![AmazonスクレイピングAPI [2025完全ガイド]](/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Famazon-scraper-api%2Fda326fac686058aad592ae8e42e9abc3.png&w=1920&q=100)
AmazonスクレイピングAPI [2025]: これだけで十分な唯一のガイド
Advanced Data Extraction Specialist
eコマースデータの需要が高まるにつれ、Amazonプラットフォーム上のデータをクローリングして分析することがますます重要になっています。Amazon Scraper APIを使用することで、企業や開発者は、Amazonから製品情報、価格、レビュー、在庫、その他のデータを簡単に抽出できます。
しかし、技術の進歩にもかかわらず、多くのユーザーは依然として、効率的かつ正確にデータをクローリングする方法という課題に直面しています。
このガイドでは、Amazon Scraper APIを深く理解できるようにご案内します。
#1. Amazon Scraper APIの主要機能を理解する
#2. APIを迅速に設定してクローリングを開始する
#3. データクローリングのベストプラクティス
2025年現在、Amazon Scraper APIはより強力で柔軟になり、正確な構造化データを提供して、競争の激しい市場で優位に立つことができます。次に、このツールを最大限に活用する方法を詳しく説明します。
パート1:Amazon Scraper APIを使用する理由
Amazon Scraper APIは、企業がAmazonからのデータ収集を簡素化する強力なツールです。

使用する理由:
- **自動化されたデータ抽出:**製品データ収集を自動化することで時間を節約できます。
- **リアルタイム更新:**最新の価格、在庫、レビューなどでデータを最新の状態に保ちます。
- **正確な構造化データ:**分析と統合を容易にするために、構造化された形式(JSONなど)でデータを提供します。
- **競合価格の追跡:**競合他社の価格と製品の在庫状況を監視します。
- **スケーラブルで効率的:**IPブロックのリスクなしに、大量のデータを処理できます。
- **シームレスな統合:**迅速な設定と使用のために、システムに簡単に統合できます。
AmazonスクレイピングAPIのおすすめ
Amazonデータをスクレイピングする最も簡単な方法の1つは、Scrapelessのような専用のスクレイピングAPIを使用することです。このツールはプロセス全体を合理化し、ユーザーは製品の説明、レビュー、オファー、検索結果、価格などの重要な情報をJSON形式で簡単に抽出できます。
簡単なAPIコールだけで、Scrapelessは、広範なコーディング知識を必要とせずに、豊富なAmazonデータへのアクセスを可能にし、時間と労力を節約したいユーザーにとって理想的なソリューションとなります。
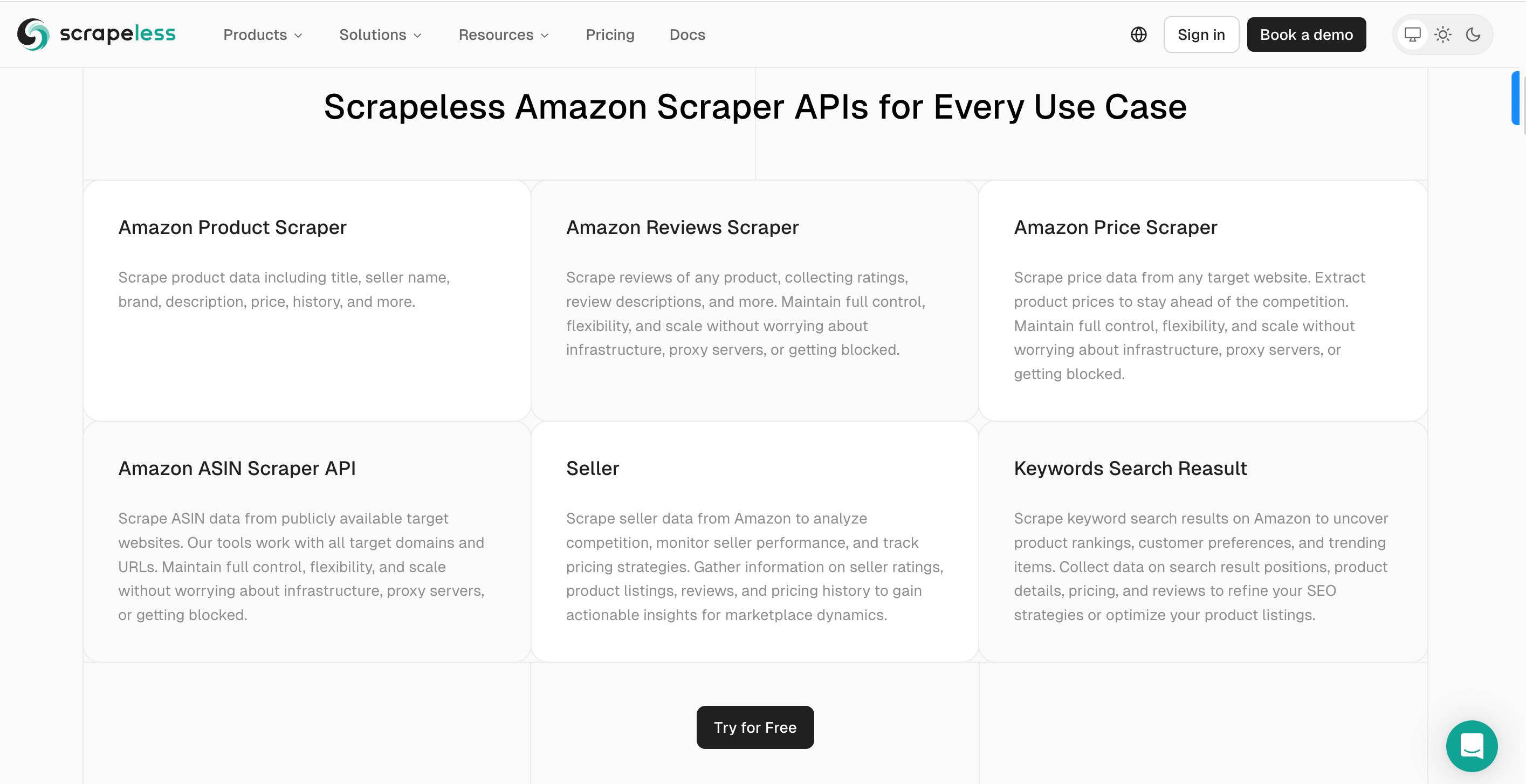
Scrapeless AmazonスクレイピングAPIを使用すると、次のようなことができます。
- **ユーザーフレンドリーなインターフェース:**ほとんどのツールは、スクレイピングするデータを選択しやすくするポイントアンドクリックインターフェースを提供しています。
- **事前に構築されたテンプレート:**Scrapelessなどのツールは、Amazon用に特別に設計された事前に構築されたテンプレートを提供し、ユーザーは最小限の設定で製品の詳細をスクレイピングできます。
- **自動化されたデータ抽出:**これらのツールは、IPローテーションとCAPTCHAの課題を自動的に処理するため、Amazonによってブロックされるリスクを軽減します。
Amazon Scraper APIを使用したAmazon製品データのスクレイピング方法:
ステップ1。Scrapelessにログインします
ステップ2。****スクレイピングAPIをクリック> Amazonを選択して、Shopeeスクレイピングページに入ります。
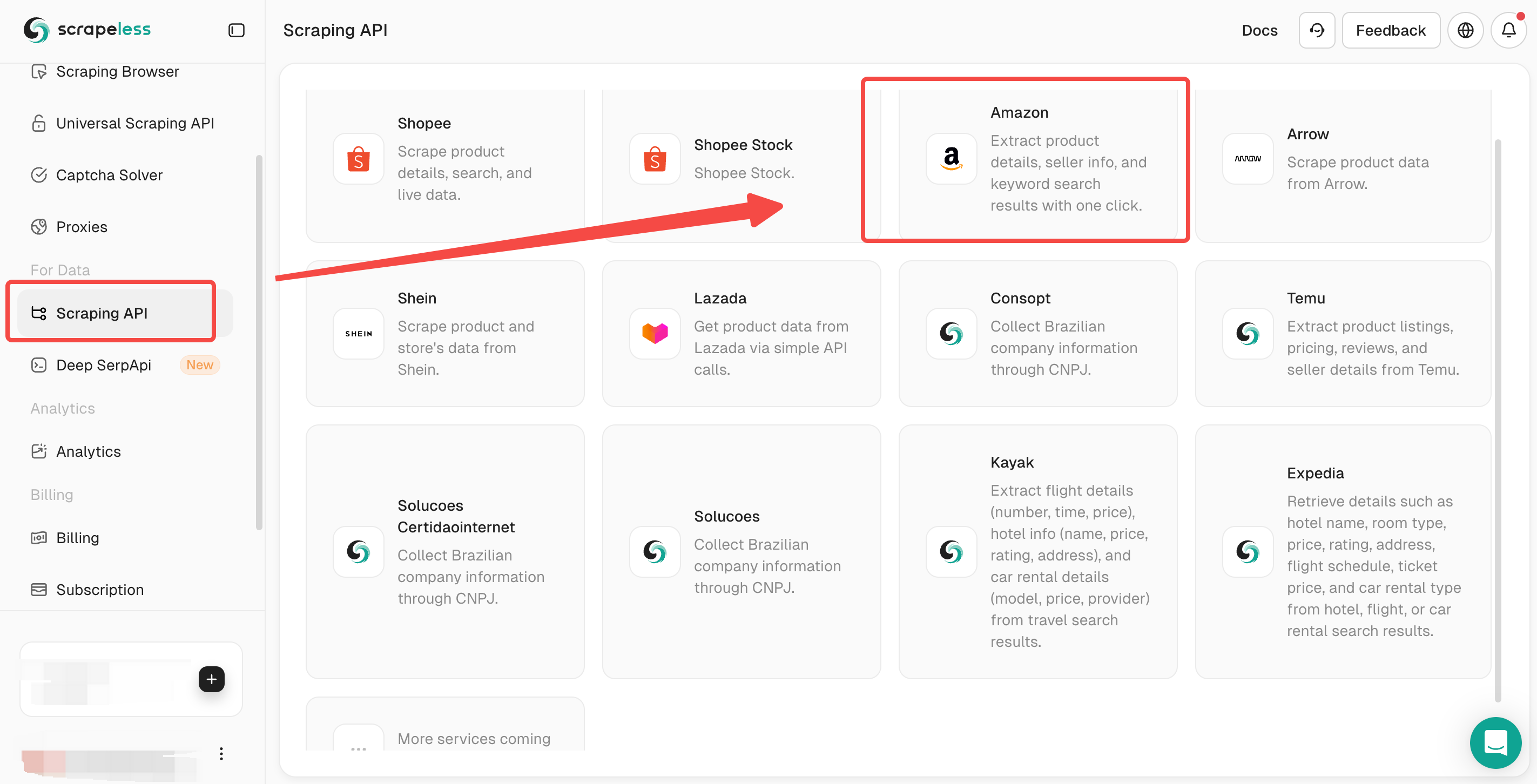
ステップ3。クローリングするAmazon製品ページのリンクを入力ボックスに貼り付けます。そして、クローリングするデータの種類を選択します。
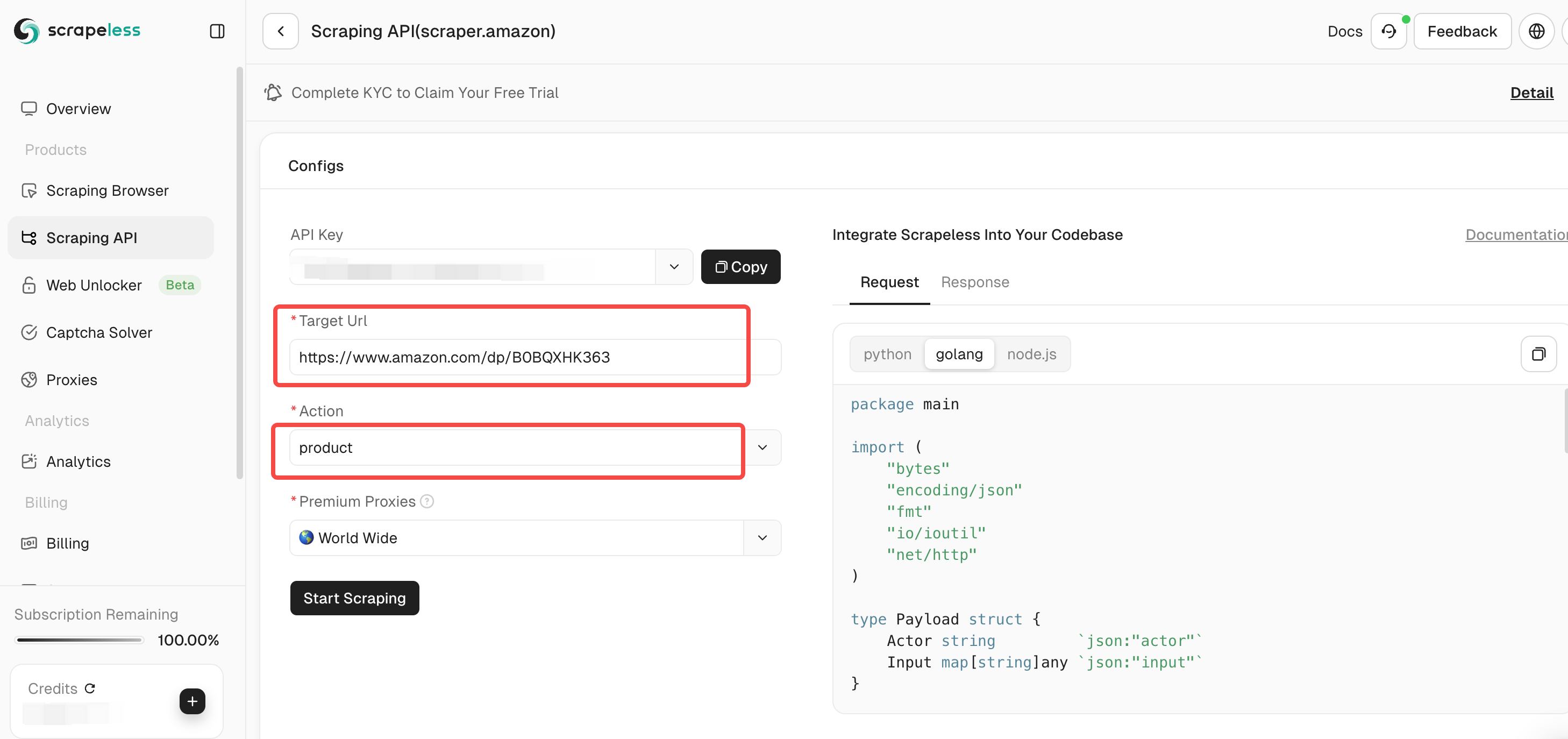
ツールページでは、クローリングするデータの種類を選択できます。
- **販売者:**販売者名、評価、連絡先情報など、販売者の情報をクローリングします。
- **製品:**タイトル、価格、評価、コメントなどの製品詳細をクローリングします。
- **キーワード:**製品に関連するキーワードをクローリングして、製品のSEOと市場トレンドを分析します。
**ステップ4。**入力リンクと選択したデータの種類が正しいことを確認したら、「スクレイピング開始」ボタンをクリックします。システムはデータのクローリングを開始し、クローリングされた結果をページの右側のパネルに表示します。
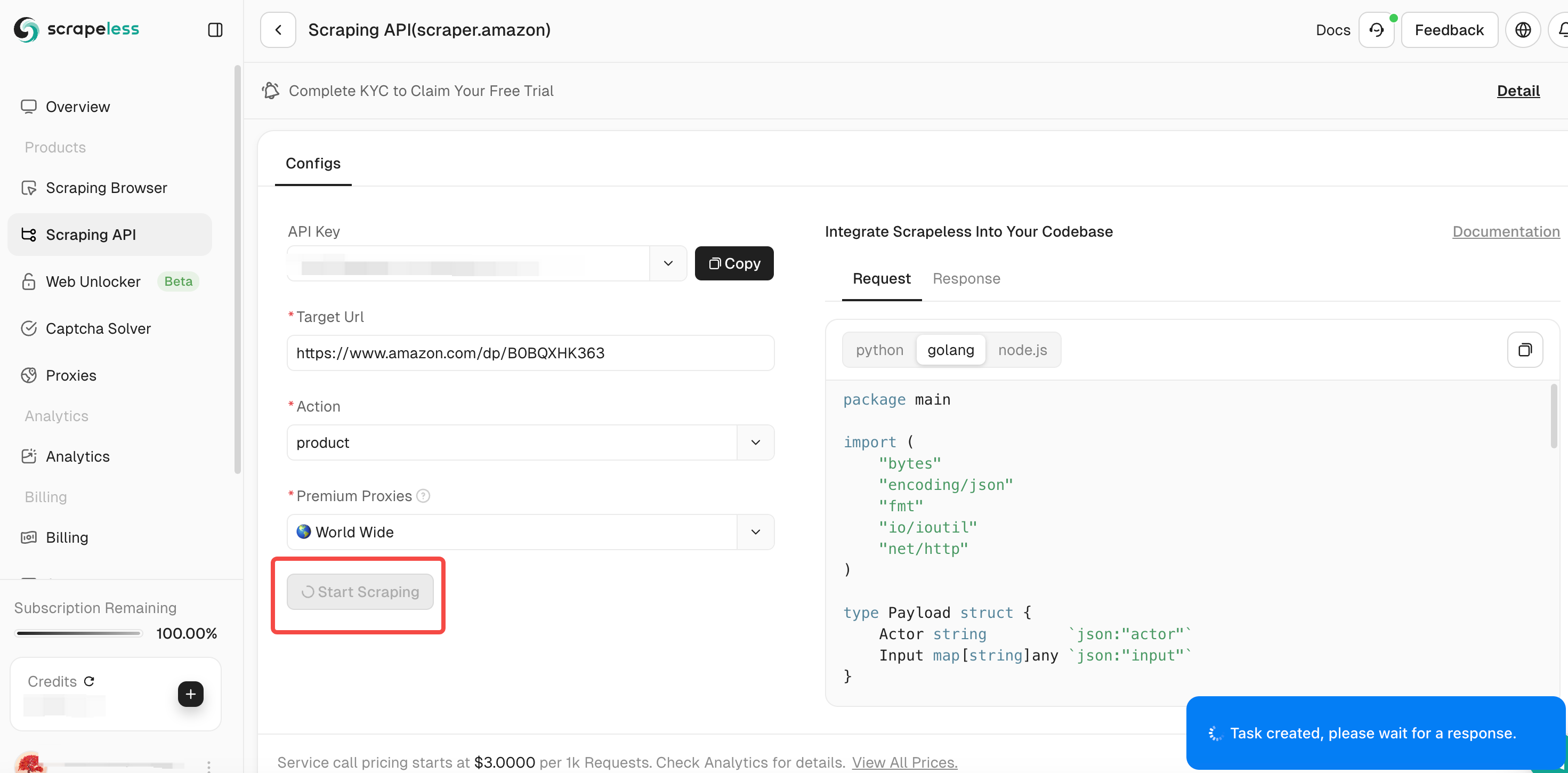
**ステップ5。**クローリングが完了したら、右側のパネルでクローリングされたデータを表示できます。結果は、分析しやすい明確な形式で表示されます。
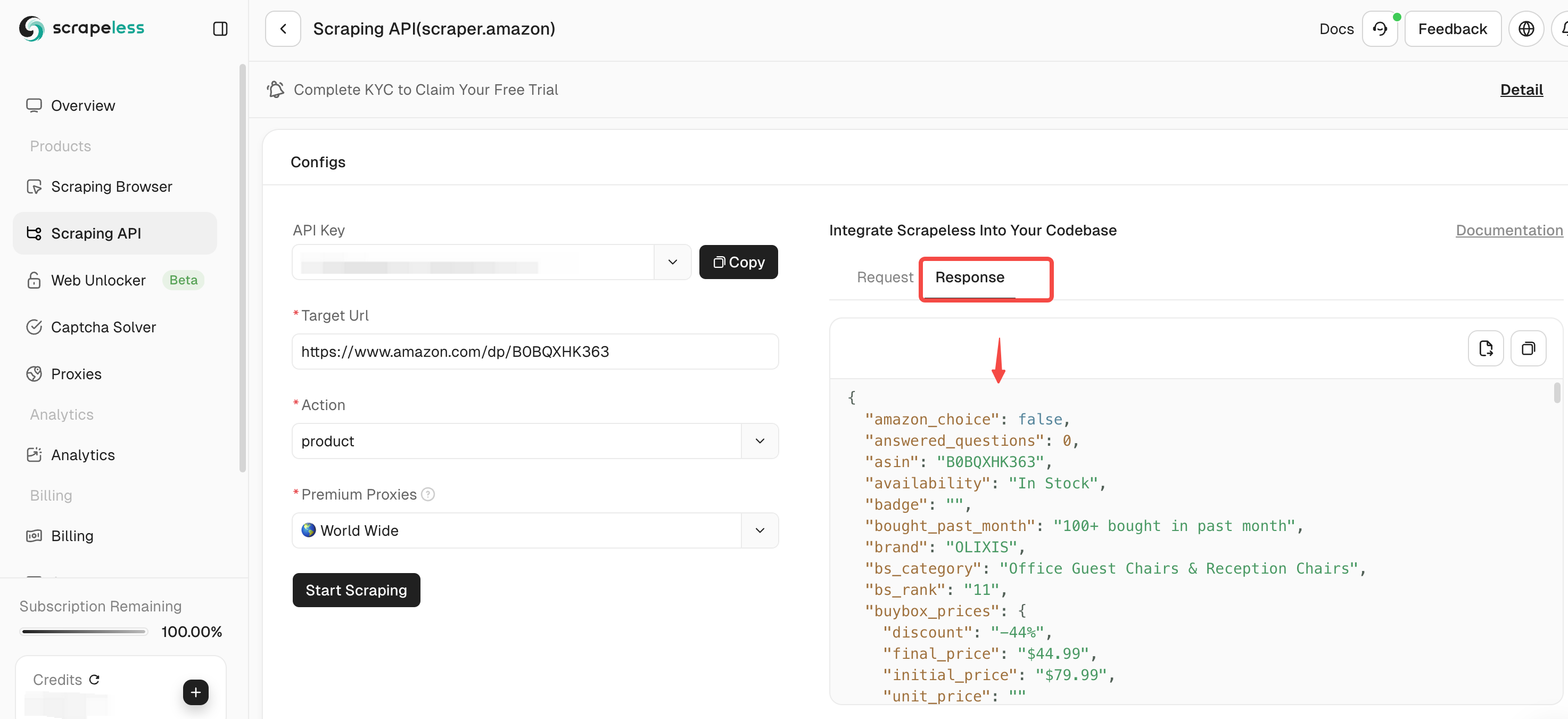
他の製品をクローリングする必要がある場合は、「続行」をクリックして新しいAmazonリンクを入力し、上記の手順を繰り返します。
Amazon Scraper APIを使用したAmazon製品ASINデータのスクレイピング方法:
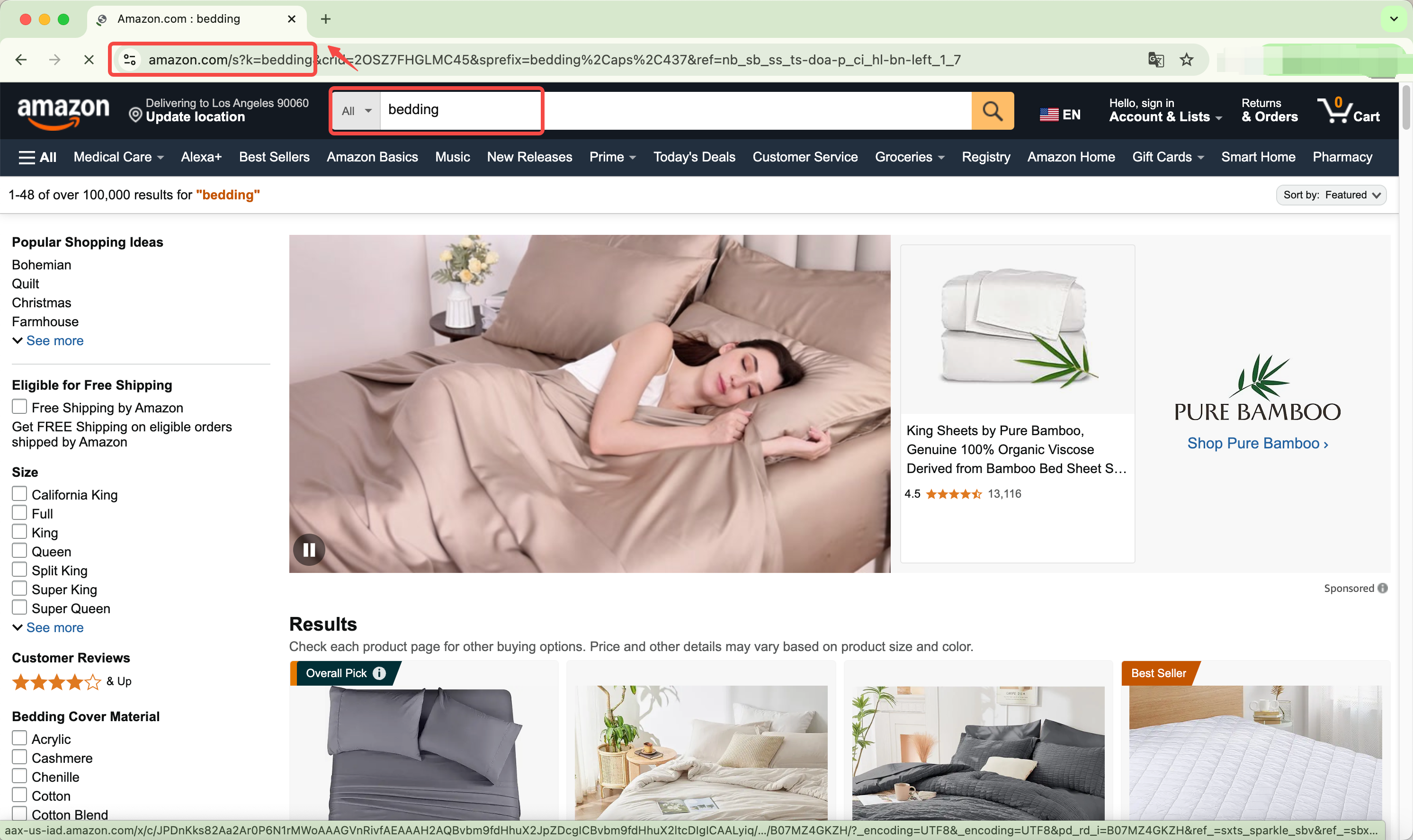
ステップ1:URLの作成
Amazonの検索ボックスにキーワードを入力し、対応するURLをコピーします。「寝具」をURLとしてリストしています。https://www.amazon.com/s?k=bedding
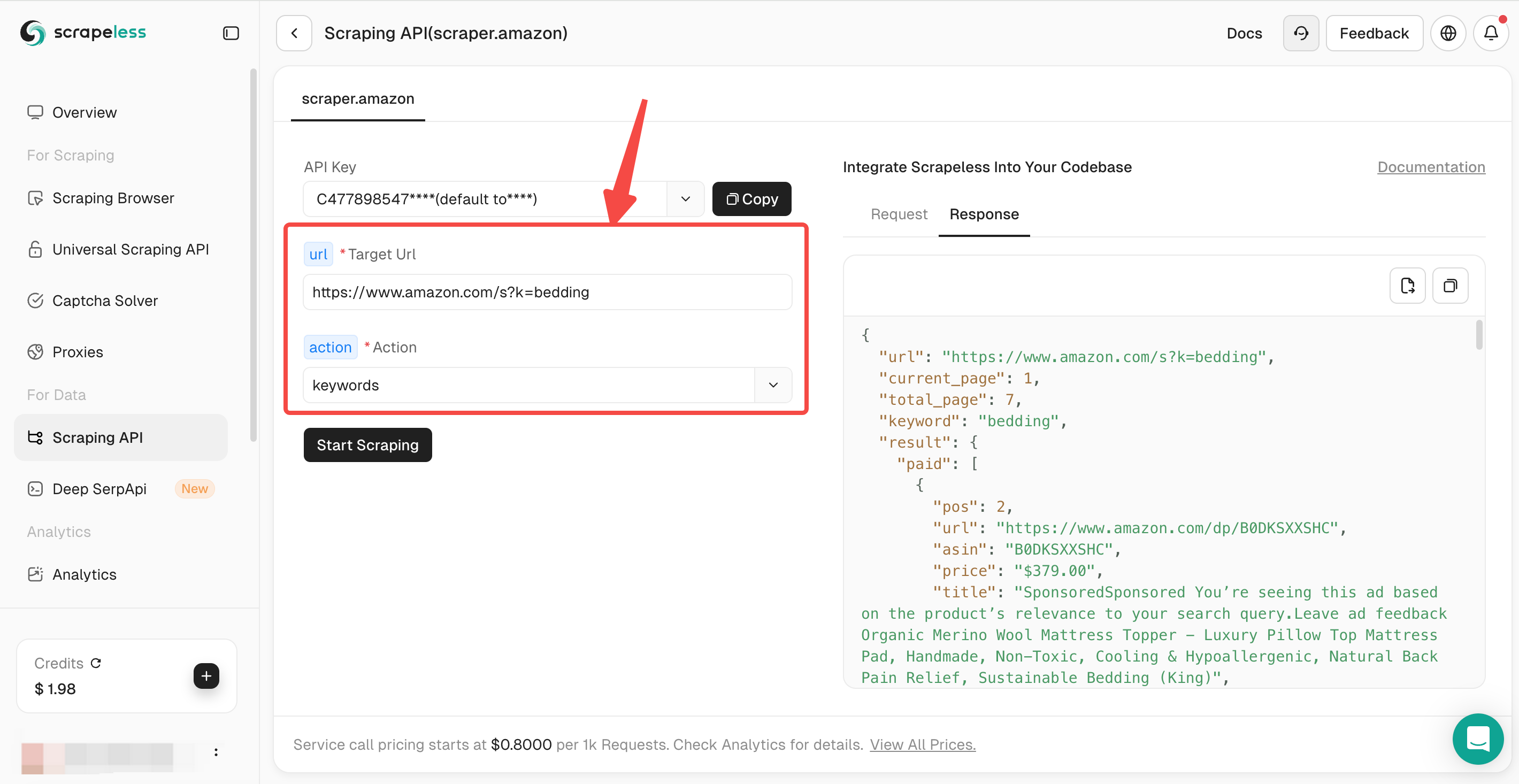
ステップ2:クローリングパラメータの設定
作成したURLをScrapeless AmazonスクレイピングAPIにコピーし、キーワードを選択します。
ステップ3:スクレイピング開始
「スクレイピング開始」をクリックします。クロール結果は右側のダッシュボードに表示されます。
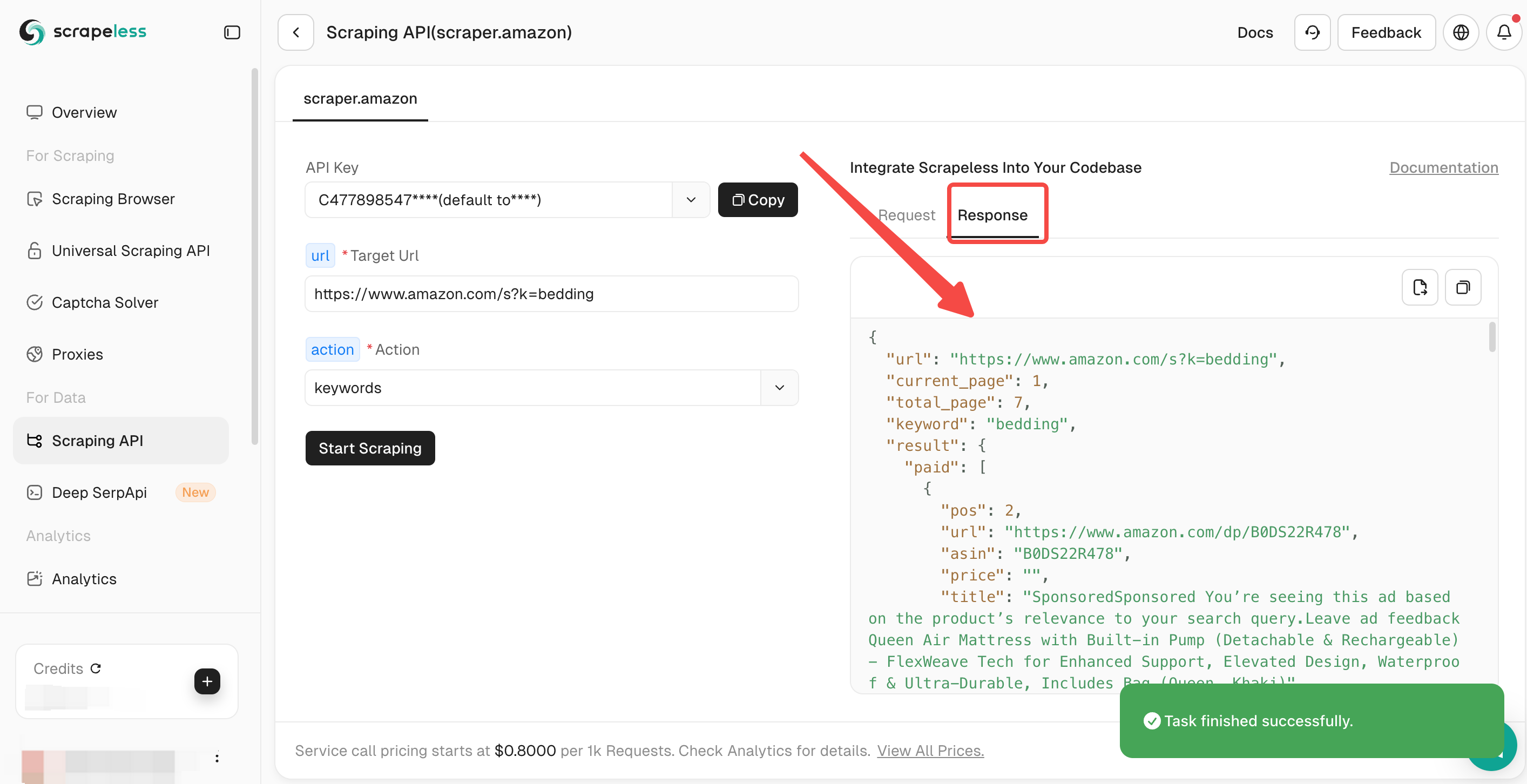
いくつかの検索結果コードを以下に示します。
"url": "https://www.amazon.com/s?k=bedding",
"current_page": 1,
"total_page": 7,
"keyword": "bedding",
"result": {
"paid": [
{
"pos": 2,
"url": "https://www.amazon.com/dp/B0DS22R478",
"asin": "B0DS22R478",
"price": "",
"title": "SponsoredSponsored あなたはこの広告を検索クエリに関連する製品に基づいて見ています。広告フィードバックを残す クイーンエアマットレス内蔵ポンプ付き(取り外し可能&充電式)-強化サポートのためのフレックスウィーブテクノロジー、高度なデザイン、防水&超耐久性、バッグ付き(クイーン、カーキ)",
"rating": "",
"is_prime": false,
"url_image": "/sspa/click?ie=UTF8&spc=MTo5MzMyMzAwNTI2MjQzOTg6MTc0MjA5NzkwMzpzcF9hdGY6MzAwNjcxMjQ0OTI2ODAyOjowOjo&url=%2FLunaDream-Mattress-Built-Detachable-Rechargeable%2Fdp%2FB0DS22R478%2Fref%3Dsr_1_1_sspa%3Fdib%3DeyJ2IjoiMSJ9.kQJ5rAORw8oqha9VD8o8yW0gjsD58K6tZK0xcTj0AWrml0pG3A8RQySnBFxZh4rD4WjAWF5iALvRwV7hdxXVeCUIjDOOUeeEj_JI5T4YZR2XjrlG0i-l63cHd3JrsDC_xzvwvHRNM9CybOL9WXa_MiqHie_2jNpf2y4CrgFBeI6k8ZLiLcSwP4UKXQnT_zf9zJdCWdUMVJG5Dq65K-zq80Rxrz_bX0WYA_hNzTi3w1eAkXClZ5rmho1yX2qTkiOV7HhZXKWWioD6O4eEI6X-KUDUKRXthez3xwu88aOWUng.-ZkU0sCs2lJJKIyHERUSqfIoWc4eO9qjfh9yF1UfGx8%26dib_tag%3Dse%26keywords%3Dbedding%26qid%3D1742097903%26sr%3D8-1-spons%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9hdGY%26psc%3D1",
"best_seller": false,
"price_upper": "",
"is_sponsored": true,
"manufacturer": "",
"pricing_count": 1,
"reviews_count": 0,
"price_strikethrough": "",
"shipping_information": ""
},
{
"pos": 3,
"url": "https://www.amazon.com/dp/B0CPPLH6RL",
"asin": "B0CPPLH6RL",
"price": "$279.99",
"title": "SponsoredSponsored この広告は、製品の検索クエリとの関連性に基づいて表示されています。",このスクレイピングされた結果は、「寝具」というキーワードのAmazon検索SERP(検索エンジン結果ページ)の部分的な分析です。次の情報が含まれています。
基本的な検索情報
- url:検索結果ページのURL(https://www.amazon.com/s?k=bedding)。
- current_page:検索結果の現在のページ番号(1)。
- total_page:検索結果の総ページ数(7)。
- keyword:使用された検索キーワード(寝具)。
スポンサー付き(有料)製品情報
-
データには、「result」:{「paid」: [...] }に格納されている、いくつかのスポンサー付き製品(広告掲載)に関する詳細が含まれています。主な詳細は次のとおりです。
-
pos(位置):2(検索結果におけるこのスポンサー付き製品の順位)。
-
url:Amazon製品ページのURL(https://www.amazon.com/dp/B0DS22R478)。
-
asin(Amazon標準識別番号):B0DS22R478(製品の一意の識別子)。
.....
Scrapeless AmazonスクレイピングAPIパラメータ
| パラメータ | 必須 | 説明 |
|---|---|---|
| action | true | このパラメータは、実行する検索の種類を定義します。可能なタイプには、product、seller、keywordsなどがあります。 |
| url | false | このパラメータは、製品または販売者のURL情報です。タイプがproductの場合、このパラメータは必須です。 |
| page | false | このパラメータは、検索された製品のページ番号を定義します。タイプがkeywordsの場合に使用できます。 |
| domain | false | このパラメータは、URLのドメイン名を定義します。例: |
| zip_code | false | このパラメータは郵便番号です。入力すると、関連する配送情報が取得できます。 |
| return_HTML | false | このパラメータは、元のHTMLページを返すかどうかを定義します。Trueは返すことを意味し、falseは返さないことを意味します。 |
Amazonから構造化データを迅速にスクレイピングしたいですか?Scrapeless Amazon APIは、プロキシのローテーションからヘッドレスブラウザまで、すべての複雑さを処理し、迅速かつシームレスなデータ抽出を保証します。ログインして今すぐダッシュボードにアクセスし、無料トライアルをすぐに獲得しましょう!
プロジェクトへのScrapelessの統合方法
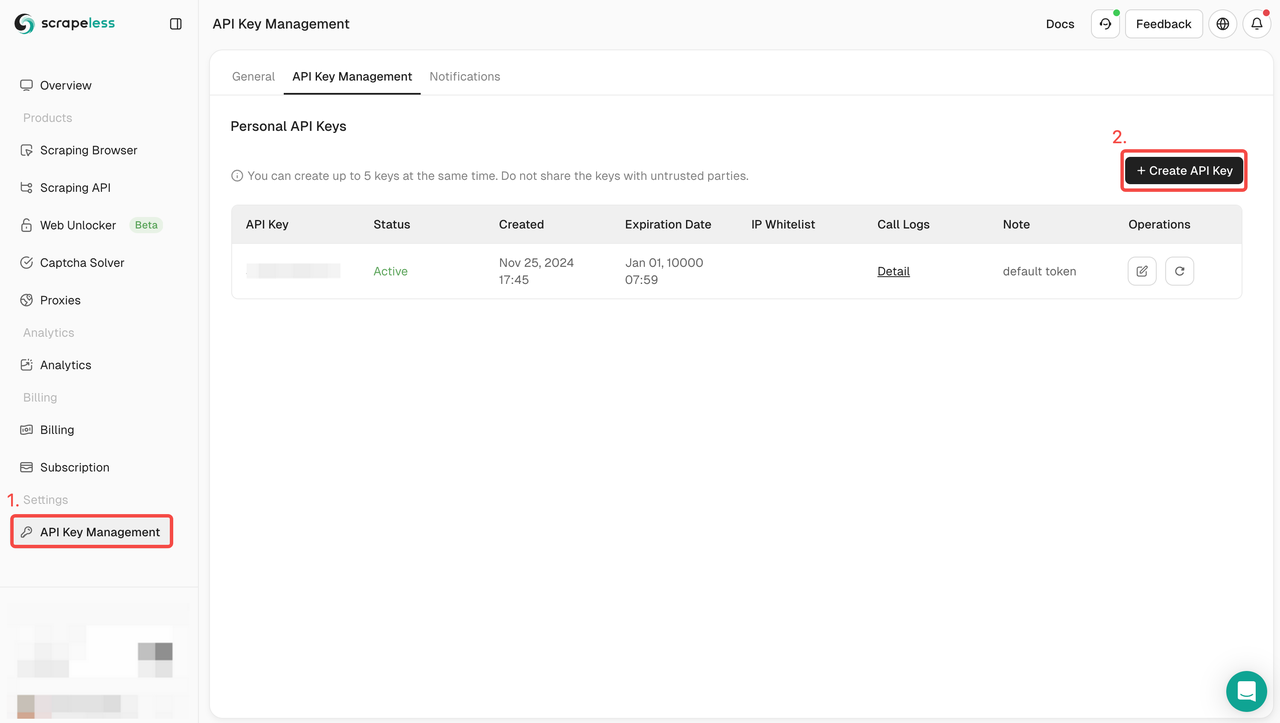
ステップ1:Scrapeless APIキーを取得する
- Scrapelessにサインアップする
- APIキー管理を選択する
- Scrapeless APIキーを作成するには、「APIキーの作成」をクリックします。
ScrapelessはシームレスなWebスクレイピングを保証します。
🎁 Discordに参加して、無料トライアルを今すぐ獲得しましょう!
ステップ2:次のコードをプロジェクトに統合する
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUTR API KEY"
headers = {
"x-api-token": token
}
input_data = {
"action": "keywords",
"url": "https://www.amazon.com/s?k=bedding"
}
payload = Payload("scraper.amazon", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()データスクレイピングで発生する一般的な問題の回避方法
問題1:短時間で多くのリクエストが行われると、Webサイトは同じIPアドレスからのリクエストをブロックまたはスロットルすることが多く、データスクレイピングを防ぎます。
- 解決策:ローテーションプロキシまたはプロキシプールを使用して、リクエストを異なるIPアドレスに分散します。これにより、レート制限に達したり、ブロックされたりするのを回避できます。
問題2:Amazonを含む多くのWebサイトは、自動化されたスクレイピングの試行を検出するために、CAPTCHAまたはその他のボット対策メカニズムを使用しており、データの抽出を困難にしています。
- 解決策:CAPTCHAをバイパスするには、ヘッドレスブラウザまたはCAPTCHA解決サービスを使用して、自動的にCAPTCHAを完了します。ScrapelessスクレイパーAPIは、CAPTCHAを自動的に解決するか、機械学習アルゴリズムを使用して検出を回避することで、この問題を解決できます。
Amazon Scraper APIに関するFAQ
Amazonはデータスクレイピングを許可していますか?
Amazonの利用規約では、データ収集のためにWebサイトへの自動アクセスを許可していますが、いくつかの要件があります。
- 公開データ:Amazonは、製品情報、価格、レビューなど、サイトにアクセスした誰でもアクセスできるデータのスクレイピングを許可しています。
- 個人使用または研究:Amazonは、個人使用または研究目的のスクレイピングを許可しています。
Amazonから価格をスクレイピングできますか?
はい、Amazonから製品情報を取得できます。これには以下が含まれます。
- 価格:現在の価格、割引、過去の価格変動。
- 製品タイトル:製品の名前と説明。
- 製品詳細:仕様、機能、技術詳細。
- カスタマーレビューと評価:ユーザーフィードバック、評価、レビューサマリー。
- 在庫状況:在庫状況、配送オプション、配送時間。
- 画像:製品画像とサムネイル。
- ASIN(Amazon標準識別番号):製品の一意の識別子。
必要なもの:
Sheinデータのスクレイピング方法
最高のGoogleトレンドスクレイピングAPI-Googleトレンドからデータを簡単にスクレイピング
検索エンジンスクレイピングのためのトップ6 SERP API
まとめ
ここでは、専門的なAPIサービスプロバイダーであるScrapeless[Webスクレイピングツールキット]が、複雑な技術設定やデータ抽出の問題を心配することなく、Amazon Scraper APIの使い方をすばやく理解し、必要なデータを簡単に取得するための詳細なガイドを提供します。
Amazonからデータを迅速に抽出したい開発者や企業にとって、Amazon Scraper APIは効率的で使いやすいソリューションです。クローリングプロセスを簡素化し、多くの時間と労力を費やすことなく正確なデータを取得できます。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


