
2025年5款最佳网页爬虫:高效数据抓取完整指南
Advanced Data Extraction Specialist
有很多网络爬虫可以帮助你高效地提取数据、索引网页或执行自动化网络抓取。但是,你可能会发现并非所有爬虫都同样有效——有些功能有限,有些可能难以配置或过于资源密集。有时,选择错误的工具会减慢你的工作流程,甚至导致IP被封。那么,你如何找到合适的工具呢?
为了解决这个问题,你只需要一个能够平衡性能、易用性和可扩展性的最佳网络爬虫。鉴于此,我们已经选择并审核了5个最佳的网络爬虫,它们为各种抓取需求提供强大的功能。继续阅读以找到最适合你需求的那个。
| 产品名称 | 易用性 | 功能 | 最适合 | 类型 | 价格 |
|---|---|---|---|---|---|
| Scrapeless | 非常容易,用户友好的界面,具有高级自动化功能 | 高级反封锁技术、代理池、快速数据提取、动态渲染支持、验证码解锁、真实浏览器反检测 | 需要高性能数据抓取的专业人士和企业 | 基于云,大规模抓取 | 从$49/月起,订阅折扣可用 |
| WebHarvy | 易于使用,点击式界面 | 可视化抓取界面,支持抓取图像、链接、文本,计划程序用于自动化爬取 | 抓取结构化数据的中小型企业 | 基于桌面,图形界面 | 从$129起 |
| OutWit Hub | 中等易用性,需要一些技术知识 | 自动检测模式,提取图像、链接、文本和其他数据类型 | 需要灵活和可定制抓取的用户 | 基于桌面,浏览器扩展程序 | 从€95起 |
| ParseHub | 易于使用,所需设置最少 | 抓取动态网站,支持多种数据格式,适用于复杂的网站结构 | 抓取复杂或动态网站的用户 | 基于桌面,具有云选项 | 从$189/月起 |
| Content Grabber | 中等,但强大的功能需要学习 | 全自动化,支持抓取大型数据集,高级数据导出选项 | 抓取大量数据的机构和开发人员 | 基于桌面,强大的脚本支持 | 从$449到$2495 |
现在让我们深入细节,讨论这些工具以及一些网络爬取的基础知识。
什么是网络爬取?
网络爬取是使用自动化软件浏览和提取网站数据的过程。该软件,称为网络爬虫或蜘蛛,会遵循网站上的链接来收集文本、图像和其他内容等数据,以便进一步使用。
为什么网络爬取很重要?
网络爬取对于以下方面至关重要:
- 搜索引擎索引: 爬虫帮助像谷歌这样的搜索引擎索引网页,以获得更好的搜索结果。
- 市场调研: 企业使用爬虫来监控竞争对手的定价、产品细节和趋势。
- 数据收集: 它有助于收集大型数据集以进行分析、机器学习和洞察。
- 效率: 自动化数据收集,节省时间和资源。
如何爬取数据?
要爬取数据,请按照以下步骤操作:
选择目标网站: 确定要从中收集数据的网站。
设置爬虫: 使用工具或自定义脚本来自动化此过程。
提取数据: 定义所需的数据并配置爬虫。
存储数据: 以结构化格式保存提取的信息以进行分析。
网络爬取技术
网络爬虫使用各种技术,例如:
- HTML 解析: 从网页的 HTML 中提取数据。
- API 爬取: 使用 API 来检索结构化数据。
- 无头浏览器: Puppeteer 等工具有助于从依赖 JavaScript 的网站提取数据。
- 代理和验证码解决: 通过轮换 IP 和绕过安全措施来防止封锁。
什么是网络爬虫?
网络爬虫是一个旨在收集和复制网络数据的自动化程序。在几乎所有行业中,企业和组织最终都需要提取数据以用于各种用例。
但是,网络爬虫不仅仅是用于批量复制信息的简单程序。它们必须足够强大,能够从多个来源抓取数据,并智能地模拟人类行为,以确保在不被阻止的情况下提取数据。
为什么使用网络爬虫?
对于大规模数据提取而言,人工在线抓取是不切实际的。此外,自动化有助于设置严格的算法并避免歧义。与手动方法相比,使用网络爬虫具有以下优势:
- 更高的准确性:自动化爬虫确保数据一致地收集,而不会出现人为错误。
- 成本效益:降低与手动数据录入相关的成本。
- 对数据的控制:你可以专门定义需要提取哪些数据。
- 时间效率:网络爬虫可以节省提取过程中的大量时间,使大规模数据收集成为可能。
为了确保我们只推荐最有效的网络爬虫,我们进行了以下测试:
| 标准 | 详情 |
|---|---|
| 🎉 测试数量 | 10多个网络爬虫,包括开源和商业工具 |
| 👀 我们爬取了什么 | 电子商务网站、新闻门户、社交媒体平台和结构化数据库 |
| 😎 我们重视什么 | 价格、爬取速度、反检测功能、真实浏览器模拟、代理支持和易用性 |
1. Scrapeless ★★★
价格: 从$49/月起
最适合: 需要高级且高效的大规模网络抓取解决方案的企业和开发人员
Scrapeless是当今市场上最好的网络爬虫之一,它提供了一体化解决方案,用于处理反封锁措施,同时高效地从网站提取数据。
使用Scrapeless,你可以从各种各样的网站抓取数据,包括电子商务、市场调研和社交媒体平台。它擅长绕过验证码挑战,使用真实的浏览器模拟进行反检测,并管理其他爬虫通常难以处理的动态内容。
该工具的反封锁技术包括诸如丰富的代理IP池、快速验证码解锁和TLS指纹欺骗等功能,确保你的抓取活动不会被检测到,并且安全地避免IP被封。Scrapeless还以其从依赖JavaScript的页面抓取数据的能力而闻名,这使其成为现代复杂网站的理想选择。对于需要大规模数据提取而无需担心被检测到的企业来说,它是一个强大的解决方案。
更多优势:
- Scrapeless: 从**$49/月**起即可完全访问其网络抓取API。
- Google SERP API :Google SERP API定价低至每1000次查询$0.3,对于频繁搜索来说非常实惠。它还涵盖30多种搜索结果类型,例如AI结果、知识图谱、本地新闻、广告结果、Twitter结果等。
- Google Trends抓取API:在短短2秒钟内提供数据,可快速访问趋势数据。
如何使用Scrapeless抓取API抓取数据
使用Scrapeless抓取数据既简单又高效。你可以按照以下步骤开始:
-
注册一个帐户:访问Scrapeless网站并注册一个帐户。
-
为你的场景选择抓取API:你可以在左侧选择所需的抓取API。
或者你可以设置API集成将我们的工具集成到你的工作流程中,无论你使用的是Python、Node.js还是其他编程语言。你可以参考Scrapeless API文档。
- 设置抓取目标:选择要抓取的网站并配置所需的抓取设置。这里我们以Google Flights为例。
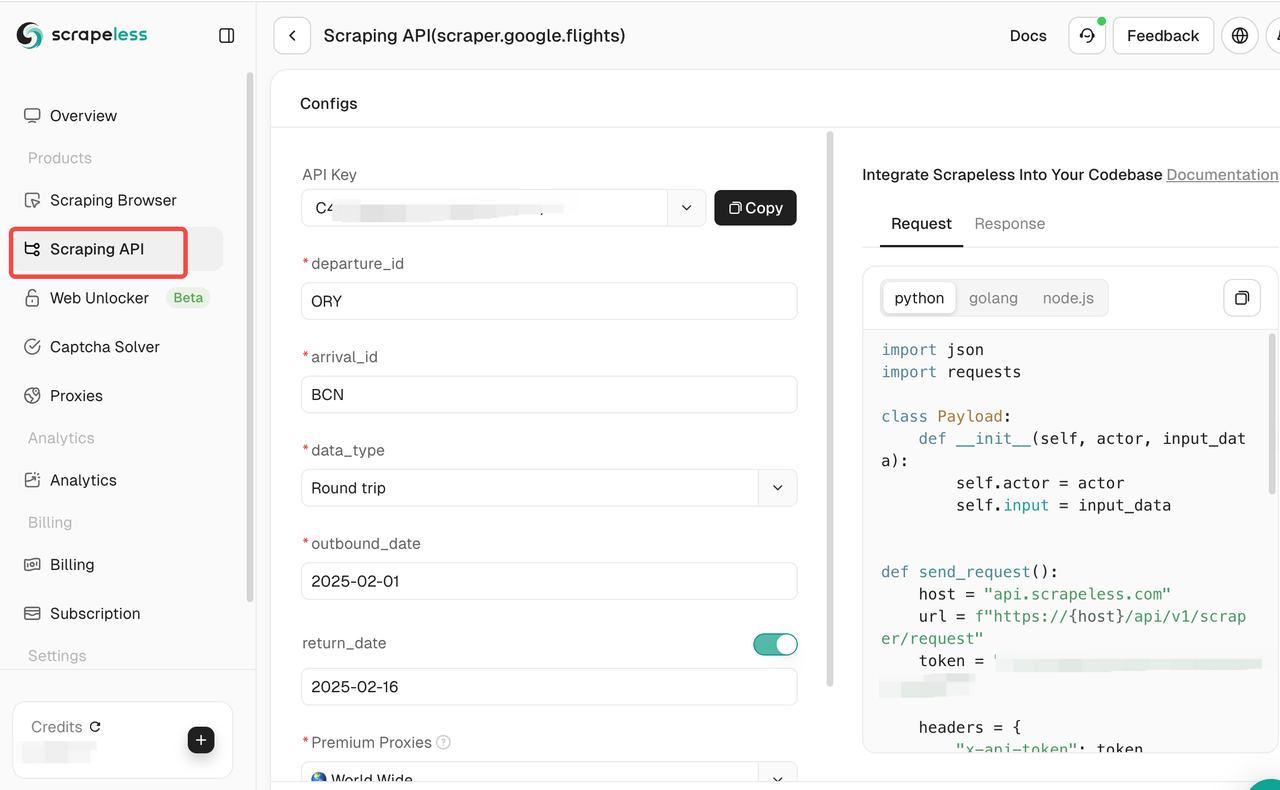
点击抓取API,然后选择Google Flight,并设置相应的抓取需求。
- 开始抓取:点击开始抓取开始抓取,抓取结果将显示在右侧。
2. WebHarvy
价格: 从$129起
最适合: 寻找简单点击式抓取解决方案的用户
WebHarvy是一款易于使用的网络爬虫,非常适合初学者。其可视化的点击式界面使抓取变得简单明了,无需编写任何代码。虽然它不像Scrapeless那样具有高级的反封锁功能,但它非常适合从电子商务网站和博客抓取产品数据。
优点:
- 易用性:用户友好的界面,无需编码知识
- 可视化点击式抓取:无需学习复杂的配置即可提取数据
- 适用于电子商务网站:非常适合提取产品列表、图像和价格
缺点:
- 反封锁功能有限:容易受到高流量网站上的抓取限制
- 可扩展性有限:在大规模、高频抓取项目中表现不佳
3. OutWit Hub
价格: 从€95起
最适合: 需要简单基于浏览器的抓取工具的初学者
OutWit Hub是一个基于浏览器扩展的网络爬虫,允许你抓取链接、电子邮件、图像等等。它非常适合初学者和小型抓取任务,但对于需要复杂抓取或处理依赖JavaScript的页面的高级用例来说可能不是最佳选择。
如果你也遇到了JS挑战,你可以点击查看本教程:如何绕过Cloudflare挑战
优点:
- 浏览器集成:易于安装并在浏览器中直接使用
- 易于使用的界面:非常适合没有编码经验的初学者
- 灵活性:允许抓取各种数据类型,如链接、图像和文本
缺点:
- 缺少高级功能:缺少处理动态内容或大容量抓取的支持
- 可扩展性有限:最适合轻量级抓取,而不是大型或复杂的项目
4. ParseHub
价格: 从$189/月起
最适合: 需要抓取动态内容的高级用户
ParseHub是一款高级网络爬虫,擅长抓取依赖JavaScript的网站。它提供了一套更强大的功能来处理复杂的网站,但高昂的价格和复杂性可能会让经验不足的用户望而却步。它提供了一个可视化界面,但比WebHarvy更复杂。
优点:
- 支持动态网站:非常适合抓取依赖JavaScript的网站
- 可视化界面:允许你创建抓取项目而无需编码
- 高级功能:提供计划和自动化抓取任务的选项
缺点:
- 定价:对于小型或休闲用户来说价格昂贵
- 学习曲线陡峭:对于初学者来说,更高级的功能可能令人不知所措
- 性能较慢:对于大型抓取任务来说,速度不如Scrapeless
5. Content Grabber
价格: 从$449到$2495
最适合: 企业级抓取解决方案
Content Grabber是一款功能丰富的网络爬虫,专为大规模网络抓取任务设计,尤其适合企业级用户。它非常适合跨多个网站抓取结构化数据,但高昂的价格和高级设置对于休闲用户来说可能过于复杂。
优点:
缺点:
- 成本高:对于小型企业或个人来说,价格可能过高
- 复杂性:需要时间和精力来有效地学习和设置
- 对于小型项目来说过于复杂:更适合大规模操作
关于网络爬虫的常见问题
1. 网络抓取和网络爬取有什么区别?
**回答:**虽然网络抓取和网络爬取都涉及从网络提取信息,但它们的目的不同。网络爬取主要关注跨多个网站发现和索引内容。搜索引擎使用它来规划网络结构。另一方面,网络抓取是指使用抓取工具从网站提取特定数据(例如产品详细信息、价格或联系信息)的行为。抓取通常更具针对性,旨在收集可操作的数据,而爬取是关于收集和索引网络上更大的数据集。
2. 网络抓取是如何工作的?
**回答:**网络抓取通过使用自动化软件或脚本(网络爬虫)从网站提取数据来工作。此过程包括向网站发送请求,检索HTML内容,并对其进行解析以提取有用的信息,例如文本、图像、链接等等。像Scrapeless这样的高级爬虫可以处理动态网站,绕过反抓取措施,并以各种格式导出数据以进行进一步分析。
3. 我可以使用网络爬虫来抓取动态网站吗?
**回答:**是的,许多现代网络爬虫,包括Scrapeless和ParseHub,都设计用于处理动态网站。这些爬虫可以渲染JavaScript并像真实的浏览器一样与网站交互,从而可以从动态加载内容的页面抓取数据。Scrapeless尤其提供了诸如反检测技术和快速数据提取等功能,确保动态内容能够准确高效地被抓取。
最终想法
总而言之,为2025年的数据抓取选择最佳的网络爬虫对于最大限度地提高效率至关重要。虽然像WebHarvy、OutWit Hub和ParseHub这样的工具都是不错的选择,但Scrapeless凭借其用户友好的界面、高级功能和具有竞争力的价格(每月仅需$49)占据了领先地位。此外,你可以免费试用Scrapeless来探索其功能。
不要错过加入Scrapeless Discord社区的机会,加入Scrapeless Discord并联系销售人员以申请免费试用!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


