
2025年搜索引擎抓取Top 6 SERP API终极列表
Specialist in Anti-Bot Strategies
2025年6大最佳SERP数据API
在选择和测试不同的SERP抓取API时,以下测试方向可以帮助评估每个API的性能:
- 抓取速度和响应时间。
- 反屏蔽测试。
- 数据一致性测试。
- API错误和处理能力。
- 用户负载和并发处理。
Top 1. Scrapeless

为什么Scrapeless是最好的抓取SERP工具?是的,这里有一点偏见。但是,Scrapeless凭借其实力更具可信度。
**Scrapeless支持免费版本。**只需加入我们的Discord即可享受!Scrapeless serp API是一个创新的解决方案,旨在简化从搜索引擎提取数据的过程。借助我们先进的抓取API,您可以访问所需的数据,无需编写或维护复杂的抓取脚本。简单的API调用即可立即访问有价值的信息。
- 优缺点
| 优点 | 缺点 |
|---|---|
| Scrapeless具有强大的反屏蔽和反指纹识别能力。 | 上市时间短 |
| 它提供高并发抓取能力,可以智能调整请求频率和IP使用频率 | 每次API调用的成本从0.001美元起,对于更大数据量的请求,成本下降到低于0.0008美元 |
Scrapeless支持抓取许多主要的搜索引擎,例如Google、Bing、Yahoo等。并支持专属服务,只需告诉我们您的需求。
- 用例
Scrapeless非常适合需要抓取难以抓取和严格的反爬虫网站数据的用户,特别是那些需要绕过搜索引擎屏蔽的任务。对于所有SEO公司、市场研究机构以及需要获取大量竞争对手数据的用户来说,它都是理想的选择。
正在寻找一个全面的抓取API工具?
使用Scrapeless享受无缝抓取体验。
立即试用!
Top 2. ZenSerp
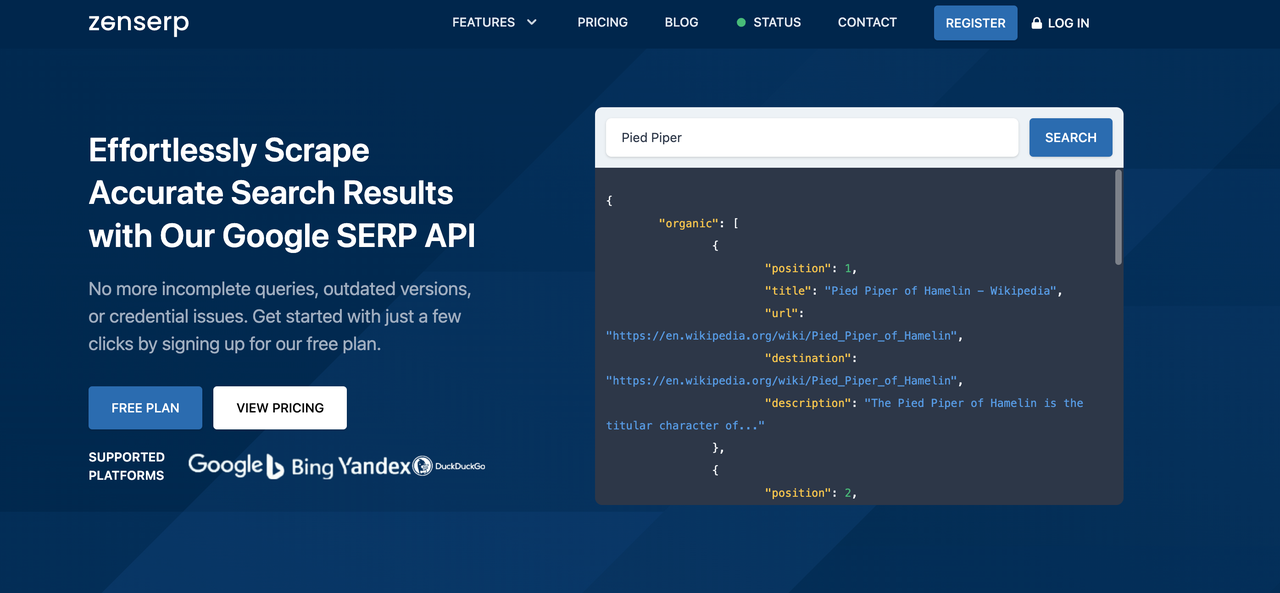
ZenSerp是一项提供各种API的服务,旨在从不同的搜索引擎收集数据。使用此API非常简单,网站上还有一个Playground,允许您直接在您的网站上配置和运行API请求。您还可以查看生成的请求代码,但有时在生成代码时会出错。
- 优缺点
| 优点 | 缺点 |
|---|---|
| 提供访问搜索结果的API | 与其他服务相比,免费试用版受到限制,可能无法提供足够的数据进行全面测试 |
| 提供的定价计划起价为49.99美元 | 生成的代码可能包含错误,这可能会使使用变得困难或不可能,尤其对于初学者而言 |
| 快速,平均响应时间为4.73秒 |
- 用例
此抓取SERP工具适用于SEO分析、排名监控和大规模抓取任务。开发人员和中小型企业会喜欢使用它。
Top 3. SerpWow
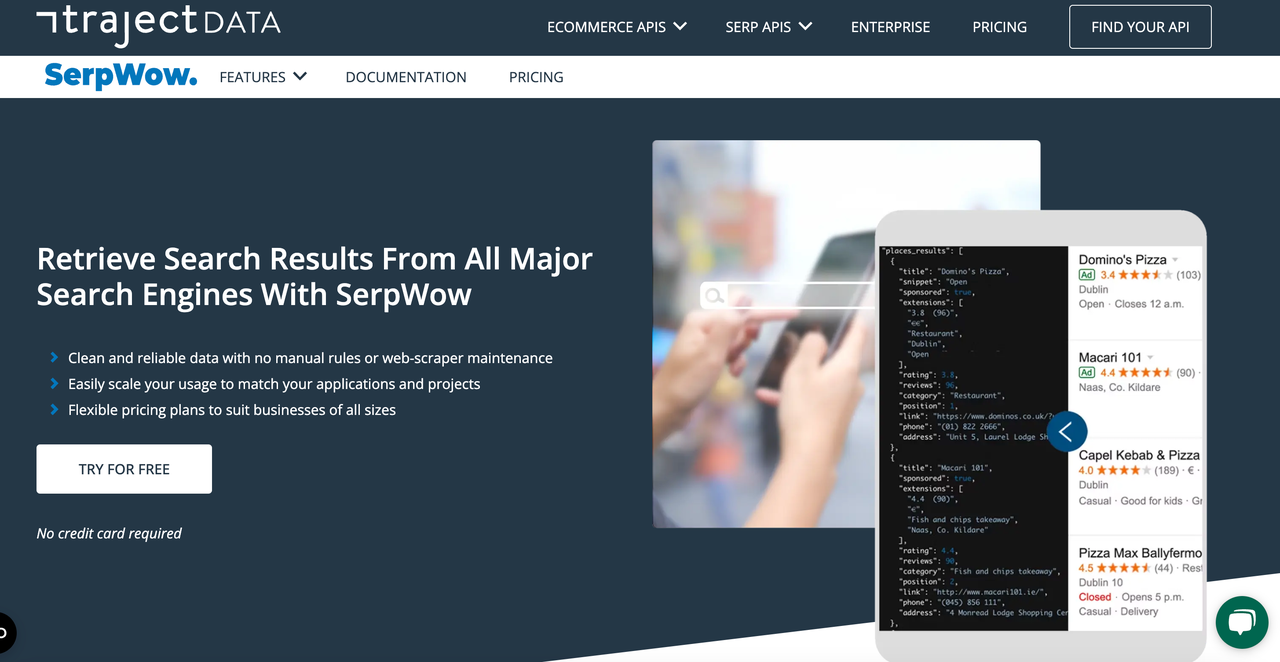
SerpWow是一个简单易用的SERP抓取API,专注于实时抓取高精度搜索引擎结果数据,提供稳定的性能和强大的抓取能力。总的来说,使用此SERP API与大多数其他API类似。此外,该网站提供了清晰的文档和示例。
- 优缺点
| 优点 | 缺点 |
|---|---|
| 试用版允许100个请求,提供在承诺付费计划之前测试服务的机会。 | 其JSON响应包含异构的、冗余的、非结构化的数据。 |
| 其最低资费计划起价为每1000个请求25美元。 | 平均响应时间为12.08秒,在所考虑的服务中属于中等水平。 |
- 用例
它适用于需要低延迟和高频率抓取的SEO监控和关键词排名分析。中小型企业或SEO开发人员可能会选择它。
Top 4. DataForSEO
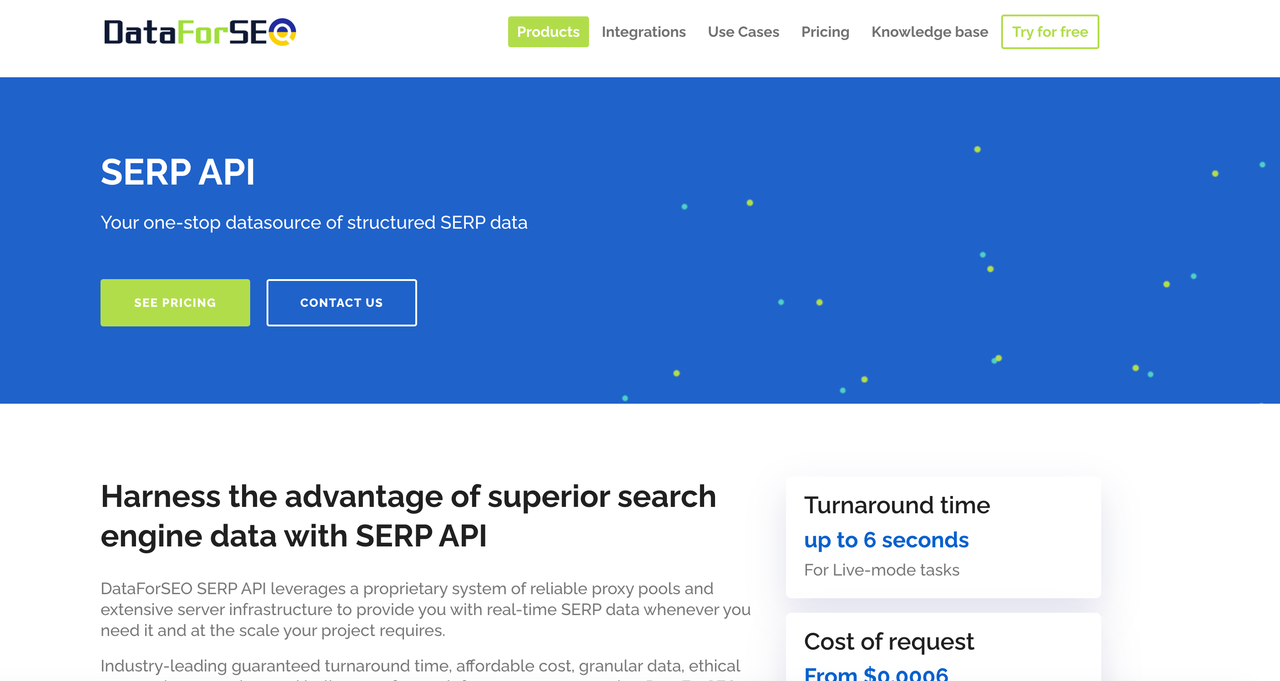
DataForSEO SERP抓取API以JSON格式获取实时的SERP数据,包括自然搜索结果和付费搜索结果。其中包括一个用于抓取Google SERP数据的API。
此抓取SERP工具的SERP API非常方便。它不是通过API密钥提供的,而是通过基于登录名和密码生成的密钥提供的。
- 优缺点
不幸的是,它包含许多不必要的信息。让我们考虑一下这项服务的主要优缺点:
| 优点 | 缺点 |
|---|---|
| 提供500次请求试用 | 平均响应时间为6.75秒 |
| JSON响应格式方便 | JSON响应缺乏结果分割 |
| 综合数据检索 | 非企业访问需要联系支持 |
- 用例
适用于需要高精度、大规模SEO抓取的数据。它适用于大型企业和SEO公司,特别是那些需要大数据支持的市场研究和SEO优化任务。
Top 5. HasData

HasData是一个网络抓取和自动化平台,提供简化数据提取、网络自动化和数据处理任务的工具和基础设施。它提供各种提取API,包括Google SERP API。但是,测试表明,此API也是最慢的API之一。
- 优缺点
| 优点 | 缺点 |
|---|---|
| 更低的价格(起价为29美元) | 不支持某些不太常见的编程语言 |
| 以JSON格式响应,并包含指向页面屏幕截图的链接 | 没有内置的分析或报告工具 |
| 30天免费试用,允许200个Google SERP请求 | 文档繁琐,缺乏原始API用法的清晰示例,并且经常依赖其库 |
- 用例
此SERP API适用于中小型企业和开发人员执行中等规模的搜索引擎数据抓取,特别是那些需要灵活定制抓取任务的用户。
Top 6. Scrape-IT
Scrape IT是一个专注于简单高效的网络数据抓取的API。它适用于不需要复杂功能并追求高效抓取的用户。
- 优缺点
| 优点 | 缺点 |
|---|---|
| 文档非常清晰,包含几乎所有语言的代码片段 | 在同时发出多个请求时,API会遇到延迟响应 |
| 平均响应时间5秒 | |
| 支持Google和Bing,适用于主流SEO抓取任务 |
- 用例
Scrape IT在JavaScript渲染和反屏蔽机制方面具有明显的优势,尤其适用于对抓取动态内容要求较高的用户。
总体评价
| 属性 | 速度 | 可扩展性 | 文档 | 稳定性 | 定价 | 评价 |
|---|---|---|---|---|---|---|
| Scrapeless | 4.6 | 4.7 | 4.7 | 4.8 | 4.8 | 🌟🌟🌟🌟🌟 |
| ZenSerp | 4.8 | 4.8 | 4.6 | 4.7 | 4.6 | 🌟🌟🌟🌟 |
| SerpWow | 4.0 | 4.7 | 4.5 | 4.7 | 4.5 | 🌟🌟🌟🌟 |
| DataForSEO | 4.3 | 4.6 | 4.6 | 4.8 | 4.7 | 🌟🌟🌟 |
| HasData | 4.0 | 4.5 | 4.7 | 4.7 | 4.8 | 🌟🌟🌟 |
| Scrape It | 4.3 | 4.5 | 4.5 | 4.4 | 4.7 | 🌟🌟🌟 |
最佳SERP API工具 - Scrapeless:使用方法
我们一直在努力访问准确可靠的Google SERP数据至关重要。这就是Scrapeless SERP API的用武之地——一个功能强大、价格实惠且高效的工具,旨在简化您的数据提取工作。
我们的竞争价格一定会让您大吃一惊!每1000个URL的费用是多少?只需1美元(订阅以获得更多折扣)!
为什么我们应该选择Scrapeless SERP API?
Scrapeless专为处理抓取Google搜索引擎结果页面(SERP)的挑战而设计。凭借先进的反检测机制、高速性能和极高的成功率,Scrapeless确保您的数据收集顺利进行,不会中断或被禁止。
无论您是跟踪关键词排名、监控竞争对手还是收集市场洞察,Scrapeless都能提供始终准确的结果。
- 经济高效:Scrapeless旨在提供卓越的价值。
- 一致的性能:**凭借其久经考验的记录,Scrapeless即使在高负载下也能提供稳定的API响应。
- 令人印象深刻的成功率:告别失败的提取,Scrapeless承诺99.99%成功访问Google SERP数据。
- 可扩展的解决方案:借助Scrapeless背后的强大基础设施,轻松处理数千个查询。
如何使用Scrapeless Google Search API?
步骤1. 登录Scrapeless控制面板并转到“Google Search API”。
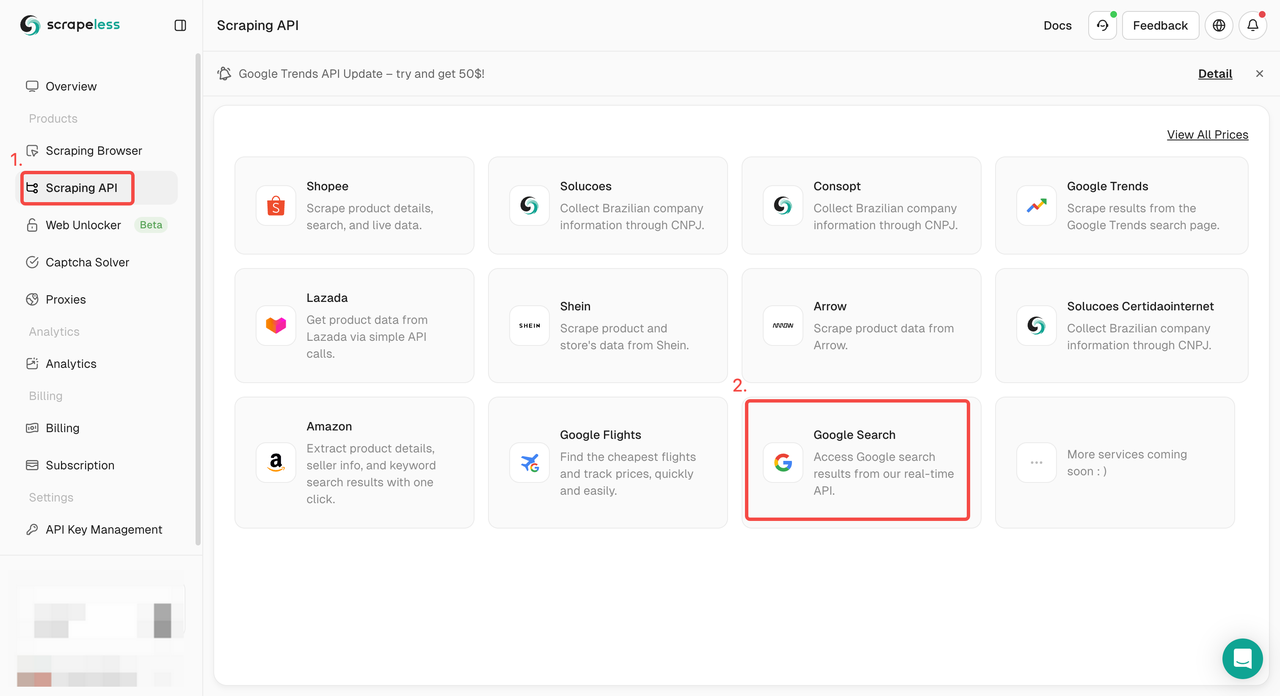
步骤2. 在左侧配置您需要的关键词、地区、语言、代理和其他信息。确保一切正常后,单击“开始抓取”。
q:参数定义您要搜索的查询。gl:参数定义要用于Google搜索的国家/地区。hl:参数定义要用于Google搜索的语言。

步骤3. 获取抓取结果并导出它们。
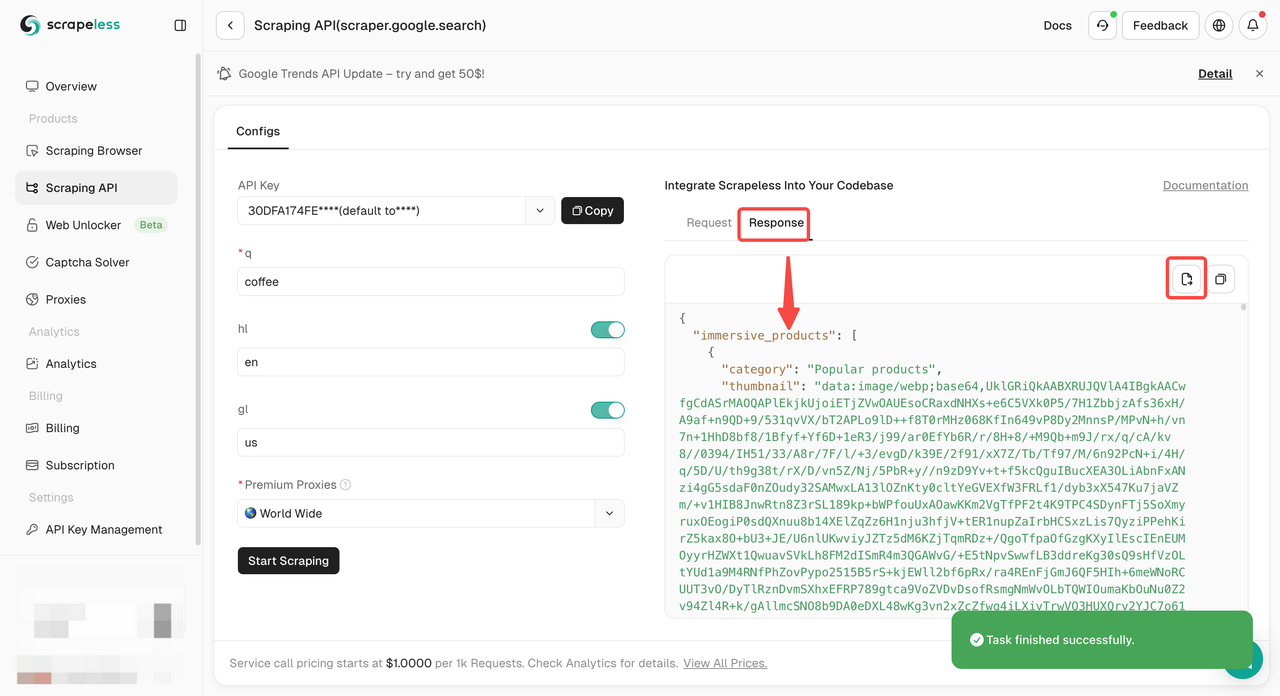
只需要集成到项目的示例代码?我们已经为您准备好了!或者您可以访问我们的API文档以获取您需要的任何语言。
- Python:
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang:
go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}什么是搜索引擎抓取?
搜索引擎抓取(也称为SERP抓取)是指通过自动化方式获取搜索引擎结果页面(SERP)上的数据。这通常包括标题、描述、URL、排名、付费广告、图片、视频以及搜索引擎返回的其他类型的搜索结果。抓取此数据有助于:
- 监控竞争对手的SEO策略
- 分析关键词排名和搜索趋势
- 进行市场研究和用户行为分析
- 提供搜索引擎优化 (SEO) 建议
为了避免被搜索引擎阻止或反检测,通常需要使用代理池、IP轮换和浏览器指纹模拟等技术。
Scrapeless与轮换代理和IP服务集成。
立即获取此特殊的SERP数据API!
SERP API提取的数据类型
SERP API专注于抓取和提供来自搜索引擎的高质量搜索结果数据。它主要提取以下类型的数据,以帮助用户进行深入的SEO分析和排名监控:
- 搜索结果排名数据
Serp数据API提供关键词在搜索引擎结果中的特定排名位置,包括自然排名(自然搜索结果)和付费广告(Google Ads)位置。
- 网页标题和描述
抓取每个搜索结果的标题和描述对于SEO优化非常重要,有助于分析页面结构和搜索结果中的关键词密度。
- URL地址
提供每个搜索结果页面的URL,以帮助用户分析排名页面的SEO性能以及它是否是竞争对手页面。
- 搜索引擎功能
Serp API可以提取与搜索引擎功能相关的数据,例如“精选摘要”、“图片”、“视频”、“新闻剪辑”等。这些数据对于SEO策略和内容优化至关重要。
- SERP分析数据
包括SERP功能、搜索意图分析、搜索广告、图片/视频搜索结果等,以帮助用户充分了解某个关键词的搜索引擎表现。
- 地理定位数据
Serp API还支持按特定地理位置抓取数据,可以获取不同地区和语言环境下的搜索引擎排名数据,非常适合全球化或本地化的SEO分析。
- 搜索引擎广告数据
提供搜索引擎广告排名、显示的广告文案、广告客户信息等,以帮助用户了解付费广告的有效性。
总结
本博客中的这6个SERP API将帮助您应对不同的情况:
- BrightData和Oxylabs:在大规模和高需求任务中效果很好。
- Apify:最适合小型和灵活的抓取。
- Serp API:是进行SEO数据抓取的绝佳工具。
Scrapeless是您最佳的SERP数据API选择! 它适用于需要绕过复杂反爬虫机制的高级用户,尤其是在面临极高反爬虫压力的抓取任务中。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


