
How to Scrape Lazada Product Data Using Python?
Specialist in Anti-Bot Strategies
What Is Lazada Product Scraping?
Lazada is an online marketplace where different merchants sell goods, and scraping this data is beneficial for various applications, including price monitoring, market research, inventory management, and competitive analysis.
Lazada offers various features such as secure payment options, customer reviews, and a delivery system that facilitates customer purchases and door-to-door delivery.
Lazada web scraping is the process of obtaining data from the Lazada website using automated tools or scripts.
Scraping is the practice of obtaining specific information from Lazada web pages, such as product details (such as name, price, description, and photos), seller information, user reviews, and ratings. However, it is important to remember that online scraping can be subject to legal issues, and some websites’ terms of service restrict scraping their data without permission.
Why do you need Lazada web crawling?
- Price monitoring and comparison. Crawl product data on Lazada can help businesses or consumers track price fluctuations, analyze price trends of similar products, and find the best time to buy.
- Market analysis. Businesses can obtain market dynamics such as best-selling products, user reviews, product rankings, etc. by crawling Lazada's data. This helps optimize sales strategies, predict market demand, and develop more accurate marketing plans.
- Product information collection. For e-commerce companies or agents who need to manage large-scale product catalogs, crawling Lazada's product data (such as product name, description, price, inventory information, etc.) can speed up entry and update product data and improve efficiency.
- Competitor analysis. By crawling competitors' product lists, pricing strategies, and promotions on Lazada, companies can gain insight into their competitors' market positioning and develop more competitive business plans.
- Comment and rating analysis. User comments and ratings are important bases for consumer decision-making. By crawling this information, companies can analyze consumer feedback on products, thereby improving products or services and enhancing user experience.
- Build a product price comparison platform. Some startups or technology platforms need to crawl Lazada's data to build price comparison websites or applications, allowing users to easily compare prices and discount information on different platforms.
- Automated inventory management. For merchants, crawling Lazada's data can automatically check whether the inventory or price of certain products has changed, so as to adjust their product strategies in time.
- Explore business opportunities. Crawl Lazada's hot-selling products and underdeveloped product areas to help discover potential business opportunities and open up new business directions.
Why choose Python language to crawl Lazada data?
- Powerful crawler ecosystem
Python has a wealth of crawler-related libraries and frameworks, such as:
requests: simple and easy to use, suitable for sending HTTP requests to obtain static web page data.BeautifulSoup: lightweight HTML parsing library, easy to extract web page content.Scrapy: powerful crawler framework, supporting efficient distributed crawling and data management.Selenium: used to process dynamic web page content, supporting automated browser operations.
These tools can easily adapt to different scenarios of Lazada web crawling.
- Rich data processing capabilities
Python provides powerful data processing and analysis tools, such as:
pandas: efficient data table operation tool, easy to store and process crawled data.csvandjson: built-in support for common data storage formats, easy to output results.NumPyandmatplotlib: powerful tools for statistics and visualization of data.
These tools make it possible to complete everything from data crawling to analysis in one stop.
- Dynamic web page processing capabilities
For Lazada's dynamically loaded content, Python combined with tools such as Selenium and Playwright can simulate real user behavior and bypass JavaScript rendering limitations. In addition, with cloud browser services (such as Browserless), the efficiency of dynamic web page processing can be further improved.
- Highly scalable
Python has good scalability and can be easily integrated with proxy pool management tools (such as proxy-rotator), CAPTCHA solving tools (such as anticaptcha), and data storage services (such as MySQL and MongoDB) to meet large-scale crawling needs.
Is There an Easy Way to Scrape Lazada Product?
Build your Python Lazada scraper always should bypass getting blocked, which seemed to be a headache. Fortunately, here is a easy-to-use method to scrape Lazada product without any difficulty!
Scrapeless - the best Lazada scraping API
Scrapeless is an advanced web scraping platform designed for businesses and developers who need accurate, secure, and scalable data extraction. It provides advanced solutions to simplify the process of collecting data from various sources, including e-commerce platforms such as Lazada and Amazon.
With its powerful design, Scrapeless eliminates the need for you to build and maintain your own scraping tools, and can easily handle complex challenges such as CAPTCHA solving, anti-bot systems, and IP rotation. Whether you want to collect product details, price trends, or customer reviews, Scrapeless provides a reliable and efficient way to meet your data needs.
How to deploy Scrapeless Lazada scraping API?
- Step 1. Log in to Scrapeless.
- Step 2. Click the "Scraping API"
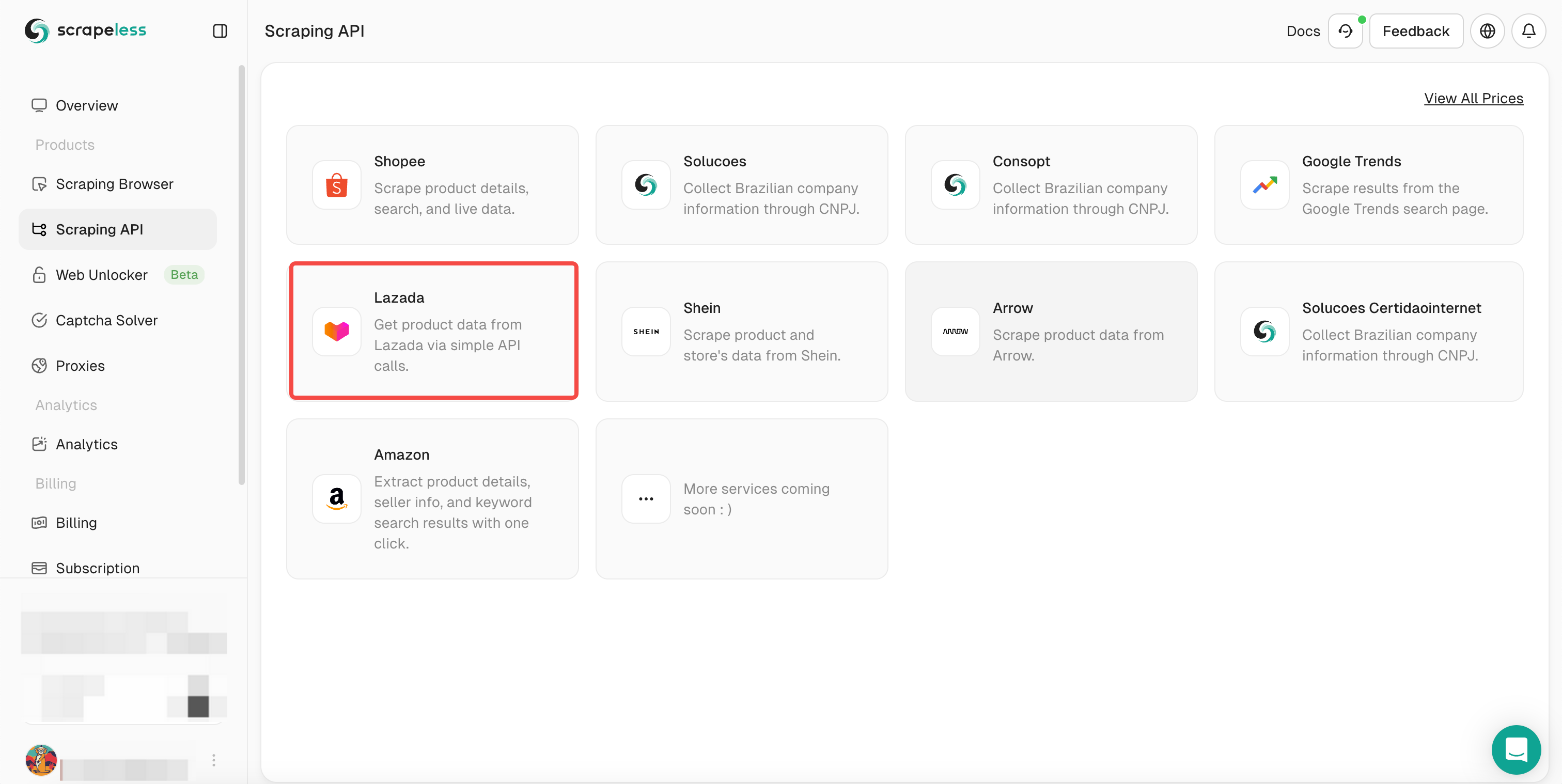
- Step 3. Select Lazada and enter the Lazada scraping page.
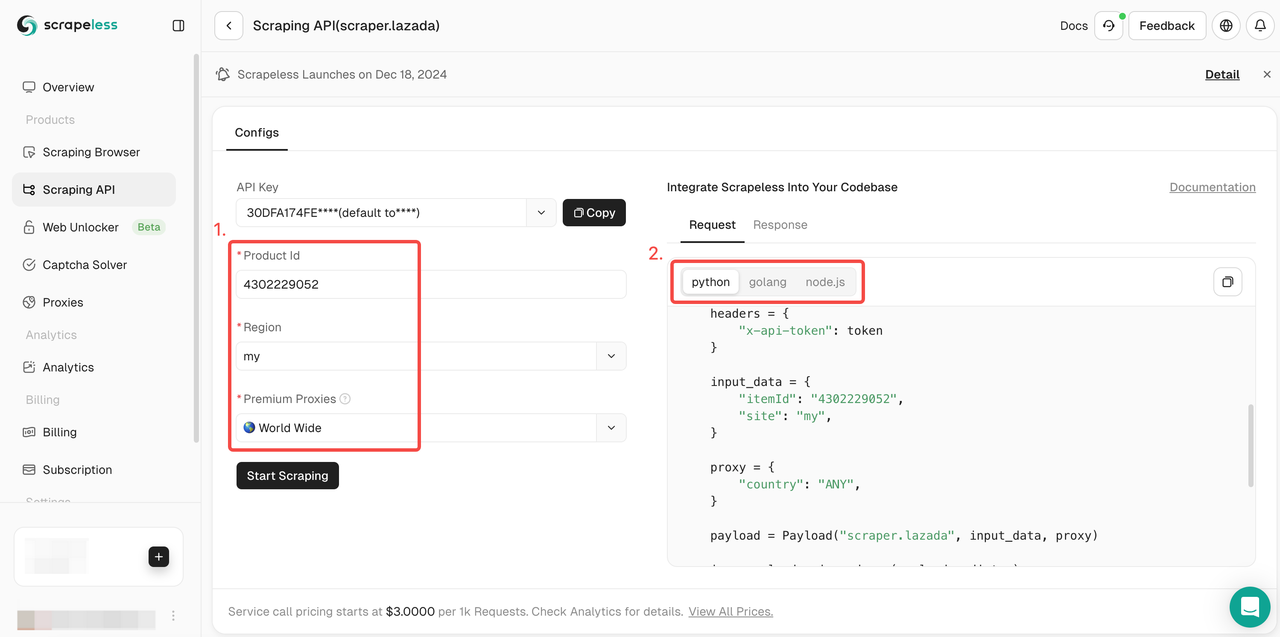
- Step 4. Pull down the Action List and select the data condition settings to be crawled. Then click Start Scraping.
- Step 5. The crawl will be successful in a few seconds. The corresponding structured data will be displayed on the right.
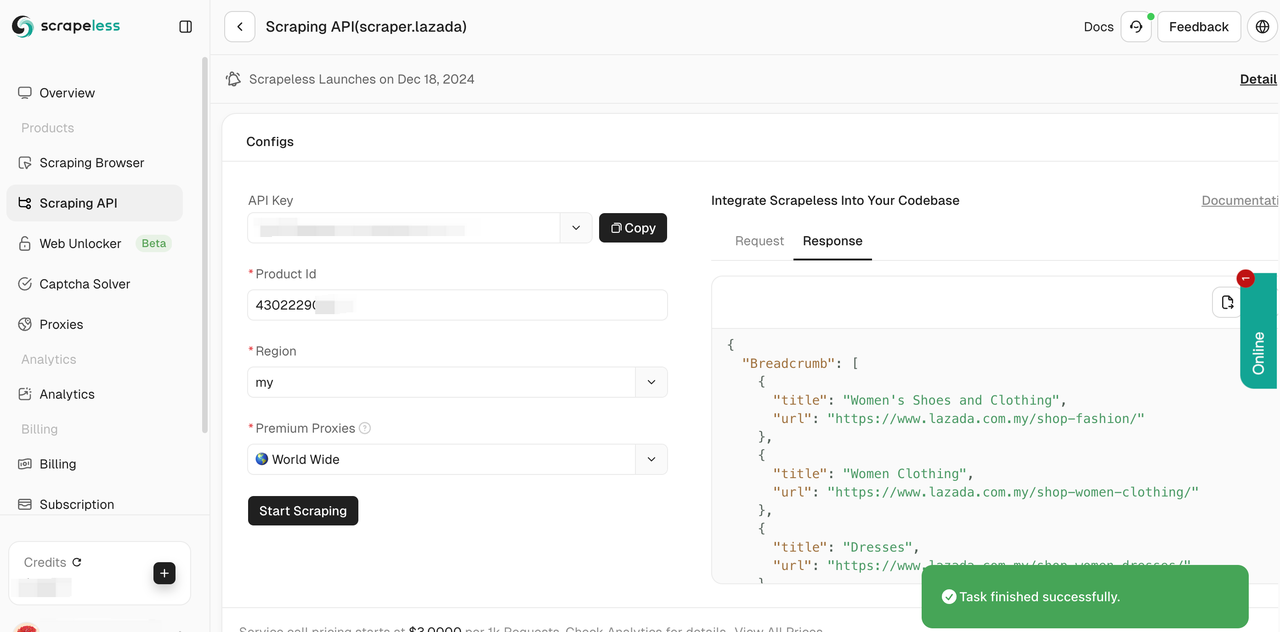
You can also integrate our reference code into your project and deploy your large scaled data scraping. Here we take Python as an example. You can also use Golong and NodeJS in our client.
- Python:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #your API token
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #Input the product ID
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()How to Extract Lazada Product Data using Python?
Step 1: Set Up the Environment
Install the required Python libraries. You’ll primarily need requests for sending HTTP requests and BeautifulSoup for parsing HTML. If the site uses dynamic content, you can use Selenium or cloud browser services like Browserless. Install the necessary libraries using:
Bash
pip install requests beautifulsoup4 seleniumStep 2: Inspect the Lazada Website
Open Lazada in your browser and locate the page you want to scrape (e.g., product listing or search results). Use developer tools (F12) to inspect the page structure and identify the tags and classes for product data like name, price, and links.
Step 3: Send an HTTP Request
For static pages, use the requests library to send a GET request. Include headers like User-Agent to mimic a real browser.
Python
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
url = 'https://www.lazada.com.my/shop-mobiles/'
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
else:
print(f" ")Step 4: Parse the HTML Content
Use BeautifulSoup to extract the product information by identifying the appropriate HTML tags and classes.
Python
products = soup.find_all('div', class_='c16H9d') # Replace with actual class names
for product in products:
name = product.text
print(f"Product Name: {name}")Step 5: Handle Dynamic Content
If the page content is loaded dynamically using JavaScript, use Selenium or a cloud browser to render the full content.
Python
from selenium import webdriver
driver = webdriver.Chrome() # Ensure you have ChromeDriver installed
driver.get('https://www.lazada.com.my/shop-mobiles/')
# Wait for content to load and scrape
elements = driver.find_elements_by_class_name('c16H9d')
for element in elements:
print(f"Product Name: {element.text}")
driver.quit()Step 6: Manage Anti-Bot Measures
Lazada may use techniques to block bots. Use the following strategies to bypass detection:
- Proxy Rotation: Use rotating proxies to avoid IP bans.
- User-Agent Spoofing: Randomize the User-Agent in headers.
- Cloud Browsers: Services like Browserless can help bypass advanced detection systems.
Step 7: Store the Data
Save the scraped data in a CSV file or database for future use.
Python
import csv
with open('lazada_products.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Product Name', 'Price', 'URL']) # Example headers
# Add product details hereThe Bottom Lines
Scraping Lazada product data provides a significant opportunity for businesses in the e-commerce space. The acquired data is a valuable resource for market research, competitor analysis, pricing optimization, and various other data-driven strategic initiatives.
Scrapeless scraping API makes Lazada product scraping simply and efficiently. With CAPTCHA bypassing and IP smart rotation, you can avoid website blocking and easily achieve data scraping.
Sign in and get the Free Trial now!
Further Reading:
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


