
Top 5 Best Web Scraping APIs in 2025
Advanced Data Extraction Specialist
A web scraping API is a powerful tool designed to automate the extraction of data from websites across the internet. Its primary purpose is to help businesses, researchers, and developers gather and organize valuable information from various online sources. These APIs are essential for efficiently handling large volumes of web data, ensuring that organizations can access accurate and relevant insights without manual intervention.
Regardless of your specific use case for data extraction, we’ve compiled a list of the best web scraping APIs available today. Each API has been thoroughly evaluated based on its features, cost-effectiveness, and overall performance. Whether you’re looking to enhance your SEO, streamline your data collection process, or conduct comprehensive research, these web scraping APIs are equipped to address your needs.
Best web scraper in 2025
- Scrapeless – the best overall web crawler
- Scrapy – advanced open-source crawler
- DYNO Mapper – SEO-focused visual crawler
- Oncrawl – Technical SEO web crawler
- Node Crawler – JavaScript-based web crawler
Now, let’s dive into why these Web Scraping API providers stand out and why you should consider them for your web scraping needs.
Scrapeless
Scrapeless's Web Scraper API is designed to efficiently extract relevant data from target websites. It automatically browses the web to collect the precise information you need. By combining AI Agent technology and Browserless integration, Scrapeless creates a powerful web scraping tool without manual coding. AI Agent enhances the scraping process by optimizing the scraping tasks, while Browserless handles the headless browser operation, ensuring smooth data collection from dynamic websites.
With Scrapeless's web crawler, users have full control over their crawling strategy and scope. The crawler methodically follows links from a starting page, traversing all accessible pages of a site until every page has been indexed.
Advantages:
- High success rate: Delivers accurate and reliable data extraction with minimal errors.
- Scalability: Efficiently handles large-scale data collection, making it suitable for extensive websites.
- AI-powered features: Leverages artificial intelligence to enhance the efficiency of web scraping tasks.
- Browserless integration: Uses headless browsing technology to scrape dynamic and JavaScript-heavy websites seamlessly.
- Ethical data collection: Follows best practices in data scraping to ensure ethical and compliant operations.
Disadvantages:
- Learning curve: New users may need time to fully understand and utilize all of Scrapeless’ advanced features.
Price:
- Free Trial
How to get a free trial of Scrapeless?
To get a free trial of Scrapeless, simply log in to the Scrapeless dashboard. Once you're logged in, you will find the option to claim the free trial directly from the dashboard. It's an easy and straightforward process, allowing you to start using the tool right away.
How much does Scrapeless's Scraping API cost?
Scrapeless's Scraping API starts at $1 per 1,000 URLs. Additionally, Scrapeless offers one of the most affordable and fastest SERP APIs available, with search queries processed in just 1-2 seconds. The pricing for these search queries is as low as $0.30 per 1,000 queries, making it one of the most cost-effective solutions on the market.
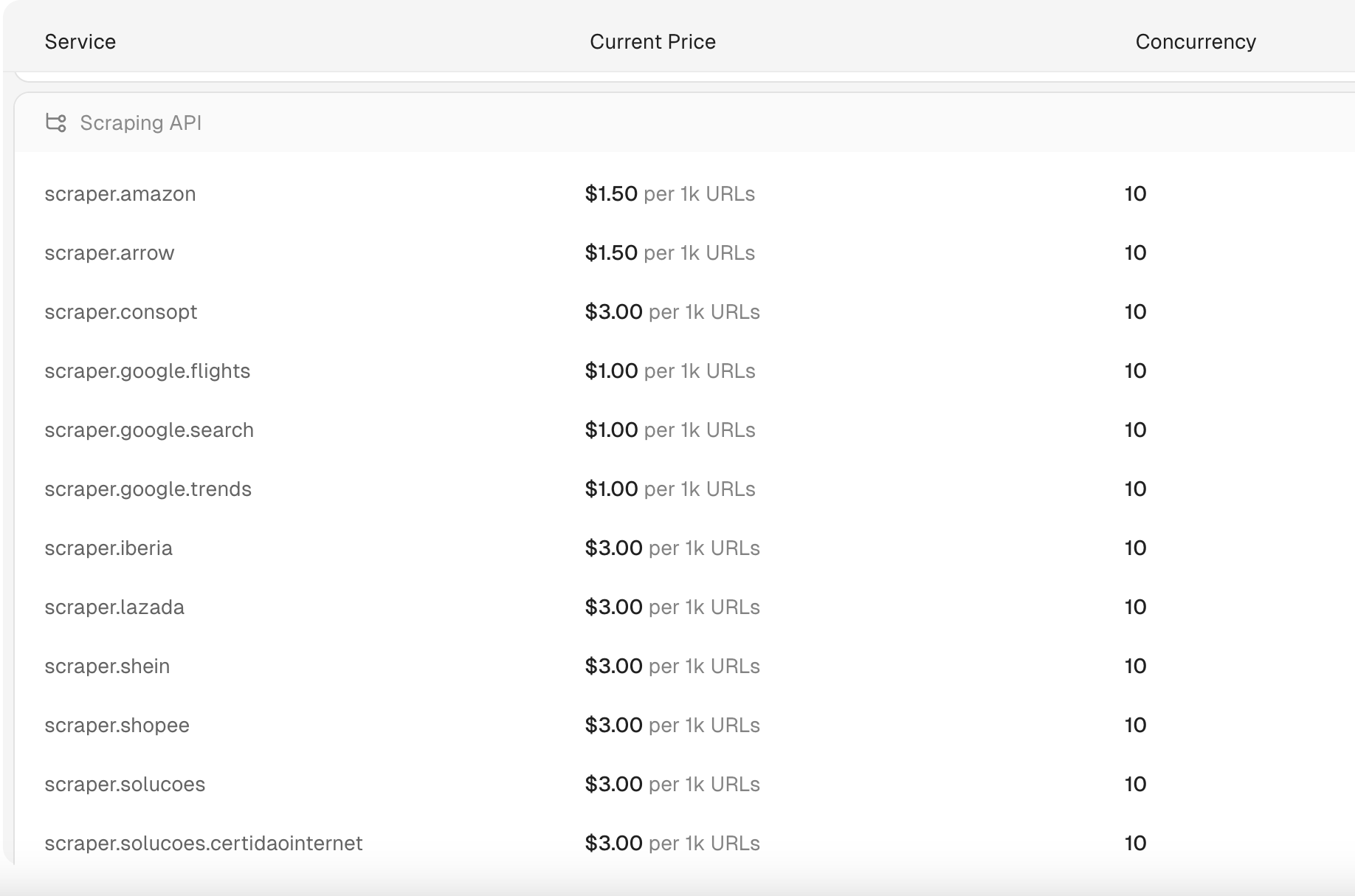
Note:
- Charges are applied on a per-request basis.
- Only successful requests will be billed.
How to use Scrapeless's Scraping API to get Shopee data?
To use Scrapeless's Scraping API to scrape Shopee data, you generally need to follow the following steps. Remember that web scraping may involve legal and ethical issues, so be sure to review Shopee's Terms of Service and ensure compliance with applicable laws.
Step 1. Sign up for Scrapeless API
Please log in to your Scrapeless account. After logging in, you will get an API key.
Step 2. Select your scraping plan
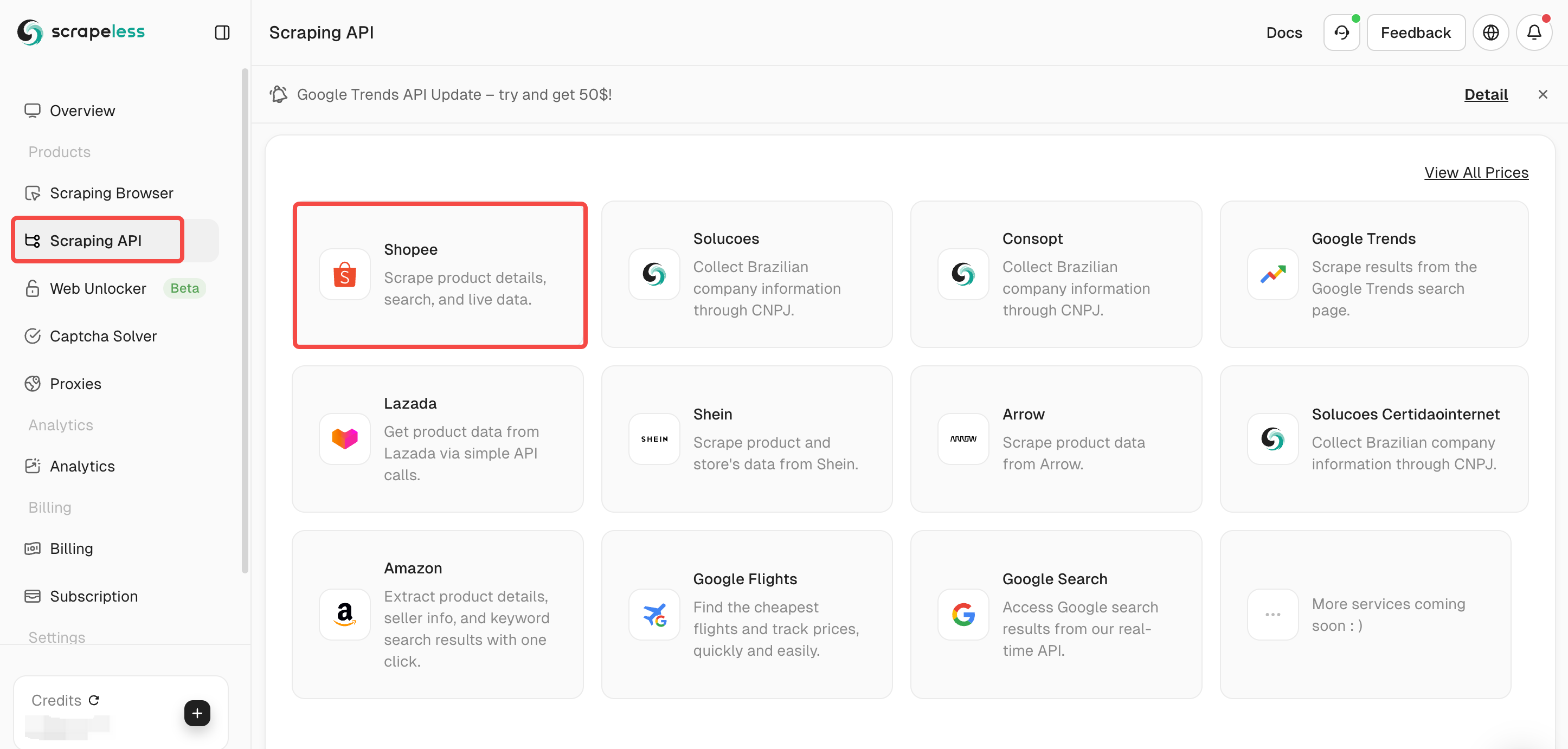
Select Scraping API in the dashboard, and then select Shopee.
Scrapeless provides multiple scraping APIs, such as Lazada /Shein /Google Search/Google Flights.
Step 3. Configure the parameters of your Shopee Scraping API. Then click “Start Scraping” and you can see the output result data in the right panel.
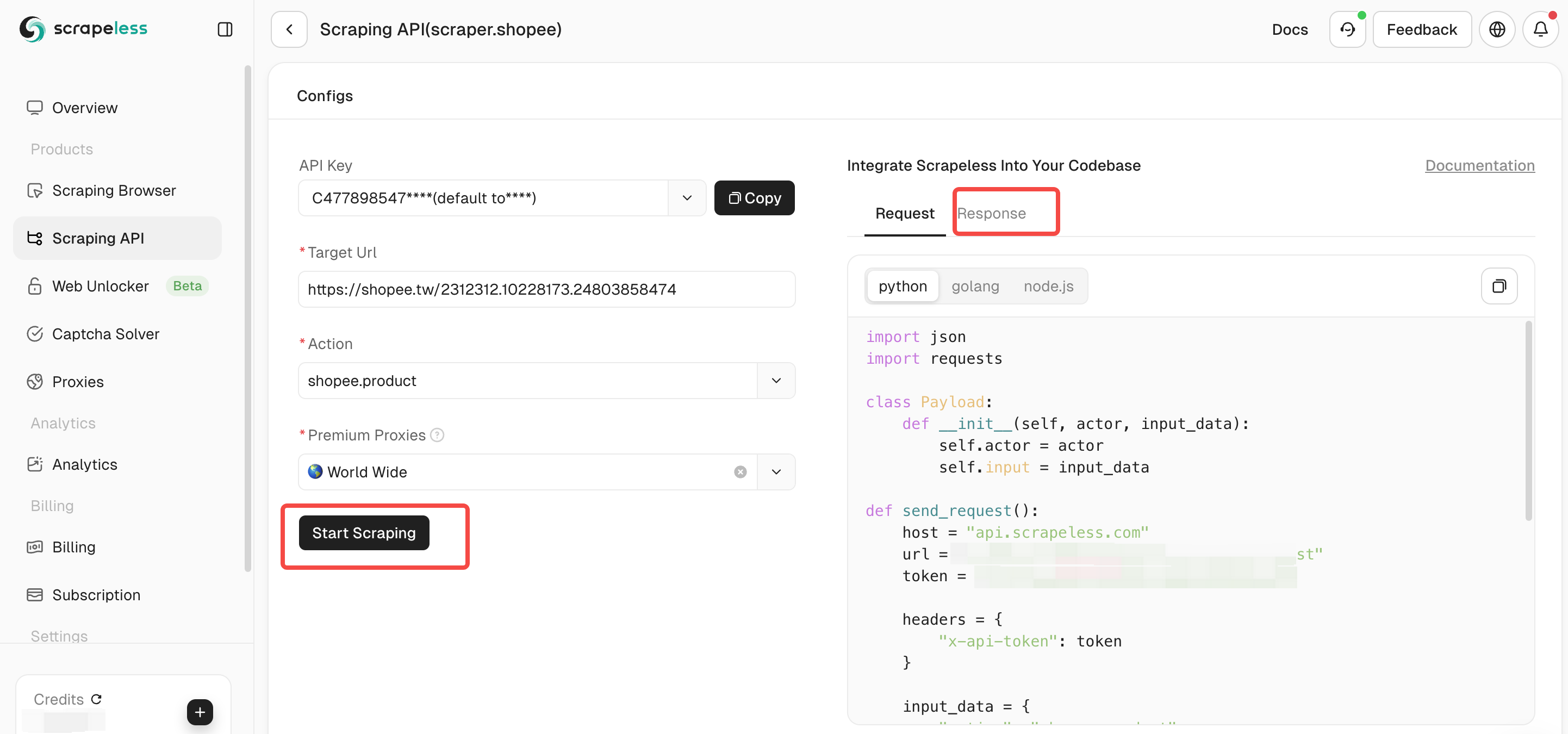
How to integrate Scrapeless into your project?
To integrate Scrapeless into your project, you can effectively improve your crawling efficiency. Scrapeless is commonly used for web scraping and data extraction tasks. The following is a code example to integrate Scrapeless into your project. Of course, you can also check out the complete documentation of Scrapeless:
Shopee Product
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee Search
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.product",
"url": "https://shopee.tw/api/v4/pdp/get_pc?item_id=1413075726&shop_id=19675194"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee Live
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.live",
"url": "https://live.shopee.co.th/api/v1/session/{sessionId}"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee Rcmd
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.rcmd",
"url": "https://shopee.co.th/api/v4/shop/rcmd_items?bundle=shop_page_category_tab_main&item_card_use_scene=category_product_list_topsales&limit=30&offset=0&shop_id=1195212398&sort_type=13&upstream="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Shopee Ratings
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.shopee",
"input": {
"action": "shopee.ratings",
"url": "https://shopee.ph/api/v2/item/get_ratings?exclude_filter=1&filter=0&filter_size=0&flag=1&fold_filter=0&itemid=23760784194&limit=6&offset=0&relevant_reviews=false&request_source=2&shopid=29975023&tag_filter=&type=0&variation_filters="
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Scrapy
Scrapy is a popular, open-source web crawling framework built with Python, designed to facilitate web scraping and data extraction via web scraping APIs. It provides developers with the tools to build robust, scalable crawlers by leveraging a well-organized system centered around "spiders"—self-contained crawling units with specific instructions to target data.
Following the "don’t repeat yourself" (DRY) principle, Scrapy promotes code reusability, making it an efficient choice for scaling large crawling operations. Thanks to its versatility, Scrapy is favored by developers and data scientists working on advanced scraping tasks.
Advantages:
- Open-source scraping library: Available for free under the BSD license, with contributions from a vibrant community.
- Ideal for developers and data scientists: Offers powerful customization options and full control over the scraping process.
Disadvantages:
- Challenging for beginners: Requires a strong understanding of Python and web scraping concepts, which can be a barrier for those new to the field.
- Resource-heavy: Can consume significant system resources, particularly when dealing with large-scale scraping projects.
- Not very user-friendly for newcomers: The complexity and need for coding expertise may overwhelm those who are new to web scraping.
Price:
- Free
You may need: How to Solve Web Scraping Challenges - Full Guide 2025
DYNO Mapper
DYNO Mapper is an intuitive visual sitemap generator that crawls websites by following internal links, mimicking the behavior of search engine bots. After crawling, it generates a visual sitemap that showcases the website’s structure, helping users better understand site navigation. The tool supports multiple output formats, including interactive visual sitemaps, HTML, CSV, XML, PDF, JSON, and Excel (XLSX). In addition to its sitemap functionality, DYNO Mapper offers content inventory and auditing capabilities, along with accessibility testing to ensure compliance with ADA website standards. It also integrates seamlessly with web scraping APIs for advanced data extraction needs, making it one of the best web crawlers for content management.
Advantages:
- Multiple output formats: Provides flexibility by delivering data in several formats, enhancing the usability of the information.
- Content inventory and auditing tools: Helps streamline the organization and optimization of website content for better performance.
Disadvantages:
- Free plan limitations: The free plan has restricted features, which might not meet the needs of all users.
- Complex to master: Requires time and effort to fully understand and use all its advanced features.
Price:
- Free trial available, with the most affordable plan starting at $39/month.
Oncrawl
Oncrawl is a powerful web crawling tool tailored for SEO and technical website analysis. It offers detailed SEO audits, customizable dashboards, and scalable solutions for large-scale websites, making it a key resource for any digital marketing strategy. As one of the best web crawlers, Oncrawl enables businesses to analyze and improve their online presence efficiently. Additionally, it integrates with web scraping APIs to enhance data extraction capabilities.
Advantages:
- Thorough SEO audits: Provides comprehensive insights into your website's SEO performance.
- Customizable dashboards and reports: Users can personalize reports and dashboards to meet their specific requirements.
Disadvantages:
- Limited crawling control for smaller websites: May not offer as much flexibility in crawling settings for smaller sites.
- Steep learning curve: Requires time to fully grasp and leverage all of Oncrawl’s features.
Price:
- Starting from $69/month
Node Crawler
Node Crawler is a popular web crawling library designed for Node.js, widely recognized for its flexibility and ease of use. By utilizing Cheerio as its default parser, it provides fast and efficient HTML parsing and manipulation. The library offers numerous customization options, such as queue management for handling concurrency, rate limiting, and automatic retries, making it a powerful tool for web scraping projects.
Thanks to its lightweight nature, Node Crawler ensures minimal memory consumption, making it ideal for high-performance tasks, even when processing large volumes of requests. As one of the best web crawlers for Node.js developers, it integrates perfectly into JavaScript-based workflows and allows seamless use of web scraping APIs.
Advantages:
- Perfect for Node.js developers: Integrates effortlessly into JavaScript environments, making it the go-to choice for developers familiar with Node.js.
- Efficient and lightweight: Designed with performance in mind, ensuring low memory usage during operations, even when handling multiple requests.
Disadvantages: - No native JavaScript rendering: It doesn’t support JavaScript rendering by default, which may require additional tools or configurations to scrape dynamic content.
Price:
- Free
Best web scraping Tool compared
| Provider | Best features |
|---|---|
| Scrapeless | Advanced proxy infrastructure and residential IPs for scalable and ethical web scraping and web crawling. |
| Scrapy | A powerful open-source Python framework for building custom web crawlers and scrapers. |
| DYNO Mapper | Focuses on creating visual sitemaps and conducting SEO audits for website optimization and structure analysis. |
| Oncrawl | A technical SEO-focused web crawler with advanced analysis for website architecture, crawl budget, and log files. |
| Node Crawler | A flexible, JavaScript-based crawler built on Node.js, ideal for modern websites with dynamic content. |
What is web scraping?
Web scraping is a technique used to automatically extract data from websites. This process involves several key steps:
Definition
Web scraping, also known as web harvesting or web data extraction, refers to the automated method of retrieving and collecting information from web pages. It typically involves using software tools or scripts that can access the internet, download web pages, and extract specific data from them for various purposes, such as analysis or storage in databases.
How Web Scraping Works
- Request: The process begins with sending a request to a website's server, similar to entering a URL in a browser.
- Response: The server responds by delivering the requested web page, which may contain text, images, and other types of data.
- Parsing: The web scraping tool then analyzes the HTML content of the page to locate and extract specific data points, such as product prices, contact information, or other relevant details
- Storage: Finally, the extracted data is saved in a structured format, such as CSV, Excel, or a database, for later use
Applications of Web Scraping
Web scraping has a wide range of applications across various industries:
- Market Research: Gathering competitive pricing and product information.
- Lead Generation: Collecting contact details for sales and marketing efforts.
- Price Monitoring: Tracking changes in prices for products across different retailers.
- Content Aggregation: Compiling news articles or product reviews from multiple sources
Differences from Web Crawling
While web scraping and web crawling are related concepts, they serve different purposes. Web crawling is primarily focused on discovering and indexing web pages by following links throughout the internet. In contrast, web scraping specifically targets the extraction of data from those pages once they have been accessed.
Conclusion
In conclusion, selecting the right web scraping API is crucial for businesses and developers looking to extract and leverage valuable data from the web. The top 5 best web scraping APIs in 2025 provide a range of features that cater to different needs—whether it's scalability, ease of use, or advanced data processing capabilities. Each of these tools has its own strengths, making them suitable for various applications, from SEO optimization to market research and content aggregation.
FAQ
How do web scraping APIs work?
Web scraping APIs function by sending requests to target websites on behalf of the user, retrieving data while managing complexities such as proxy handling and anti-bot measures. Users can access structured data without needing to develop custom scrapers.
Can I try these web scraping APIs before committing?
Most leading web scraping APIs offer free trials or pay-per-use pricing models to let users test their functionality and effectiveness before making a financial commitment. For example, Scrapeless offers a free trial. Users who also participate in testing new features on Scrapeless’ Discord will also receive credits that can be used across all Scrapeless products! 🎉
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


