
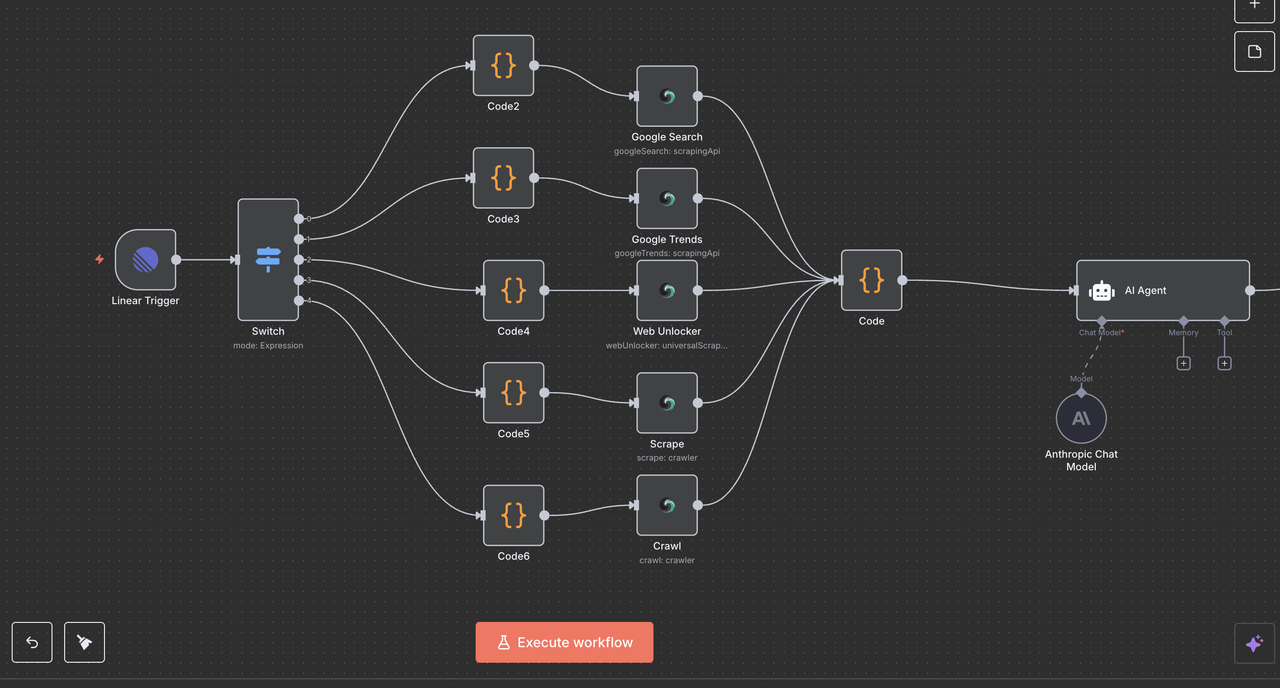
線形 + スクレイプレス + クロードを使用してAI駆動の研究アシスタントを構築する
Advanced Data Extraction Specialist
現代のチームは、情報に基づいた意思決定のために信頼できるデータへの即時アクセスを必要としています。競合他社を調査したり、トレンドを分析したり、市場情報を収集したりする場合、手動のデータ収集はワークフローを遅らせ、開発の勢いを打ち砕きます。
Linearのプロジェクト管理プラットフォームとScrapelessの強力なデータ抽出API、Claude AIの分析能力を組み合わせることにより、Linearの課題に直接簡単なコマンドに応答するインテリジェントなリサーチアシスタントを作成できます。
この統合により、Linearの作業スペースはスマートなコマンドセンターに変わります。「/search competitor analysis」や「/trends AI market」と入力すると、包括的なデータ収集とAIによる分析が自動的に開始され、すべてがLinearの課題内の構造化されたコメントとして返されます。
なぜLinear + Scrapeless + Claudeを選ぶべきか?
Linear: 現代の開発ワークスペース
Linearはチームコラボレーションとタスク管理のための完璧なインターフェースを提供します:
- 課題駆動型ワークフロー: 開発プロセスとの自然な統合
- リアルタイム更新: 即時通知と同期されたチームコミュニケーション
- WebhookおよびAPI: 外部ツールとの強力な自動化機能
- プロジェクト追跡: 内蔵の分析と進捗モニタリング
- チームコラボレーション: シームレスなコメントとディスカッション機能
Scrapeless: エンタープライズクラスのデータ抽出
Scrapelessは複数のソースから信頼性の高いスケーラブルなデータ抽出を提供します:
- Google検索: すべての結果タイプにわたってGoogle SERPデータの包括的な抽出を可能にします。
- Googleトレンド: 時間の経過に伴う人気、地域の関心、関連検索を含むキーワードトレンドデータをGoogleから取得します。
- ユニバーサルスクレイピングAPI: 通常ボットをブロックするJSレンダリングウェブサイトからデータにアクセスし、抽出します。
- クロール: ウェブサイトとそのリンクされたページをクロールして包括的なデータを抽出します。
- スクレイプ: 単一のウェブページから情報を抽出します。
Claude AI: インテリジェントなデータ分析
Claude AIは生データを実用的な洞察に変えます:
- 高度な推論: 洗練された分析とパターン認識
- 構造化された出力: Linearのコメントに最適なクリーンでフォーマットされたレスポンス
- コンテキスト認識: ビジネスの文脈とユーザーの意図を理解します
- 実用的な洞察: 推奨事項と次のステップを提供します
- データ合成: 複数のデータソースを組み合わせて一貫した分析を提供します
使用例
競争情報コマンドセンター
即時競合調査
- 市場ポジション分析: 自動化された競合他社のウェブサイトのクロールと分析
- トレンドモニタリング: 競合他社の言及とブランドの感情の変化を追跡
- 製品ローンチの検出: 競合他社が新機能を導入した時期を特定
- 戦略的洞察: 競争ポジショニングのAI駆動型分析
コマンドの例:
/search "competitor product launch" 2024
/trends competitor-brand-name
/crawl https://competitor.com/products市場調査の自動化
リアルタイム市場インテリジェンス
- 業界トレンド分析: 市場セグメントのために自動化されたGoogleトレンドのモニタリング
- 消費者の感情: 製品カテゴリの検索トレンド分析
- 市場機会の特定: AI駆動型市場ギャップ分析
- 投資リサーチ: スタートアップと産業の資金調達トレンド分析
コマンドの例:
/trends "artificial intelligence market"
/search "SaaS startup funding 2024"
/crawl https://techcrunch.com/category/startups製品開発リサーチ
機能調査とバリデーション
- ユーザーニーズ分析: 製品機能のための検索トレンド分析
- 技術調査: 自動化された文書とAPI研究
- ベストプラクティスの発見: 実装パターンのために業界リーダーをクロール
- 市場バリデーション: 製品市場適合のためのトレンド分析
コマンドの例:
/search "user authentication best practices"
/trends "mobile app features"
/crawl https://docs.stripe.com/api実装ガイド
ステップ1: Linearワークスペースのセットアップ
Linear環境の準備
-
Linearワークスペースにアクセス
- linear.app に移動してワークスペースにログイン
- Webhookの設定には管理者権限が必要です
- 研究自動化用のプロジェクトを作成または選択
-
Linear APIトークンの生成
- Linear設定 > API > 個人APIトークンに移動
- 適切な権限で**「トークンを作成」**をクリック
- n8nの設定で使用するためにトークンをコピー
ステップ2: n8nワークフローのセットアップ
n8n自動化環境の作成
- n8nインスタンスの設定
- n8nクラウドを使用するか、自己ホスト(注意: 自己ホスティングにはngrokの設定が必要; このガイドではn8nクラウドを使用します)
- 新しいワークフローをLinear統合のために作成する
- 提供されたワークフローモジュールのJSONをインポートする
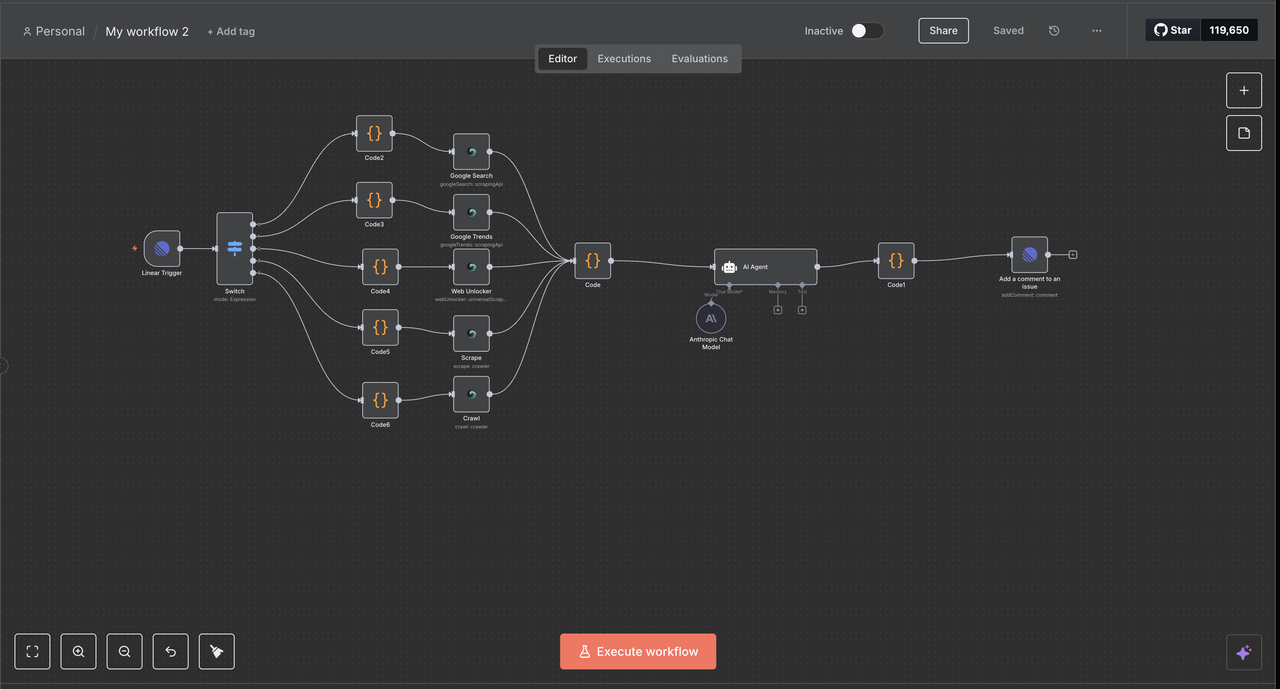
- Linearトリガーの設定
- Linearの資格情報をAPIトークンを使用して追加する
- 問題イベントをリッスンするためのWebhookを設定する
- 必要に応じてチームIDを設定し、リソースフィルターを適用する
ステップ 3: Scrapeless統合の設定
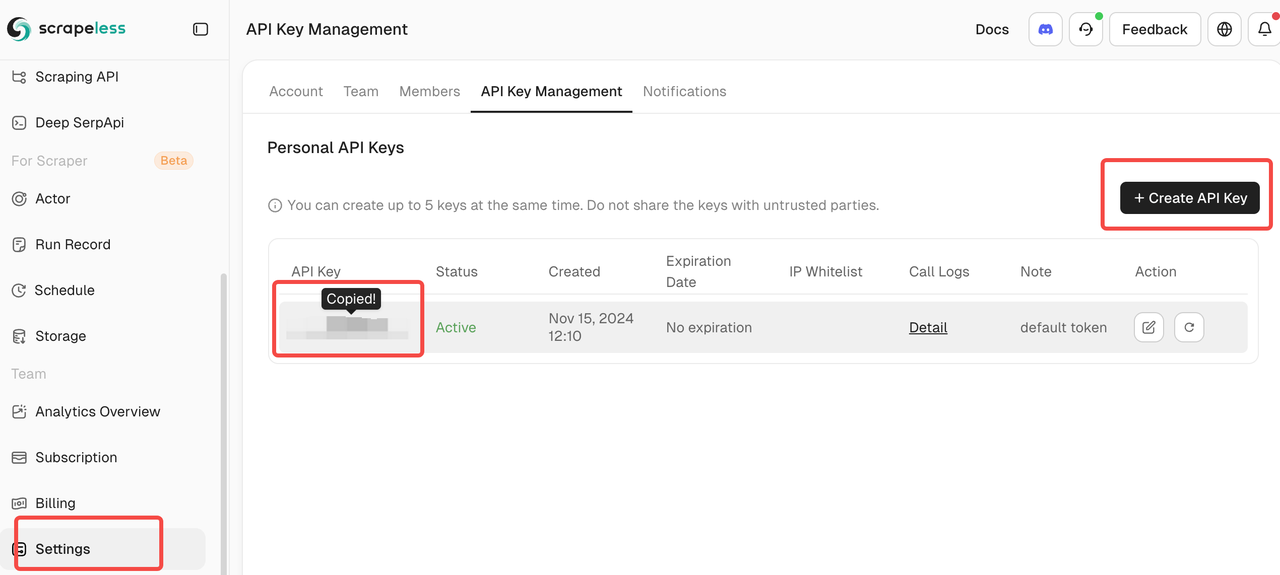
Scrapelessアカウントを接続する
- Scrapelessの資格情報を取得する
- scrapeless.comでサインアップする
- ダッシュボード > APIキーに移動する
- n8n設定用のAPIトークンをコピーする
ワークフローアーキテクチャの理解
各コンポーネントをステップバイステップで説明し、それぞれのノードが何をするのか、どのように連携するのかを見ていきましょう。
ステップ 4: Linearトリガーノード(エントリーポイント)
始まりのポイント: Linearトリガー
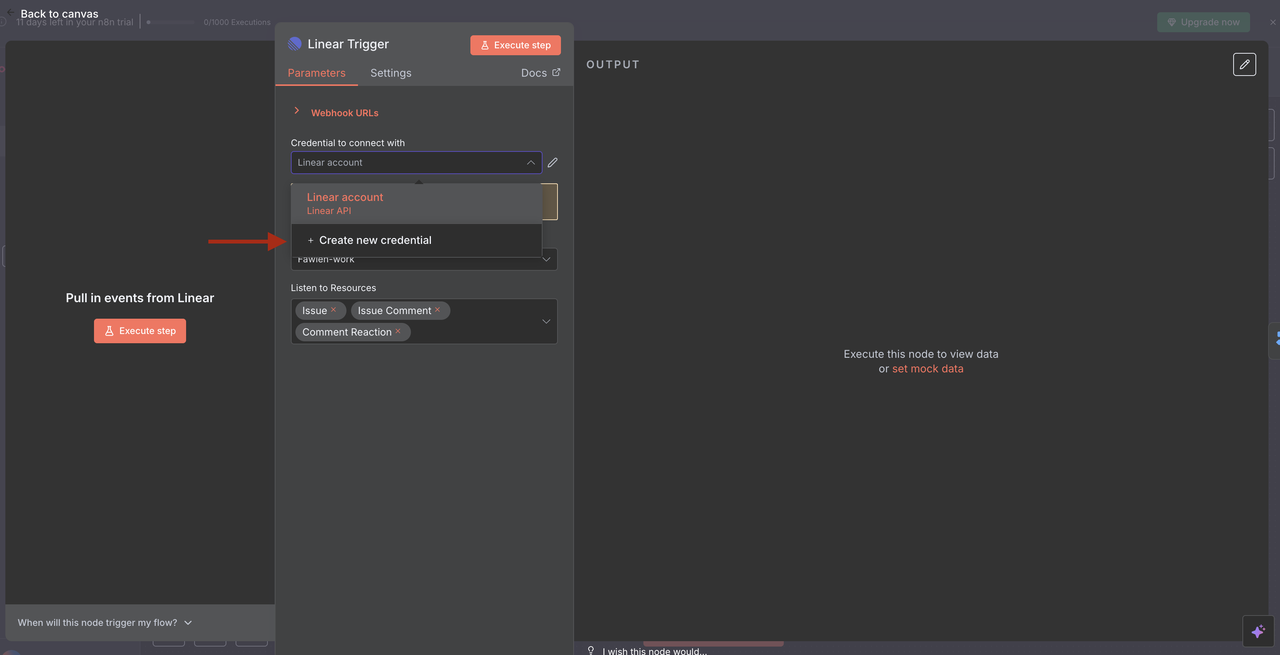
Linearトリガーはワークフローのエントリーポイントです。このノードは:
何をするのか:
- 問題が作成または更新されるたびにLinearからのウェブフックイベントをリッスンする
- タイトル、説明、チームID、その他のメタデータを含む問題データをキャプチャする
- 特定のイベントが発生したときにのみトリガーされる(例:問題作成、問題更新、コメント作成)
設定の詳細:
- チームID: 特定のLinearワークスペースチームにリンク
- リソース:
issue、comment、およびreactionイベントを監視するように設定 - Webhook URL: n8nによって自動生成され、Linearのウェブフック設定に追加する必要がある
なぜ重要なのか:
このノードは、Linearの問題を自動化トリガーに変換します。
たとえば、誰かが問題のタイトルに/search competitor analysisと入力すると、ウェブフックはそのデータをリアルタイムでn8nに送信します。
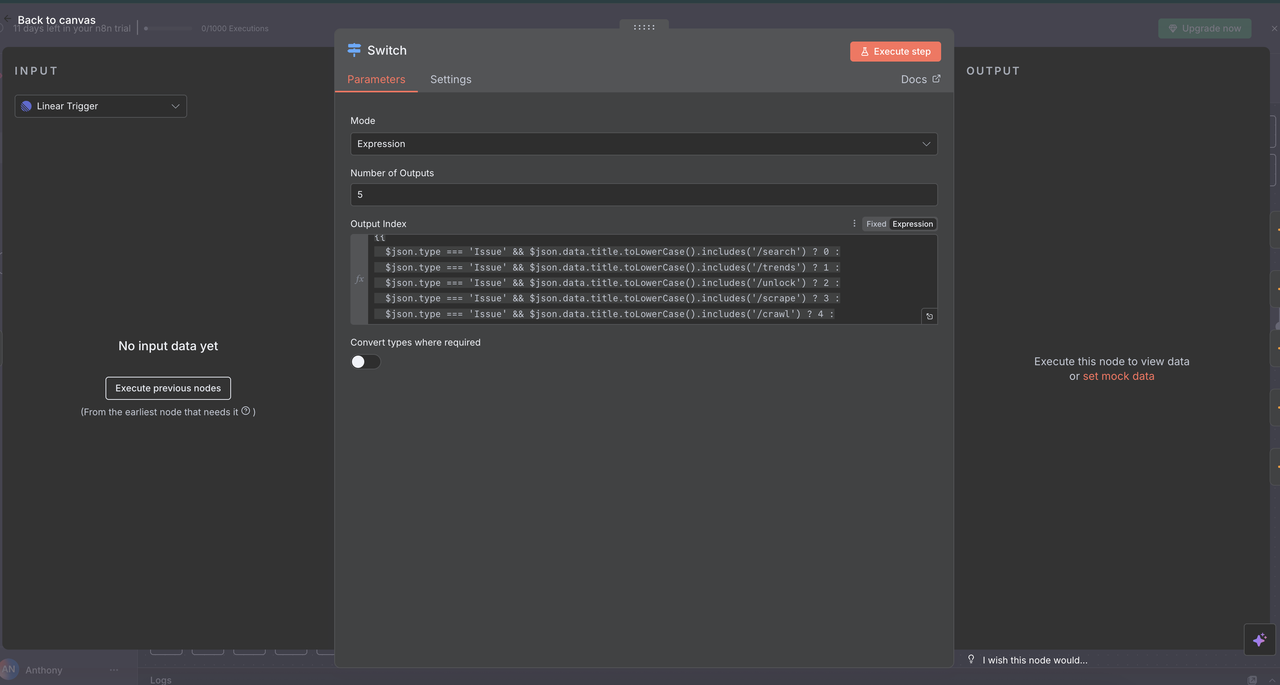
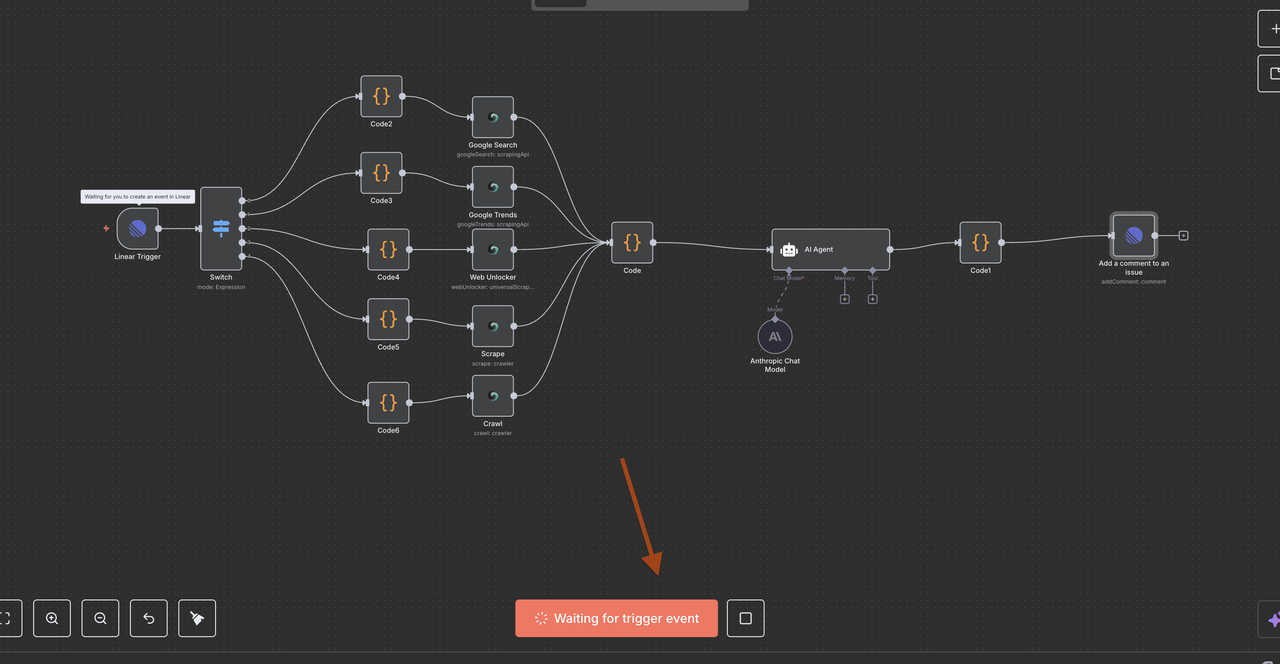
ステップ 5: スイッチノード(コマンドルーター)
インテリジェントなコマンド検出とルーティング
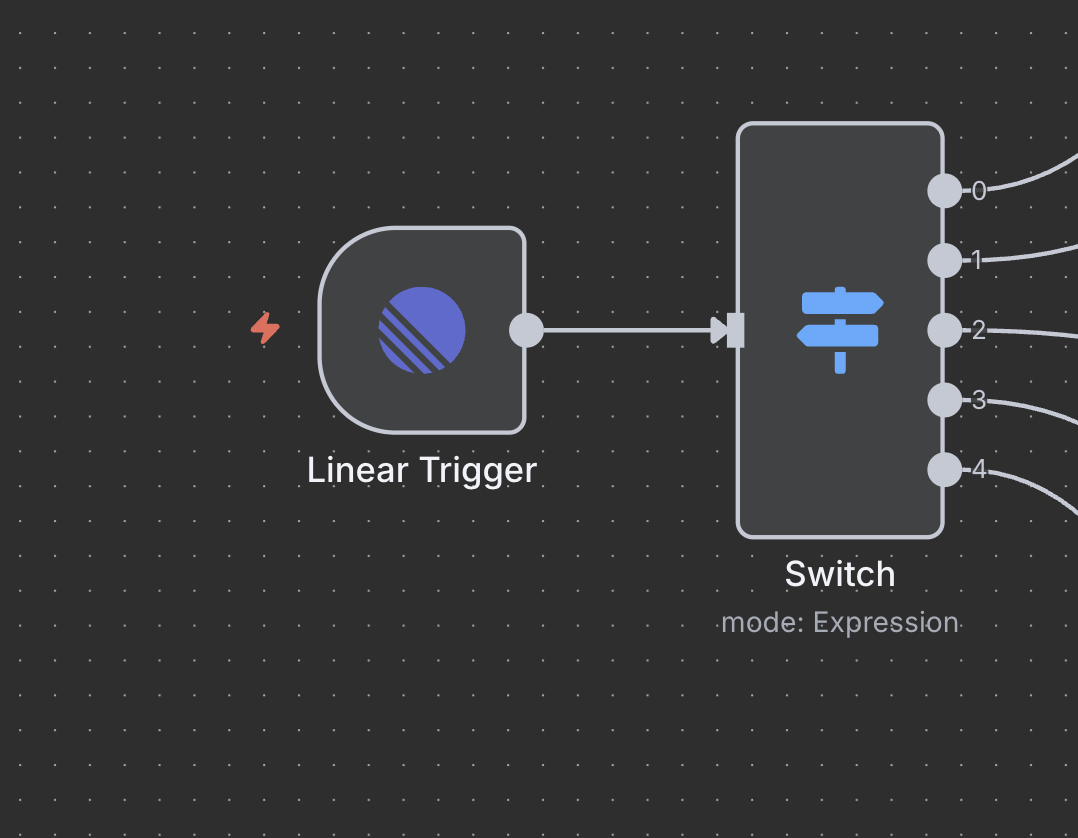
スイッチノードは、問題のタイトルに基づいてどのタイプのリサーチを行うべきかを決定する“脳”として機能します。
動作方法:
// コマンド検出とルーティングロジック
{
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/search') ? 0 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/trends') ? 1 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/unlock') ? 2 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/scrape') ? 3 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/crawl') ? 4 :
-1
}ルートの説明
- 出力0 (
/search): Google Search APIにルートしてウェブ検索結果を取得する - 出力1 (
/trends): Google Trends APIにルートしてトレンド分析を行う - 出力2 (
/unlock): Web Unlockerにルートして保護されたコンテンツにアクセスする - 出力3 (
/scrape): Scraperにルートして単一ページのコンテンツを抽出する - 出力4 (
/crawl): Crawlerにルートして複数ページのウェブサイトをクロールする - 出力-1: コマンドが検出されなかったため、ワークフローは自動的に終了
スイッチノードの設定
- モード: 動的ルーティングのために
"Expression"に設定 - 出力の数:
5(各コマンドタイプのために1つ) - 式: ルーティングロジックを決定するJavaScriptコード
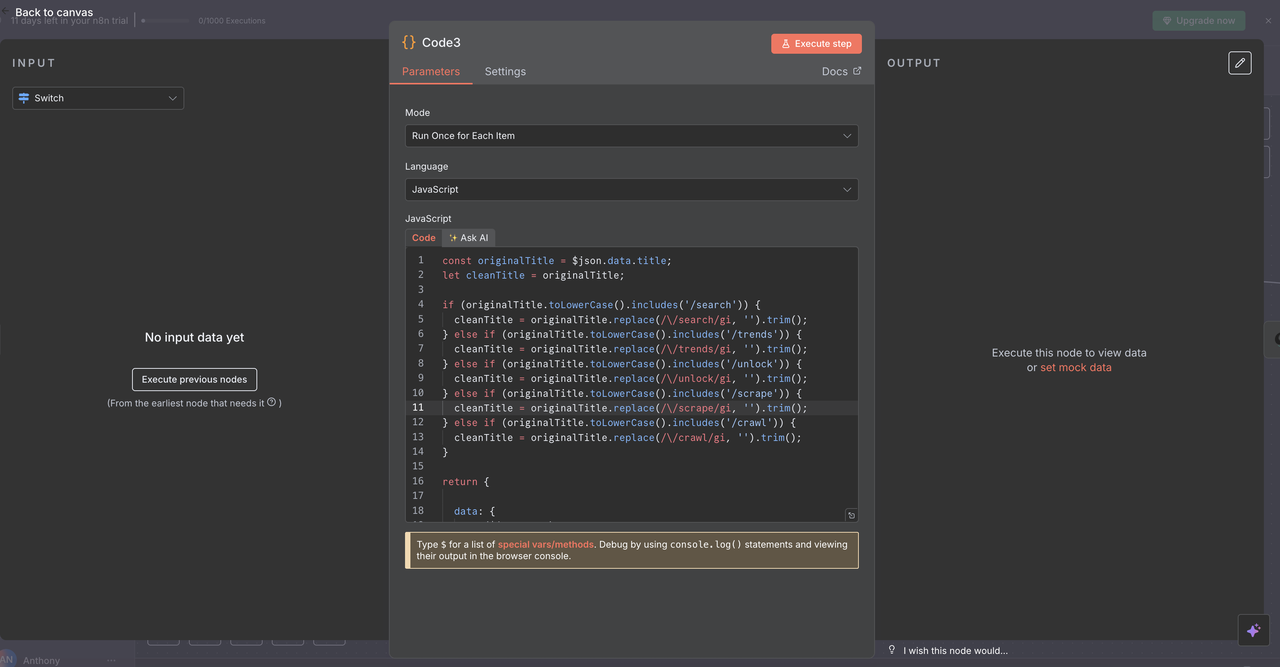
ステップ 6: タイトルクリーニングコードノード
API 処理のためのコマンドの準備
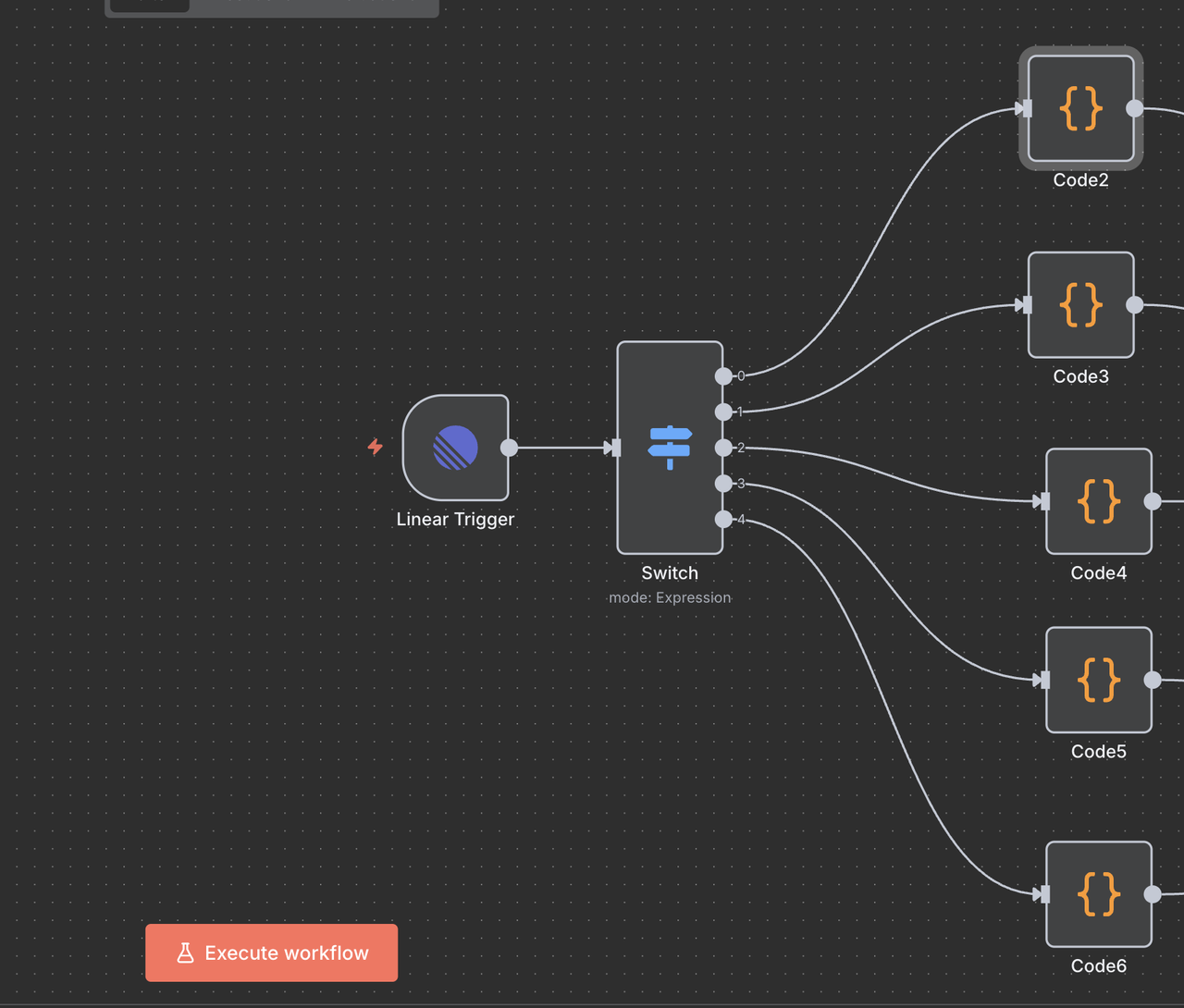
各ルートには、Scrapeless APIを呼び出す前に問題タイトルからコマンドをクリーンアップするコードノードが含まれています。
各コードノードの機能:
js
// API 処理のためにタイトルからコマンドをクリーンアップ
const originalTitle = $json.data.title;
let cleanTitle = originalTitle;
// 検出されたコマンドに基づいてコマンドプレフィックスを削除
if (originalTitle.toLowerCase().includes('/search')) {
cleanTitle = originalTitle.replace(/\/search/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/trends')) {
cleanTitle = originalTitle.replace(/\/trends/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/unlock')) {
cleanTitle = originalTitle.replace(/\/unlock/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/scrape')) {
cleanTitle = originalTitle.replace(/\/scrape/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/crawl')) {
cleanTitle = originalTitle.replace(/\/crawl/gi, '').trim();
}
return {
data: {
...($json.data),
title: cleanTitle
}
};
例の変換
/search competitor analysis→competitor analysis/trends AI market growth→AI market growth/unlock https://example.com→https://example.com
なぜこのステップが重要か
Scrapeless APIは、コマンドプレフィックスのないクリーンなクエリを必要とします。
これにより、APIに送信されるデータが正確で解釈可能になり、オートメーションの信頼性が向上します。
ステップ 7: Scrapeless 操作ノード
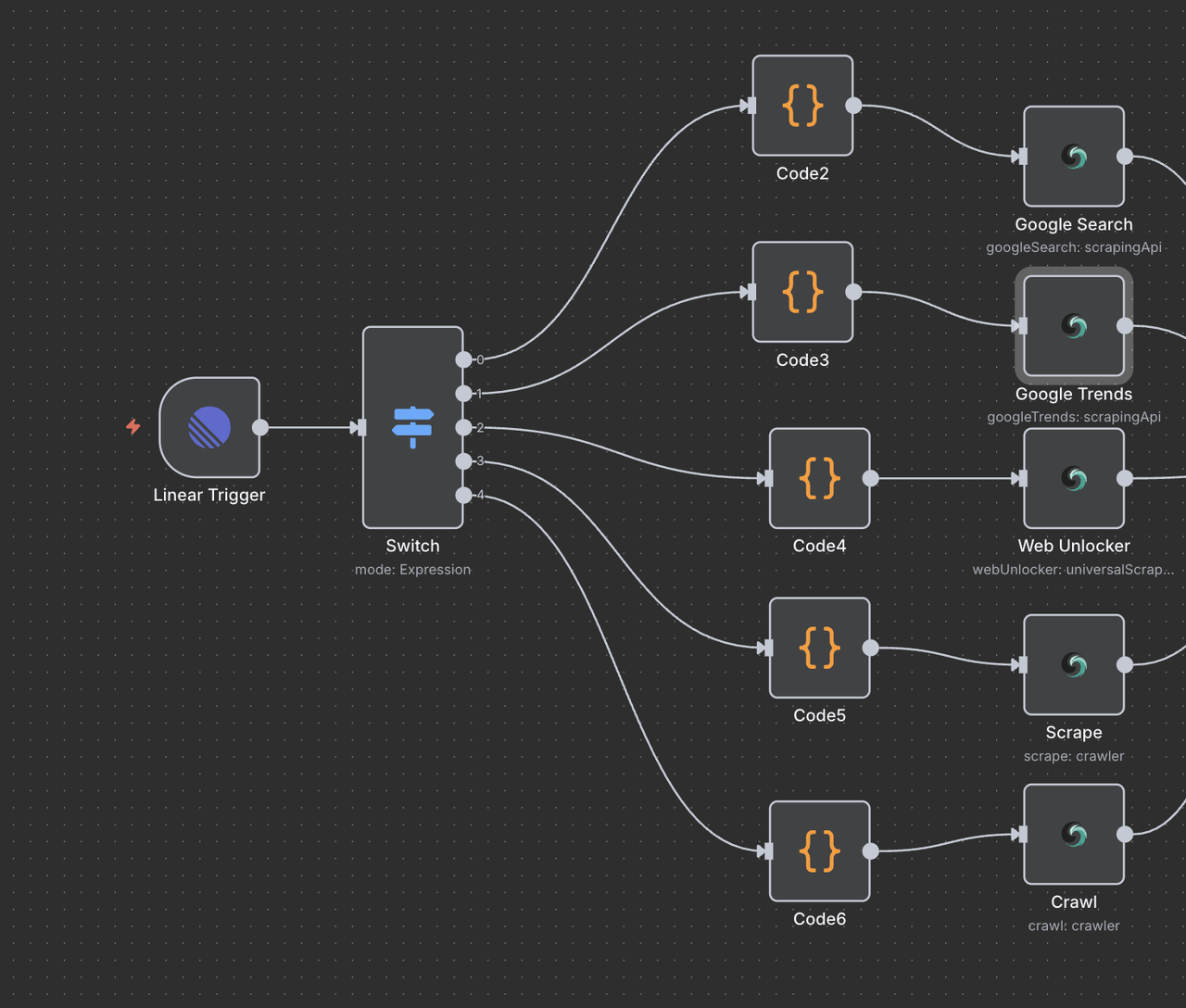
このセクションでは、各Scrapeless操作ノードを説明します。
7.1 Google 検索ノード(/search コマンド)
目的:
Googleのウェブ検索を実行し、オーガニック検索結果を返します。
設定:
- 操作:
Search Google(デフォルト) - クエリ:
{{ $json.data.title }}(前のステップからのクリーンなタイトル) - 国:
"US"(ロケールごとにカスタマイズ可能) - 言語:
"en"(英語)
結果:
- オーガニック検索結果:タイトル、URL、およびスニペット
- 「人々はまた尋ねる」関連の質問
- メタデータ:推定検索結果数、検索時間
ユースケース:
- 競合製品の調査
/search competitor pricing strategy
- 業界レポートを探す
/search SaaS market report 2024
- ベストプラクティスを発見する
/search API security best practices
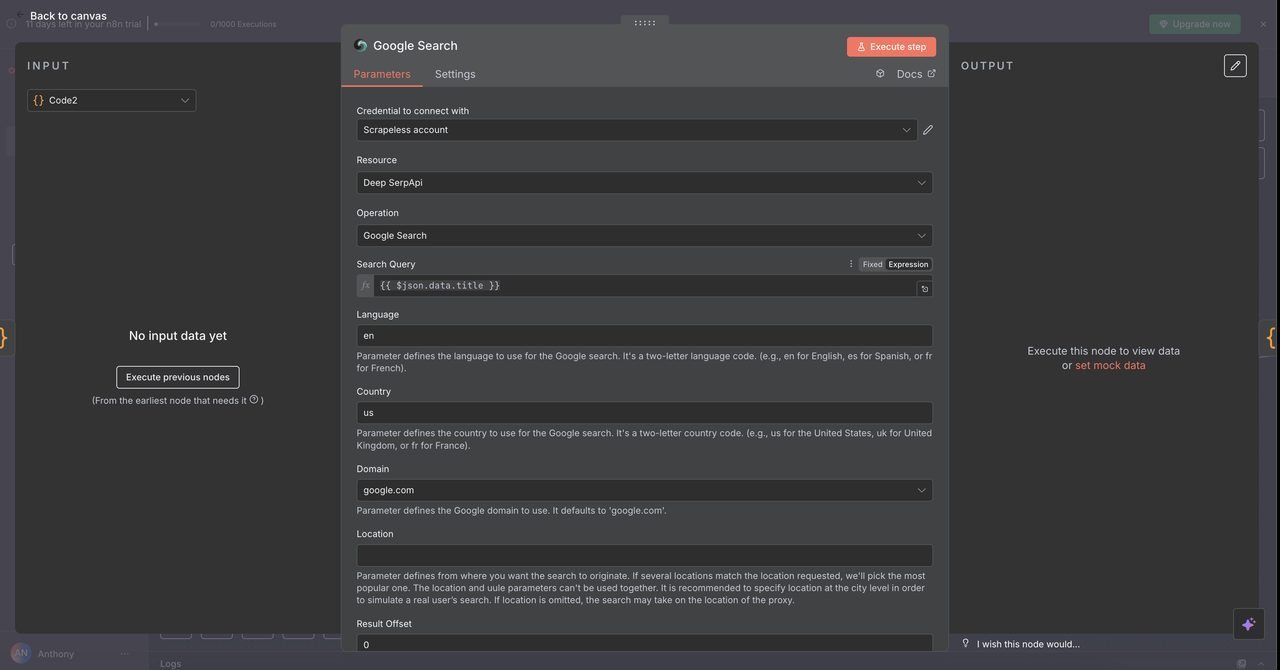
7.2 Google トレンドノード(/trends コマンド)
目的:
特定のキーワードの検索トレンドデータと時間ごとの関心を分析します。
設定:
- 操作:
Google Trends - クエリ:
{{ $json.data.title }}(クリーンなキーワードまたはフレーズ) - 期間: 1か月、3か月、1年などのオプションから選択
- 地理的:
Globalに設定するか、地域を指定
結果:
- 時間ごとの関心チャート(0–100スケール)
- 関連クエリおよびトレンドトピック
- 興味の地理的分布
- トレンドコンテキストのカテゴリ内訳
ユースケース:
- 市場の検証
/trends electric vehicle adoption - 季節の分析
/trends holiday shopping trends - ブランドモニタリング
/trends company-name mentions
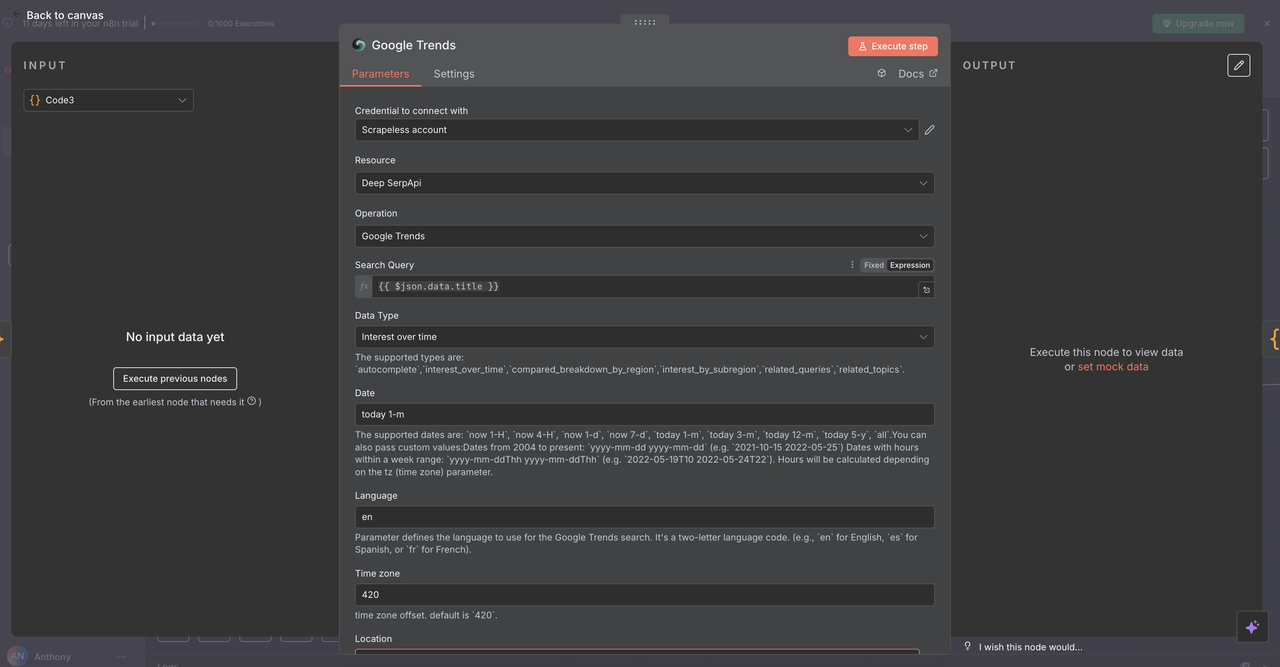
7.3 ウェブアンロッカーノード(/unlock コマンド)
目的:
ボット対策や有料壁で保護されたウェブサイトからコンテンツにアクセスします。
設定:
- リソース:
Universal Scraping API - URL:
{{ $json.data.title }}(有効なURLを含む必要があります) - ヘッドレス:
false(ボット対策の互換性向上のため) - JavaScriptレンダリング:
enabled(動的コンテンツの完全な読み込みのため)
結果:
- ページの完全なHTMLコンテンツ
- JavaScriptレンダリングされた最終コンテンツ
- 一般的なボット対策を回避する機能
ユースケース:
- 競合の価格分析
/unlock https://competitor.com/pricing - 制限付き研究にアクセス
/unlock https://research-site.com/report - 動的アプリをスクレイピング
/unlock https://spa-application.com/data
7.4 スクレイパーノード(/scrape コマンド)
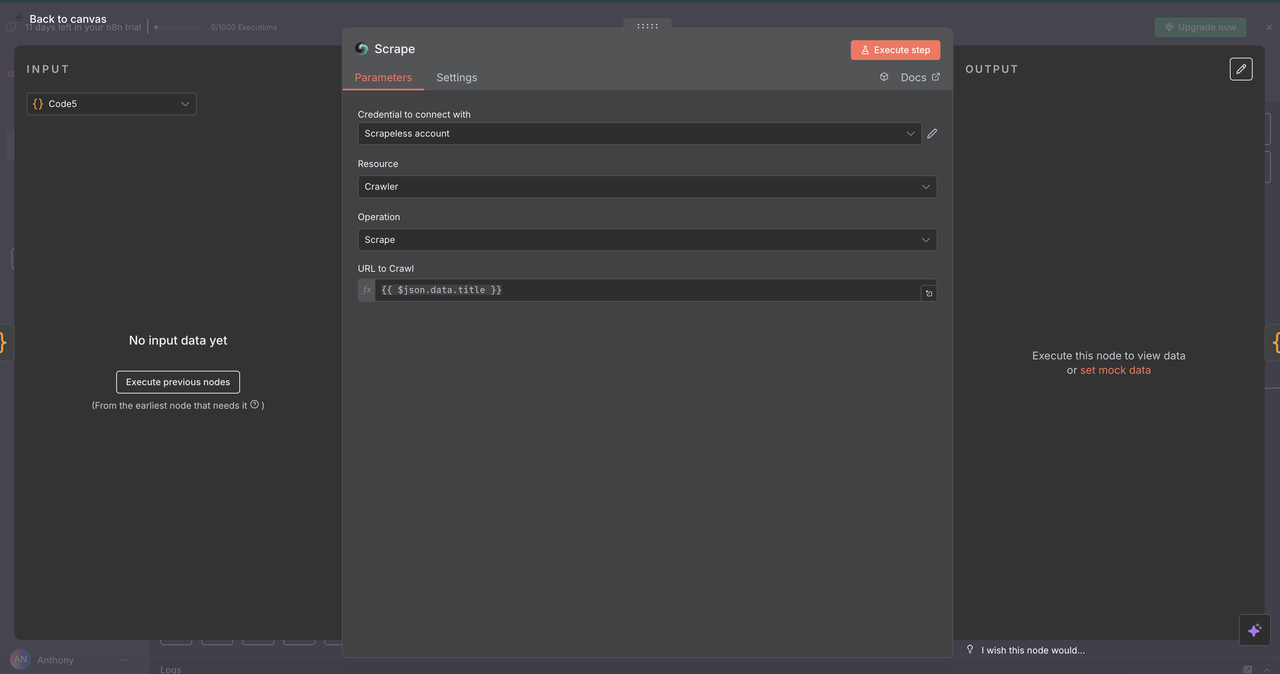
目的:
セレクターやデフォルトの解析を使用して、単一のウェブページから構造化されたコンテンツを抽出します。
設定:
- リソース:
クローラー(単一ページのスクレイピングに使用) - URL:
{{ $json.data.title }}(対象ウェブページ) - フォーマット: 出力形式を
HTML、テキスト、またはMarkdownから選択 - セレクター: 特定のコンテンツをターゲットとするためのオプションのCSSセレクター
返される内容:
- ページからの構造化されたクリーンなテキスト
- ページのメタデータ(タイトル、説明など)
- デフォルトでナビゲーション/広告を除外
使用例:
- ニュース記事の抽出
/scrape https://news-site.com/article - APIドキュメントの解析
/scrape https://api-docs.com/endpoint - 商品情報の取得
/scrape https://product-page.com/item
7.5 クローラーノード(/crawl コマンド)
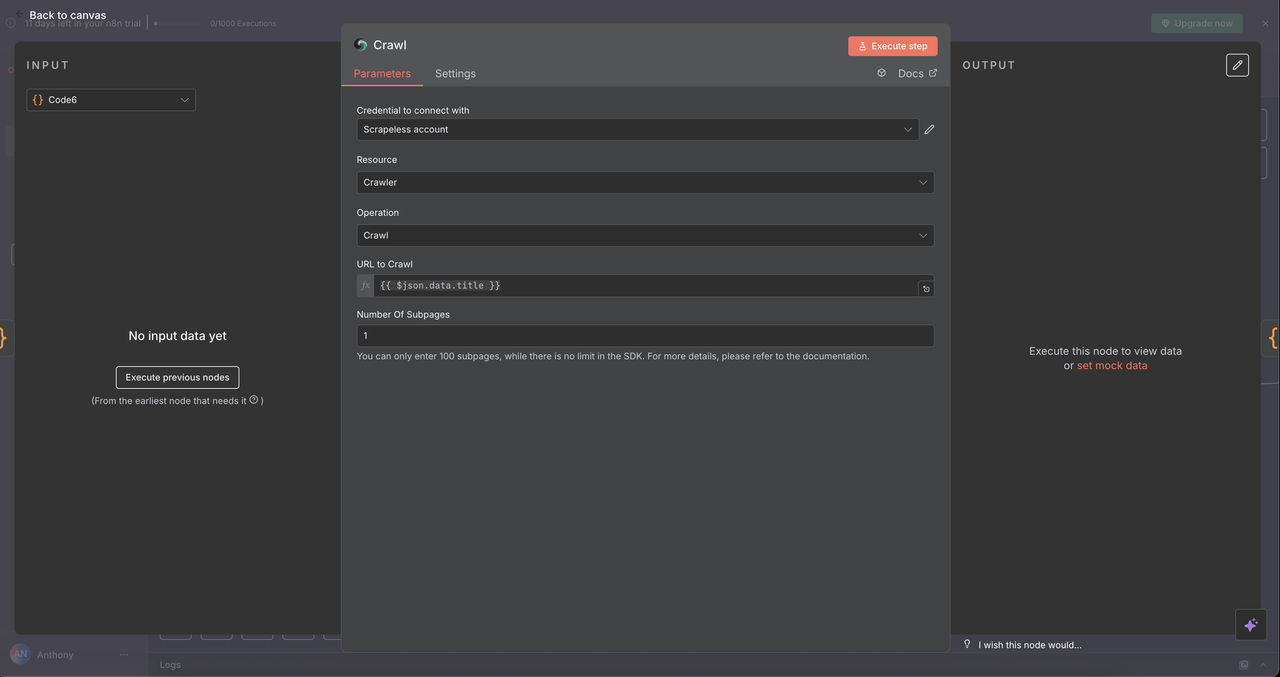
目的:
複数のページを体系的にクロールし、包括的なデータ抽出を行います。
設定:
- リソース:
クローラー - 操作:
クロール - URL:
{{ $json.data.title }}(出発点URL) - クロールするページの制限: オプションの上限、例えば、オーバーロードを避けるために5〜10ページ
- 含める/除外するパターン: クロールスコープを絞り込むための正規表現または文字列フィルタ
返される内容:
- 関連する複数ページのコンテンツ
- サイトのナビゲーション構造
- ターゲットドメイン/サブセクション全体のリッチデータセット
使用例:
-
競合調査
/crawl https://competitor.com
(例: 価格、機能、会社情報ページ) -
ドキュメントマッピング
/crawl https://docs.api.com
(APIまたは開発者ドキュメント全体をクロール) -
コンテンツ監査
/crawl https://blog.company.com
(SEOレビュー用の関係記事、カテゴリ、タグをマッピング)
ステップ8: データの収束と処理
すべてのScrapeless結果をまとめる
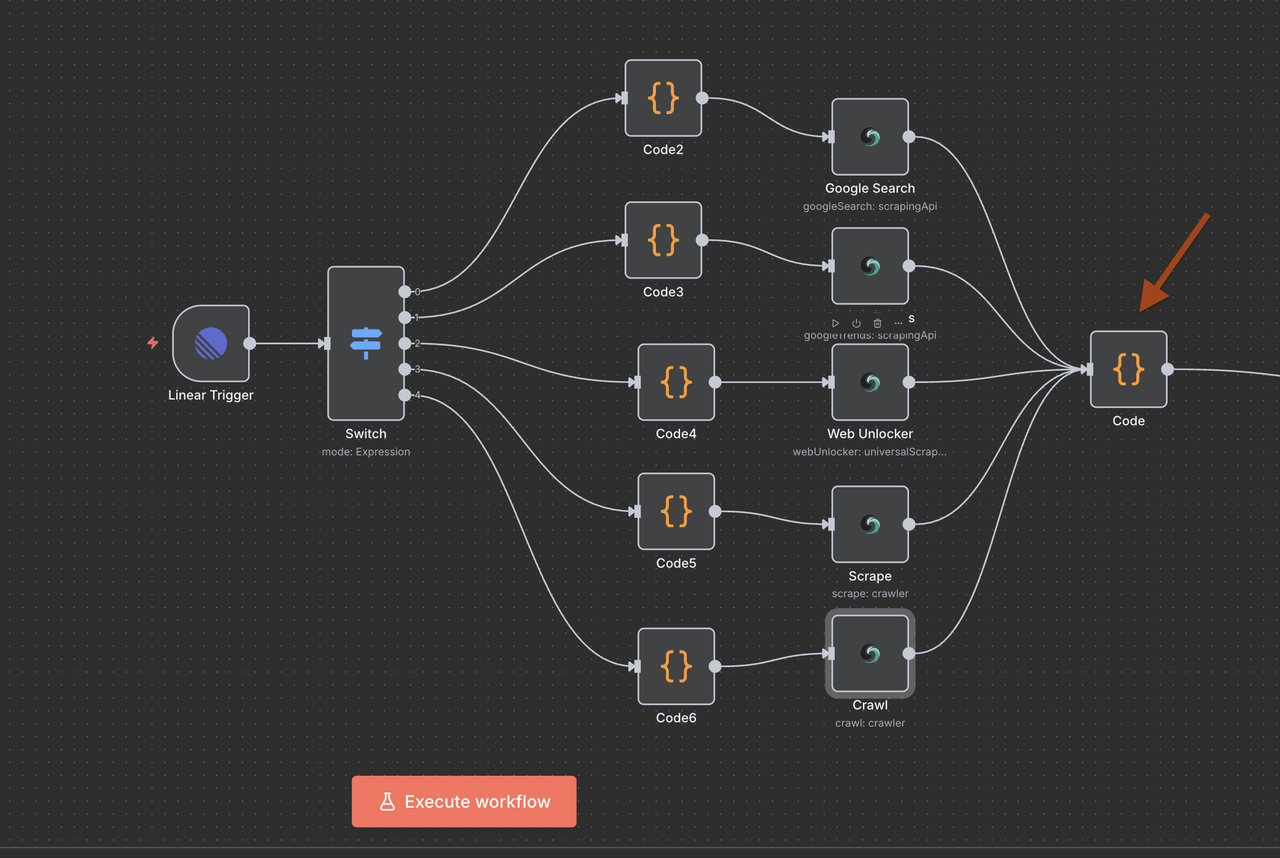
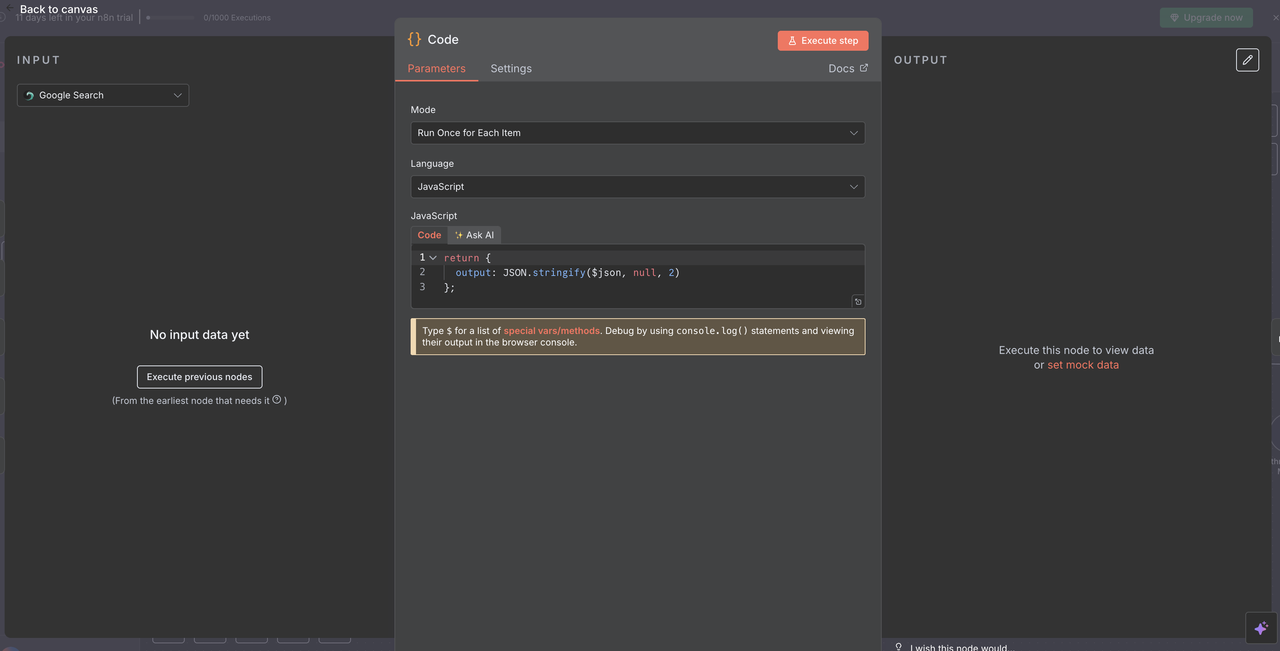
5つのScrapeless操作ブランチのいずれかを実行した後、単一のコードノードがAI処理のために応答を標準化するために使用されます。
収束コードノードの目的:
- いかなるScrapelessノードからの出力を集約
- すべてのコマンド間でデータ形式を標準化
- Claudeや他のAIモデル入力のための最終ペイロードを準備
コード設定:
javascript
// Scrapelessの応答をAIが読み取れる形式に変換
return {
output: JSON.stringify($json, null, 2)
};
ステップ9: Claude AI分析エンジン
インテリジェントなデータ分析とインサイト生成
9.1 AIエージェントノードの設定
⚠️ ClaudeのAPIキーを設定するのを忘れないでください。
AIエージェントノードは魔法が起こる場所です — 標準化されたScrapelessの出力を引き受け、明確で実行可能なインサイトに変換します。
設定の詳細:
- プロンプトタイプ:
定義 - テキスト入力:
{{ $json.output }}(収束ノードからの処理済みJSON文字列) - システムメッセージ: Claudeのトーン、役割、タスクを設定
AI分析システムプロンプト:
あなたはデータアナリストです。検索/スクレイピング結果を簡潔に要約してください。事実に基づいて簡潔にしてください。Linearコメント用にフォーマットしてください。
提供されたデータを分析し、以下を含む構造化された要約を作成してください:
- 主な発見とインサイト
- データソースと信頼性評価
- 実行可能な推奨事項
- 関連するメトリクスとトレンド
- さらなる調査のための次のステップ
Linearでの読みやすさのために、明確なヘッダーと箇条書きで応答をフォーマットしてください。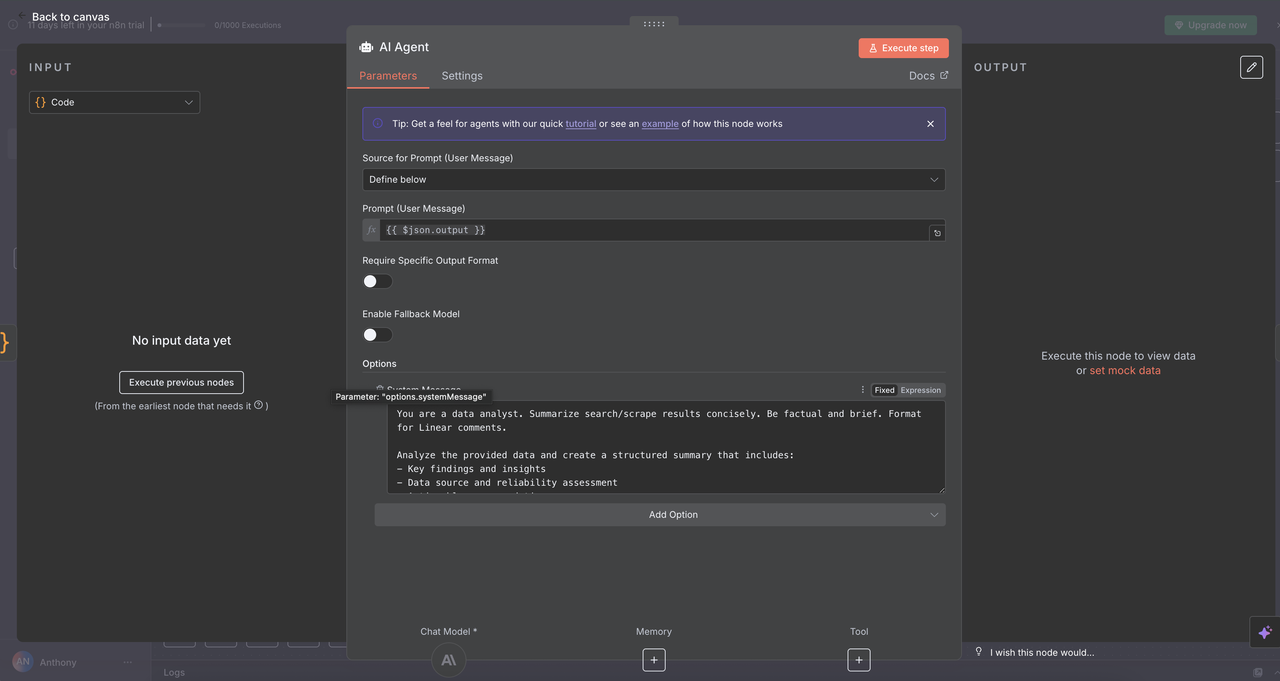
なぜこのプロンプトが機能するのか
- 具体性: Claudeにどのタイプの分析を行うべきかを正確に示す
- 構造: 明確なセクションで整理された出力を要求
- コンテキスト: Linearコメント形式に最適化
- 実行可能性: チームが行動できるインサイトに焦点を当てる
9.2 Claudeモデル設定
Anthropic ChatモデルノードはAIエージェントをClaudeの強力な言語処理に接続します。
モデル選択とパラメータ
- モデル:
claude-3-7-sonnet-20250219(Claude Sonnet 3.7) - 温度:
0.3(創造性と一貫性のバランス) - 最大トークン数:
4000(包括的な回答に十分)
これらの設定の理由
- Claude Sonnet 3.7: 知性、パフォーマンス、コスト効率の強いバランス
- 低温度 (0.3): 事実に基づいた、一貫した応答を保証
- 4000トークン: 過度なコストをかけずに深い洞察を生成するのに十分
ステップ10: 応答の処理とクリーンアップ
Claudeの出力をLinearコメントのために準備する
10.1 応答クリーンニングコードノード
ClaudeがAIの応答をクリーンアップし、Linearコメントに適切に表示されるためのコードノード。
応答クリーンニングコード:
// LinearコメントのためにClaude AI応答をクリーンアップ
return {
output: $json.output
.replace(/\\n/g, '\n')
.replace(/\\\"/g, '"')
.replace(/\\\\/g, '\\')
.trim()
};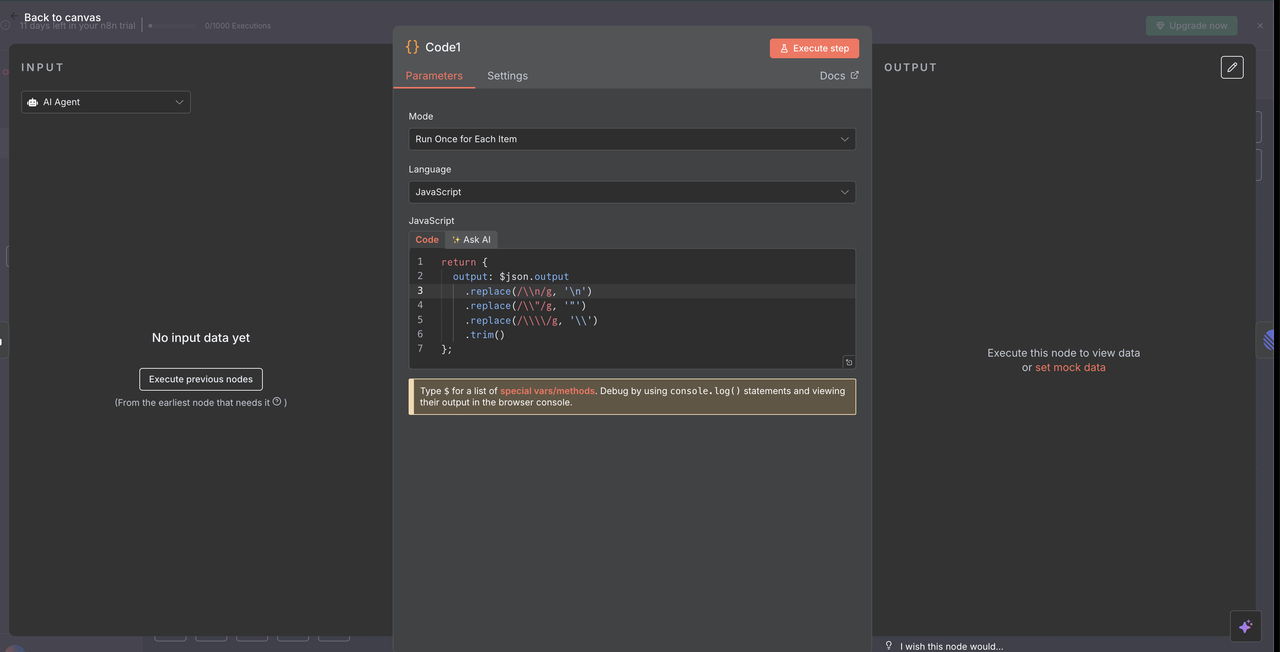
このクリーンアップが達成すること
- エスケープ文字の削除: 直されるべき特殊文字を表示するためのJSONエスケープ文字を削除
- 改行修正: リテラルな
\n文字列を実際の改行に変換 - 引用符の正規化: 引用符がLinearコメントに正しくレンダリングされるようにする
- 空白のトリミング: 不要な先頭および末尾のスペースを削除
クリーンアップが必要な理由
- Claudeの出力は特殊文字をエスケープしたJSONとして提供される
- Linearのマークダウンレンダラーは、適切にフォーマットされたプレーンテキストを必要とする
- このクリーンアップステップがなければ、応答には生のエスケープ文字が表示され、可読性が損なわれる
10.2 Linearコメントの配信
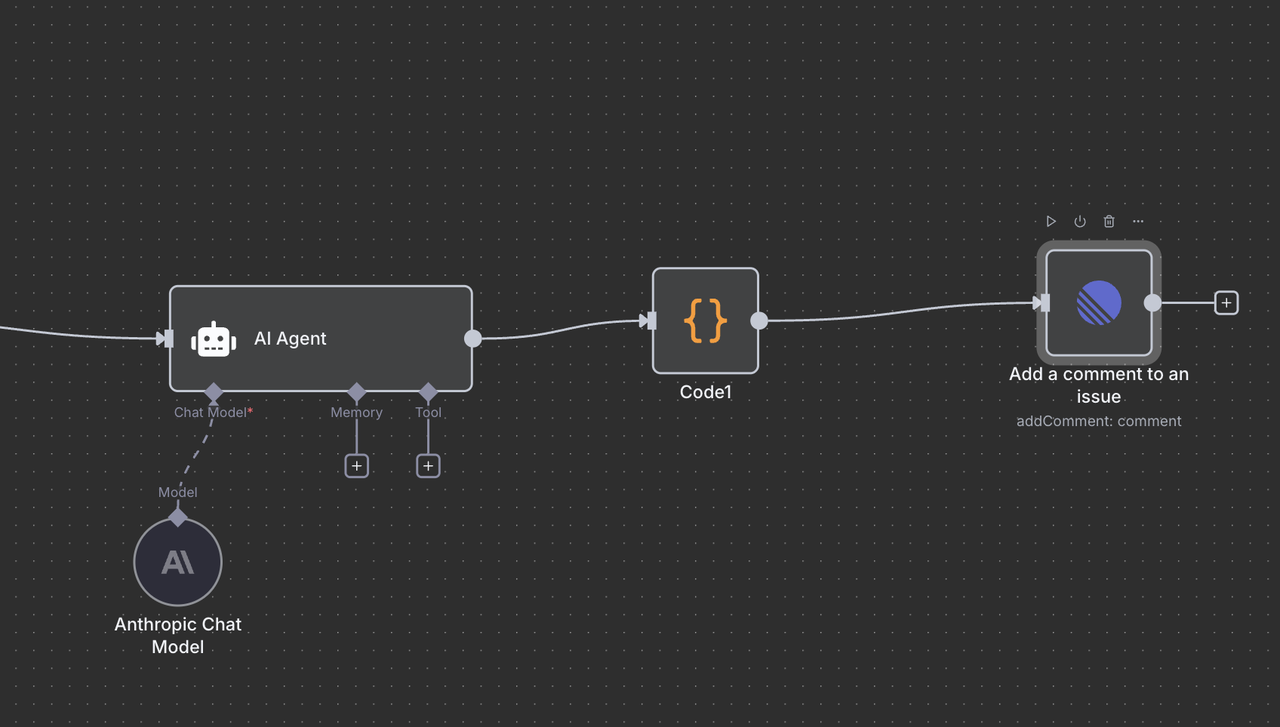
最後のLinearノードは、AIが生成した分析を元の問題にコメントとして投稿します。
設定詳細:
- リソース:
"Comment"操作に設定 - 問題ID:
{{ $('Linear Trigger').item.json.data.id }} - コメント:
{{ $json.output }} - 追加フィールド: 必要に応じてメタデータやフォーマットオプションを含める
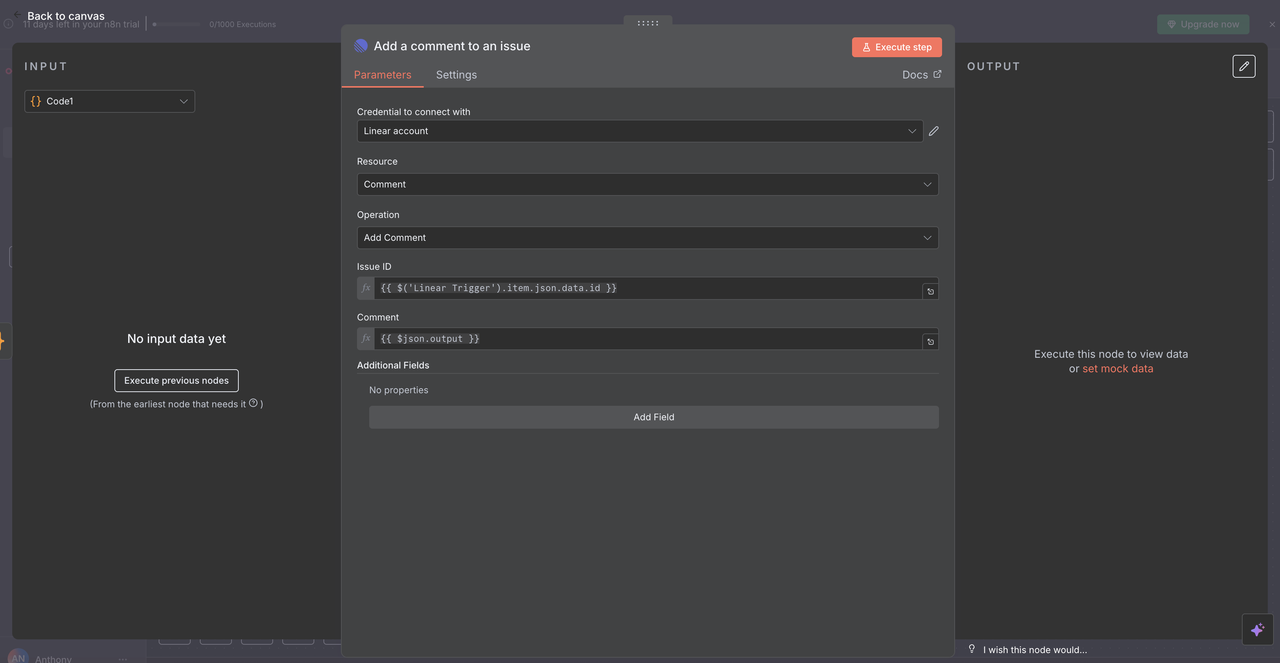
問題IDの働き
- 元のLinear Triggerノードを参照
- ワークフローを開始したウェブフックから正確な問題IDを使用
- AIの応答が正しいLinearの問題に表示されるようにする
完全なサークル
- ユーザーが
/search competitive analysisを使用して問題を作成 - ワークフローがコマンドを処理し、データを収集
- Claudeが収集された結果を分析
- 分析結果が同じ問題にコメントとして投稿される
- チームは文脈の中で研究の洞察を直接見る
ステップ11: 研究アシスタントのテスト
完全なワークフローの検証
すべてのノードが設定された今、各コマンドタイプをテストして正しい機能を確認しましょう。
11.1 各コマンドタイプをテスト
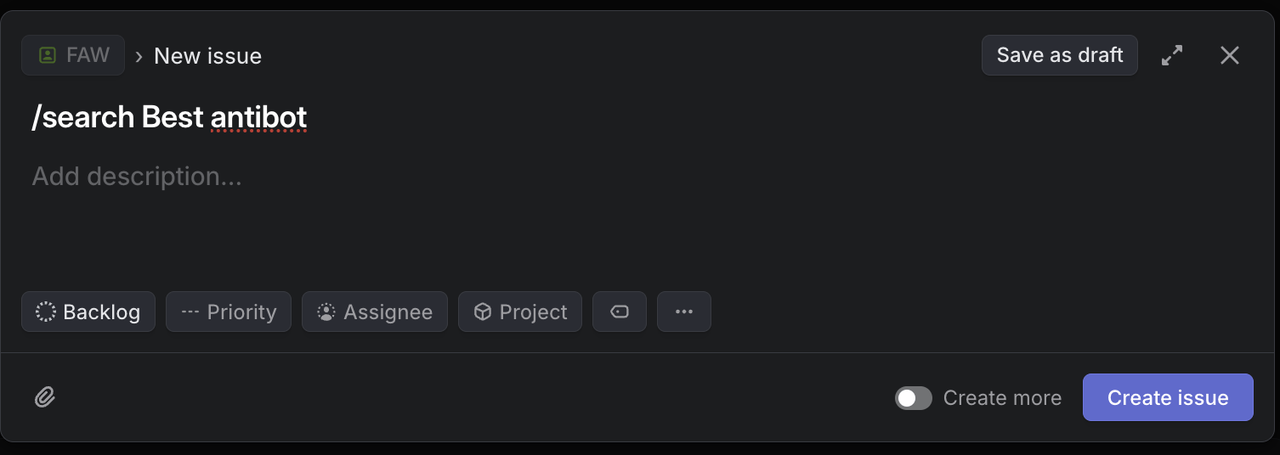
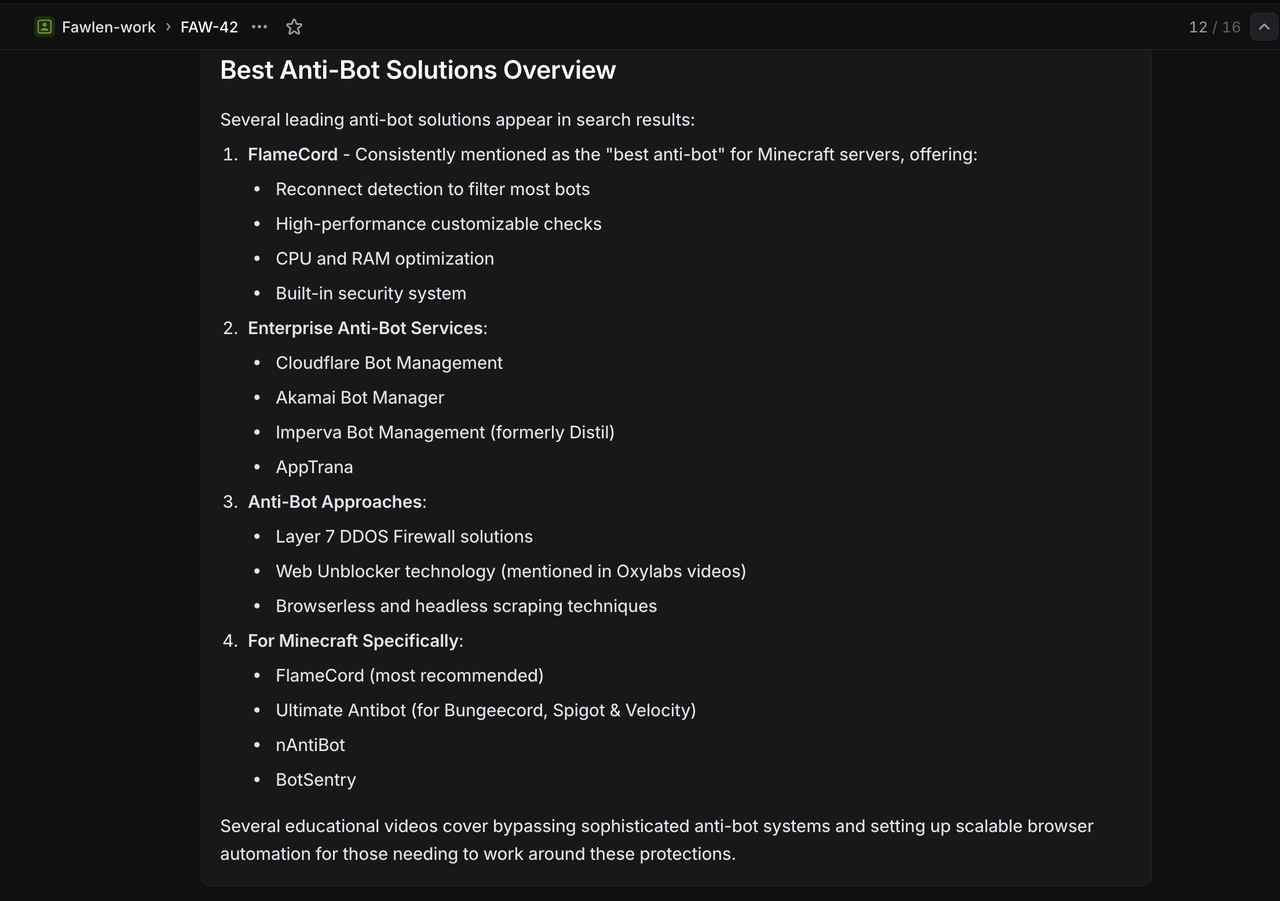
次の特定のタイトルでLinearにテスト問題を作成:
Google検索テスト:
`/search competitive analysis for SaaS platforms` 期待される結果: SaaS競争分析に関するGoogle検索結果を返します。
Googleトレンドテスト:
`/trends artificial intelligence adoption` 期待される結果: AI導入に対する関心の推移データを返します。
ウェブアンロックテスト:
`/unlock https://competitor.com/pricing` 期待される結果: 保護されたまたはJavaScriptを多く使用した価格ページの内容を返します。
スクレイパーテスト:
`/scrape https://news.ycombinator.com` 期待される結果: Hacker Newsのホームページから構造化されたコンテンツを返します。
クロールテスト:
`/crawl https://docs.anthropic.com` 期待される結果: Anthropicのドキュメントの複数のページからのコンテンツを返します。
トラブルシューティングガイド
Linearウェブフックの問題
- 問題: ウェブフックがトリガーしない
- 解決策: ウェブフックURLとLinearの権限を確認
- 確認: n8nウェブフックエンドポイントのステータス
Scrapeless APIエラー
- 問題: 認証失敗
- 解決策: APIキーとアカウント制限を確認
- 確認: 使用メトリクスのためのScrapelessダッシュボード
Claude AIのレスポンス問題
- 問題: 不十分または不完全な分析
- 解決策: システムのプロンプトとコンテキストを洗練する
- 確認: 入力データの品質とフォーマット
リニアコメントフォーマット
- 問題: マークダウンまたはフォーマットの破損
- 解決策: レスポンスクリーニングコードを更新する
- 確認: 特殊文字の取り扱い
結論
Linearのコラボレーティブな作業スペース、Scrapelessの信頼できるデータ抽出、そしてClaude AIの知的分析の組み合わせは、チームが情報を収集し処理する方法を変革する強力な研究自動化システムを作り出します。
この統合は、研究ニーズを特定し、実行可能な洞察を得る間の摩擦を排除します。Linearの課題にコマンドを入力するだけで、チームは従来数時間の手作業を必要とした包括的なデータ収集と分析のワークフローを開始できます。
主な利点
- ⚡ 即時研究: 質問から洞察まで60秒未満
- 🎯 コンテキストの保持: 研究がプロジェクトの議論に接続されたまま
- 🧠 AIの強化: 生データが自動的に実行可能なインテリジェンスに変わる
- 👥 チームの効率: チーム全体がアクセスできる共有研究
- 📊 包括的なカバレッジ: 統一されたワークフロー内の複数のデータソース
チームの研究能力を反応的からプロアクティブに変革しましょう。Linear、Scrapeless、Claudeが連携することで、単なるデータ収集にとどまらず、ビジネスの成長に合わせた競争優位のインテリジェンスを構築しています。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


