リードをフィルタリングする前に、マークダウン形式でラップされる可能性のあるClaudeのJSON応答を適切に解析する必要があります。
1. AIエージェント(Claude)の後にコードノードを追加
2. ClaudeのJSON応答を解析してクリーニングするように設定
### 1. コードノード設定// Claude AI JSON応答を解析するコード
console.log("=== CLAUDE AI RESPONSEの解析 ===");
try {
// Claudeの応答は「出力」フィールドに到着します
const claudeOutput = $json.output || "";
console.log("Claude出力の長さ:", claudeOutput.length);
console.log("Claude出力プレビュー:", claudeOutput.substring(0, 200));
// Claudeのマークダウン応答からJSONを抽出
let jsonString = claudeOutput;
// マークダウンのバックティックを削除
if (jsonString.includes('json')) {
const jsonMatch = jsonString.match(/json\s*([\s\S]?)\s/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
} else if (jsonString.includes('')) {
// フォールバックの場合
const jsonMatch = jsonString.match(/\s*([\s\S]?)\s```/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
}
// 追加のクリーニング
jsonString = jsonString.trim();
console.log("抽出されたJSON文字列:", jsonString.substring(0, 300));
// JSONを解析
const leadData = JSON.parse(jsonString);
console.log("成功裏にリードデータを解析しました:", leadData.company_name);
console.log("リードスコア:", leadData.lead_score);
```javascript
console.log("連絡先メール:", leadData.contact_email);
// バリデーションとデータクリーニング
const cleanedLead = {
company_name: leadData.company_name || "不明",
industry: leadData.industry || null,
company_size: leadData.company_size || null,
location: leadData.location || null,
contact_email: leadData.contact_email || null,
phone: leadData.phone || null,
key_services: Array.isArray(leadData.key_services) ? leadData.key_services : [],
target_market: leadData.target_market || null,
technologies: Array.isArray(leadData.technologies) ? leadData.technologies : [],
funding_stage: leadData.funding_stage || null,
business_model: leadData.business_model || null,
social_presence: leadData.social_presence || { linkedin: null, twitter: null },
lead_score: typeof leadData.lead_score === 'number' ? leadData.lead_score : 0,
qualification_reasons: Array.isArray(leadData.qualification_reasons) ? leadData.qualification_reasons : [],
decision_makers: Array.isArray(leadData.decision_makers) ? leadData.decision_makers : [],
next_actions: Array.isArray(leadData.next_actions) ? leadData.next_actions : [],
content_insights: leadData.content_insights || {},
// フィルタリング用のメタ情報
is_qualified: leadData.lead_score >= 6 && leadData.contact_email !== null,
has_contact_info: !!(leadData.contact_email || leadData.phone),
processing_timestamp: new Date().toISOString(),
claude_processing_status: "SUCCESS"
};
console.log(`✅ リード処理完了: ${cleanedLead.company_name} (スコア: ${cleanedLead.lead_score}, 資格: ${cleanedLead.is_qualified})`);
return cleanedLead;
} catch (error) {
console.error("❌ Claude応答解析中のエラー:", error);
console.error("生の出力:", $json.output);
// 構造化エラー応答
return {
company_name: "Claude解析エラー",
industry: null,
company_size: null,
location: null,
contact_email: null,
phone: null,
key_services: [],
target_market: null,
technologies: [],
funding_stage: null,
business_model: null,
social_presence: { linkedin: null, twitter: null },
lead_score: 0,
qualification_reasons: [`Claude解析失敗: ${error.message}`],
decision_makers: [],
next_actions: ["Claude応答解析を修正", "JSON形式を確認"],
content_insights: {},
is_qualified: false,
has_contact_info: false,
processing_timestamp: new Date().toISOString(),
claude_processing_status: "FAILED",
parsing_error: error.message,
raw_claude_output: $json.output || "出力を受信していません"
};
}2. なぜClaude応答解析を追加するのか?
- マークダウン処理: Claudeの応答からjson形式を取り除く
- データバリデーション: すべてのフィールドが適切な型とデフォルトを持つことを保証
- エラー回復: JSON解析の失敗を優雅に処理
- フィルタリング準備: フィルタリングを容易にするために計算フィールドを追加
- デバッグサポート: トラブルシューティングのための包括的なログ記録
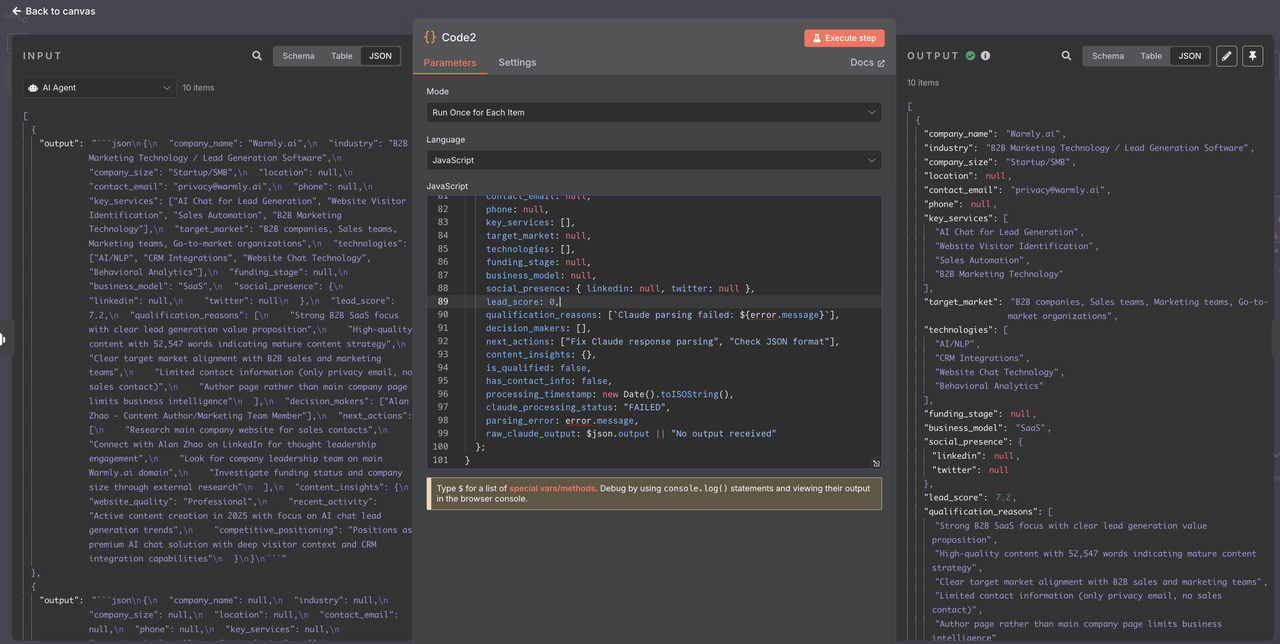
ステップ8: リードフィルタリングと品質管理
解析され、検証されたデータを使用して、資格スコアとデータの完全性に基づいてリードをフィルタリングします。
- Claude応答解析の後にIFノードを追加
- 強化された資格基準を設定
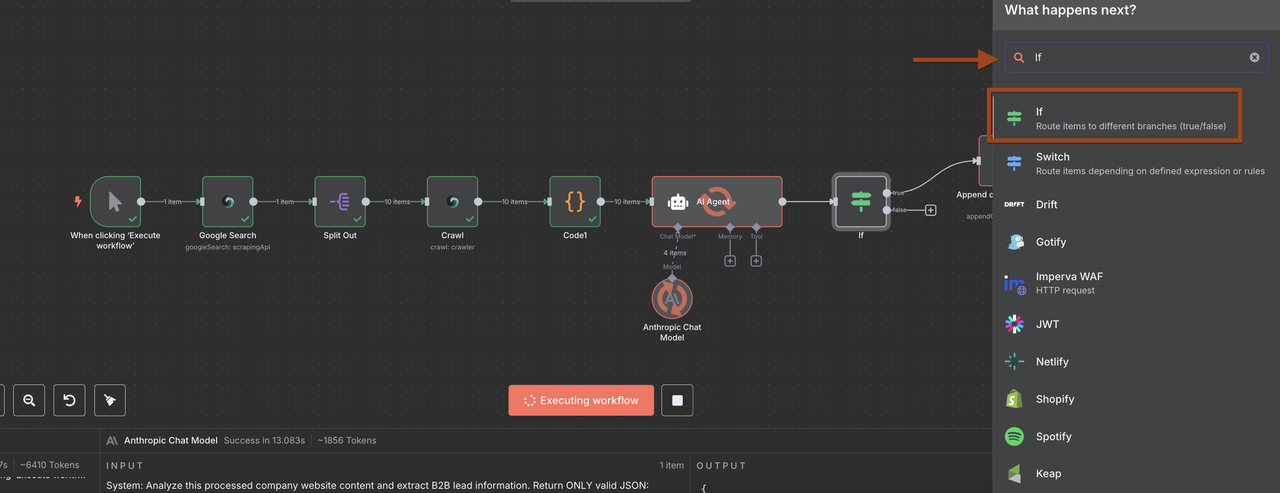
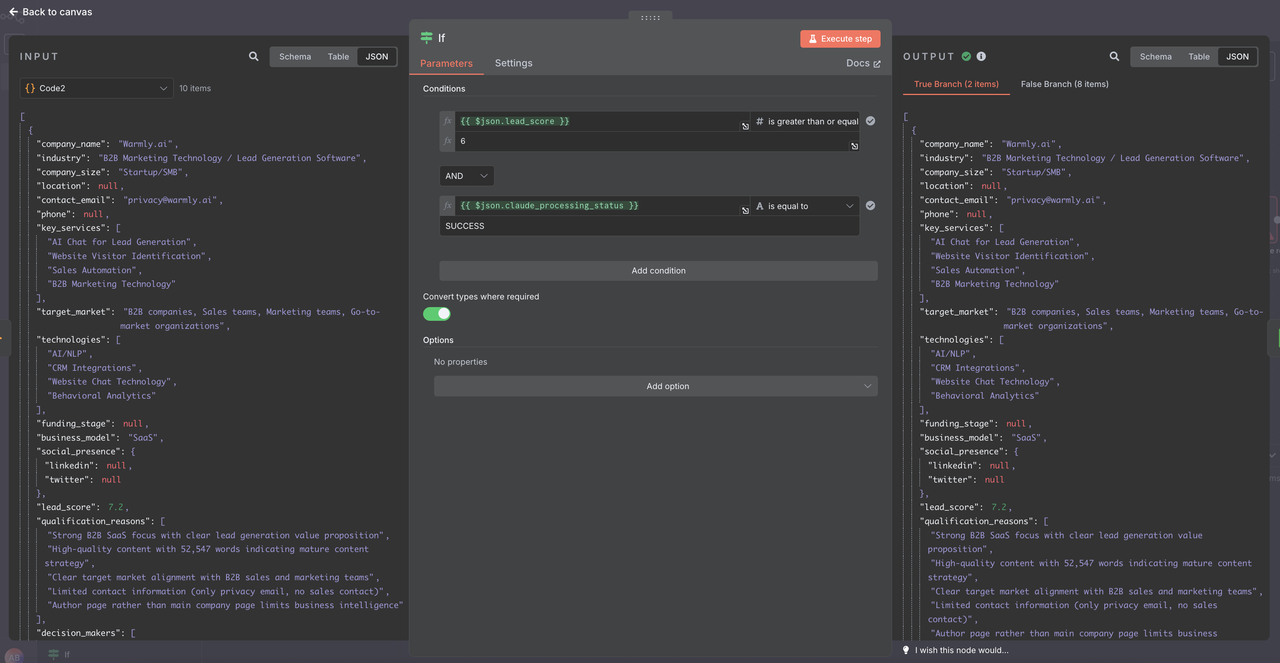
1. 新しいIFノードの構成
データが適切に解析されたので、IFノードでこれらの条件を使用します。
1: 複数の条件を追加
条件1:
- フィールド: {{ $json.lead_score }}
- 演算子: 以上または等しい
- 値: 6
条件2:
- フィールド: {{ $json.claude_processing_status }}
- 演算子: 等しい
- 値: SUCCESS
オプション: 必要に応じて型を変換
- TRUE
2. フィルタリングの利点
- 品質保証: 資格のあるリードのみが保存される
- コスト最適化: 低品質のリードの処理を防ぐ
- データ整合性: 保存前に解析データが有効であることを保証
- デバッグ機能: 解析失敗がキャッチされ、ログに記録される
ステップ9: Google Sheetsにリードを保存
資格のあるリードをGoogle Sheetsデータベースに保存し、簡単にアクセスと管理を行います。
- フィルタの後にGoogle Sheetsノードを追加
- 新しいリードを追加するように構成
ただし、データを管理する方法は任意です。
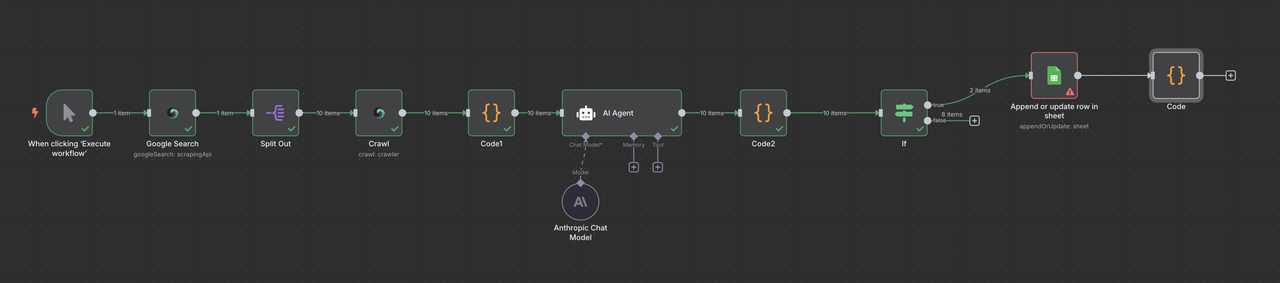
Google Sheetsのセットアップ:
1. 「B2Bリードデータベース」という名前のスプレッドシートを作成します。
2. 列を設定します:
- 会社名
- 業界
- 会社サイズ
- 所在地
- 連絡先メール
- 電話
- ウェブサイト
- リードスコア
- 追加日
- 資格ノート
- 次のアクション
私の方では、Discordのウェブフックを直接使用することを選びます。
## ステップ9-2:Discord通知(他のサービスにも適応可能)
新しい適格なリードのリアルタイム通知を送信します。
1. Discordのウェブフック用のHTTPリクエストノードを追加します。
2. Discord特有のペイロードフォーマットを設定します。
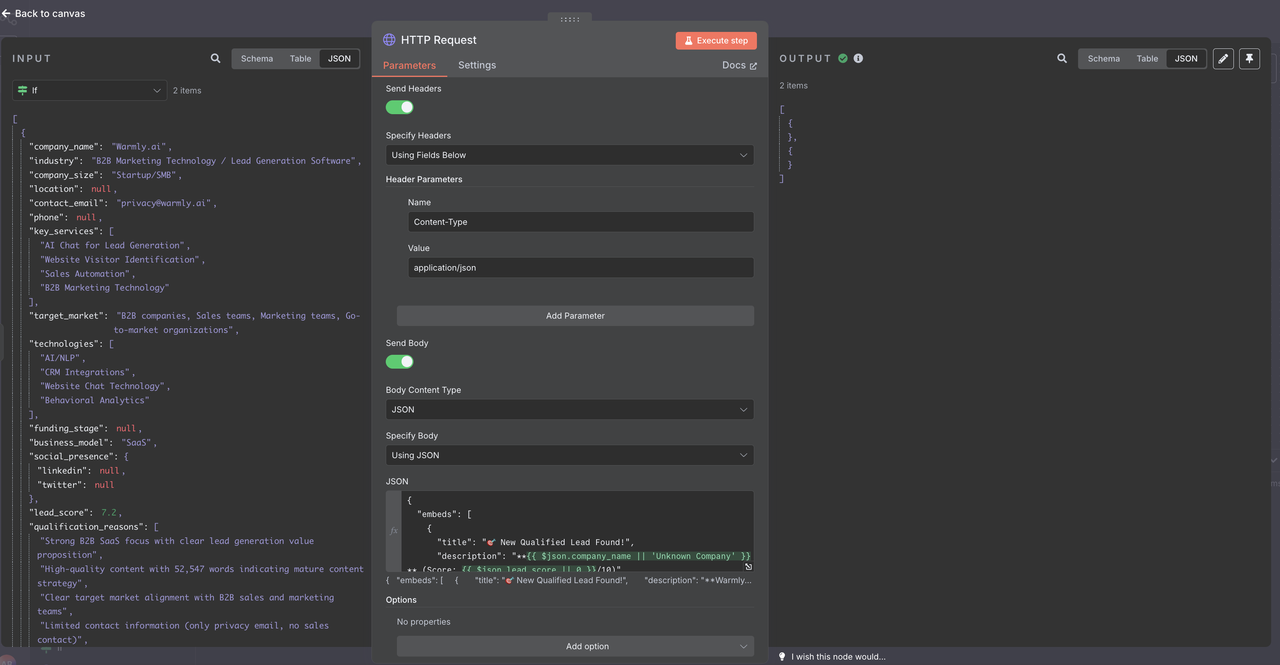
**Discordウェブフックの設定:**
- メソッド:POST
- URL:あなたのDiscordウェブフックURL
- ヘッダー:Content-Type: application/json
**Discordメッセージペイロード:**{
"embeds": [
{
"title": "🎯 新しい適格リードが見つかりました!",
"description": "{{ $json.company_name || '不明な会社' }} (スコア: {{ $json.lead_score || 0 }}/10)",
"color": 3066993,
"fields": [
{
"name": "業界",
"value": "{{ $json.industry || '指定されていません' }}",
"inline": true
},
{
"name": "サイズ",
"value": "{{ $json.company_size || '指定されていません' }}",
"inline": true
},
{
"name": "所在地",
"value": "{{ $json.location || '指定されていません' }}",
"inline": true
},
{
"name": "連絡先",
"value": "{{ $json.contact_email || 'メールが見つかりません' }}",
"inline": false
},
{
"name": "電話",
"value": "{{ $json.phone || '電話が見つかりません' }}",
"inline": false
},
{
"name": "サービス",
"value": "{{ $json.key_services && $json.key_services.length > 0 ? $json.key_services.slice(0, 3).join(', ') : '指定されていません' }}",
"inline": false
},
{
"name": "ウェブサイト",
"value": "[ウェブサイトを訪問]({{ $node['Code2'].json.url || '#' }})",
"inline": false
},
{
"name": "適格な理由",
"value": "{{ $json.qualification_reasons && $json.qualification_reasons.length > 0 ? $json.qualification_reasons.slice(0, 2).join(' • ') : '標準的な資格基準が満たされました' }}",
"inline": false
}
],
"footer": {
"text": "n8nリード生成ワークフローによって生成されました"
},
"timestamp": ""
}
]
}
## 結果
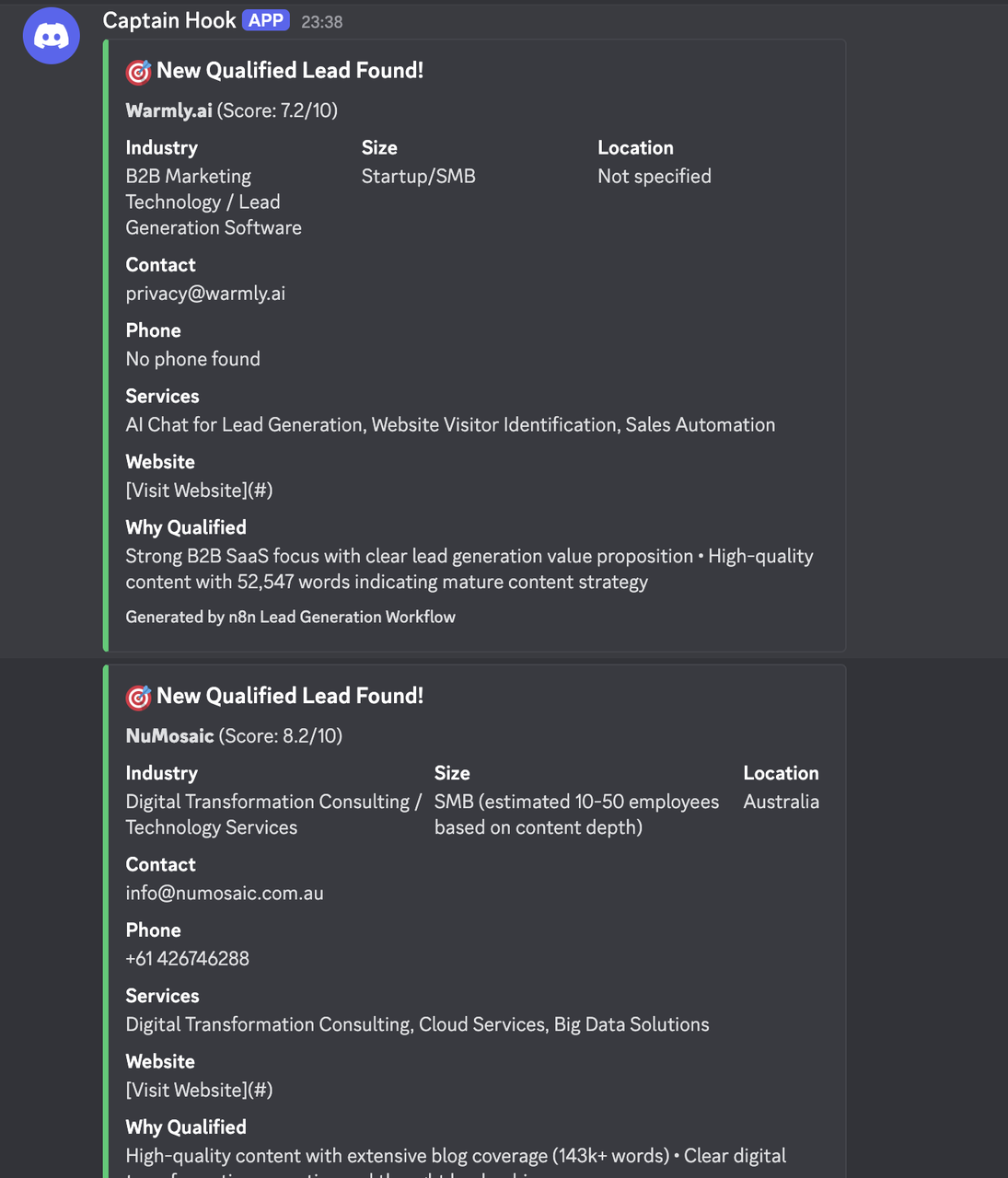
## 業界特有の設定
### SaaS/ソフトウェア会社
検索クエリ:"SaaS企業" "B2Bソフトウェア" "エンタープライズソフトウェア"
"クラウドソフトウェア" "API" "開発者" "サブスクリプションモデル"
"サービスとしてのソフトウェア" "プラットフォーム" "統合"
資格基準:
- 従業員数:20-500
- 最新の技術スタックを使用
- APIドキュメントがある
- GitHub/技術コンテンツでアクティブ
### マーケティング代理店
検索クエリ:"デジタルマーケティング代理店" "B2Bマーケティング" "エンタープライズクライアント"
"マーケティングオートメーション" "需要創出" "リード生成"
"コンテンツマーケティング代理店" "成長マーケティング" "パフォーマンスマーケティング"
資格基準:
- クライアントのケーススタディーが利用可能
- チームサイズ:10-100
- B2Bを専門
- アクティブなコンテンツマーケティング
### Eコマース/小売
検索クエリ:"eコマース会社" "オンライン小売" "D2Cブランド"
"Shopifyストア" "WooCommerce" "eコマースプラットフォーム"
"オンラインマーケットプレイス" "デジタルコマース" "小売技術"
資格基準:
- 収益指標
- マルチチャネルの存在
- 言及された技術プラットフォーム
- 成長軌道のシグナル
## データ管理と分析
### リードデータベーススキーマ
最大の利用効率のためにGoogleシートを構築します:
コアリード情報:
- 会社名、業界、サイズ、所在地
- 連絡先メール、電話、ウェブサイト
- リードスコア、追加日、ソースクエリ
資格データ:
- 資格の理由、意思決定者
- 次のアクション、フォローアップ日
- 担当営業、リードステータス
エンリッチメントフィールド:
- LinkedIn URL、ソーシャルメディアの存在
- 使用技術、資金調達ステージ
- 競合、最近のニュース
### 分析と報告
追加のシートでワークフローのパフォーマンスを追跡:
デイリーサマリーシート:
- 日別に生成されたリード数
- 平均リードスコア
- 検出されたトップ業界
- コンバージョン率
検索パフォーマンス:
- ベストパフォーミングクエリ
- 地理的分布
- 会社サイズの内訳
- 業界別の成功率
ROI追跡:
- リードあたりのコスト(APIコスト)
- 接触までの時間
- 機会へのコンバージョン
- 収益の帰属
## 結論
このインテリジェントなB2Bリード生成ワークフローは、潜在顧客の発見、資格付け、整理を自動化することで、営業プロスペクティングを変革します。Google検索とインテリジェントなクロール、AI分析を組み合わせることで、営業パイプラインを構築するための体系的アプローチを作成します。
このワークフローは、特定の業界、会社の規模ターゲット、資格基準に適応しながら、AI駆動の分析を通じて高いデータ品質を維持します。適切な設定と監視を行うことで、このシステムは営業チームにとって一貫した質のあるリードの源となります。
Google Sheetsとの統合は、営業チームにとってアクセス可能なデータベースを提供し、Discordの通知により高価値のプロスペクトを即座に認識できます。モジュラー設計により、異なる通知サービス、CRMシステム、データストレージソリューションに容易に適応できるようになっています。
----
Scrapelessは、関連する法律および規制を厳守し、ウェブサイトの利用規約およびプライバシーポリシーに従ってのみ、公に利用可能なデータにアクセスします。このソリューションは、正当なビジネスインテリジェンスおよびマーケティング最適化目的のために設計されています。Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


