
如何使用Python抓取Lazada产品数据?
Specialist in Anti-Bot Strategies
什么是Lazada产品抓取?
Lazada是一个在线市场,不同的商家在上面销售商品,抓取这些数据对各种应用都很有益处,包括价格监控、市场调研、库存管理和竞争分析。
Lazada提供各种功能,例如安全的支付选项、客户评论和送货系统,方便客户购买和送货上门。
Lazada网页抓取是使用自动化工具或脚本从Lazada网站获取数据的过程。
抓取是从Lazada网页获取特定信息的做法,例如产品详情(如名称、价格、描述和照片)、卖家信息、用户评论和评分。但是,必须记住,在线抓取可能会涉及法律问题,一些网站的服务条款限制未经许可抓取其数据。
为什么需要Lazada网页爬取?
- 价格监控和比较。爬取Lazada上的产品数据可以帮助企业或消费者跟踪价格波动,分析类似产品的价格趋势,并找到最佳购买时机。
- 市场分析。企业可以通过爬取Lazada的数据,获取市场动态,例如畅销产品、用户评论、产品排名等。这有助于优化销售策略,预测市场需求,制定更准确的营销计划。
- 产品信息收集。对于需要管理大规模产品目录的电商公司或代理商来说,爬取Lazada的产品数据(例如产品名称、描述、价格、库存信息等)可以加快录入和更新产品数据,提高效率。
- 竞争对手分析。通过爬取竞争对手在Lazada上的产品列表、定价策略和促销活动,企业可以洞察竞争对手的市场定位,制定更有竞争力的商业计划。
- 评论和评分分析。用户评论和评分是消费者决策的重要依据。通过爬取这些信息,企业可以分析消费者对产品的反馈,从而改进产品或服务,提升用户体验。
- 构建产品价格比较平台。一些初创公司或技术平台需要爬取Lazada的数据来构建价格比较网站或应用程序,让用户可以轻松比较不同平台上的价格和折扣信息。
- 自动化库存管理。对于商家来说,爬取Lazada的数据可以自动检查某些产品的库存或价格是否发生变化,从而及时调整其产品策略。
- 探索商业机会。爬取Lazada的热销产品和未开发的产品领域,有助于发现潜在的商业机会,开辟新的业务方向。
为什么选择Python语言爬取Lazada数据?
- 强大的爬虫生态系统
Python拥有丰富的爬虫相关库和框架,例如:
requests:简单易用,适合发送HTTP请求获取静态网页数据。BeautifulSoup:轻量级的HTML解析库,方便提取网页内容。Scrapy:强大的爬虫框架,支持高效的分布式爬取和数据管理。Selenium:用于处理动态网页内容,支持自动化浏览器操作。
这些工具可以轻松适应Lazada网页爬取的不同场景。
- 丰富的数处理能力
Python提供强大的数据处理和分析工具,例如:
pandas:高效的数据表格操作工具,方便存储和处理爬取的数据。csv和json:内置支持常见的数据存储格式,方便输出结果。NumPy和matplotlib:强大的数据统计和可视化工具。
这些工具使得从数据爬取到分析都能一站式完成。
- 动态网页处理能力
对于Lazada动态加载的内容,Python结合Selenium和Playwright等工具可以模拟真实用户行为,绕过JavaScript渲染的限制。此外,结合云浏览器服务(例如Browserless),可以进一步提高动态网页处理的效率。
- 高度可扩展性
Python具有良好的可扩展性,可以轻松集成代理池管理工具(例如proxy-rotator)、验证码解决工具(例如anticaptcha)和数据存储服务(例如MySQL和MongoDB),满足大规模爬取的需求。
是否有简单的方法来抓取Lazada产品?
构建你的Python Lazada爬虫总是需要绕过被封禁的问题,这似乎很头疼。幸运的是,这里有一个简单易用的方法来轻松抓取Lazada产品!
Scrapeless——最好的Lazada抓取API
Scrapeless是一个先进的网页抓取平台,专为需要准确、安全和可扩展的数据提取的企业和开发者而设计。它提供高级解决方案,简化从各种来源(包括Lazada和亚马逊等电商平台)收集数据的过程。
凭借其强大的设计,Scrapeless使您无需构建和维护自己的抓取工具,并可以轻松应对验证码解决、反机器人系统和IP轮换等复杂挑战。无论您是想收集产品详情、价格趋势还是客户评论,Scrapeless都提供可靠且高效的方式来满足您的数据需求。
如何部署Scrapeless Lazada抓取API?
- 步骤1。登录Scrapeless。
- 步骤2。点击“Scraping API”
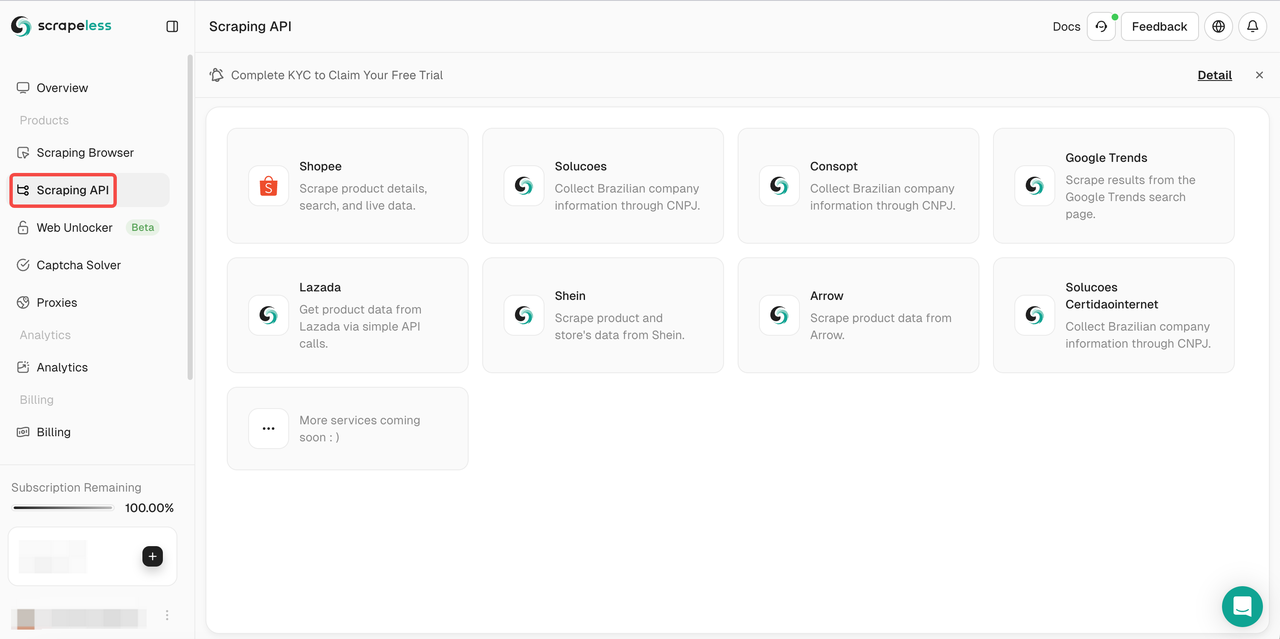
- 步骤3。选择Lazada并输入Lazada抓取页面。
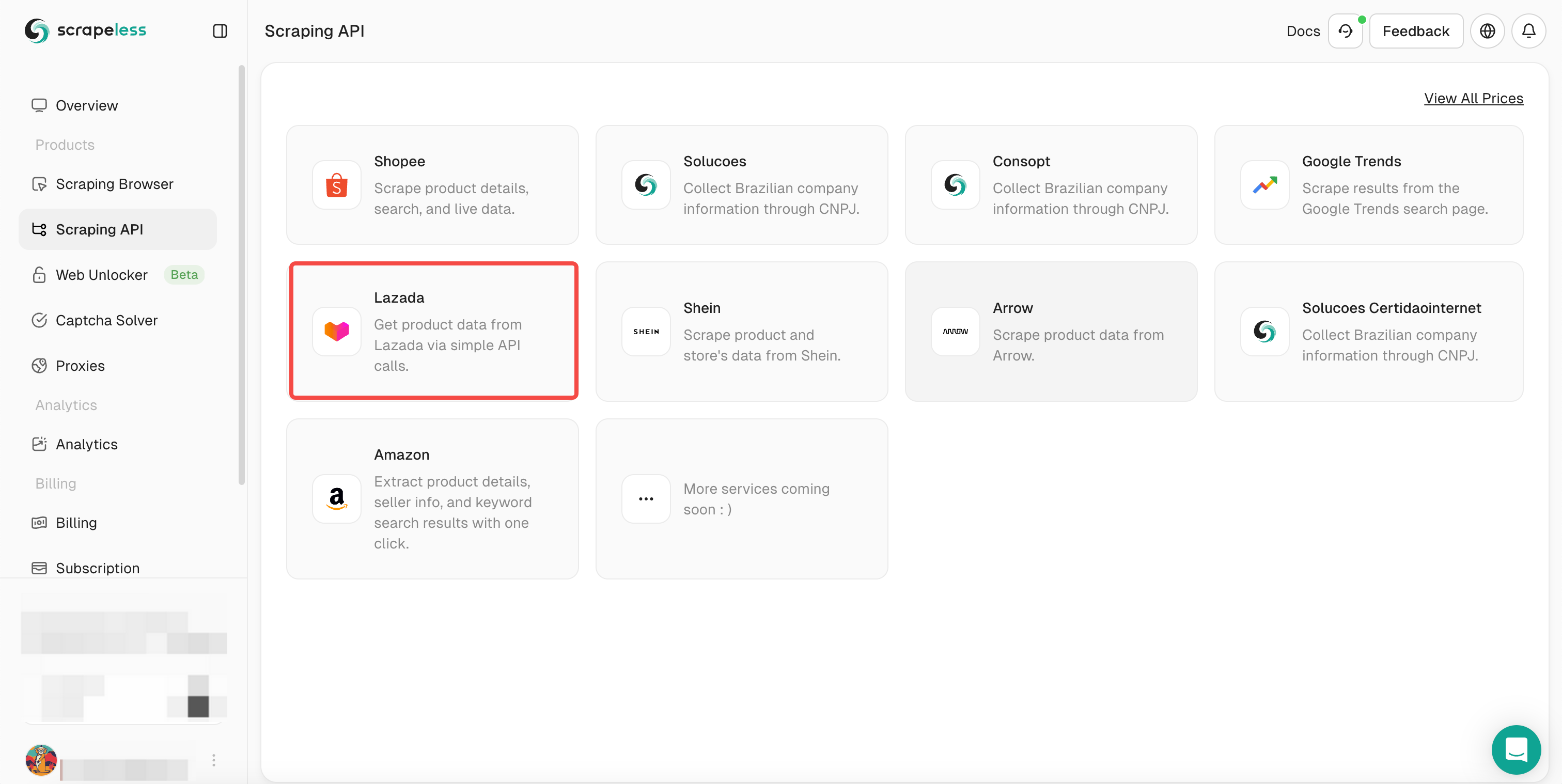
- 步骤4。下拉Action List并选择要爬取的数据条件设置。然后点击Start Scraping。
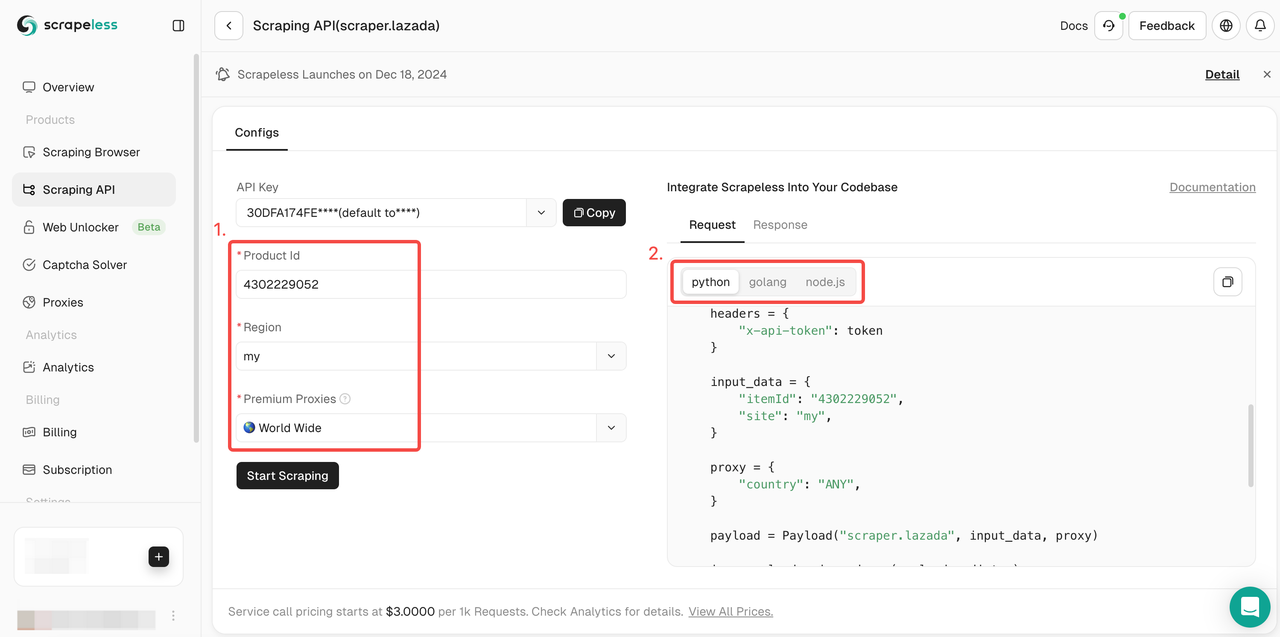
- 步骤5。抓取将在几秒钟内成功完成。相应的结构化数据将显示在右侧。
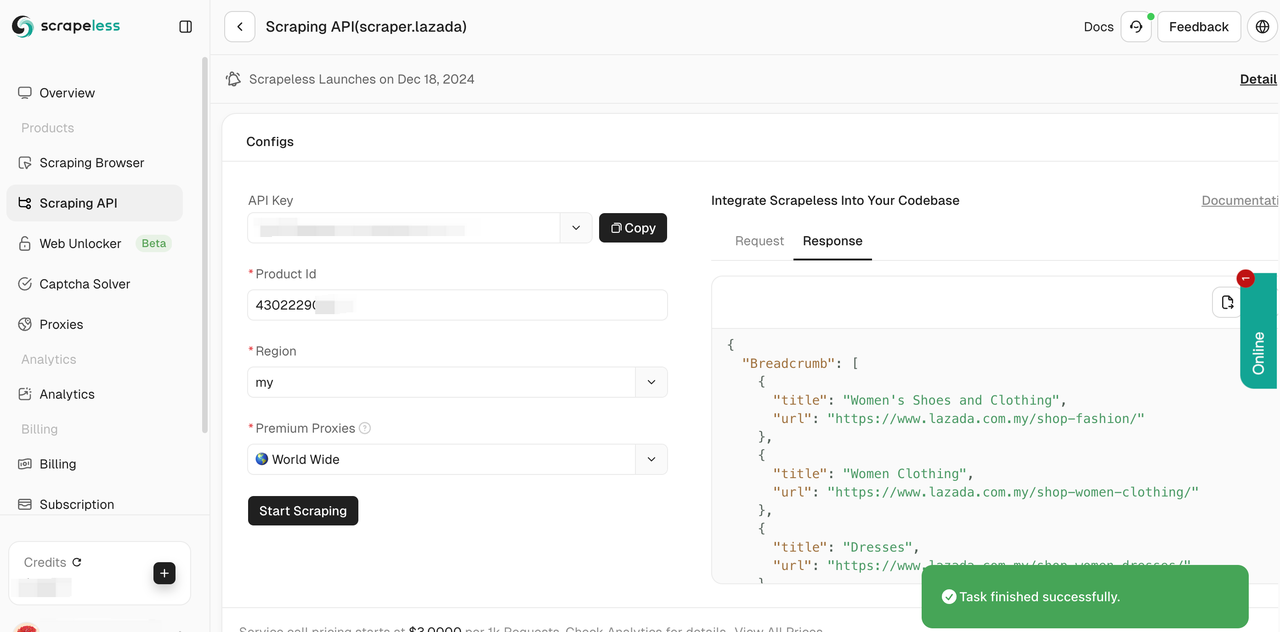
您还可以将我们的参考代码集成到您的项目中并部署大规模数据抓取。这里我们以Python为例。您也可以在我们的客户端中使用Golong和NodeJS。
- Python:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #你的API令牌
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #输入产品ID
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()如何使用Python提取Lazada产品数据?
步骤1:设置环境
安装所需的Python库。您主要需要requests来发送HTTP请求和BeautifulSoup来解析HTML。如果站点使用动态内容,您可以使用Selenium或Browserless等云浏览器服务。使用以下命令安装必要的库:
bash
pip install requests beautifulsoup4 selenium步骤2:检查Lazada网站
在浏览器中打开Lazada,找到要抓取的页面(例如,产品列表或搜索结果)。使用开发者工具(F12)检查页面结构,并确定产品数据(如名称、价格和链接)的标签和类。
步骤3:发送HTTP请求
对于静态页面,使用requests库发送GET请求。包含诸如User-Agent之类的标头以模拟真实的浏览器。
python
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
url = 'https://www.lazada.com.my/shop-mobiles/'
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
else:
print(f" ")步骤4:解析HTML内容
使用BeautifulSoup通过识别合适的HTML标签和类来提取产品信息。
python
products = soup.find_all('div', class_='c16H9d') # 用实际的类名替换
for product in products:
name = product.text
print(f"Product Name: {name}")步骤5:处理动态内容
如果页面内容使用JavaScript动态加载,请使用Selenium或云浏览器来呈现完整内容。
python
from selenium import webdriver
driver = webdriver.Chrome() # 确保已安装ChromeDriver
driver.get('https://www.lazada.com.my/shop-mobiles/')
# 等待内容加载并抓取
elements = driver.find_elements_by_class_name('c16H9d')
for element in elements:
print(f"Product Name: {element.text}")
driver.quit()步骤6:管理反机器人措施
Lazada可能会使用技术来阻止机器人。使用以下策略来绕过检测:
- 代理轮换:使用轮换代理来避免IP封禁。
- User-Agent欺骗:随机化标头中的User-Agent。
- 云浏览器:Browserless之类的服务可以帮助绕过高级检测系统。
步骤7:存储数据
将抓取的数据保存到CSV文件或数据库中以备将来使用。
python
import csv
with open('lazada_products.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Product Name', 'Price', 'URL']) # 示例标题
# 在此处添加产品详细信息总结
抓取Lazada产品数据为电商领域的企业提供了重要的机会。获取的数据是市场调研、竞争对手分析、价格优化以及其他各种数据驱动战略举措的宝贵资源。
Scrapeless抓取API使Lazada产品抓取变得简单高效。通过绕过验证码和智能IP轮换,您可以避免网站封锁并轻松实现数据抓取。
进一步阅读:
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


