
ScrapelessとGoogleスプレッドシートを使って自動求人検索エージェントを構築する方法
Advanced Data Extraction Specialist
最新の求人情報を把握することは、求職者、採用担当者、テック愛好者にとって非常に重要です。ウェブサイトを手動で確認する代わりに、プロセスを自動化することができます。定期的に求人掲示板をスクレイピングし、結果をGoogle Sheetsに保存することで、簡単に追跡したり共有したりできます。
このガイドでは、Scrapeless、n8n、およびGoogle Sheetsを使用して、自動化された求人検索エージェントの構築方法を説明します。6時間ごとにY Combinatorの求人ページから求人情報をスクレイピングし、構造化データを抽出してスプレッドシートに保存するワークフローを作成します。
必要条件
始める前に、次のものを用意してください:
- n8n: コードなしの自動化プラットフォーム(セルフホストまたはクラウド)。
- Scrapeless API: ScrapelessからAPIキーを取得します。
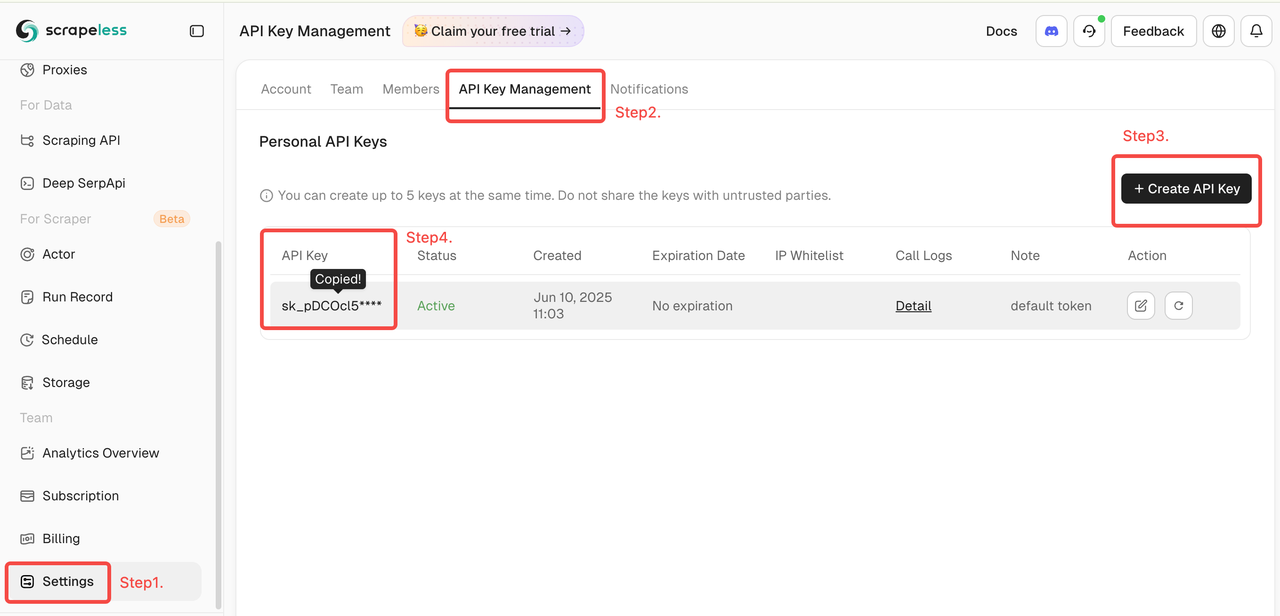
- ログインしてScrapelessのダッシュボードにアクセスします。
- 次に、左側の「設定」をクリックし、「APIキー管理」を選択した後、「APIキーを作成」をクリックします。最後に、作成したAPIキーをクリックしてコピーします。
- Google Sheetsアカウント: 求人データを保存および表示するため。
- 対象ウェブサイト: この例ではY Combinatorの求人ページを使用します。
ScrapelessとGoogle Sheetsを使用した自動化された求人検索エージェントの構築方法
1. スケジュールトリガー: 6時間ごとに実行
ノードタイプ: スケジュールトリガー
設定:
- インターバルフィールド:
hours - インターバル値:
6
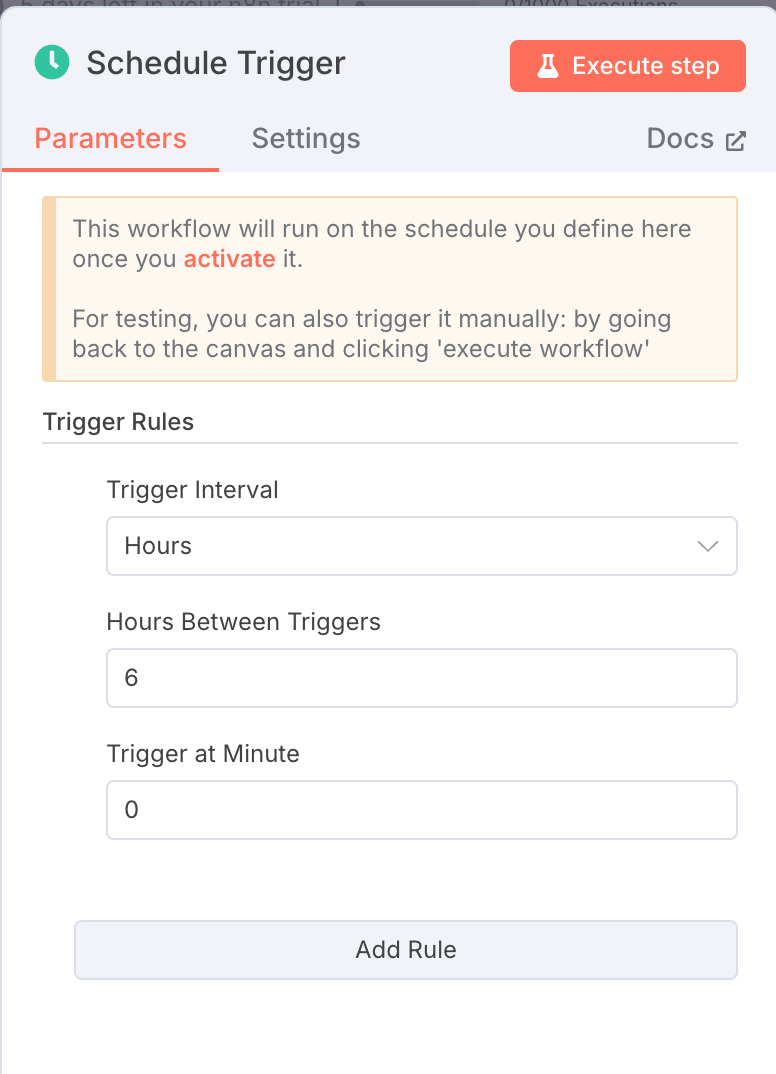
このノードは、手動入力なしでワークフローが6時間ごとに自動的に実行されることを保証します。
2. Scrapelessクローラー: 求人情報をスクレイピング
ノードタイプ: Scrapelessノード
設定:
- リソース:
crawler - 操作:
crawl - URL:
https://www.ycombinator.com/jobs - クローリングページの制限: 2
- 認証情報:
あなたのScrapeless APIキー
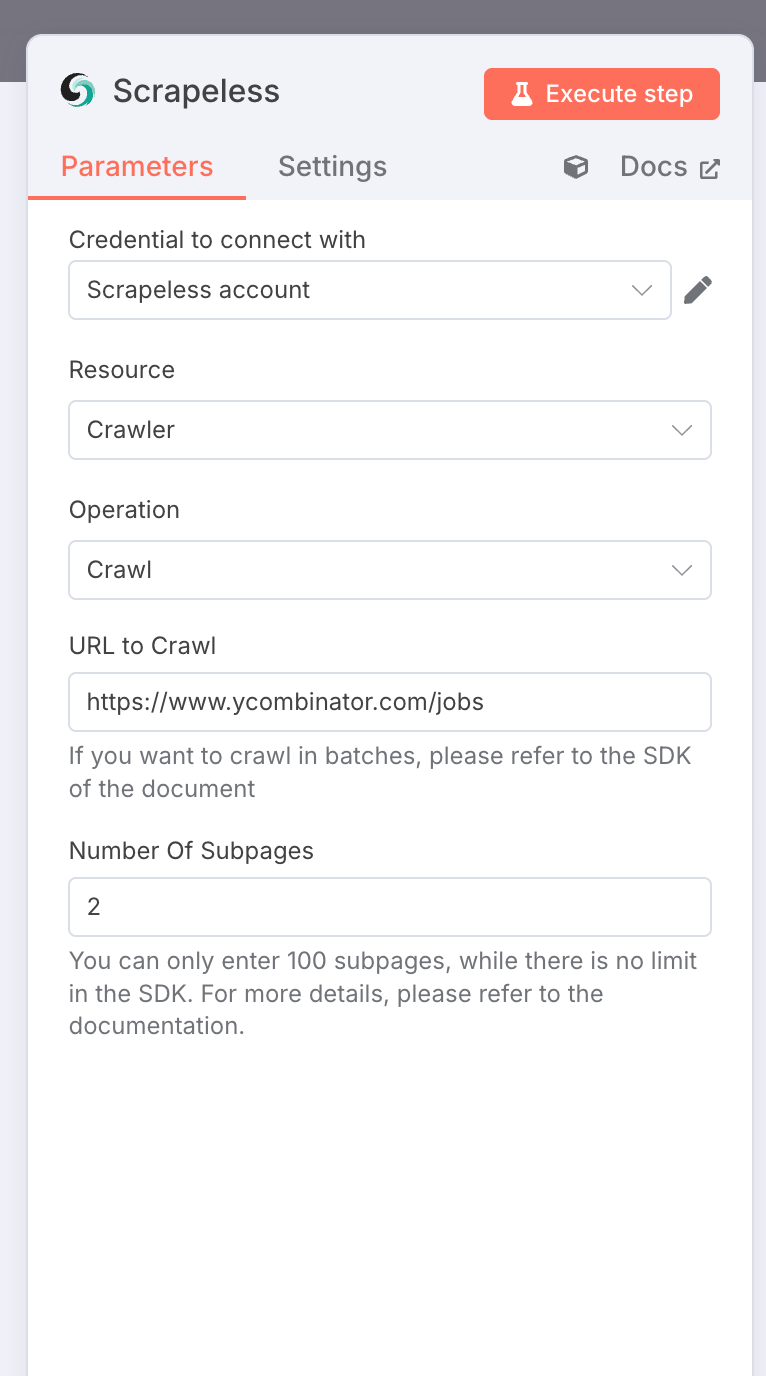
出力: マークダウン形式のリッチな求人データのオブジェクトの配列。
3. マークダウンコンテンツの抽出
ノードタイプ: JavaScriptコードノード
目的: 生のクローリング結果からmarkdownフィールドのみを抽出します。
const raw = items[0].json;
const output = raw.map(obj => ({
json: {
markdown: obj.markdown,
}
}));
return output;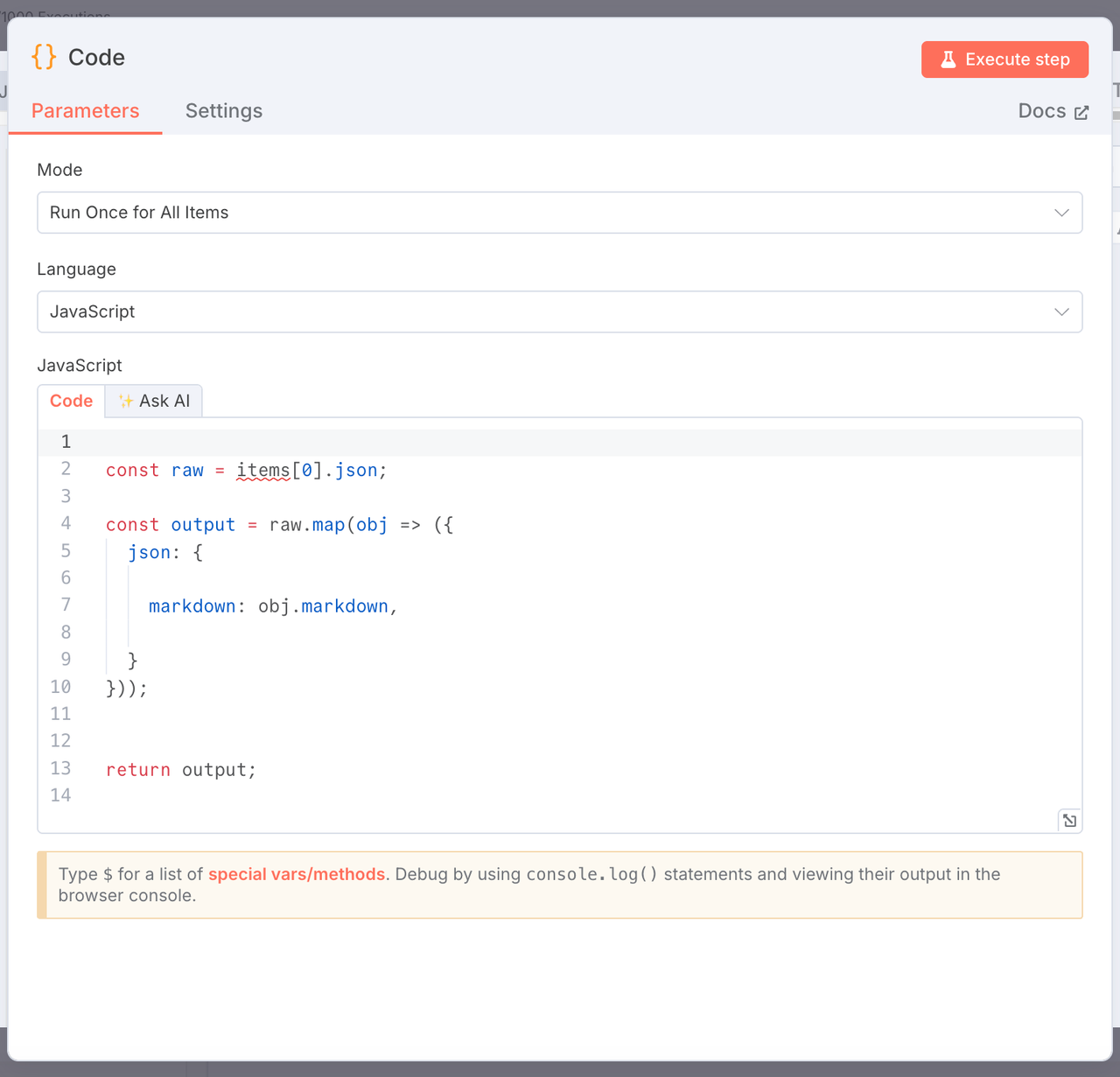
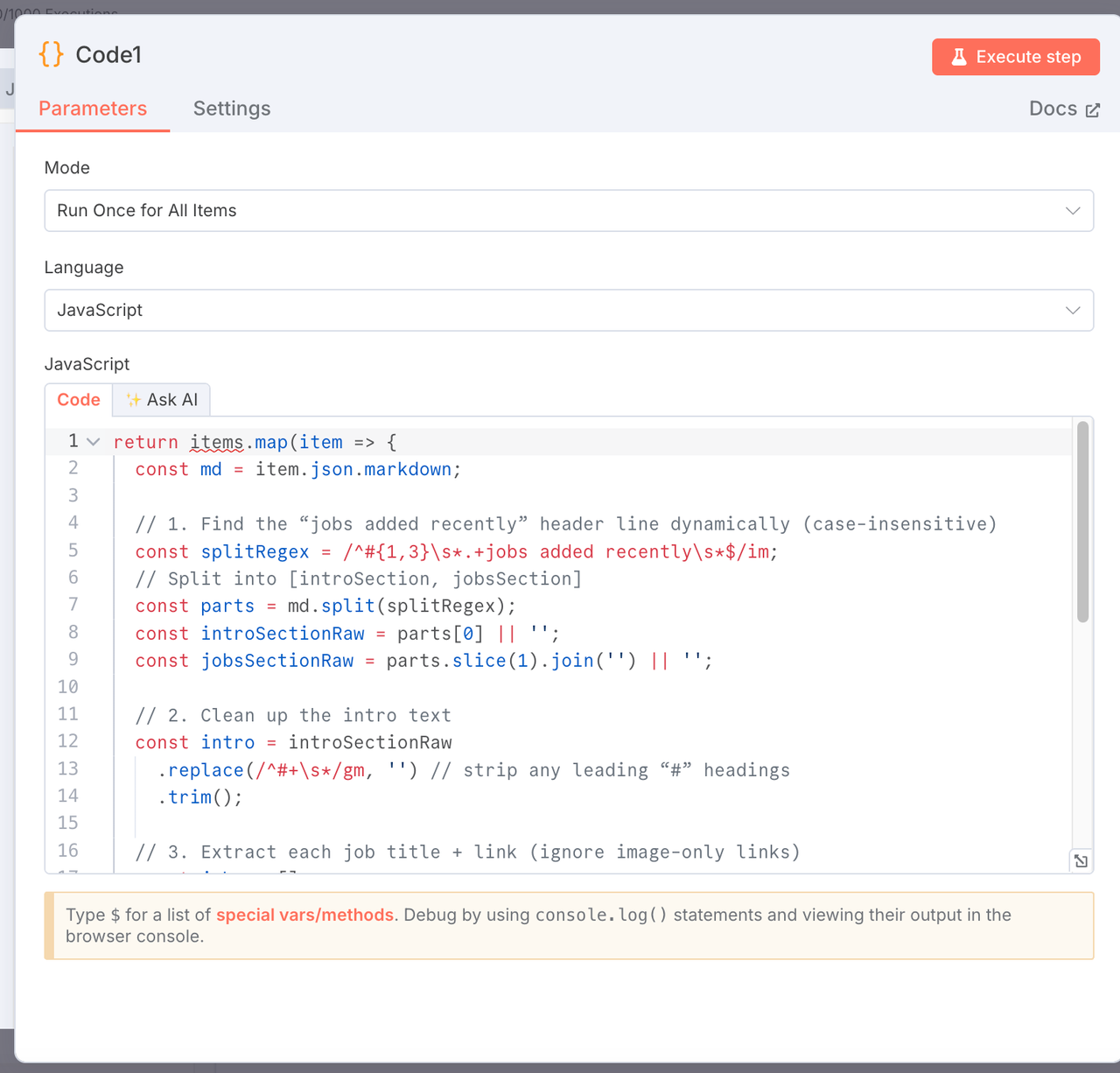
4. マークダウンを解析: イントロと求人リストを抽出
ノードタイプ: JavaScriptコードノード
目的: マークダウンをイントロと構造化された求人タイトルとリンクのリストに分割します。
return items.map(item => {
const md = item.json.markdown;
const splitRegex = /^#{1,3}\s*.+jobs added recently\s*$/im;
const parts = md.split(splitRegex);
const introSectionRaw = parts[0] || '';
const jobsSectionRaw = parts.slice(1).join('') || '';
const intro = introSectionRaw.replace(/^#+\s*/gm, '').trim();
const jobs = [];
const re = /\-\s*\[(?!\!)([^\]]+)\]\((https?:\/\/[^\)]+)\)/g;
let match;
while ((match = re.exec(jobsSectionRaw))) {
jobs.push({
title: match[1].trim(),
link: match[2].trim(),
});
}
return {
json: {
intro,
jobs,
},
};
});
5. エクスポート用に求人情報をフラット化
ノードタイプ: JavaScriptコードノード
目的: 各求人情報を別々の行に変換して、エクスポートを容易にします。
const output = [];
items.forEach(item => {
const intro = item.json.intro;
const jobs = item.json.jobs || [];
jobs.forEach(job => {
output.push({
json: {
intro,
jobTitle: job.title,
jobLink: job.link,
},
});
});
});
return output;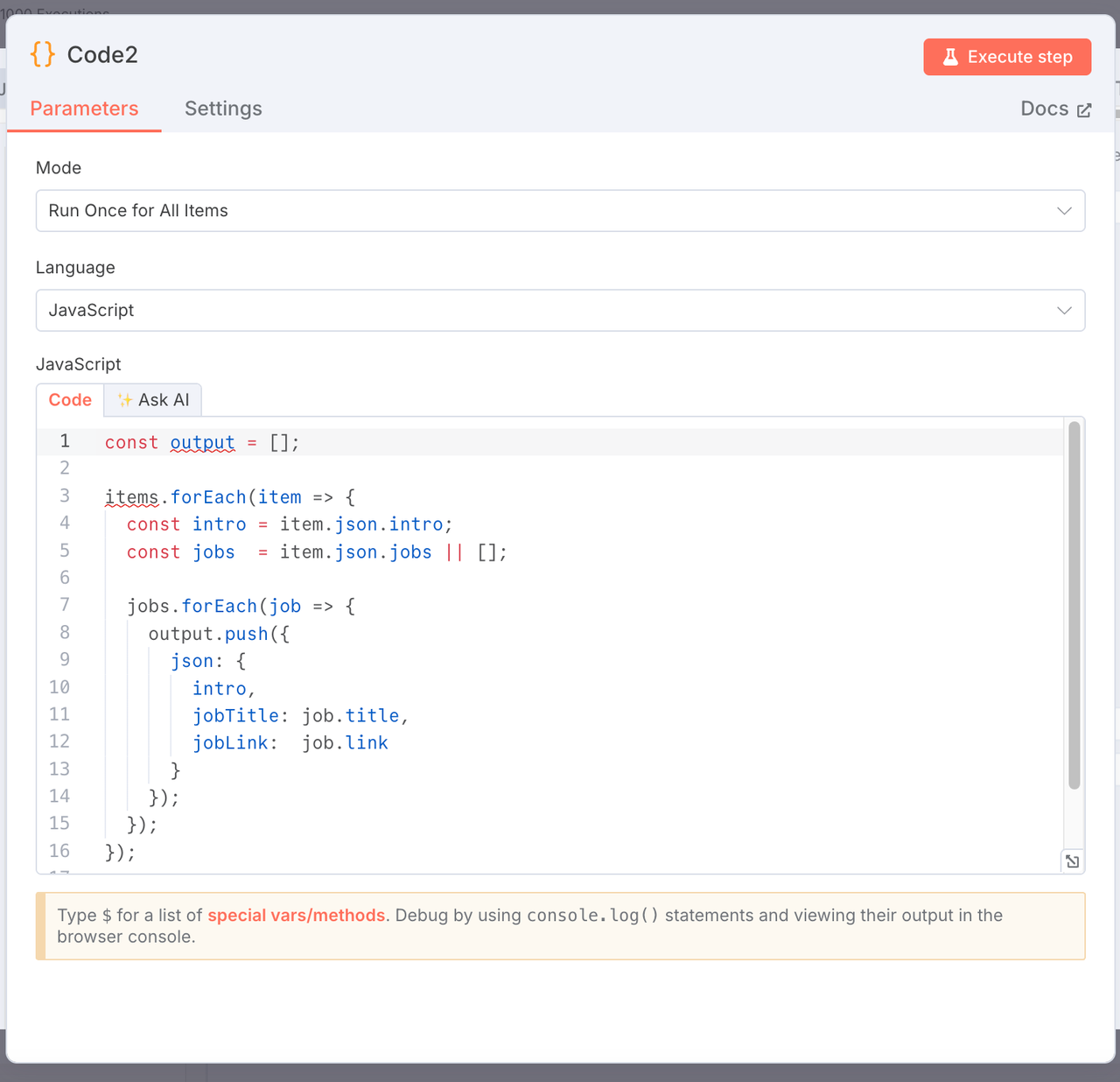
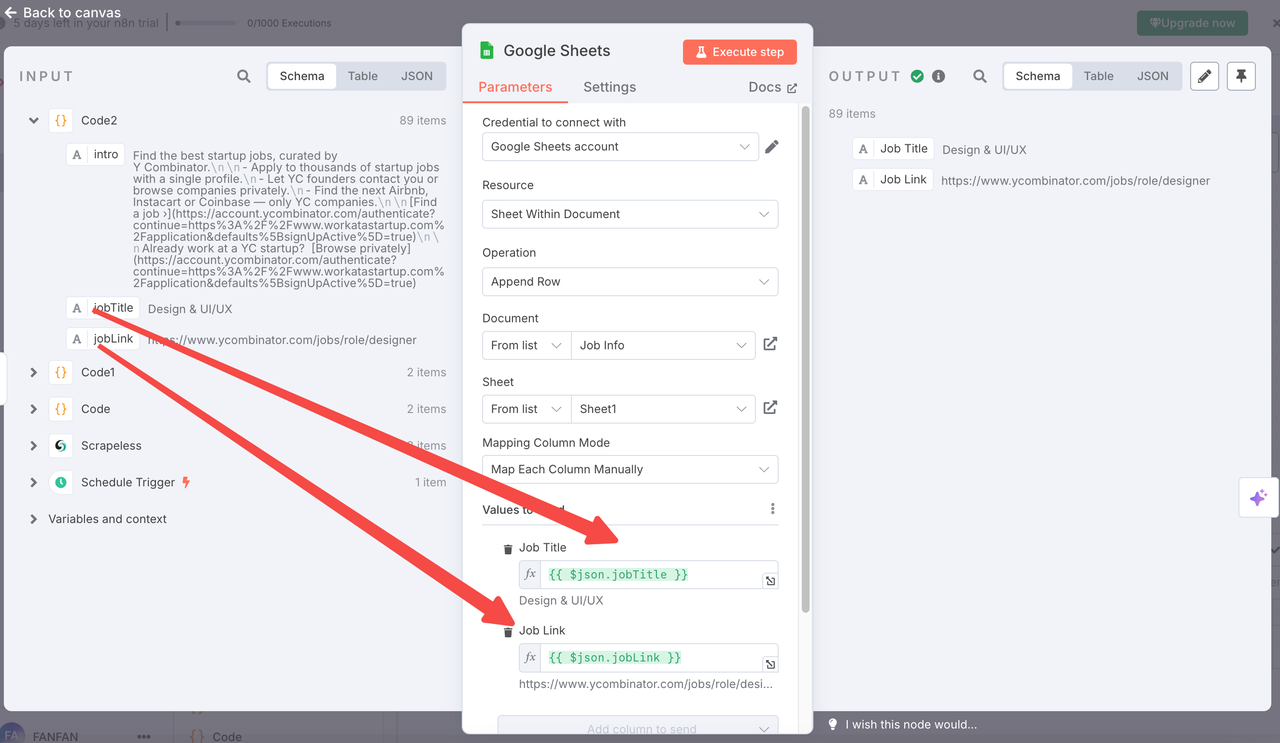
6. Google Sheetsに追加
ノードタイプ: Google Sheetsノード
設定:
- 操作:
append - ドキュメントURL: 作成したGoogleシートの名前を直接選択できます(推奨方法)
- シート名:
Links(タブID:gid=0) - 列のマッピング:
title←{{ $json.jobTitle }}link←{{ $json.jobLink }}
- 型の変換:
false - OAuth: Google Sheetsアカウントを接続
最終的なデータは、追跡またはさらなる分析のためにシートに自動的に追加されます。
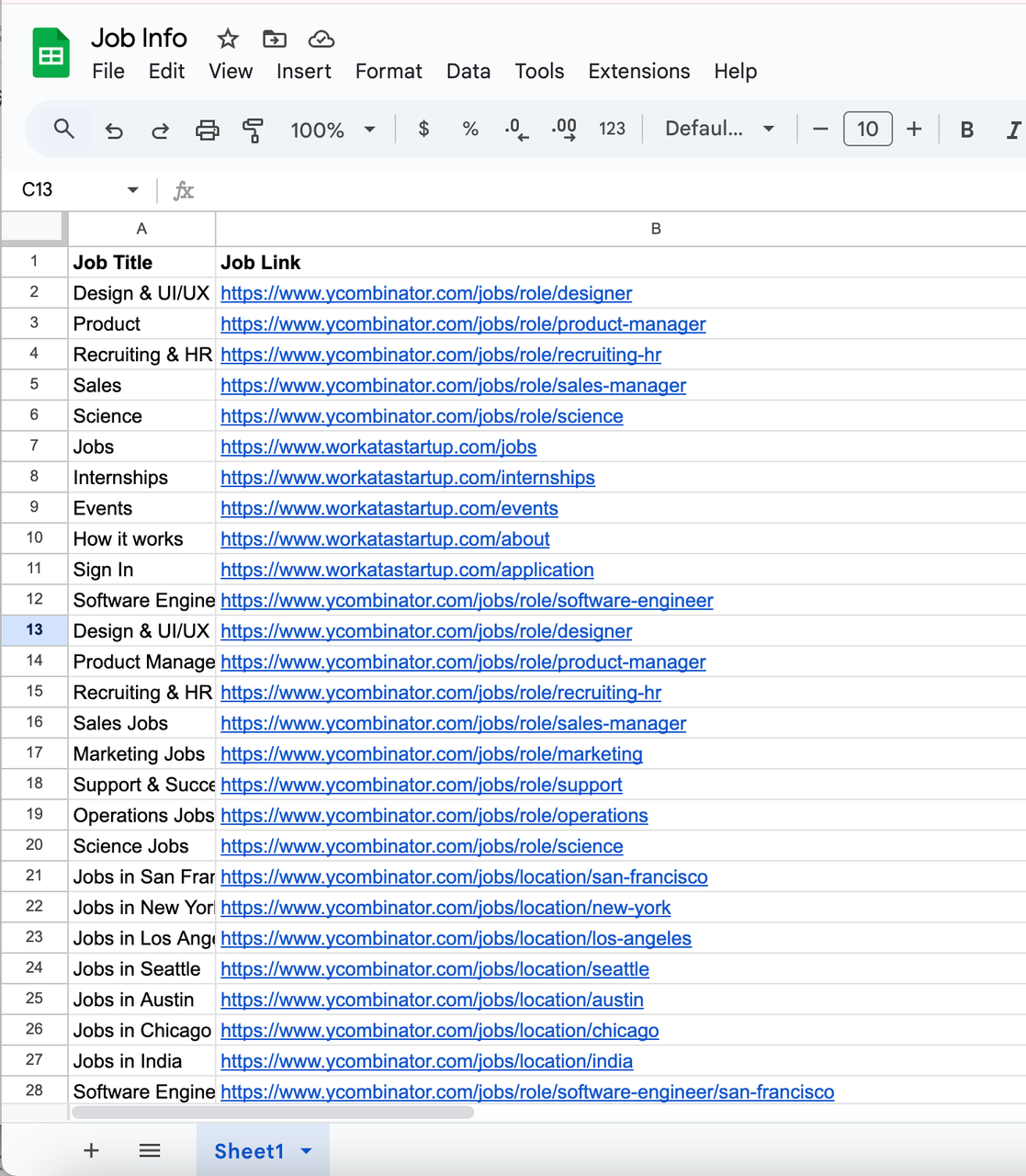
7. 出力結果例
ワークフローダイアグラム
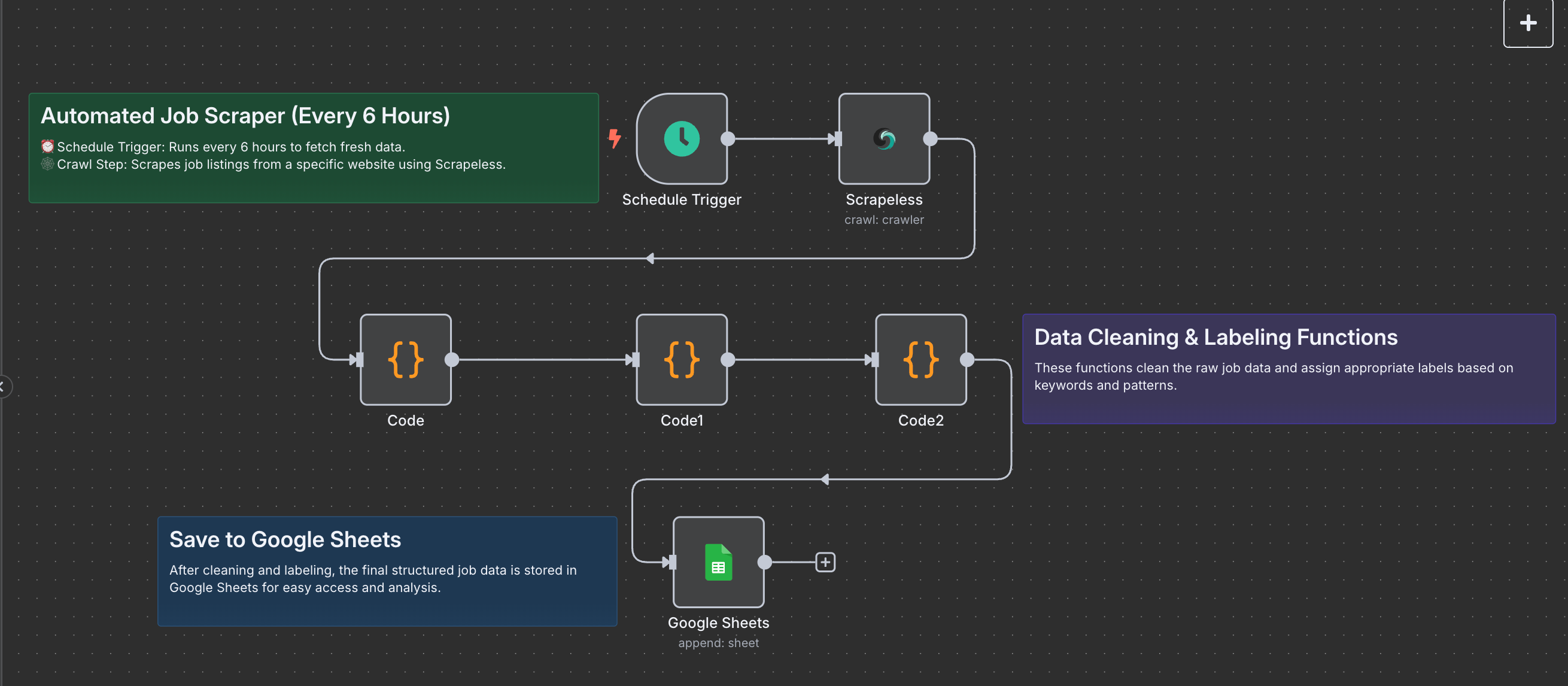
各ノードはモジュール式でカスタマイズ可能です。必要に応じて、ウェブサイト、スクレイピングの頻度、またはデータフォーマットロジックを変更できます。
カスタマイズのアイデア
- より多くのサイトをスクレイプ: LinkedIn、AngelList、またはその他の求人掲示板のURLに置き換えます。
- 通知を追加: 求人の更新をSlack、Discord、またはメールに送信します。
- AIで強化: GPTノードを使用して求人の要約やキーワードタグを生成します。
適用可能なビジネスユースケース
この自動化された求人検索エージェントは、さまざまなビジネスシナリオに適用できます。
- 採用エージェンシー: ニッチな求人掲示板や企業のキャリアページを継続的に監視し、タレントプールのための新しい求人を見つけます。
- スタートアップインキュベーターおよびアクセラレーター: ポートフォリオ企業(Y Combinatorスタートアップなど)の採用活動を追跡し、市場の需要を把握します。
- HRおよびタレントチーム: 競合情報を自動化し、ライバル企業や業界リーダーからの求人情報を追跡します。
- 求人集約プラットフォーム: 複数のソースから求人を集約し、手動のスクレイピングなしで自社プラットフォームへの公開を効率化します。
- フリーランスおよびリモートワークコミュニティ: ニュースレター、コミュニティフォーラム、特定のオーディエンスをターゲットにした求人掲示板向けに新しい求人情報をキュレーションします。
- 市場調査チーム: 業界横断的な採用トレンドを分析し、市場の成長、需要のある技術スタック、または新たに出現する役割についての洞察を得ます。
このワークフローは、定期的で構造化された、スケーラブルな求人市場インテリジェンスが必要な企業に特に有用で、手動作業の無数の時間を節約し、データの正確性を保証します。
自動化された求人検索エージェントのワークフロー
結論
Scrapeless、n8n、およびGoogle Sheetsを使用すれば、求人情報をスクレイピングしてデータをクリーンアップし、スプレッドシートに保存する完全自動化された求人検索エージェントを簡単に構築できます。このセットアップは柔軟性があり、コスト効率が高く、手動作業なしでリアルタイムの求人監視を希望する個人、採用者、またはチームに最適です。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


