
AI駆動のブログライター、ScrapelessおよびPineconeデータベースを使用
Senior Web Scraping Engineer
あなたは経験豊富なコンテンツクリエイターである必要があります。スタートアップチームとして、製品の日々更新されるコンテンツは非常に豊富です。ウェブサイトのトラフィックを迅速に増やすために大量の誘導ブログをレイアウトするだけでなく、製品の更新プロモーションに関するブログを週に2~3本準備する必要があります。
支払い広告の入札予算を増やして、より高い表示位置とさらなる露出を得るために多くの資金を費やすことと比較して、コンテンツマーケティングには依然として代替不可能な利点があります。内容の幅広さ、顧客獲得テストの低コスト、高出力効率、比較的少ないエネルギー投資、豊富なフィールド経験の知識ベースなどです。
しかし、大量のコンテンツマーケティングの結果はどうなっているのでしょうか?
残念ながら、たくさんの記事がGoogle検索の10ページ目に深く埋もれています。
「低トラフィック」の記事の強い影響をできるだけ避ける良い方法はありますか?トップパフォーマンスのブログの知識をクローンし、新鮮なコンテンツを大量に生成する自己更新型のSEOライターを作りたいと思ったことはありませんか?
このガイドでは、n8n、Scrapeless、Gemini(必要に応じてClaude/OpenRouterなど他のものも選択可能)、Pineconeを使用して、完全に自動化されたSEOコンテンツ生成ワークフローの構築方法を説明します。このワークフローは、リトリーバル拡張生成(RAG)システムを使用して、既存の高トラフィックブログに基づいてコンテンツを収集、保存、生成します。
YouTubeチュートリアル: https://www.youtube.com/watch?v=MmitAOjyrT4
このワークフローの目的は何ですか?
このワークフローは4つのステップで構成されます:
- パート1:ScrapelessのCrawlを呼び出して対象ウェブサイトのすべてのサブページをクロールし、各ページの全コンテンツを詳細に分析するためにScrapeを使用します。
- パート2:クロールしたデータをPinecone Vector Storeに保存します。
- パート3:ScrapelessのGoogle Searchノードを使用して、対象トピックまたはキーワードの価値を完全に分析します。
- パート4:Geminiに指示を伝え、準備されたデータベースからRAGを通じて文脈コンテンツを統合し、ターゲットブログを生成するか、質問に回答します。
もしScrapelessを聞いたことがないなら、それはAIエージェント、オートメーションワークフロー、ウェブクロールを支えるためのインフラ企業です。Scrapelessは、開発者や企業が効率的にインテリジェントで自律的なシステムを作成するための基本的な構成要素を提供します。
Scrapelessは、ブラウザーレベルのツールとプロトコルベースのAPIを提供し、ヘッドレスクラウドブラウザ、Deep SERP API、Universal Crawling APIsなど、AIエージェントやオートメーションプラットフォームにとって統一的でモジュラーな基盤として機能します。
AIアプリケーションのために本当に構築されています。なぜなら、AIモデルはしばしば最新の情報、つまり現在の出来事や新しい技術に追いついていないからです。
n8nのほか、APIを通じて呼び出すこともでき、Makeなどの主流プラットフォームにノードがあります:
公式ウェブサイトでも直接使用できます。
n8nでScrapelessを使用するには:
- 設定 > コミュニティノードにアクセス
- n8n-nodes-scrapelessを検索してインストールします
まず、n8nにScrapelessのコミュニティノードをインストールする必要があります:
認証接続
Scrapeless APIキー
このチュートリアルではScrapelessサービスを使用します。APIキーを登録して取得していることを確認してください。
- Scrapelessのウェブサイトにサインアップして、APIキーを取得し、無料トライアルを請求してください。
- 次に、Scrapelessノードを開き、認証セクションにAPIキーを貼り付けて接続します。
PineconeインデックスとAPIキー
データをクロールした後、それを統合して処理し、すべてのデータをPineconeデータベースに集めます。PineconeのAPIキーとインデックスを事前に準備する必要があります。
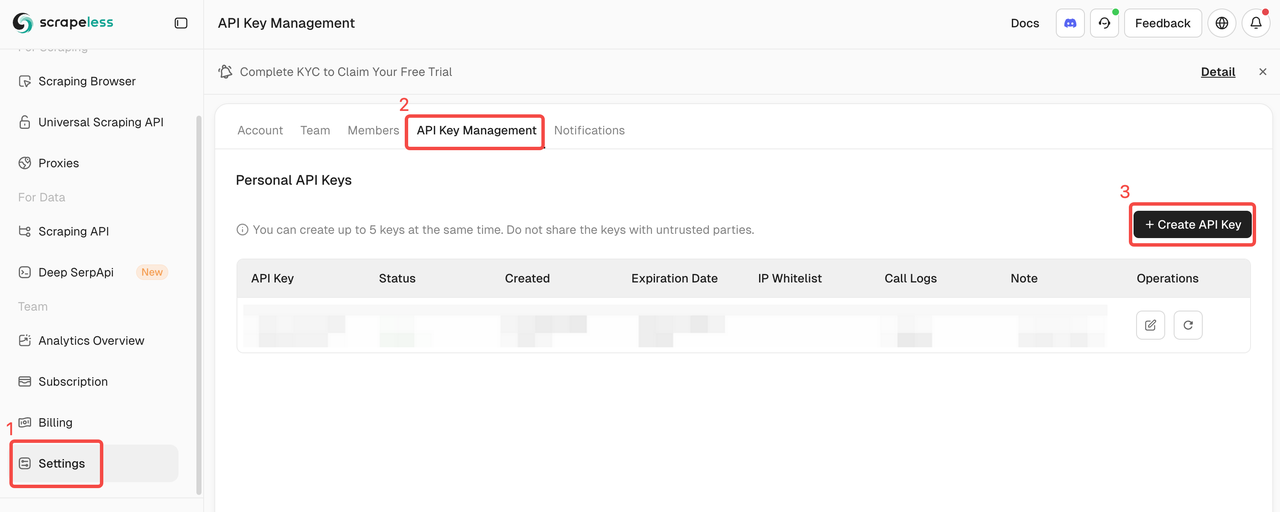
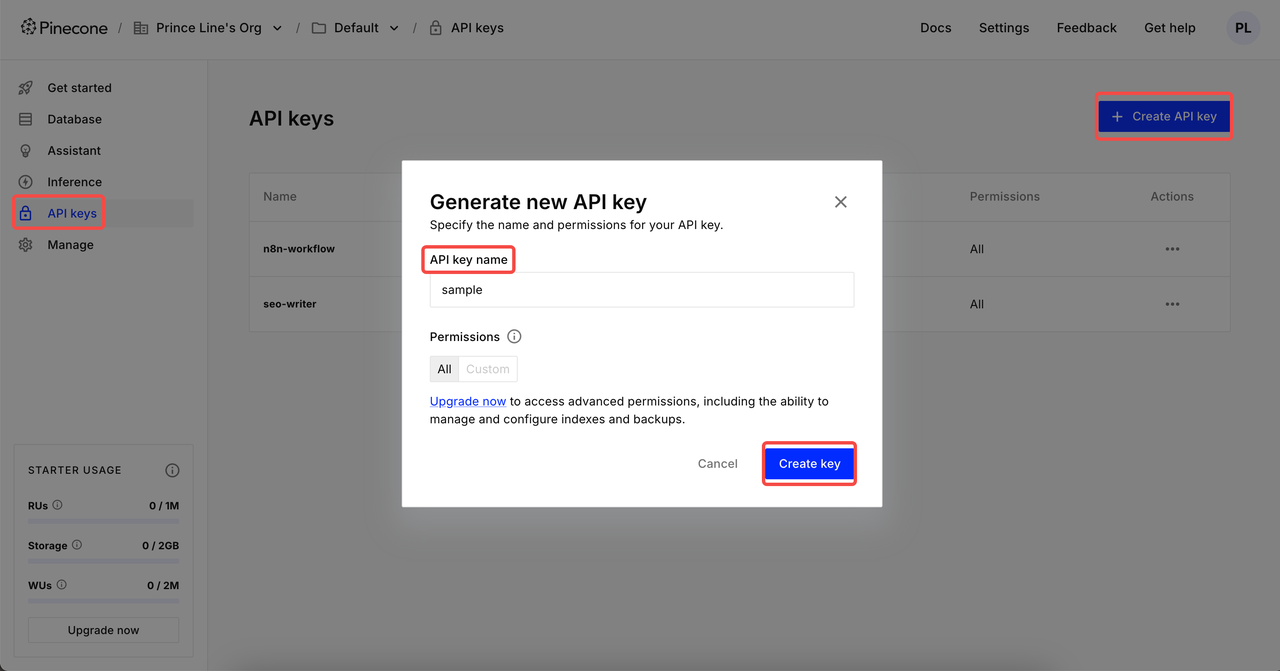
APIキーの作成
ログイン後、API Keysをクリック → Create API keyをクリック → APIキー名を補完 → Create key。これで、n8nで設定できます。
⚠️ 作成が完了したら、APIキーをコピーして保存してください。データのセキュリティのため、Pineconeは作成したAPIキーを再表示しません。
インデックスの作成
インデックスをクリックして作成ページに入ります。インデックス名を設定 → 構成のモデルを選択 → 適切な次元を設定 → インデックスを作成。
一般的な2つの次元設定:
- Google Gemini Embedding-001 → 768次元
- OpenAIのtext-embedding-3-small → 1536次元
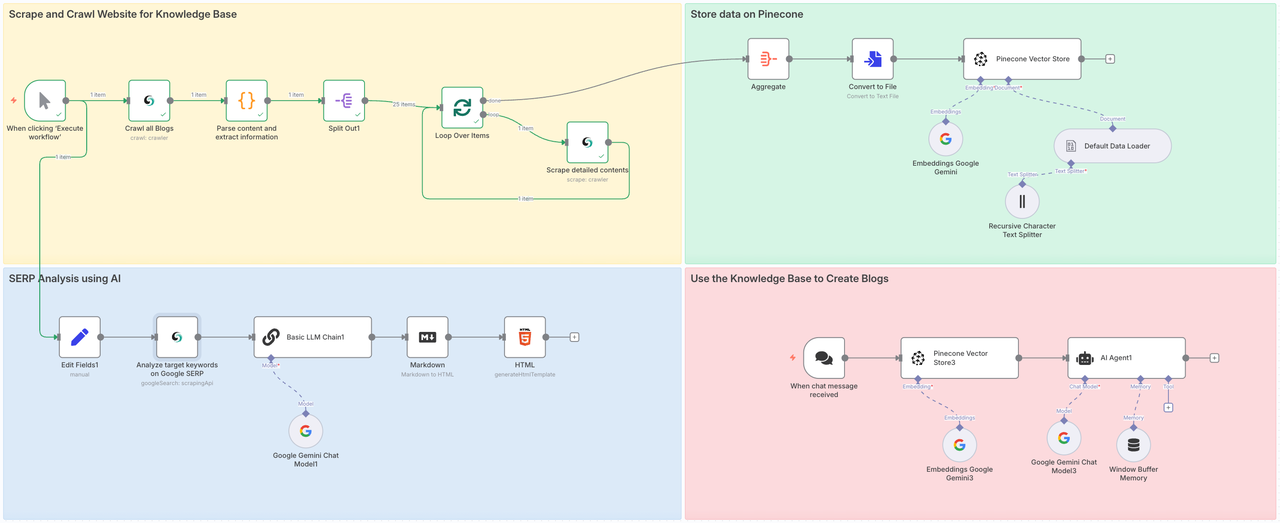
フェーズ1:ナレッジベースのためにウェブサイトをスクレイピングおよびクロール
最初の段階は、すべてのブログコンテンツを直接集約することです。広範囲からコンテンツをクロールすることで、AIエージェントがすべての分野からデータソースを取得し、最終的な出力記事の質を確保します。
- Scrapelessノードは、記事ページをクロールしてすべてのブログ投稿URLを収集します。
- その後、毎URLをループし、ブログコンテンツをスクレイピングし、データを整理します。
- 各ブログ投稿はAIモデルを使用して埋め込まれ、Pineconeに保存されます。
- この場合、ほんの数分で25件のブログ投稿をスクレイピングしました — 何も手を動かさずに。
Scrapelessクロールノード
このノードは、ターゲットブログウェブサイトのすべてのコンテンツをクロールし、メタデータ、サブページのコンテンツを含むMarkdown形式でエクスポートするために使用されます。これは手動コーディングでは迅速に実現できない大規模なコンテンツクロールです。
設定:
- Scrapeless APIキーを接続
- リソース:
Crawler - 操作:
Crawl - 対象のスクレイピングウェブサイトを入力します。ここではhttps://www.scrapeless.com/ja/blogを参照として使用します。
コードノード
ブログデータを取得した後、データを解析し、必要な構造化情報を抽出する必要があります。
以下は私が使用したコードです。直接参照できます:
JavaScript
return items.map(item => {
const md = $input.first().json['0'].markdown;
if (typeof md !== 'string') {
console.warn('Markdownコンテンツが文字列ではありません:', md);
return {
json: {
title: '',
mainContent: '',
extractedLinks: [],
error: 'Markdownコンテンツが文字列ではありません'
}
};
}
const articleTitleMatch = md.match(/^#\s*(.*)/m);
const title = articleTitleMatch ? articleTitleMatch[1].trim() : 'タイトルが見つかりませんでした';
let mainContent = md.replace(/^#\s*.*(\r?\n)+/, '').trim();
const extractedLinks = [];
// 否定の先読み `(?!#)` は、基準URLの後に '#' がマッチしないことを保証します、
// より堅牢な方法は、特に '#' の前で停止することです。
const linkRegex = /\[([^\]]+)\]\((https?:\/\/[^\s#)]+)\)/g;
let match;
while ((match = linkRegex.exec(mainContent))) {
extractedLinks.push({
text: match[1].trim(),
url: match[2].trim(),
});
}
return {
json: {
title,
mainContent,
extractedLinks,
},
};
});ノード: 分割
分割ノードは、清掃されたデータを統合し、必要なURLとテキストコンテンツを抽出するのに役立ちます。
アイテムをループ + Scrapelessスクレイプ
アイテムをループ
ループオーバータイムノードを使用して、Scrapelessのスクレイプと共にクロールタスクを繰り返し実行し、以前に取得した全アイテムを分析します。
Scrapelessスクレイプ
スクレイプノードは、以前に取得したURL内のすべてのコンテンツをクロールするために使用されます。このようにして、各URLを深く分析できます。Markdown形式が返され、メタデータやその他の情報が統合されます。
フェーズ2. Pineconeにデータを保存する
Scrapelessブログページのすべてのコンテンツを正常に抽出しました。次に、この情報を保存するためにPineconeベクターストアにアクセスする必要があります。
ノード: 集計
ナレッジベースにデータを便利に保存するために、すべてのコンテンツを統合するために集計ノードを使用する必要があります。
- 集計:
すべてのアイテムデータ(単一リストに) - 出力フィールドに入れる:
data - 含める:
すべてのフィールド
ノード: ファイルに変換
素晴らしい!すべてのデータが正常に統合されました。次に、取得したデータをPineconeが直接読み取れるテキスト形式に変換する必要があります。これを行うには、「ファイルに変換」を追加します。
ノード: Pineconeベクターストア
次に、ナレッジベースを設定する必要があります。使用されるノードは次のとおりです:
PineconeベクターストアGoogle Geminiデフォルトデータローダー再帰的文字テキストスプリッター
上記の4つのノードが再帰的に統合して取得したデータをクロールします。その後、すべてがPineconeナレッジベースに統合されます。
フェーズ3. AIを使用したSERP分析
コンテンツの順位付けを確実に行うために、ライブSERP分析を実施します:
- Scrapeless Deep SerpApiを使用して、選択したキーワードの検索結果を取得します
- キーワードと検索意図(例:スクレイピング、Googleトレンド、API)を入力します
- 結果はLLMによって分析され、HTMLレポートに要約されます
ノード: フィールドを編集
ナレッジベースの準備が整いました!次は、ターゲットキーワードを決定する時間です。コンテンツボックスにターゲットキーワードを入力し、意図を追加します。
ノード: Google検索
Google検索ノードはScrapelessのDeep SerpApiを呼び出してターゲットキーワードを取得します。
ノード: LLMチェーン
Geminiを使ってLLMチェーンを構築することで、前のステップで取得したデータを分析し、LLMに使用する参照入力と意図を説明することができ、LLMがよりニーズに合ったフィードバックを生成できるようになります。
ノード: Markdown
LLMは通常Markdown形式でエクスポートされるため、ユーザーとして最も明確に必要なデータを直接取得することができません。したがって、LLMが返した結果をHTMLに変換するためにMarkdownノードを追加してください。
ノード: HTML
次に、HTMLノードを使用して結果を標準化する必要があります - ブログ/レポート形式を使用して関連コンテンツを直感的に表示します。
- 操作:
HTMLテンプレートを生成
以下のコードが必要です:
XML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>レポートサマリー</title>
<link href="https://fonts.googleapis.com/css2?family=Inter:wght@400;600;700&display=swap" rel="stylesheet">
<style>
body {
margin: 0;
padding: 0;
font-family: 'Inter', sans-serif;
background: #f4f6f8;
display: flex;
align-items: center;
justify-content: center;
min-height: 100vh;
}
.container {
background-color: #ffffff;
max-width: 600px;
width: 90%;
padding: 32px;
border-radius: 16px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
text-align: center;
}
h1 {
color: #ff6d5a;
font-size: 28px;
font-weight: 700;
margin-bottom: 12px;
}
h2 {
color: #606770;
font-size: 20px;
font-weight: 600;
margin-bottom: 24px;
}
.content {
color: #333;
font-size: 16px;
line-height: 1.6;
white-space: pre-wrap;
}
@media (max-width: 480px) {
.container {
padding: 20px;
}
h1 {
font-size: 24px;
}
h2 {
font-size: 18px;
}
}
</style>
</head>
<body>
<div class="container">
<h1>データレポート</h1>
<h2>自動化によって処理されました</h2>
<div class="content">{{ $json.data }}</div>
</div>
<script>
console.log("こんにちは世界!");
</script>
</body>
</html>このレポートには以下が含まれます:
- 上位のキーワードとロングテールフレーズ
- ユーザー検索意図のトレンド
- 提案されたブログタイトルと角度
- キーワードのクラスタリング
フェーズ4. AI + RAGを使用したブログの生成
知識を収集・保存してキーワードを調査したので、ブログを生成する時間です。
- SERPレポートから得た洞察を用いてプロンプトを構築します
- AIエージェント(例:Claude、Gemini、OpenRouter)を呼び出します
- モデルがPineconeから関連するコンテキストを取得し、完全なブログ投稿を執筆します
一般的なAIの出力とは異なり、ここでの結果はScrapelessのオリジナルコンテンツからの特定のアイデア、フレーズ、トーンを含んでいます — これはRAGによって可能になりました。
終わりの思考
このエンドツーエンドのSEOコンテンツエンジンは、n8n + Scrapeless + ベクトルデータベース + LLMsの力を示しています。
あなたは:
- Scrapelessブログページを他のブログに置き換えることができます
- Pineconeを他のベクトルストアに交換できます
- OpenAI、Claude、またはGeminiをライティングエンジンとして使用できます
- カスタムパブリッシングパイプラインを構築できます(例:CMSやNotionへの自動投稿)
👉 今日はScrapelessコミュニティノードをインストールして、スケールでブログを生成し始めましょう — コーディングは不要です。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。


