Loading...
🎯 一款可定制、具备反检测功能的云浏览器,由自主研发的 Chromium驱动,专为网页爬虫和AI 代理设计。👉立即试用
最全面的指南,专为所有网络抓取开发者打造。
提供您的联系方式,我们将迅速联系您,提供产品演示和介绍。我们确保您的信息保密,符合GDPR标准。
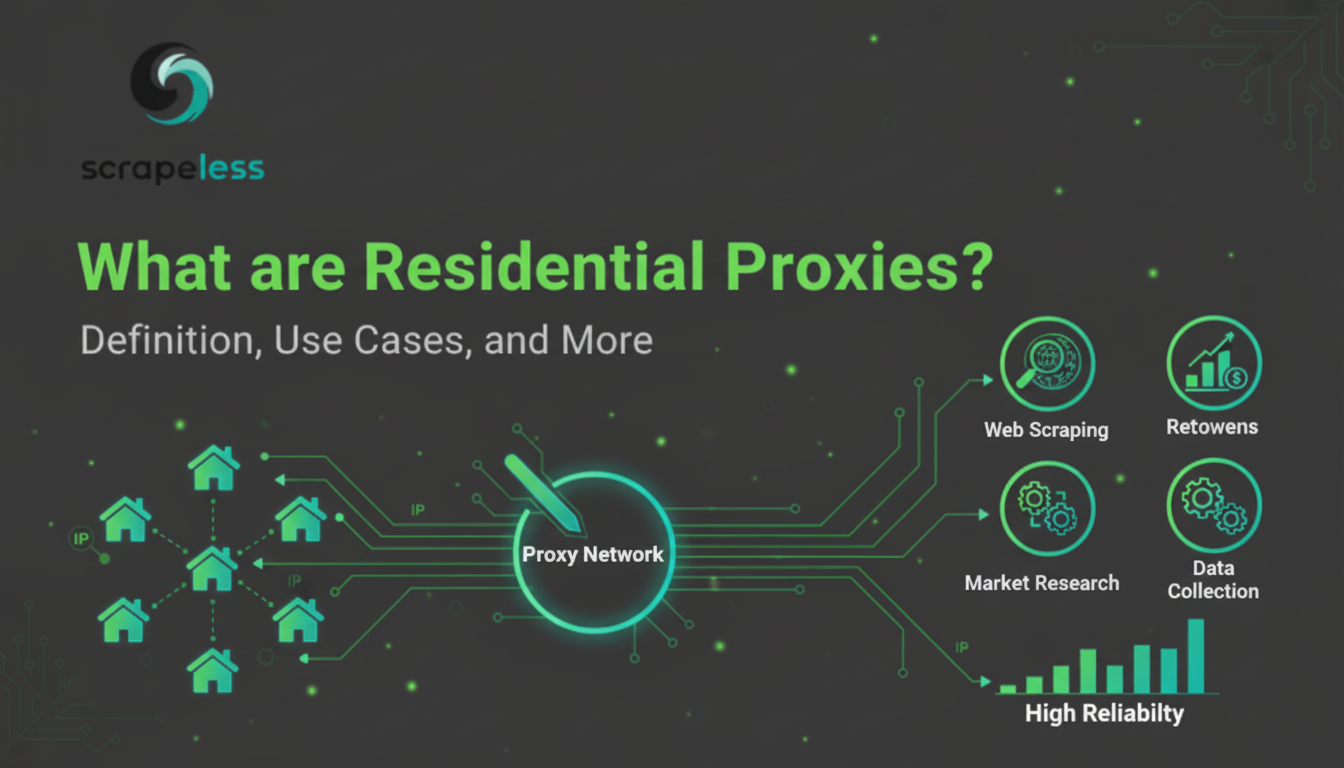
住宅代理的完整指南。了解它们是如何工作的,它们在网络抓取、价格监控和广告验证中的好处。发现为什么Scrapeless的9000万个IP和99.98%的成功率使其成为行业领导者。
学习如何使用HTTPX与Scrapeless代理进行可靠的网络抓取。完整指南包含未经身份验证、经过身份验证、轮换和备用代理连接的代码示例。99.98%的成功率,拥有超过9000万个住宅IP。

一个逐步指南,介绍如何在Cloudscraper Python库中配置、轮换和验证代理,以绕过Cloudflare和其他反机器人系统,实现有效的网络抓取。特点为无抓取代理。

解释了生成随机IP地址字符串与使用旋转代理网络以实现真正匿名性和成功抓取网页之间的区别。包括一个Python示例,并介绍了Scrapeless Proxies的特点。

在SeleniumBase框架中使用命令行配置未认证和认证代理的逐步指南,这对于地理定位和匿名网页抓取至关重要。具有无抓取代理的特点。

一份全面的指南,介绍如何在 Python 中使用 Requests、AIOHTTP 和 Scrapy 实现代理轮换,重点在于克服 IP 封禁和提高使用 Scrapeless Proxies 的抓取效率。

一个关于如何使用 HttpClientHandler 和 WebProxy 在 C# HttpClient 中配置和验证代理的逐步教程,适用于强大的网络爬虫和数据收集。具有无抓取代理的特点。

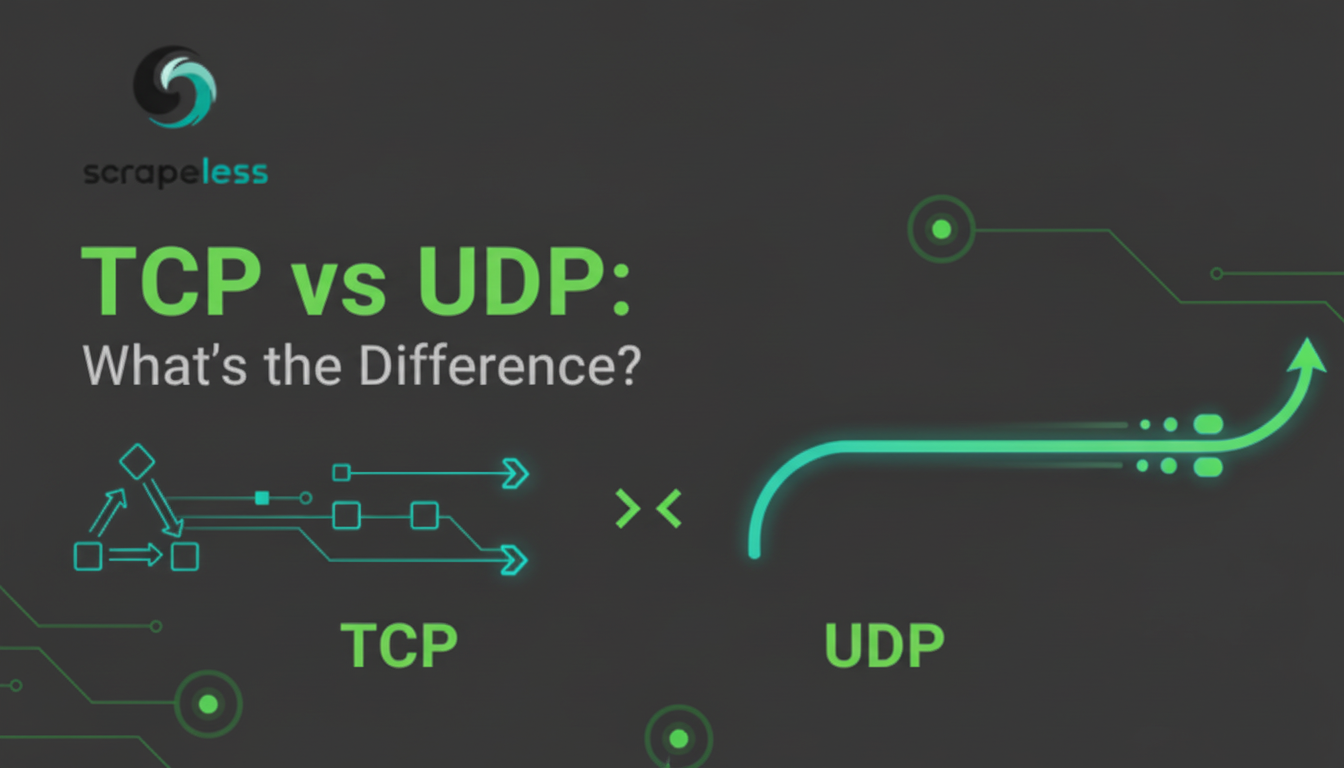
TCP和UDP的详细比较,解释它们在可靠性与速度之间的权衡,以及它们如何与像HTTP和SOCKS5这样的代理协议在网页抓取和实时数据中相关联。特性无痕代理。