
ブラウザフィンガープリンティングとは何か、そしてどのように識別フィンガープリントを作成するのか
Senior Web Scraping Engineer
ブラウザフィンガープリンティングは、デバイスインテリジェンス構築の基礎であり、企業が世界中のウェブサイトでウェブサイト訪問者を一意に識別することを可能にします。
指紋がループ、渦巻き、弓状紋の絶対的にユニークな組み合わせであるように、ウェブサイトに接続するために使用するウェブブラウザも、ユニークな印象を残します。ただし、二重ループやテント型の弓状紋ではなく、ブラウザには画面解像度、保存されたWebGL、グラフィックカード構成などのパーソナルマーカーがあります。
ブラウザフィンガープリンティングとは何か、どのようにデバイスを検出し、ボット活動をブロックするのか?この記事を読んで、今すぐそれらを解明しましょう。
ブラウザフィンガープリンティングとは?
ブラウザフィンガープリンティングは、ウェブユーザーの閲覧活動を通じてデータを収集できるツールと技術のセットです。ウェブサイトは、ユーザーのオペレーティングシステム、ブラウザの種類、画面解像度、タイムゾーン、キーボードレイアウトなど、さまざまな情報を収集し、このプロセスは通常、あなたの知らないうちに実行されます。これらの詳細を処理することにより、各ユーザーに対して一意の識別子または「デジタルフィンガープリント」を作成します。
ブラウザフィンガープリンティングはクッキーと少し似ていますが、フィンガープリンティングはユーザーの同意を必要とせず、「オプトアウト」機能がない点が異なります。これは、クッキーを使用するウェブサイトを最初に訪問したときに基本的に確認できます。
収集されるデータ
ブラウザフィンガープリンティングツールは、ユーザーのソフトウェアおよびハードウェア構成に関連するユーザーデータを収集します。これには以下が含まれます。
| ✅ システムフォント | ✅ クッキーが有効になっているかどうか |
| ✅ オペレーティングシステム | ✅ OS言語 |
| ✅ オペレーティングシステム | ✅ OS言語 |
| ✅ プラットフォーム | ✅ HTTPヘッダー属性 |
| ✅ キーボードレイアウト | ✅ 使用されているウェブブラウザ拡張機能 |
| ✅ Torブラウザかどうか | ✅ オーディオコンテキスト分析 |
| ✅ セキュアブラウザかどうか | ✅ CPUクラス |
| ✅ ユーザーエージェント | ✅ HTML 5キャンバスフィンガープリンティング(キャンバスサイズ) |
| ✅ ブラウザローカルデータベース | ✅ タッチサポート |
| ✅ ナビゲータープロパティ | ✅ 加速度計、近接センサー、ジャイロスコープなどのセンサー |
どのようにして発見されたのか?
トラッキングまたは識別されている場合、ブラウザの構成、プラグイン、または適切なプライバシー対策の不足が、フィンガープリントを際立たせている可能性があります。フィンガープリントは、特に以下のユーザーにとって効果的です。
- ユニークなブラウザ構成に依存しているユーザー
- 高度にカスタマイズされた、または古いブラウザを使用しているユーザー
- JavaScriptまたはCanvasデータの収集をブロックできないユーザー
検出を回避するには、プライバシー重視のブラウザ、アンチディテクトブラウザソリューションなどのツール、不要なプラグインの無効化、またはフィンガープリントデータを難読化するブラウザ機能の活用を検討してください。
ブラウザフィンガープリンティングの仕組み
1️⃣ ステップ1. データ収集
ウェブサイトは、JavaScriptやその他のテクノロジーを通じて、ブラウザの種類、オペレーティングシステム、画面解像度、言語設定、フォント、ハードウェア情報(GPUなど)、Canvas/WebGLレンダリング出力など、ユーザーのブラウザとデバイスに関する情報を収集します。
2️⃣ ステップ2. 属性の組み合わせ
収集された複数の属性はデータセットに統合され、一部の属性(ブラウザのアップグレードなど)が変更されても、十分な一意性を維持できます。
3️⃣ ステップ3. 一意の識別子の生成
これらのデータセット(ハッシュ計算など)を処理することにより、ユーザーのデバイスとブラウザを識別するためのユニークなフィンガープリントが生成されます。
4️⃣ ステップ4. セッションとウェブサイト全体のトラッキング
ウェブサイトは、生成されたフィンガープリントを使用してユーザーをトラッキングし、ユーザーがクッキーをクリアしたり、プライバシーモードを有効にしたりしても、同じユーザーを識別できます。
ブラウザフィンガープリンティングをバイパスする方法
Scrapeless Scraping Browserは、ブラウザフィンガープリンティングをバイパスする効果的な方法です。高性能のサーバーレスプラットフォームを提供します。動的なウェブサイトからデータを抽出するプロセスを効果的に簡素化します。開発者は、専用のサーバーなしでヘッドレスブラウザを実行、管理、監視できるため、効率的なウェブ自動化とデータ収集が可能になります。
Scrapelessがウェブスクレイピングに最適な理由
Scrapeless Scraping Browserは、195か国と7,000万以上の住宅用IPアドレスを網羅するグローバルネットワーク、強力なウェブアンロッカー、非常に安定したCAPTCHAソルバーを備えています。信頼性が高く、スケーラブルなウェブスクレイピングソリューションが必要なユーザーに最適です。
Scrapelessスクレイピングブラウザの使い方
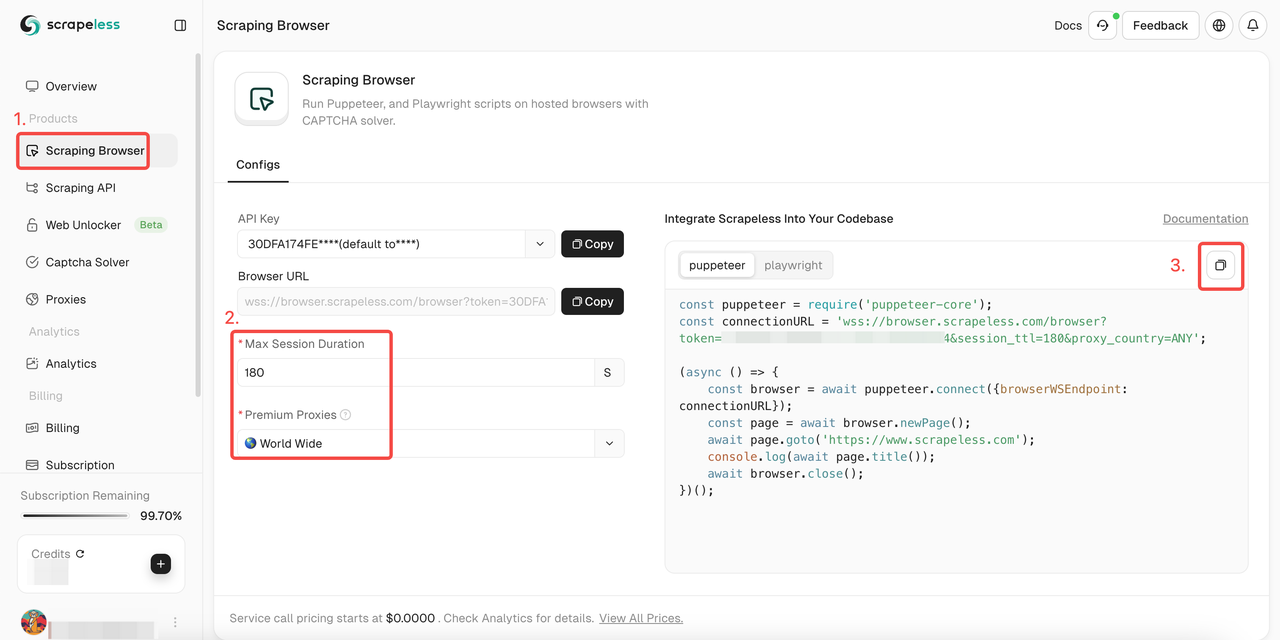
- ステップ1. Scrapelessにサインイン
- ステップ2. 「Scraping Browser」を入力
- ステップ3. 必要に応じてパラメーターを設定
- ステップ4. プロジェクトに統合するためのサンプルコードをコピーします。
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //APIトークンを入力
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //APIトークンを入力
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();詳細を知りたいですか?ドキュメントが役に立ちます!
- Puppeteer:
必要なライブラリのインストール
まず、既存のブラウザインスタンスに接続するために設計されたPuppeteerの軽量バージョンであるpuppeteer-coreをインストールします。
Bash
npm install puppeteer-coreスクレイピングブラウザに接続するためのコードの記述
Puppeteerコードで、次の方法を使用してScraping Browserに接続します。
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();このようにして、スケーラビリティ、IPローテーション、グローバルアクセスなどのScraping Browserインフラストラクチャを活用できます。
例:
Scraping Browserと統合した後の一部の一般的なPuppeteer操作を次に示します。
- ナビゲーションとページコンテンツの抽出
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- スクリーンショット
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- カスタムスクリプトの実行
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();- Playwright:
必要なライブラリのインストール
まず、既存のブラウザインスタンスに接続するPlaywrightの軽量バージョンであるplaywright-coreをインストールします。
Bash
npm install playwright-coreスクレイピングブラウザに接続するためのコードの記述
Playwrightコードで、次の方法を使用してScraping Browserに接続します。
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();これにより、スケーラビリティ、IPローテーション、グローバルアクセスなどのScraping Browserのインフラストラクチャを活用できます。
例:
Scraping Browserと統合した後の一部の一般的なPlaywright操作を次に示します。
- ナビゲーションとページコンテンツの抽出
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- スクリーンショット
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- カスタムスクリプトの実行
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();7つのブラウザフィンガープリンティング手法
1. キャンバスフィンガープリンティング
キャンバスフィンガープリンティングは、HTML5キャンバス要素を通じてユーザーのデバイスのGPUとグラフィックドライバの違いを分析します。スクリプトは画像を描画し、ブラウザのレンダリング結果を取得します。デバイスハードウェアの違いにより、レンダリングがわずかに異なり、これらの特性は一意の「キャンバスフィンガープリント」に変換されます。
2. WebGLフィンガープリンティング
このテクノロジーはWebGLを使用してユーザーのブラウザに3Dグラフィックスを生成し、生成されたグラフィックスの微妙な違い(GPUとドライバによって引き起こされる)を分析することにより、デバイスの一意の識別子を生成します。ユーザーを正確に区別するために、デバイスのハードウェアとドライバの組み合わせに依存します。
3. メディアデバイスフィンガープリンティング
メディアデバイスフィンガープリンティングは、ユーザーのデバイス上のメディアハードウェアと接続されているデバイスを識別することにより、フィンガープリントを生成します。ユーザーはカメラまたはマイクへのアクセスを承認する必要がありますが、メディアデバイスに依存するサービス(ビデオ通話など)にとって非常に役立ちます。
4. TLSフィンガープリンティング
TLSフィンガープリンティングは、安全な通信を確立する際にデバイスとサーバーで使用される暗号化アルゴリズムの組み合わせを分析することにより、デバイスを識別します。この方法は、TLSハンドシェイクの詳細を使用して、一意のデバイスフィンガープリントを生成します。
5. フォントフィンガープリンティング
このテクノロジーは、ユーザーのデバイスにインストールされているフォントのユニークなセットを使用してフィンガープリントを生成します。ユーザーのシステムのフォントの違いを検出することにより、ウェブサイトはユーザーデバイスを区別できます。この方法は、パーソナライズされたコンテンツ配信とユーザー識別に特に効果的です。
6. モバイルデバイスフィンガープリンティング
モバイルデバイスフィンガープリンティングは、オペレーティングシステムや画面解像度などのデータを使用して、デバイスの一意のプロファイルを作成します。プラットフォームがリピーターを識別し、異常なデバイス動作を検出するのに役立ち、ユーザーエクスペリエンスの最適化と不正行為の防止に重要なツールです。
7. オーディオフィンガープリンティング
オーディオフィンガープリンティングは、デバイスがオーディオを生成および処理する方法における小さなハードウェアとソフトウェアの違いをキャプチャすることにより、ユーザーを識別します。このテクノロジーは、デジタル著作権管理とパーソナライズされたオーディオコンテンツ配信で広く使用されています。
なぜフィンガープリントが収集されたのか?
- 不正検出。フィンガープリンティングは、高い不正リスクにさらされている可能性のあるサイトに早期警告指標を提供します。
- アカウントの作成と復旧。フィンガープリンティングは、同じユーザーが過剰なアカウントの生成/作成を防止します。これにより、サイト上のスパムが防止され、より高い保護が提供されます。これに加えて、フィンガープリントの照合は、ログイン情報を忘れた後にアカウントを復旧する必要があるユーザーの存在を確認するための非常に役立つツールです。
- コンテンツのパーソナライゼーション。コンテンツのパーソナライゼーションは、フィンガープリンティングと密接に関連しています。広告やウェブページのパーソナライゼーションは、あなたの使用履歴に基づいて構築され、あなたが見て、聞いて、あるいは購入したいと思うものを見つけることができます。
クッキーとブラウザフィンガープリンティング:具体的な違い
クッキーは、ウェブサイトがデバイスに保存して、訪問に関する情報を記憶する小さなデータ断片です。それらは透明で管理しやすく、ユーザーはブラウザの設定を通じてそれらを表示、削除、またはブロックできます。ただし、フィンガープリントは完全に受動的です。デバイスに保存されたり、あなたと直接やり取りしたりすることなく、データをサイレントに収集します。
次のコンテンツは、それらの違いを明確に理解するのに役立ちます。
| 機能 | クッキー | フィンガープリント |
|---|---|---|
| 永続性 | 一時的なもの。期限切れになったり、手動で削除されたりする可能性があります。 | 長期的なもの:めったに変更されないハードウェア、ソフトウェア、および行動データに基づいています。 |
| 透明性 | ユーザーの同意が必要です。ユーザーはクッキーを表示、削除、またはブロックできます。 | サイレントに動作し、多くの場合、ユーザーの認識やオプトアウトオプションはありません。 |
| トラッキング | ユーザーのデバイスに保存され、通常は明示的な同意が必要です。 | ユーザーの同意なしで受動的にデータ収集が行われます。 |
| 範囲 | 明示的に共有されない限り、特定のウェブサイトに限定されます。 | ウェブサイト、セッション、デバイス、さらには異なるネットワーク全体でユーザーをトラッキングします。 |
| 回避の難易度 | ブラウザの設定または拡張機能を使用して簡単にブロックまたは管理できます。 | アンチディテクトブラウザまたは特殊なツールなど、高度な対策が必要です。 |
| 開示 | バナーとプライバシーポリシーで開示されます。 | めったに開示されないため、フィンガープリンティングが発生したことをユーザーが認識するのが困難です。 |
まとめ
ブラウザフィンガープリンティングは、複雑なテクノロジーと深刻なプライバシー問題を組み合わせた、強力だが物議を醸すオンライントラッキングツールとなっています。「不可視化」などの従来のプライバシー防御策に抵抗する受動的なデータ収集を行うため、頻繁で多少侵襲的な追跡方法となっています。
シームレスなデータ収集とクロールを実現するために、フィンガープリント検出を効果的にバイパスするにはどうすればよいですか?Scrapeless Scraping Browserは、リアルなブラウザフィンガープリントとインテリジェントなIPローテーションを提供し、迅速な応答と効率的なウェブサイトのアンブロックを保証します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


