
Scrapeless MCP Server Is Officially Live! Build Your Ultimate AI-Web Connector
Expert Network Defense Engineer
Large Language Models (LLMs) are becoming increasingly powerful, but they are inherently limited to handling static content. They cannot open real-time web pages, process JavaScript-rendered content, solve CAPTCHAs, or interact with websites. These limitations severely restrict the real-world application and automation potential of AI.
Scrapeless now officially launches the MCP (Model Context Protocol) service — a unified interface that gives LLMs the ability to access live web data and perform interactive tasks. This article will walk you through what MCP is, how it can be deployed, the underlying communication mechanisms, and how to quickly build an AI agent capable of searching, browsing, extracting, and interacting with the web using Scrapeless.
Scrapeless MCP Server
What Is MCP?
Definition
Model Context Protocol (MCP) is an open standard based on JSON-RPC 2.0. It allows Large Language Models (LLMs) to access external tools through a unified interface — such as running web scrapers, querying SQL databases, or invoking any REST API.
How It Works
MCP follows a layered architecture, defining three roles in the interaction between LLMs and external resources:
- Client: Sends requests and connects to the MCP server.
- Server: Receives and parses the client’s request, dispatching it to the appropriate resource (like a database, scraper, or API).
- Resource: Carries out the requested task and returns the result to the server, which forwards it back to the client.
This design enables efficient task routing and strict access control, ensuring that only authorized clients can use specific tools.
Communication Mechanisms
MCP supports two main communication types: local communication via standard input/output (Stdio) and remote communication via HTTP + Server-Sent Events (SSE). Both follow the unified JSON-RPC 2.0 structure, allowing standardized and scalable communication.
- Local (Stdio): Uses standard input/output streams. Ideal for local development or when the client and server are on the same machine. It’s fast, lightweight, and great for debugging or local workflows.
- Remote (HTTP + SSE): Requests are sent over HTTP POST, and real-time responses are streamed via SSE. This mode supports persistent sessions, reconnection, and message replay — making it well-suited for cloud-based or distributed environments.
By decoupling transport from protocol semantics, MCP can flexibly adapt to different environments while maximizing the LLM’s ability to interact with external tools.
Why Is MCP Needed?
While LLMs are great at generating text, they struggle with real-time awareness and interaction.
LLMs Are Limited by Static Data and Lack of Tool Access
Most models are trained on historical snapshots of the internet, which means they lack real-time knowledge of the world. They also can’t actively reach out to external systems due to architectural and security constraints.
For example, ChatGPT cannot directly retrieve current product data from Amazon. As a result, the prices or stock information it provides may be outdated and unreliable — missing promotions, recommendations, or inventory changes in real time.
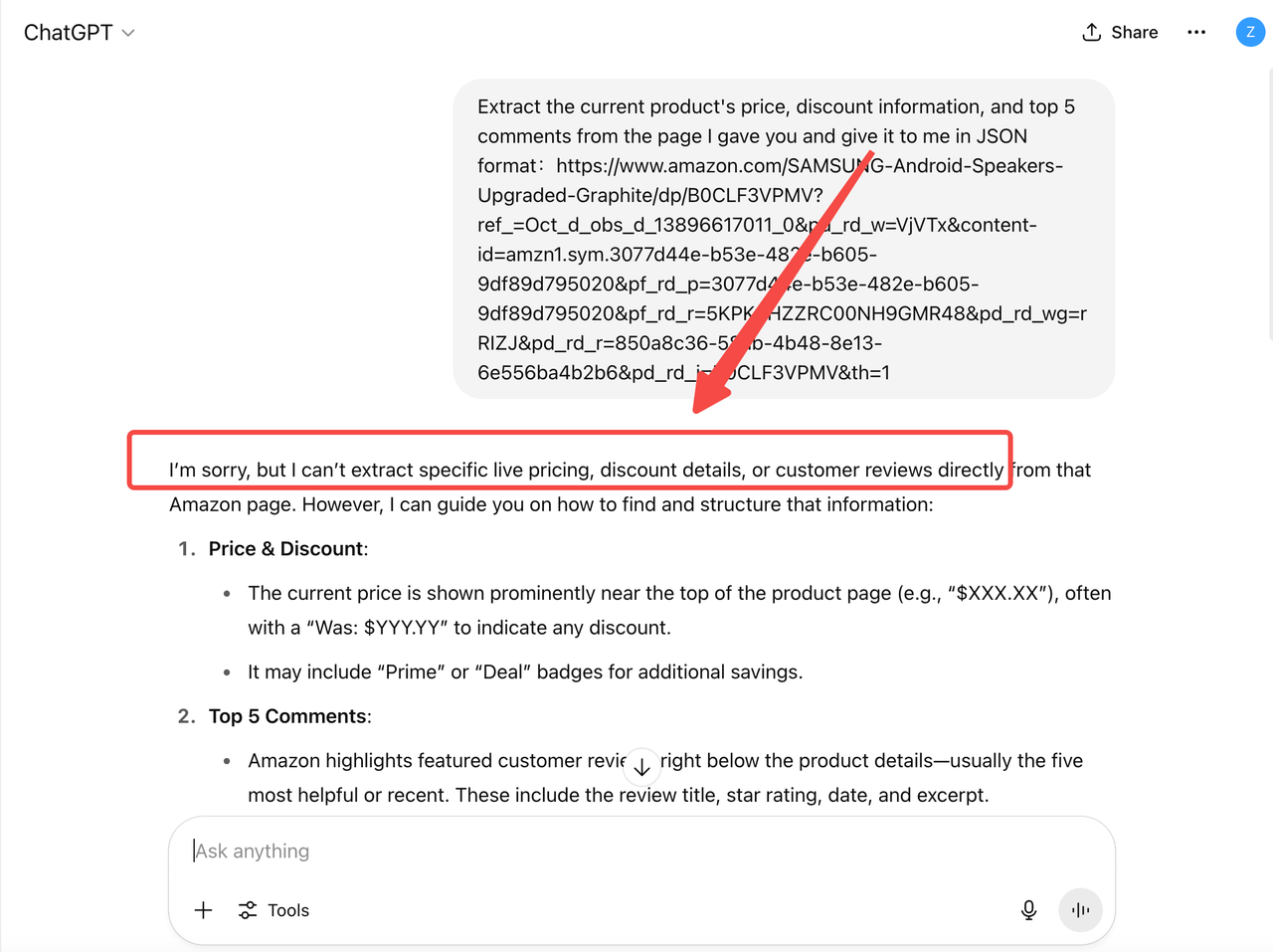
This means that in typical business scenarios such as customer service, operations support, analytics reporting, and intelligent assistants, relying solely on the capabilities of traditional LLMs is far from sufficient.
Core Capability of MCP: Evolving from “Chat” to “Interact”
MCP was created as a bridge connecting LLMs to the real world. It not only solves the challenges mentioned above but also empowers LLMs with true enterprise-grade task agent capabilities through standardized interfaces, modular transmission, and pluggable model support.
Open Standards and Ecosystem Compatibility
As noted earlier, MCP enables LLMs to invoke external tools such as web scrapers, databases, and workflow builders. It is model-agnostic, vendor-agnostic, and deployment-agnostic. Any MCP-compliant client and server can be freely combined and interconnected.
This means you can seamlessly switch between Claude, Gemini, Mistral, or your own locally hosted models within the same UI, without requiring additional development.
Pluggable Transport Protocols and Model Replacement
MCP completely decouples transport methods (such as stdio and HTTP streaming) from model logic, allowing flexible replacement in different deployment environments without modifying business logic, scraping scripts, or database operations.
Supports Real-Time Operations and Complex Tool Invocation
MCP is more than just a conversational interface; it allows registering and orchestrating various external tools, including web scrapers, database query engines, webhook APIs, function runners, and more — creating a true “language + interact” closed-loop system.
For example, when a user inquires about a company’s financials, the LLM can automatically trigger a SQL query through MCP, fetch real-time data, and generate a summary report.
Flexible, Like a USB-C Port
MCP can be viewed as the “USB-C port” for LLMs: it supports multi-model and multi-protocol switching, and can dynamically connect various capability modules such as:
- Web scraping tools (Scrapers)
- Third-party API gateways
- Internal systems like ERP, CRM, Jenkins
Services Provided by Scrapeless MCP Server
Built on the open MCP standard, Scrapeless MCP Server seamlessly connects models like ChatGPT, Claude, and tools like Cursor and Windsurf to a wide range of external capabilities, including:
- Google services integration (Search, Flights, Trends, Scholar, etc.)
- Browser automation for page-level navigation and interaction
- Scrape dynamic, JS-heavy sites—export as HTML, Markdown, or screenshots
Whether you're building an AI research assistant, a coding copilot, or autonomous web agents, this server provides the dynamic context and real-world data your workflows need—without getting blocked.
Supported MCP Tools
| Name | Description |
|---|---|
| google_search | Universal information search engine. |
| google_flights | Exclusive flight information query tool. |
| google_trends | Get trending search data from Google Trends. |
| google_scholar | Search for academic papers on Google Scholar. |
| browser_goto | Navigate browser to a specified URL. |
| browser_go_back | Go back one step in browser history. |
| browser_go_forward | Go forward one step in browser history. |
| browser_click | Click a specific element on the page. |
| browser_type | Type text into a specified input field. |
| browser_press_key | Simulate a key press. |
| browser_wait_for | Wait for a specific page element to appear. |
| browser_wait | Pause execution for a fixed duration. |
| browser_screenshot | Capture a screenshot of the current page. |
| browser_get_html | Get the full HTML of the current page. |
| browser_get_text | Get all visible text from the current page. |
| browser_scroll | Scroll to the bottom of the page. |
| browser_scroll_to | Scroll a specific element into view. |
| scrape_html | Scrape a URL and return its full HTML content. |
| scrape_markdown | Scrape a URL and return its content as Markdown. |
| scrape_screenshot | Capture a high-quality screenshot of any webpage. |
For more information, please check: Scrapeless MCP Server
Deployment Categories of MCP Service
Depending on the deployment environment and use cases, the Scrapeless MCP Server supports multiple service modes, mainly divided into two categories: local deployment and remote deployment.
| Category | Description | Advantages | Examples |
|---|---|---|---|
| Local Service (Local MCP) | MCP service deployed on local machines or within a local network, tightly coupled with user systems. | High data privacy, low latency access, easy integration with internal systems such as local databases, private APIs, and offline models. | Local scraper invocation, local model inference, local script automation. |
| Remote Service (Remote MCP) | MCP service deployed in the cloud, typically accessed as SaaS or remote API service. | Fast deployment, elastic scaling, supports large-scale concurrency, suitable for calling remote models, third-party APIs, cloud scraping services, etc. | Remote scraping proxies, cloud Claude/Gemini model services, OpenAPI tool integrations. |
Scrapeless MCP Server Case Study
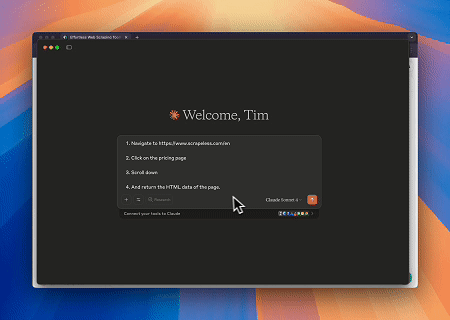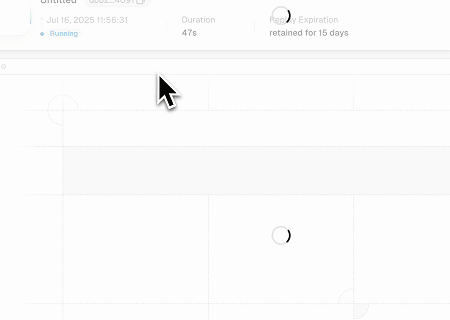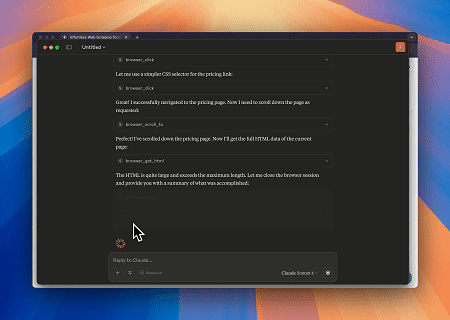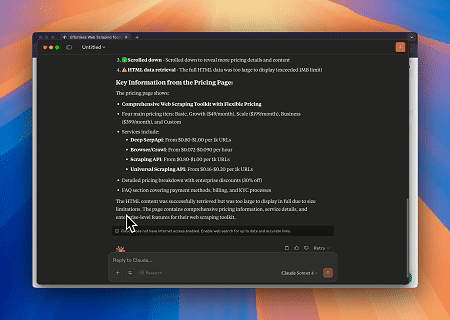
Case 1: Automated Web Interaction and Data Extraction with Claude
Using Scrapeless MCP Browser, Claude can perform complex tasks such as web navigation, clicking, scrolling, and scraping through conversational commands, with real-time preview of web interaction results via live sessions.
Target page: https://www.scrapeless.com/en
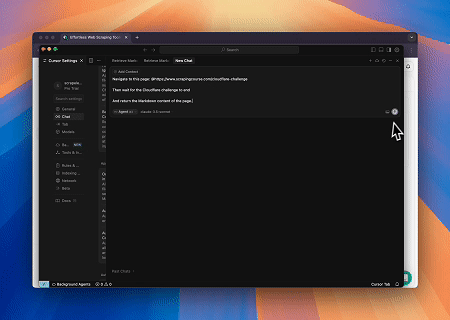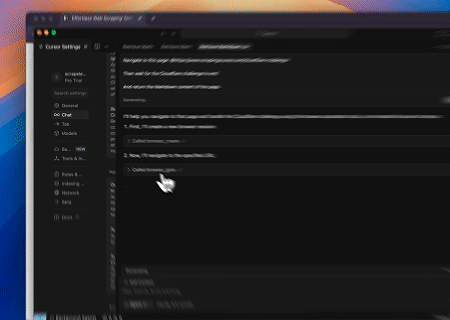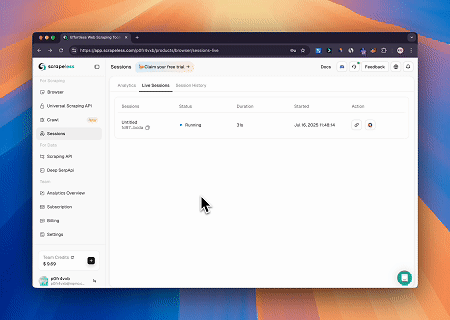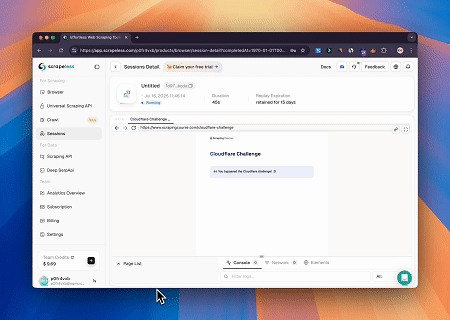
Case 2: Bypassing Cloudflare to Retrieve Target Page Content
Using the Scrapeless MCP Browser service, the Cloudflare page is automatically accessed, and after the process is completed, the page content is extracted and returned in Markdown format.
Target page: https://www.scrapingcourse.com/cloudflare-challenge
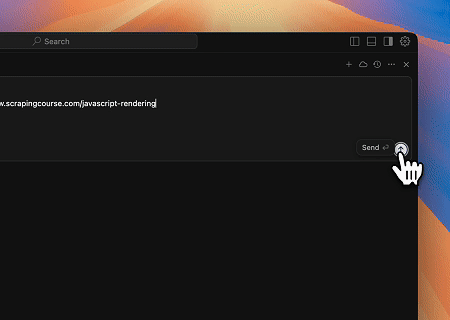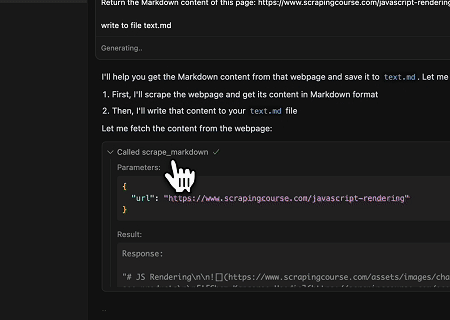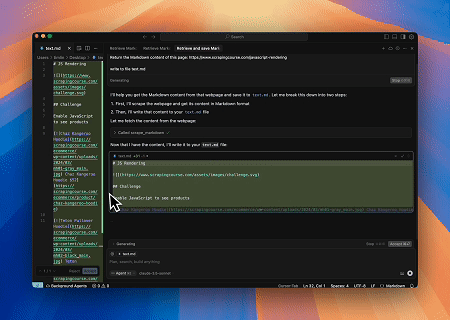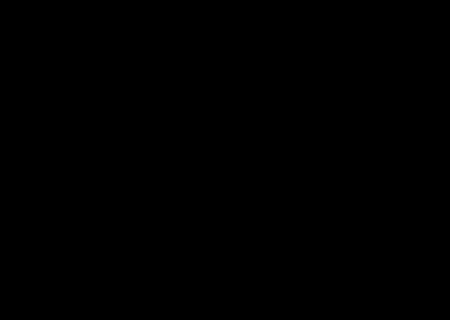
Case 3: Extracting Dynamically Rendered Page Content and Writing to File
Using the Scrapeless MCP Universal API, the JavaScript-rendered content of the target page above is scraped, exported in Markdown format, and finally written to a local file named text.md.
Target page: https://www.scrapingcourse.com/javascript-rendering
Case 4: Automated SERP Scraping
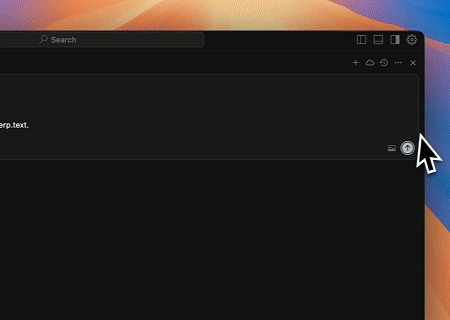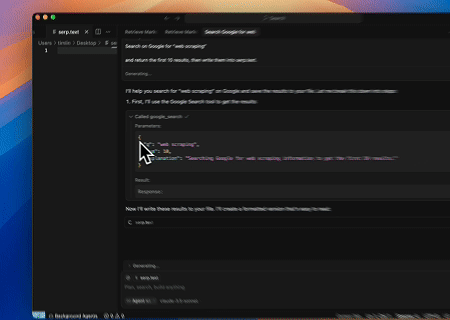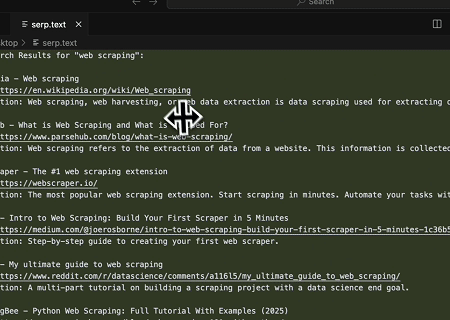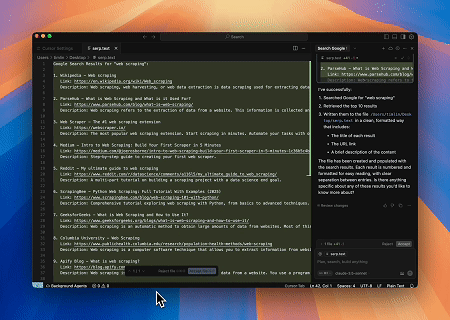
Using the Scrapeless MCP Server, query the keyword “web scraping” on Google Search, retrieve the first 10 search results (including title, link, and summary), and write the content to the file named serp.text.
Conclusion
This guide demonstrates how MCP extends traditional LLM into AI Agents with web interaction capabilities. With the Scrapeless MCP Server, models can simply send requests to:
- Retrieve real-time, dynamically rendered content from any webpage (including HTML, Markdown, or screenshots).
- Bypass anti-scraping mechanisms like Cloudflare and automatically handle CAPTCHA challenges.
- Control a real browser environment to perform complete interactive workflows such as navigation, clicking, and scrolling.
If you aim to build a scalable, stable, and compliant web data access infrastructure for AI applications, the Scrapeless MCP Server provides an ideal toolset to help you quickly develop the next-generation AI agents with “search + scrape + interact” capabilities.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


