
如何使用Scrapeless Web Unlocker解锁网站进行抓取?
Senior Web Scraping Engineer
网络爬取现已广泛用于数据分析和市场调研,当然也包括竞争对手分析。然而,我们不可避免地会遇到一些爬取障碍,例如IP封锁、复杂的JavaScript渲染和CAPTCHA验证。用户经常提出的一个关键问题是:爬取网站合法吗?
如何避免在执行自动化工作时被检测和封锁?
本文将向您展示最有效和省时的的方法。
立即开始阅读!
为什么我不断被网站封锁?
在深入探讨网络爬取技巧之前,首先,您需要了解在抓取网络数据时可能遇到的常见反机器人措施。
如果您总是遇到网络封锁,请检查以下8个方面:
1️⃣ 来自同一IP的请求过多
网站会监控流量模式,并可能封锁在短时间内发出过多请求的IP地址。这通常是为了防止爬取和滥用。
2️⃣ IP黑名单
如果您的爬取活动被标记为可疑,网站可能会将您的IP列入黑名单。如果您反复从同一IP地址访问站点或使用类似机器人的可识别行为模式,则可能会发生这种情况。
3️⃣ 使用验证码
许多网站使用CAPTCHA验证码来区分人类用户和机器人。如果您的爬虫触发了CAPTCHA验证码挑战,它可能会被封锁,直到验证码被解决。
4️⃣ JavaScript渲染
具有复杂JavaScript的网站可能会隐藏或动态生成内容。传统的爬取方法难以应对这种情况,导致爬取不完整或失败。
这是网站封锁您的爬虫最基本的原因。如何克服JS渲染挑战?别担心,稍后我们可以解决这个问题。
5️⃣ 用户代理检测
网站通常会检查“User-Agent”字符串,以查看请求是否来自真实的浏览器或机器人。没有正确模拟真实浏览器的爬取工具可能会被检测到并被封锁。
6️⃣ 速率限制和会话过期
网站可能会限制您在特定时间段内可以发出的请求数量,并且您的会话可能会在特定数量的操作后过期。反复访问网站可能会导致临时或永久封锁。
7️⃣ 指纹识别
现代网站使用浏览器指纹识别技术来检测自动爬取。此方法会跟踪独特的模式,例如屏幕分辨率、时区和其他浏览器特性,使网站更容易识别和封锁爬取工具。
8️⃣ 地理位置封锁
某些网站会根据IP地址的地理位置限制访问。如果您从不允许访问的地区进行爬取,可能会遇到封锁。
Scrapeless Web Unlocker - 最佳网站爬取解决方案
Scrapeless 不仅是领先的网站解锁工具,也是全面的网络爬取解决方案。
作为一个强大的网站解锁工具,Scrapeless 为用户提供简化高效的HTML提取服务。凭借其先进的代理选择技术和自动解锁机制,Scrapeless 可以轻松绕过复杂的反爬虫保护,帮助用户快速获取所需数据。
为什么选择Scrapeless Web Unlocker?
⚙️ 高效的JavaScript渲染 (JSRender)
Scrapeless 的 JSRender 技术使用先进的浏览器模拟渲染引擎,可以实时处理网页中的动态内容加载。它特别适合需要JavaScript生成内容的现代网站,例如动态页面、单页面应用程序 (SPA) 等。
与传统的爬虫工具相比,Scrapeless 的 JSRender 可以短时间内渲染JavaScript生成的复杂数据,这对于爬取需要交互或动态更新的内容(例如电商网站上的产品详情页)非常重要。例如,在从Shopee、亚马逊和Lazada抓取产品页面时,Scrapeless可以加载并提取所有动态数据(例如价格、库存、评论等),而不会错过任何重要信息。
🧩 绕过IP封禁
Scrapeless 提供内置的智能代理池,可以自动切换IP以确保稳定的访问体验。代理池智能选择高质量的IP资源,即使在大规模爬取中,也能有效绕过网站的IP封锁和限制,确保爬取任务顺利进行。
用户无需进行任何额外配置。我们确保最高程度的自动化,节省大量的开发时间和精力。用户可以专注于业务逻辑,而无需担心IP封锁。
⚔️ 自动验证码求解器
Scrapeless 具有集成的验证码求解器,能够处理图片验证码、文本验证码和Google reCAPTCHA挑战。这确保了不间断的爬取会话,无需人工干预。
对于那些想知道爬取网站是否合法的人——答案取决于网站的服务条款和数据收集的性质。虽然公开信息通常是公平的游戏,但在进行网络爬取时,应始终考虑伦理和法律因素。
Scrapeless 通过自动化绕过机制简化了流程,使企业和开发人员能够专注于高效地提取有价值的见解。
如何使用Scrapeless Web Unlocker?
- 步骤1。登录Scrapeless。
- 步骤2。进入“Web Unlocker”。
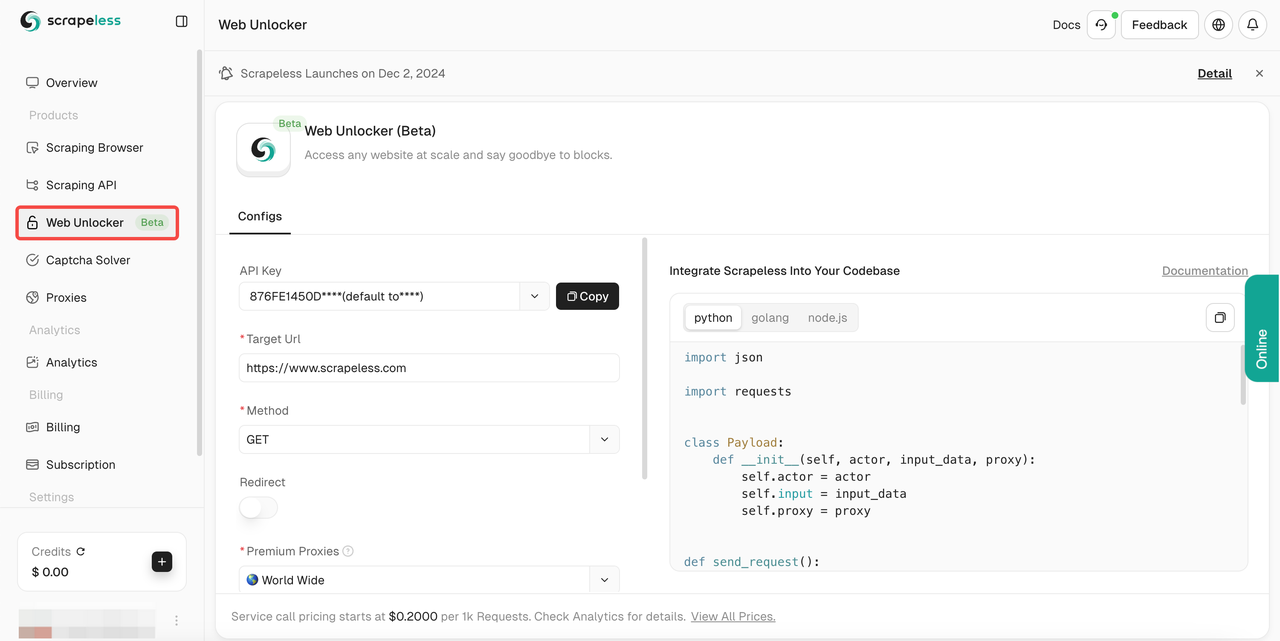
- 步骤3。根据您的需求配置左侧的操作面板:
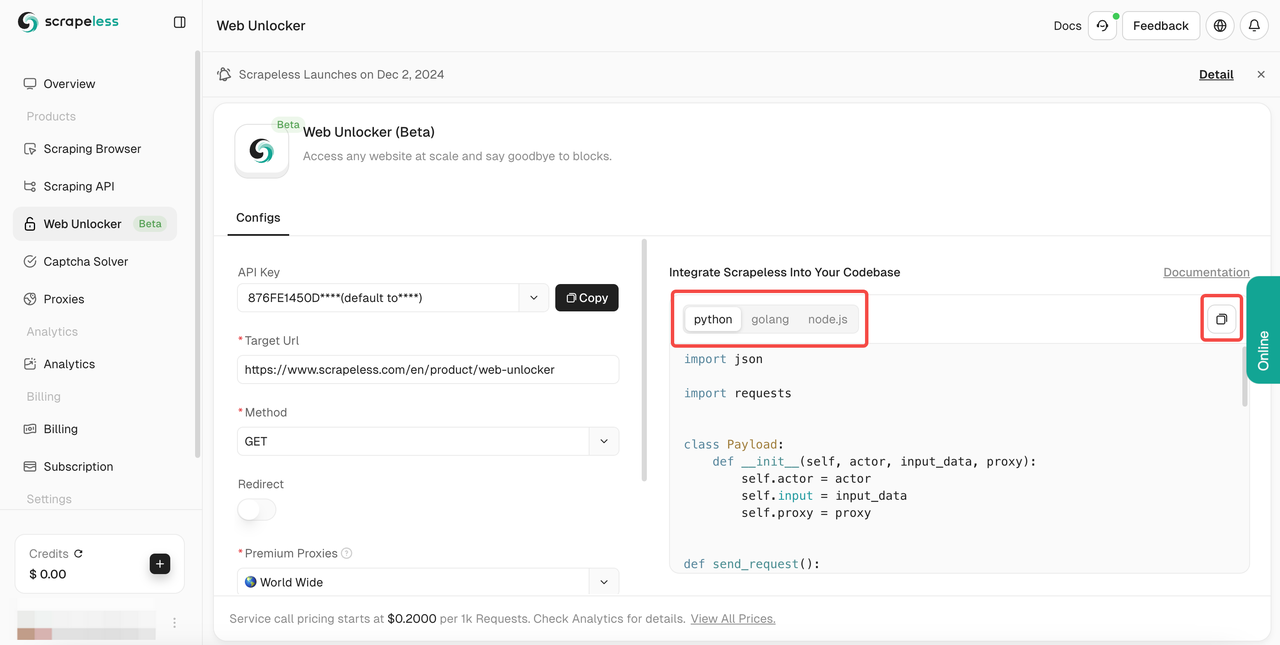
- 步骤4。填写您的
目标网址后,Scrapeless将自动为您抓取内容。您可以在右侧的结果显示框中查看抓取结果。请选择您需要的语言:Python、Golang或node.js,最后点击右上角的logo复制结果。
这确保您可以不间断地访问任何公共网站。它支持各种爬取方法,擅长渲染JavaScript,并实现了反爬虫技术,为您提供有效浏览网页的工具。
或者您可以使用我们下面的示例代码有效地集成到您自己的项目中:
- Url: 目标网站
- Method: 请求方法
- Redirect: 是否允许重定向
- Headers: 自定义请求头字段
Python:
Python
import requests
import json
url = "https://api.scrapeless.com/api/v1/unlocker/request"
payload = json.dumps({
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": False,
"method": "GET",
"request_id": "",
"extractor": ""
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)JavaScript:
JavaScript
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify({
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": false,
"method": "GET",
"request_id": "",
"extractor": ""
}
});
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
redirect: 'follow'
};
fetch("https://api.scrapeless.com/api/v1/unlocker/request", requestOptions)
.then(response => response.text())
.then(result => console.log(result))
.catch(error => console.log('error', error));Go
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/unlocker/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://httpbin.io/get",
"proxy_country": "US",
"type": "",
"redirect": false,
"method": "GET",
"request_id": "",
"extractor": ""
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}避免被封锁的其他解决方案
1. IP轮换
网站检测网络爬虫的第一种方法是检查其IP地址并跟踪其与网站的交互。如果服务器看到来自“该用户”的奇怪行为模式或不可能的请求频率,服务器可以阻止该IP地址再次访问网站。
为了避免通过相同的IP地址发送所有请求,您可以使用IP轮换服务(如Scrapeless的旋转住宅代理)通过代理池路由您的请求,在爬取网站时隐藏您的真实IP地址。这将使您能够爬取大多数网站而不会被封锁。
为什么要使用住宅代理?因为在一些具有更严格封锁要求的网站上,它们会对您的代理检测更加严格。选择住宅代理将使您的爬虫身份更真实,使您的网站爬取工作更稳定。
最终,使用IP轮换,您的爬虫可以使请求看起来像是来自不同的用户,并模拟在线流量的正常行为。
使用Scrapeless代理时,我们的智能IP轮换系统将利用多年的统计分析和机器学习,根据需要从数据中心、住宅和移动代理池中轮换您的代理,以确保99.99%的成功率。
2. 使用无头浏览器
最难爬取的网站可能会检测到诸如网络字体、扩展程序、浏览器cookie和JavaScript执行等细微迹象,以确定请求是否来自真实用户。
要爬取这些网站,您可能需要部署您自己的无头浏览器(或让Scrapeless Scraping Browser为您完成此操作!)。
无头浏览器允许您编写一个程序来控制一个与真实用户使用的浏览器相同的真实浏览器,以完全避免检测。
3. 验证码求解器提供商
验证码求解器是我们经常使用的第三方服务。它们通过使用光学字符识别 (OCR)、机器学习或第三方人工求解器等技术来自动免费解决验证码难题,允许爬虫绕过网络封锁。
这些工具通过防止由验证码验证造成的干扰,使持续的、自动化的网站爬取活动成为可能。通过模拟类似人类的行为或实时解决验证码,它们有助于避免被检测为机器人,并保持平稳的爬取过程。
但是,重要的是要考虑使用此类工具的伦理和法律影响,因为它们可能会违反网站的服务条款和隐私政策。爬取网站是否合法?这取决于司法管辖区和网站的条款。始终确保遵守当地法律法规。此外,这些工具通常价格也更高。
4. 设置真实的用户代理
设置真实的用户代理是避免在网站爬取活动中被检测到的常用方法。网站经常使用请求中的User-Agent标题来识别它们是否来自真实用户的浏览器或自动化机器人。通过伪造或随机化User-Agent,爬取脚本可以看起来像是来自普通用户,从而减少被检测到的机会。
如何实现它:
- 伪造真实浏览器的用户代理
使用常见的浏览器User-Agent字符串(如Chrome、Firefox、Safari等)来模拟真实用户的行为。例如,在Python中,您可以使用requests库设置典型的浏览器User-Agent标题:
Python
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get('https://example.com', headers=headers)- 动态轮换用户代理
通过使用代理池或API(例如random-user-agent)来轮换不同的User-Agent字符串以避免检测。这使得网站更难以根据单个User-Agent识别爬取模式。
5. 组合其他Headers
除了User-Agent之外,您还可以伪造其他Headers(如Referer、Accept-Language等)以进一步模拟真实浏览器的请求。
通常,最好让它看起来像是从Google访问的。
您可以使用以下标题来实现此目的:"Referer": "https://www.google.com/"
这可以使网站更难以区分自动化请求和真实用户的交互。
6. 在爬取请求之间设置随机间隔
网站通常会根据请求的频率和规律性来检测爬取活动。如果请求来得太快或以可预测的模式出现,网站更容易识别和阻止爬虫。通过在请求之间引入随机延迟,您可以使您的爬取行为看起来更自然。
您可以使用Python中的time.sleep()函数在请求之间引入延迟。通过设置随机间隔,您可以改变每次请求之间的时间,以使行为不那么可预测。
Python
import time
import random
import requests
# 发送带有1到3秒随机延迟的请求
headers = {'User-Agent': 'Mozilla/5.0'}
url = 'https://example.com'
for i in range(10):
response = requests.get(url, headers=headers)
print(f"Request {i+1} Status: {response.status_code}")
time.sleep(random.uniform(1, 3)) # 1到3秒之间的随机睡眠7. 避免蜜罐陷阱
许多网站使用隐形链接来检测网络爬虫,因为只有机器人才会跟踪它们。
为了避免检测,您应该检查链接是否具有CSS属性"display: none"或"visibility: hidden."。如果设置了其中任何一个,请不要访问该链接!否则可能会导致您的爬虫被检测到,允许服务器识别您的请求属性并阻止您。
蜜罐是网站用来发现爬虫的常用方法,因此请确保对您抓取的每个页面执行此检查。
此外,一些高级网站管理员也可能会将链接颜色设置为白色(或与背景颜色匹配),因此值得检查诸如"color: #fff;"或"color: #ffffff"之类的属性,以确保链接保持不可见。
8. 删除Google缓存
为了避免在爬取时被阻止,重要的是要清除或绕过Google的缓存,因为它可能会存储您之前的交互,并帮助网站检测可疑的爬取活动。以下是处理Google缓存的一些策略:
Puppeteer: 使用Puppeteer中的clearBrowserCookies()和clearBrowserCache()函数来清除:
JavaScript
cookies和缓存在爬取会话之间。
const browser = await puppeteer.launch();
const page = await browser.newPage();
// 清除缓存和cookies
await page.clearBrowserCache();
await page.clearBrowserCookies();是时候让爬取变得简单高效了!
Scrapeless Web Unlocker是一个强大的工具,它集成了智能代理池、高效的JavaScript渲染 (JSRender) 和自动CAPTCHA处理,旨在解决网站爬取中的常见问题。Scrapeless使复杂的爬取任务变得简单、高效和可靠。
如果您想突破爬取的局限性并提高效率,无论是处理复杂的动态页面还是大规模爬取任务,Scrapeless Web Unlocker都是您值得信赖的解决方案。
立即免费开始使用Scrapeless体验无与伦比的爬取性能,让您的数据收集更轻松!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


