
スクレイピングなしで、ブラウザをどのように最適に展開するか?
Senior Web Scraping Engineer
Scraping Browserは、日常的なデータ抽出と自動化作業のための定番ツールとなっています。Browser-UseをScrapeless Scraping Browserと統合することで、ブラウザ自動化の制限を克服し、ブロックを回避することができます。
この記事では、Browser-UseとScrapeless Scraping Browserを使用して自動化されたAIエージェントツールを構築し、自動データスクレイピングを行います。これにより、時間と労力を節約し、自動化作業を簡単に行える方法を示します!
以下のことを学びます:
- Browser-Useとは何か、AIエージェントの構築にどのように役立つのか?
- Scraping BrowserはなぜBrowser-Useの制限を効果的に克服できるのか?
- Browser-UseとScraping Browserを使用して、ブロックフリーのAIエージェントをどのように構築するのか?
Browser-Useとは?
Browser-Useは、AIエージェントに高度なブラウザ自動化機能を提供するために設計されたPythonベースのAIブラウザ自動化ライブラリです。ウェブページ上のすべてのインタラクティブ要素を認識し、エージェントがプログラム的にページと対話できるようにします。検索、クリック、フォーム入力、データスクレイピングなどの一般的な作業を実行します。Browser-Useはウェブサイトを構造化されたテキストに変換し、Playwrightなどのブラウザフレームワークをサポートし、ウェブインタラクションを大幅に簡素化します。
従来の自動化ツールとは異なり、Browser-Useは視覚的理解とHTML構造解析を組み合わせ、AIエージェントが自然言語の指示を使用してブラウザを制御できるようにします。これにより、AIはページコンテンツを知覚し、タスクを効率的に実行する能力が向上します。また、マルチタブ管理、要素インタラクションの追跡、カスタムアクション処理、組み込みのエラー回復メカニズムをサポートし、自動化ワークフローの安定性と一貫性を確保します。
さらに重要なことに、Browser-Useはすべての主要な大規模言語モデル(GPT-4、Claude 3、Llama 2など)と互換性があります。LangChain統合により、ユーザーは単に自然言語でタスクを説明すれば、AIエージェントが複雑なウェブ操作を完了します。AI駆動のウェブインタラクション自動化を求めるユーザーにとって、これは強力で期待の持てるツールです。
AIエージェント開発におけるBrowser-Useの限界
上述のように、Browser-Useはハリーポッターの魔法の杖のようには機能しません。むしろ、それは視覚的入力とAI制御を組み合わせてPlaywrightを使用してブラウザを自動化します。
Browser-Useには避けられないいくつかの欠点がありますが、これらの制限は自動化フレームワーク自体から生じるものではありません。むしろ、それは制御するブラウザから生じます。Playwrightのようなツールは、特定の設定および自動化ツールを使用してブラウザを起動しますが、これはボット検出システムにさらされる可能性もあります。
その結果、AIエージェントは頻繁にCAPTCHAの課題や「申し訳ありませんが、こちらの問題が発生しました」といったブロックされたページに遭遇する可能性があります。Browser-Useの真の潜在能力を発揮するには、慎重な調整が必要です。最終的な目標は、ボット検出システムのトリガーを避け、AI自動化がスムーズに実行されるようにすることです。
徹底的なテストの結果、我々は自信を持って言えます:Scraping Browserが最も効果的なソリューションです。
Scrapeless Scraping Browserとは?
Scraping Browserは、ダイナミックなウェブスクレイピングにおける3つの核心的な問題(高い同時実行ボトルネック、ボット回避、コスト管理)を解決するために設計されたクラウドベースのサーバーレスブラウザ自動化ツールです。
-
高い同時実行性とブロックしないヘッドレスブラウザ環境を提供し、開発者が容易にダイナミックコンテンツをスクレイピングできるようにします。
-
グローバルなプロキシIPプールとフィンガープリンティング技術を備えており、CAPTCHAの自動解決やブロック機構の回避が可能です。
特にAI開発者向けに構築されたScrapeless Scraping Browserは、深くカスタマイズされたChromiumコアとグローバルに分散したプロキシネットワークを特徴としています。ユーザーは、AIアプリケーションやエージェントを構築するために、複数のヘッドレスブラウザインスタンスをシームレスに実行および管理できます。ローカルインフラの制約やパフォーマンスのボトルネックを排除し、ソリューションの構築に全力を注ぐことができます。
Browser-UseとScraping Browserはどのように連携して動作するのか?
これらを組み合わせることで、開発者はBrowser-Useを使用してブラウザ操作を調整し、Scrapelessの安定したクラウドサービスと強力なブロック回避機能を利用して、ウェブデータを信頼性高く取得できます。
Browser-Useは、AIエージェントがウェブコンテンツを「理解」し、対話できるようにするシンプルなAPIを提供します。たとえば、Playwrightを介して、検索やリンクのクリックなどのアクションを完了するために、OpenAIやAnthropicのようなLLMを使用してタスク指示を解釈できます。
スクレイピングブラウザ「Scrapeless」の設定は、その弱点を解決します。厳格なボット対策がある大規模なウェブサイトに対応する際には、高い同時接続性のプロキシサポートやCAPTCHA解決、ブラウザエミュレーション機能により安定したスクレイピングが可能です。
要約すると、Browser-Useはインテリジェンスとタスクのオーケストレーションを扱い、Scrapelessは堅牢なスクレイピング基盤を提供し、自動化されたブラウザタスクをより効率的かつ信頼性のあるものにします。
スクレイピングブラウザをBrowser-Useに統合する方法
ステップ1. Scrapeless APIキーを取得
- Scrapelessダッシュボードに登録してログインします。
- 「設定」に移動します。
- 「APIキー管理」をクリックします。
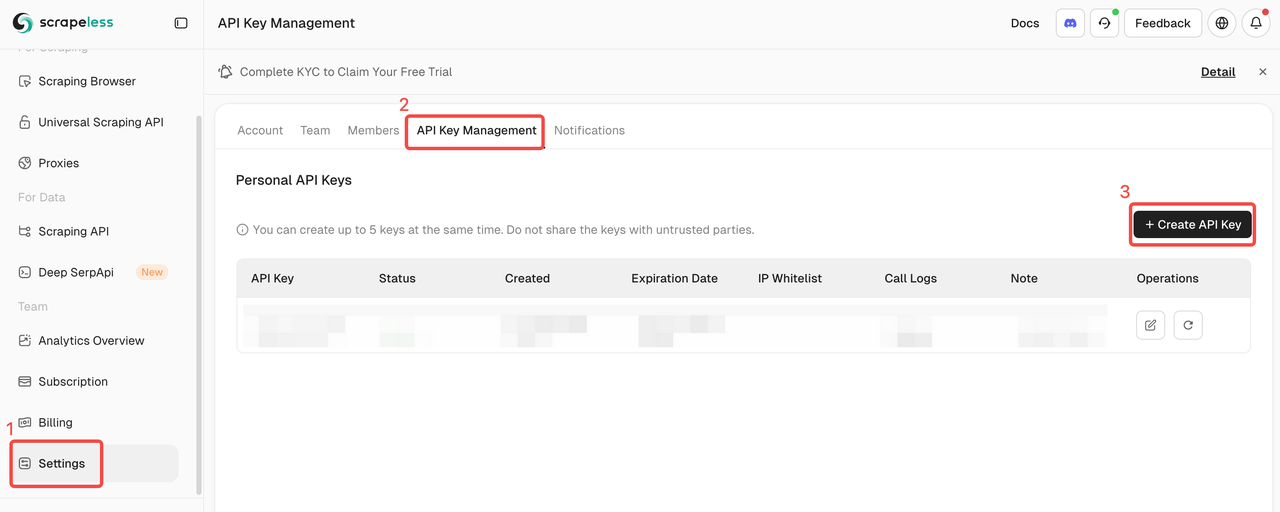
次に、コピーしてSCRAPELESS_API_KEY環境変数を.envファイルに設定します。
Browser-UseでAI機能を有効にするには、外部のAIプロバイダーから有効なAPIキーが必要です。この例ではOpenAIを使用します。まだAPIキーを生成していない場合は、OpenAIの公式ガイドに従って作成してください。
OPENAI_API_KEY環境変数も.envファイルに必要です。
注意:以下のステップはOpenAIの統合方法に焦点を当てていますが、他のAIツールに適応することも可能です。Browser-Useがサポートする他のAIツールを使用してください。
.evn
OPENAI_API_KEY=your-openai-api-key
SCRAPELESS_API_KEY=your-scrapeless-api-key💡サンプルAPIキーを実際のAPIキーに置き換えることを忘れないでください。
次に、プログラムでChatOpenAIをインポートします:langchain_openaiagent.py
Plain Text
from langchain_openai import ChatOpenAIBrowser-UseはAI統合を処理するためにLangChainに依存しています。そのため、プロジェクトにlangchain_openaiが明示的にインストールされていなくても、すでに利用可能です。
gpt-4oは次のモデルでOpenAIとの統合を設定します:
Plain Text
llm = ChatOpenAI(model="gpt-4o")追加の設定は必要ありません。これは、langchain_openaiが自動的に環境変数OPENAI_API_KEYからAPIキーを読み込むからです。
他のAIモデルやプロバイダーとの統合については、公式のBrowser-Useドキュメンテーションを参照してください。
ステップ2. Browser Useをインストール
pipを使用して(Pythonバージョンは少なくとも3.11):
Shell
pip install browser-useメモリ機能のために(PyTorchとの互換性のため、Python < 3.13が必要):
Shell
pip install "browser-use[memory]"ステップ3. ブラウザとエージェントの設定
ブラウザを設定し、自動化エージェントを作成する方法は次のとおりです:
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Googleにアクセスし、「Scrapeless」を検索し、最初の投稿をクリックし、タイトルを返す"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # または使用したいモデルを選択してください
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)ステップ4. メイン関数を作成
すべてを統合するメイン関数は次のとおりです:
Python
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())ステップ5. スクリプトを実行
スクリプトを実行します:
Shell
python run main.pyScrapelessセッションがScrapelessダッシュボードに表示されるはずです。
さらに、Scrapelessはセッションリプレイをサポートしており、プログラムの可視化を可能にします。プログラムを実行する前に、Web録画機能を有効にしておいてください。セッションが完了すると、ダッシュボードで直接記録を見ることができ、問題の迅速なトラブルシューティングに役立ちます。
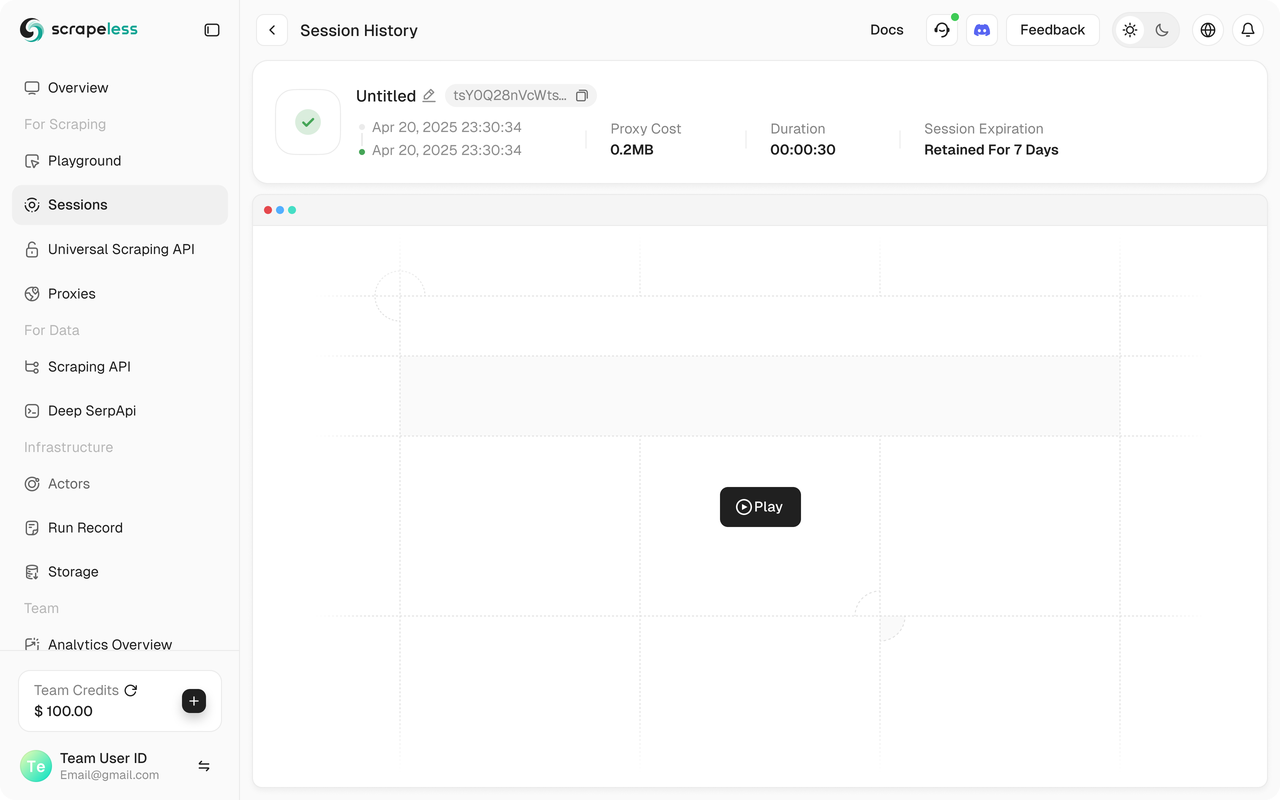
完全なコード
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Googleに行き、「Scrapeless」を検索し、最初の投稿をクリックして、タイトルを返します"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # 使用したいモデルを選択してください
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())💡ブラウザの使用は現在Pythonのみサポートされています。
💡ライブセッションのURLをコピーすれば、セッションの進捗をリアルタイムで確認でき、セッション履歴でセッションの再生見ることもできます。
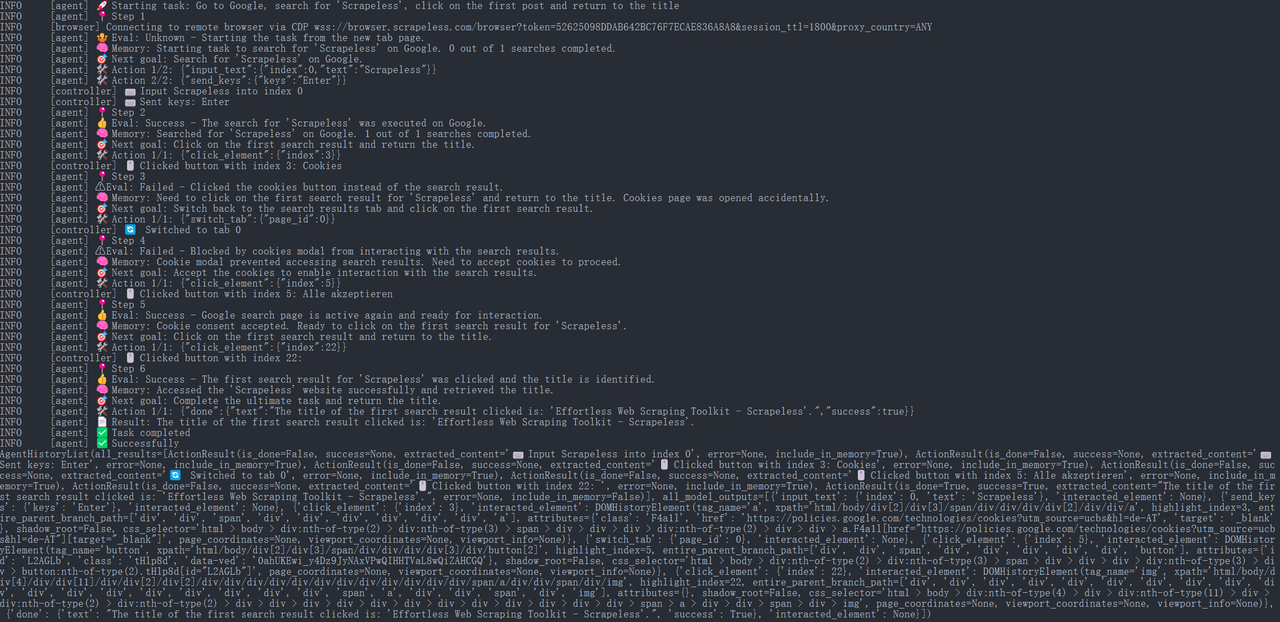
ステップ6. 実行結果
JavaScript
{
"done": {
"text": "最初にクリックした検索結果のタイトルは: 'Effortless Web Scraping Toolkit - Scrapeless'です。",
"success": true,
}
}
その後、ブラウザ使用エージェントは自動的にURLを開き、ページタイトルを印刷します:「Scrapeless: Effortless Web Scraping Toolkit」(これはScrapelessの公式ホームページのタイトルの例です)。
実行プロセス全体は、Scrapelessのコンソールの「ダッシュボード」→「セッション」→「セッション履歴」ページで表示でき、最近実行したセッションの詳細を見ることができます。
ステップ7. 結果のエクスポート
チームでの共有やアーカイブ目的で、スクレイピングした情報をJSONまたはCSVファイルに保存できます。例えば、以下のコードスニペットはタイトル結果をファイルに書き込む方法を示しています:
Python
import json
from pathlib import Path
def save_to_json(obj, filename):
path = Path(filename)
path.parent.mkdir(parents=True, exist_ok=True)
with path.open('w', encoding='utf-8') as f:
json.dump(obj, f, ensure_ascii=False, indent=4)
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
save_to_json(result.model_dump(), "scrapeless_update_report.json")
await browser.close()
asyncio.run(main())上記のコードは、ファイルを開いて検索キーワード、リンク、ページタイトルを含む内容をJSON形式で書き込む方法を示しています。生成されたscrapeless_update_report.jsonファイルは、社内のナレッジベースやコラボレーションプラットフォームを通じて共有可能で、チームメンバーがスクレイピング結果を簡単に確認できます。プレーンテキスト形式の場合、単に拡張子を.txtに変更し、基本的なテキスト出力メソッドを使用すればよいでしょう。
まとめ
Scrapelessのスクレイピングブラウザサービスを、ブラウザ使用AIエージェントと組み合わせることで、情報取得と報告のための自動システムを容易に構築できます。
- Scrapelessは、複雑な対スクレイピングメカニズムに対応できる安定した効率的なクラウドベースのスクレイピングソリューションを提供します。
- ブラウザ使用は、検索、クリック、抽出といったタスクを実行するためにAIエージェントがブラウザを賢く制御できるようにします。
この統合により、開発者は煩雑なウェブデータ収集タスクを自動エージェントにオフロードでき、研究の効率が大幅に向上し、正確性とリアルタイム結果を保証します。
Scrapelessのスクレイピングブラウザは、リアルタイムの検索データを取得する際にAIがネットワークのブロックを回避できるようにし、操作の安定性を確保します。ブラウザ使用の柔軟な戦略エンジンと組み合わせることで、強力なAI自動化研究ツールを構築し、賢いビジネス意思決定を強力にサポートします。このツールセットにより、AIエージェントはデータベースと対話するかのようにウェブコンテンツを「クエリ」でき、手動の競合監視コストを大幅に削減し、R&Dおよびマーケティングチームの効率を向上させます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


