无刮削游乐场上线 - 用于抓取浏览器的视觉控制!
Advanced Data Extraction Specialist
为进一步提升开发者使用Scrapeless Scraping Browser进行网页抓取和浏览器自动化的体验,我们很高兴地宣布Scrapeless Playground的正式上线!
现在,你可以将Scraping Browser的强大功能与一个完全可视化、互动的Playground界面结合起来。
我们为什么建立Playground?
Scrapeless Scraping Browser已经提供了一个强大且稳定的自动化环境,支持JavaScript渲染、动态内容处理、自定义指纹等更多功能。
然而,我们听到了一些用户的反复请求:
“我真的可以看到浏览器如何运行我的任务吗?”
“我想快速测试脚本,而不必每次都部署它们。”
这正是我们构建Playground的原因:
- ✅ 可重用且稳定的抓取/浏览器脚本
- ✅ 一个可视化、互动的浏览器环境,你可以看到、控制和重放
✨ 此次更新的亮点
1. 全新Playground界面
借助此更新,用户现在可以直接在Playground界面中使用Scraping Browser服务。Playground被分为两个主要部分:
- 代码面板(左侧):编写和修改你的自动化脚本。
- 实时浏览器预览(右侧):在脚本运行时即时查看浏览器行为。它还支持手动点击和交互,以便于实时调试。
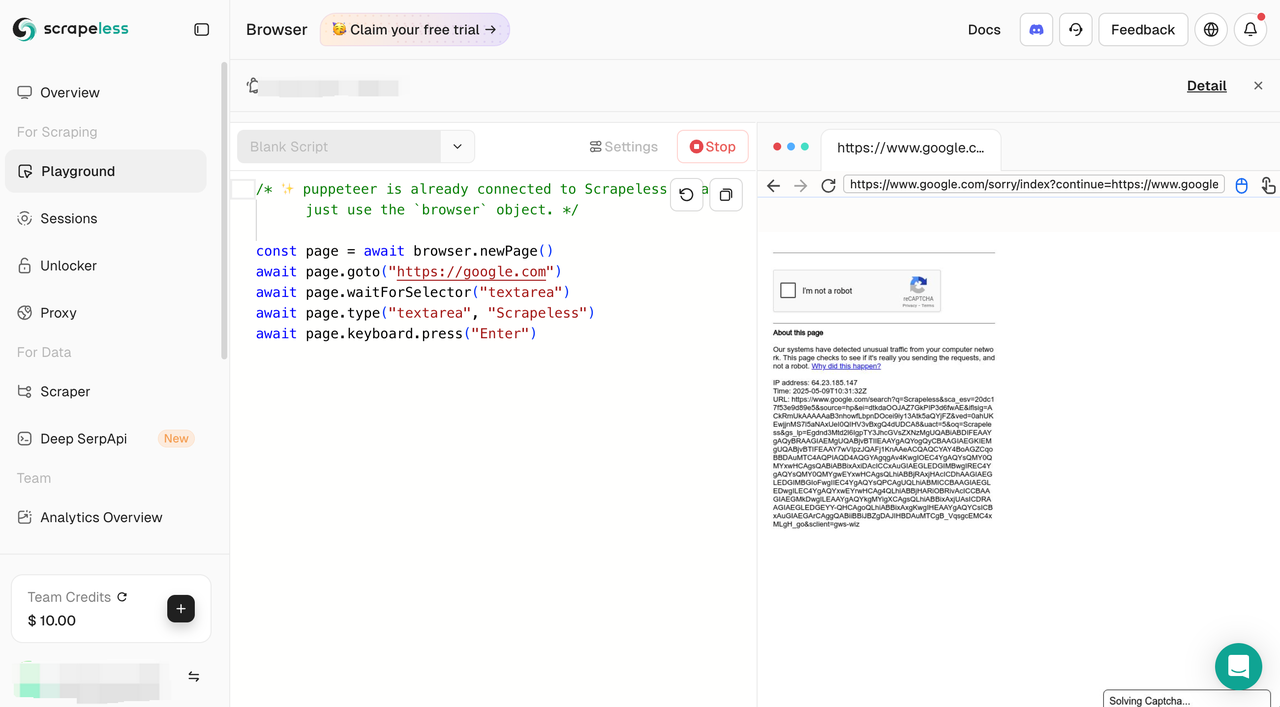
当没有脚本运行时,仅显示代码面板。一旦执行开始,预览面板会被激活—为开发和调试提供无缝、有效的环境。
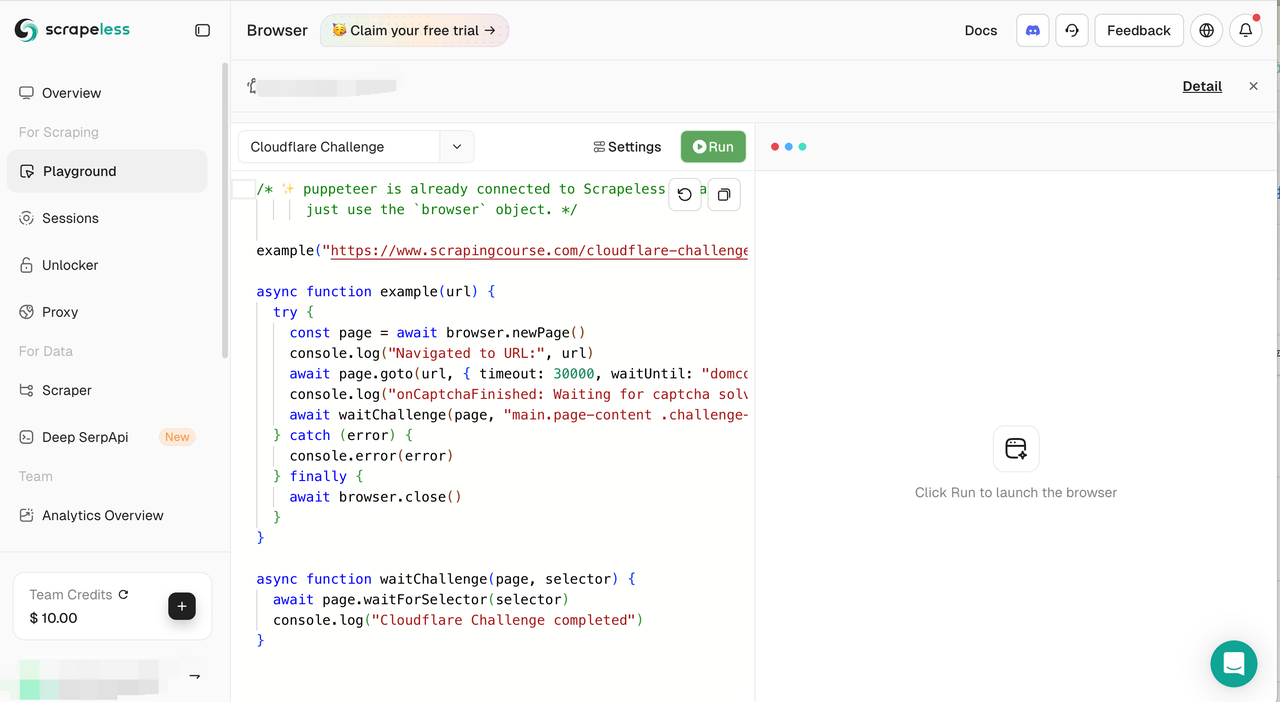
2. 常见场景的案例选择器
在Playground中,我们新增了一个浏览器案例功能,帮助你更快上手。你现在可以:
- 从下拉菜单中快速选择内置用例(例如,生成PDF、自动登录等)。
- 自动加载每个案例的示例代码,准备立即测试。
- 默认从空白脚本开始,以进行全面的自定义。
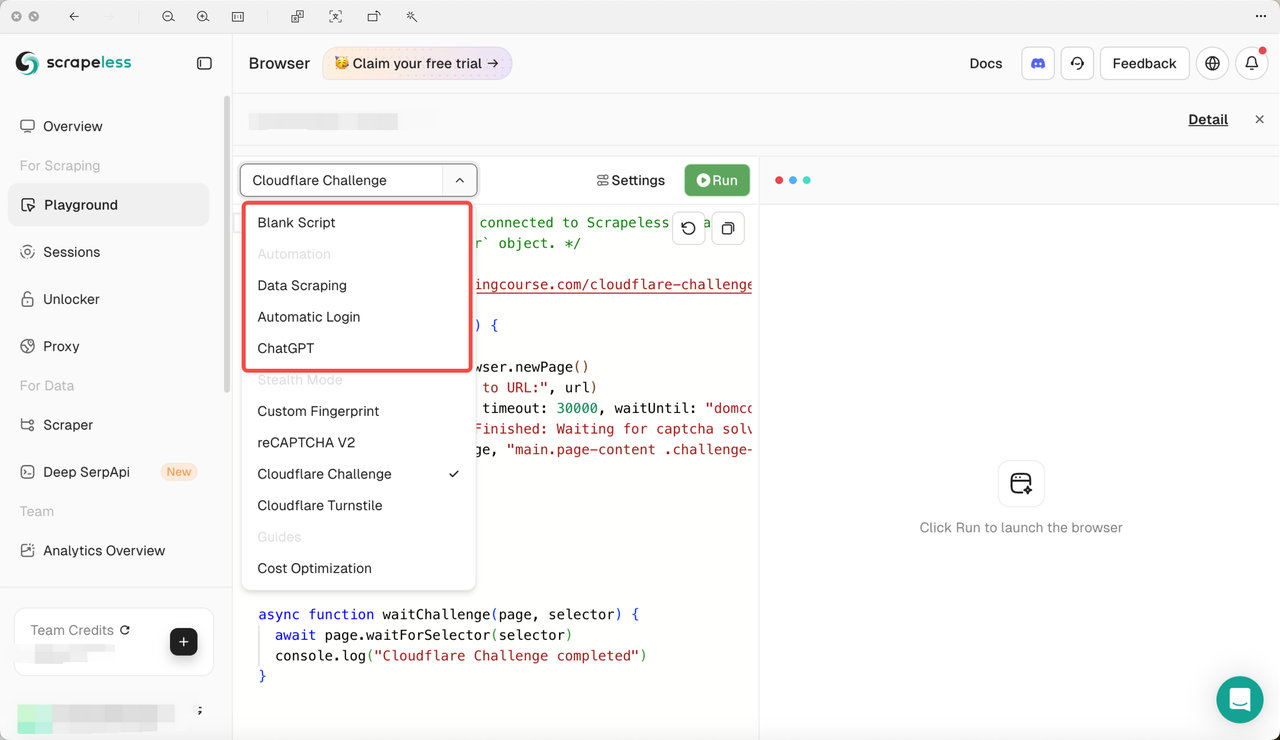
Scrapeless Scraping Browser目前支持多种高级功能,包括:
自定义指纹、reCAPTCHA v2、Cloudflare挑战和Cloudflare Turnstile。
当前在Playground中支持的案例包括:
数据抓取、自动登录和ChatGPT集成。
示例:处理Cloudflare挑战
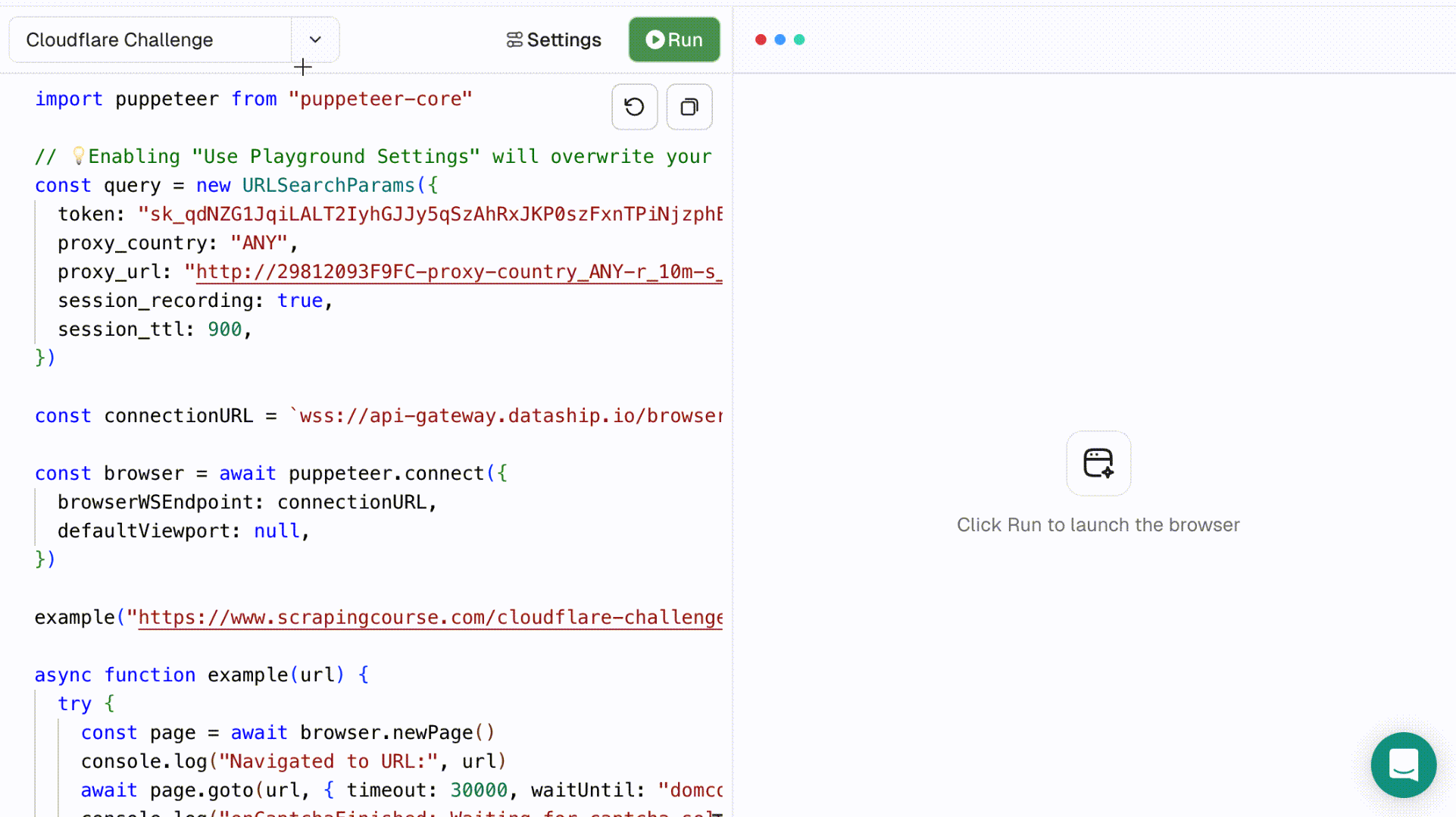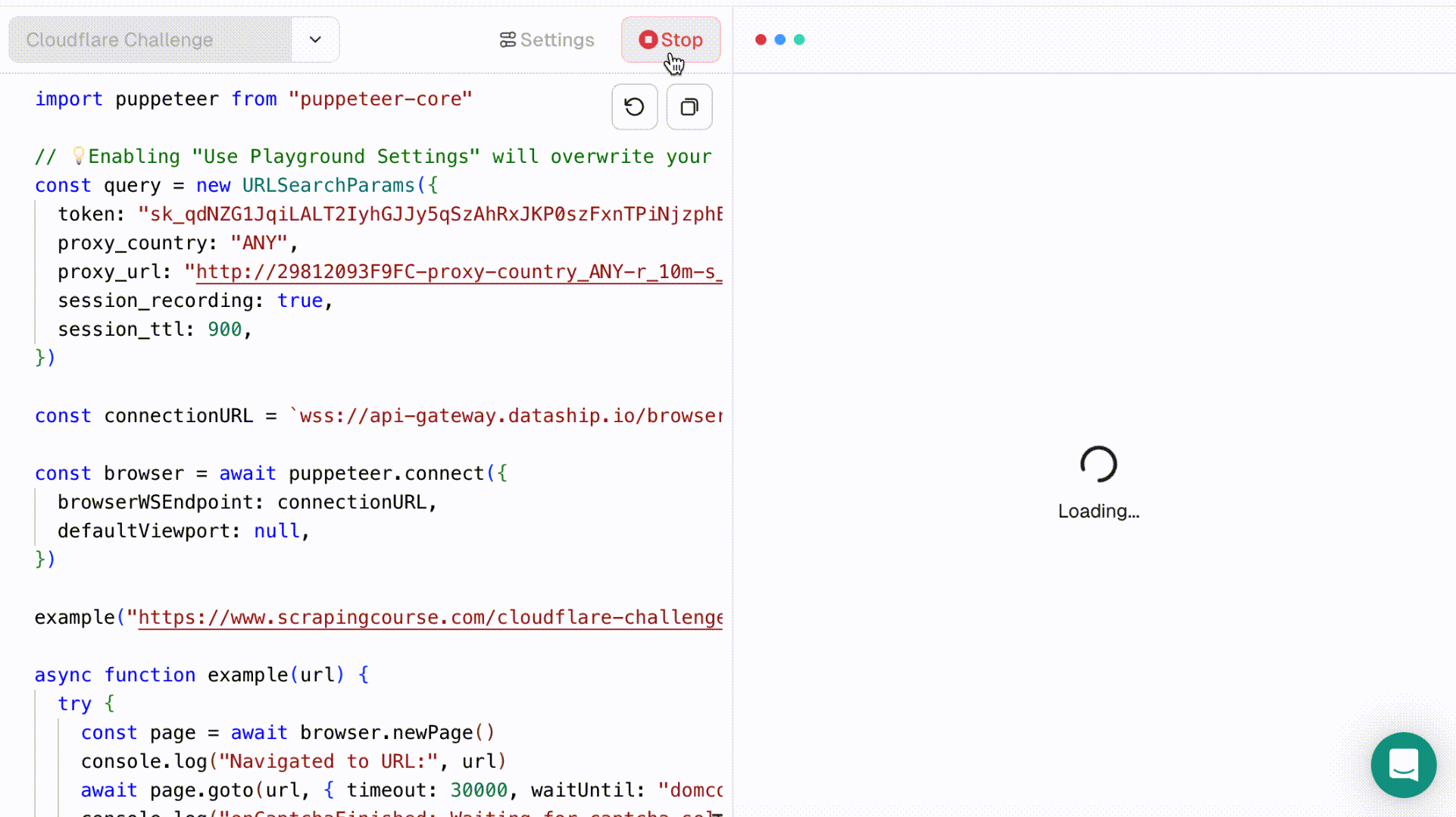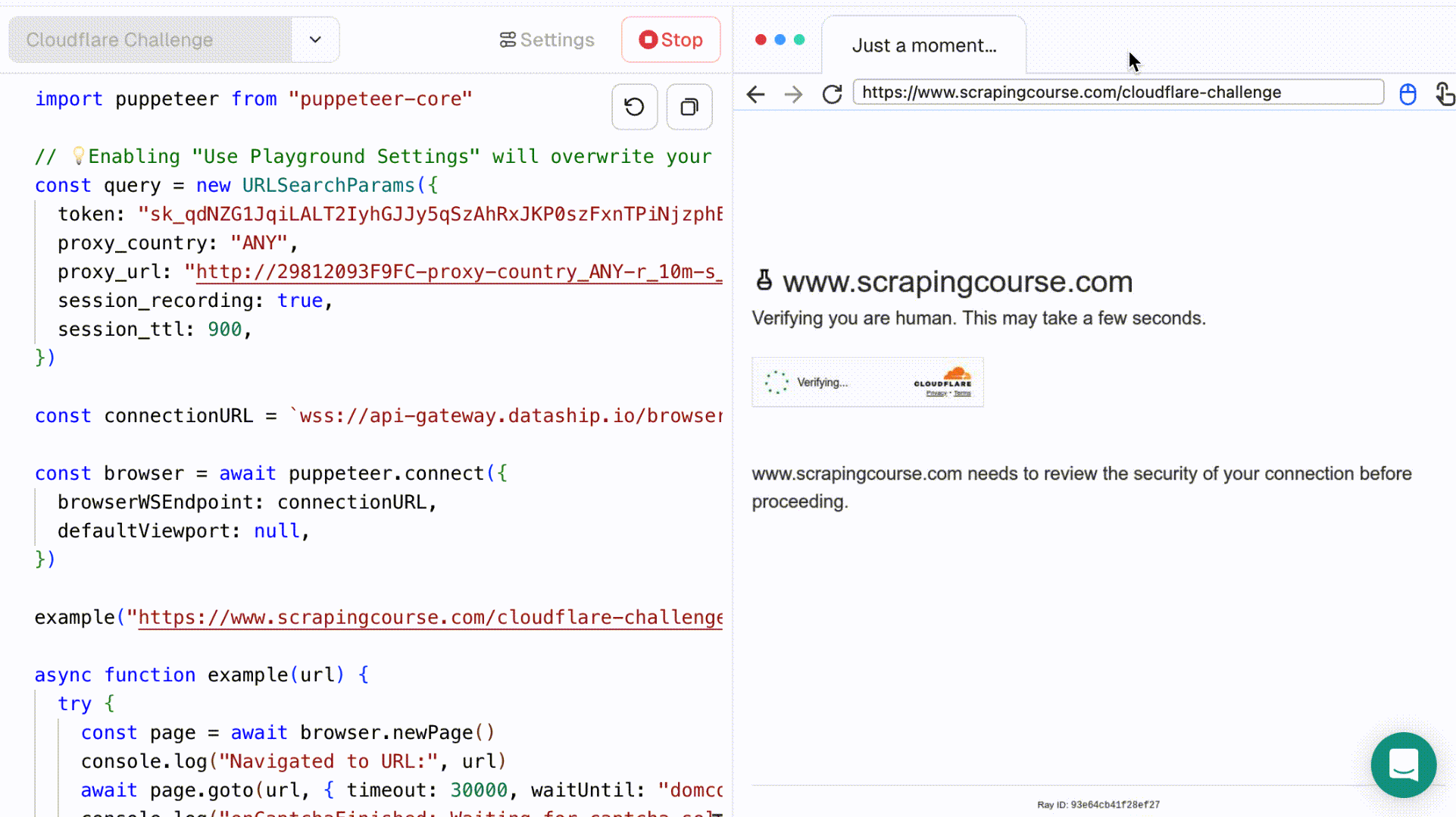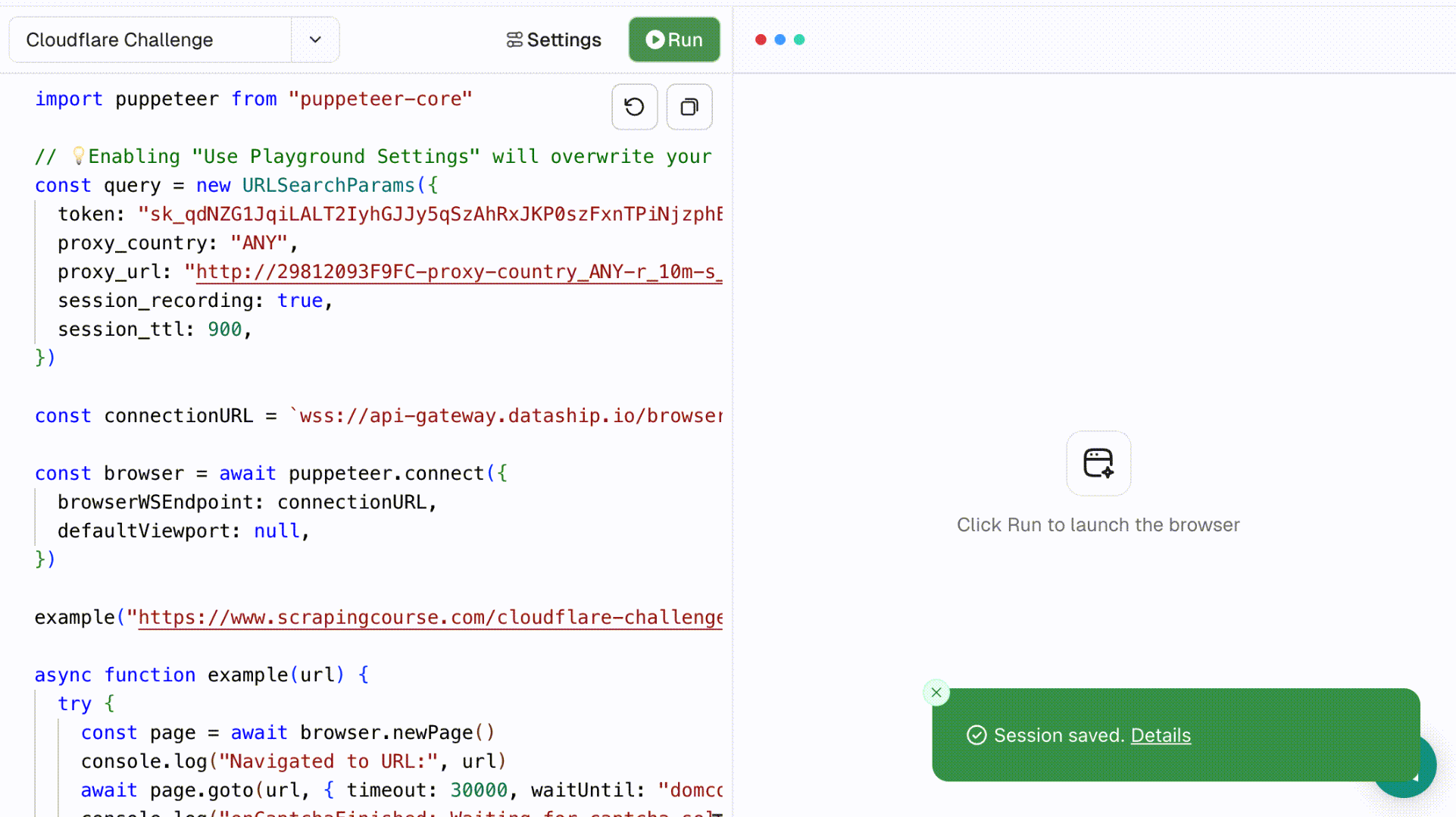
让我们通过一个使用Cloudflare挑战案例的示例进行演示:
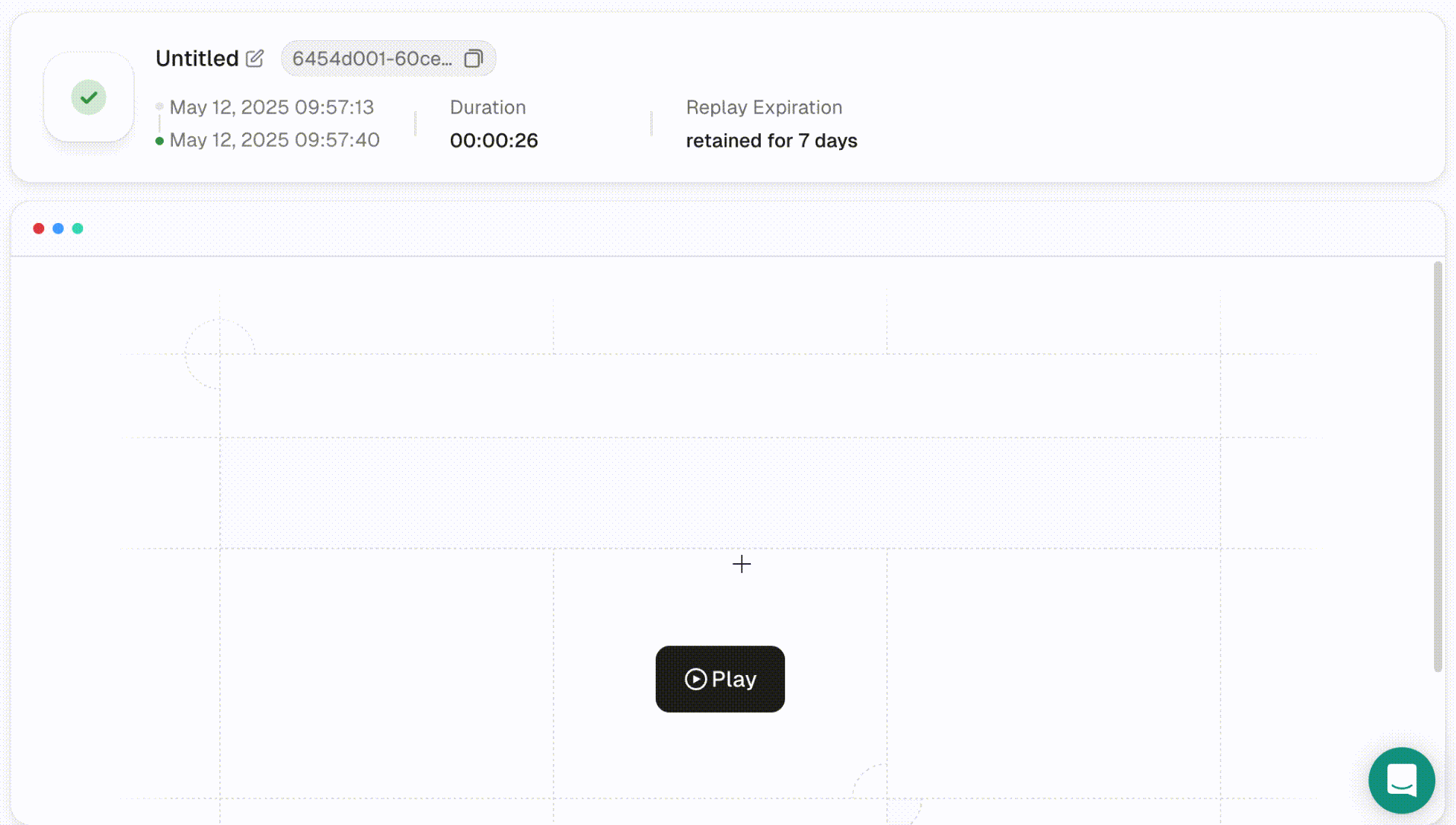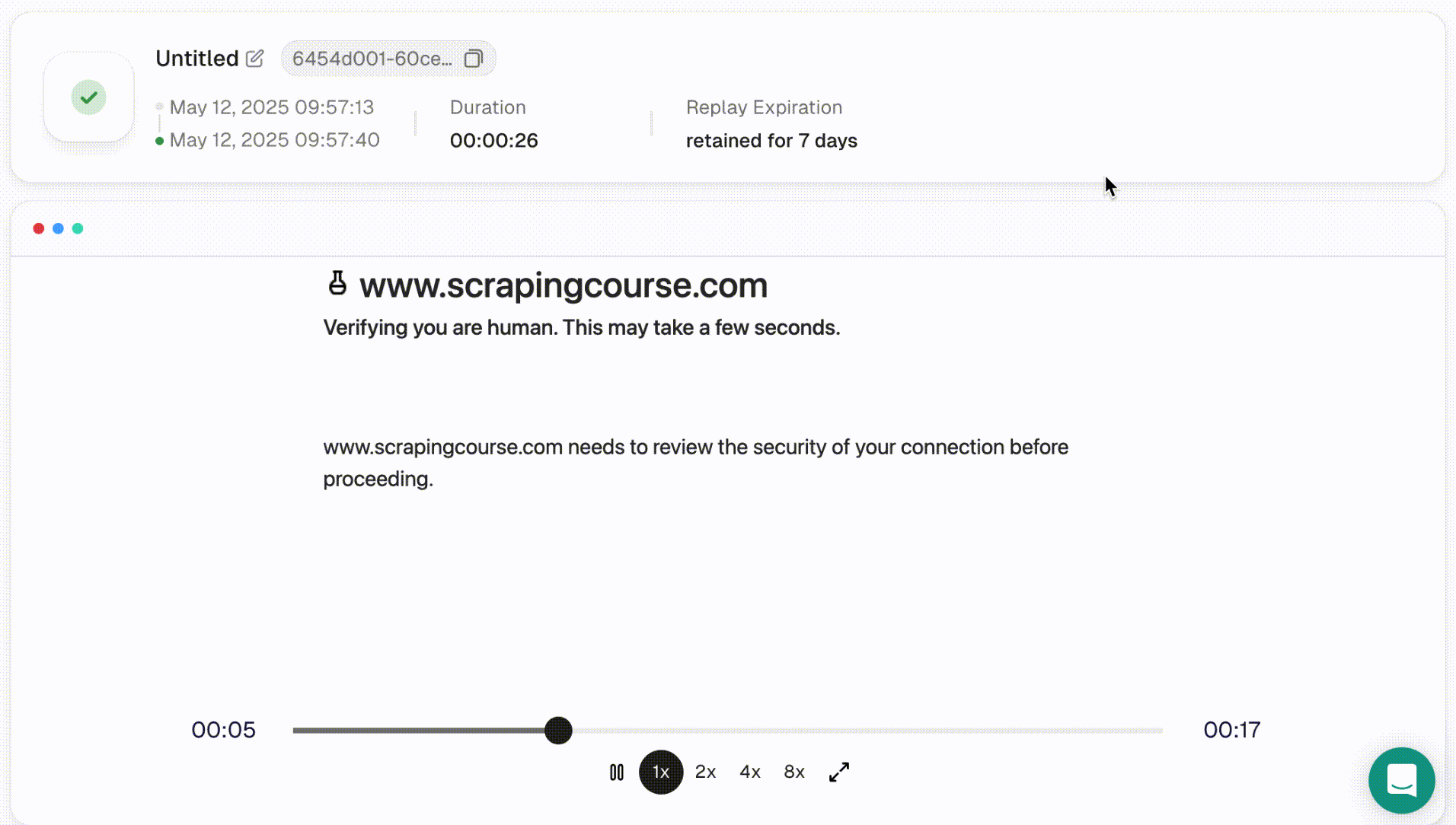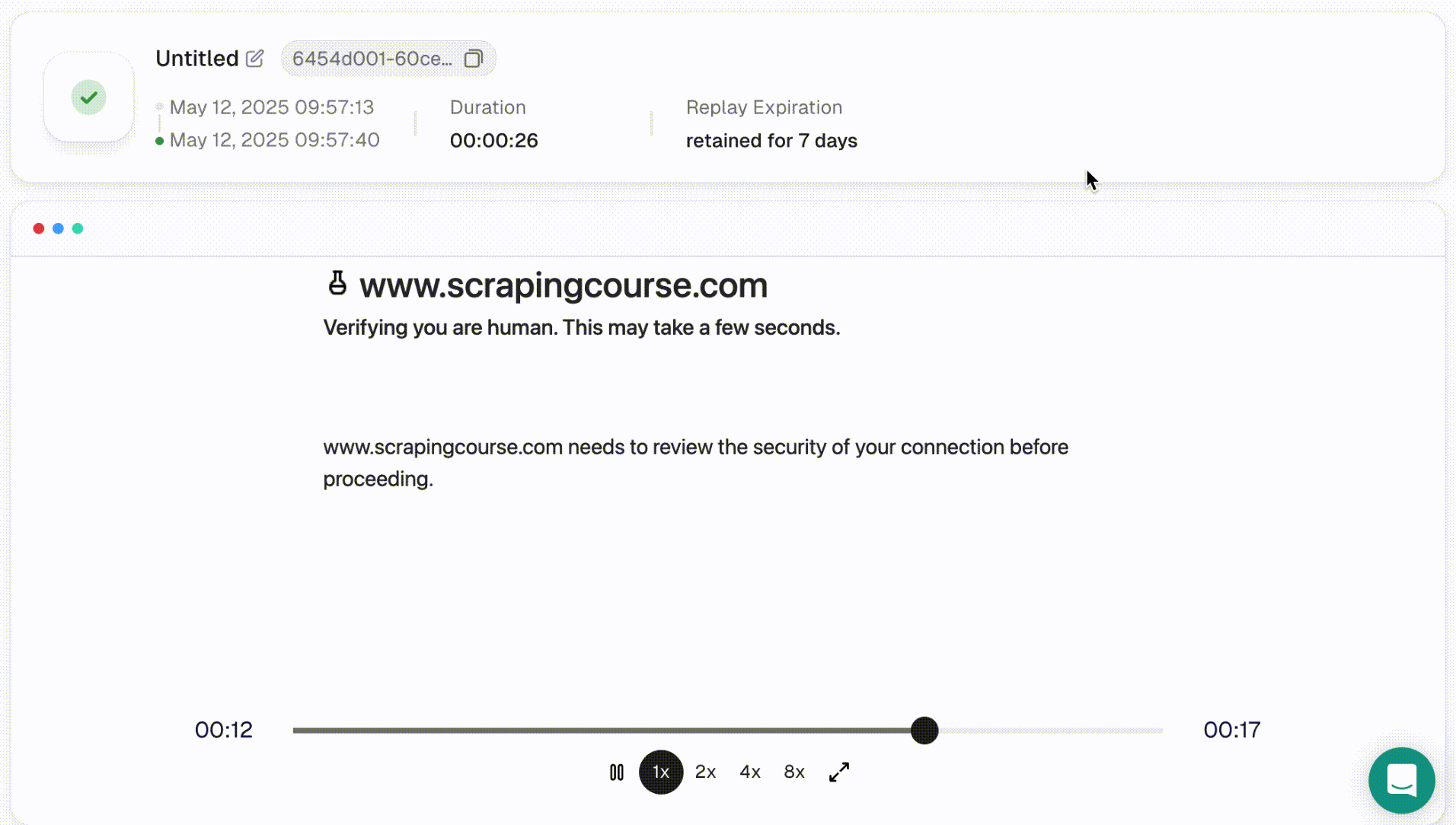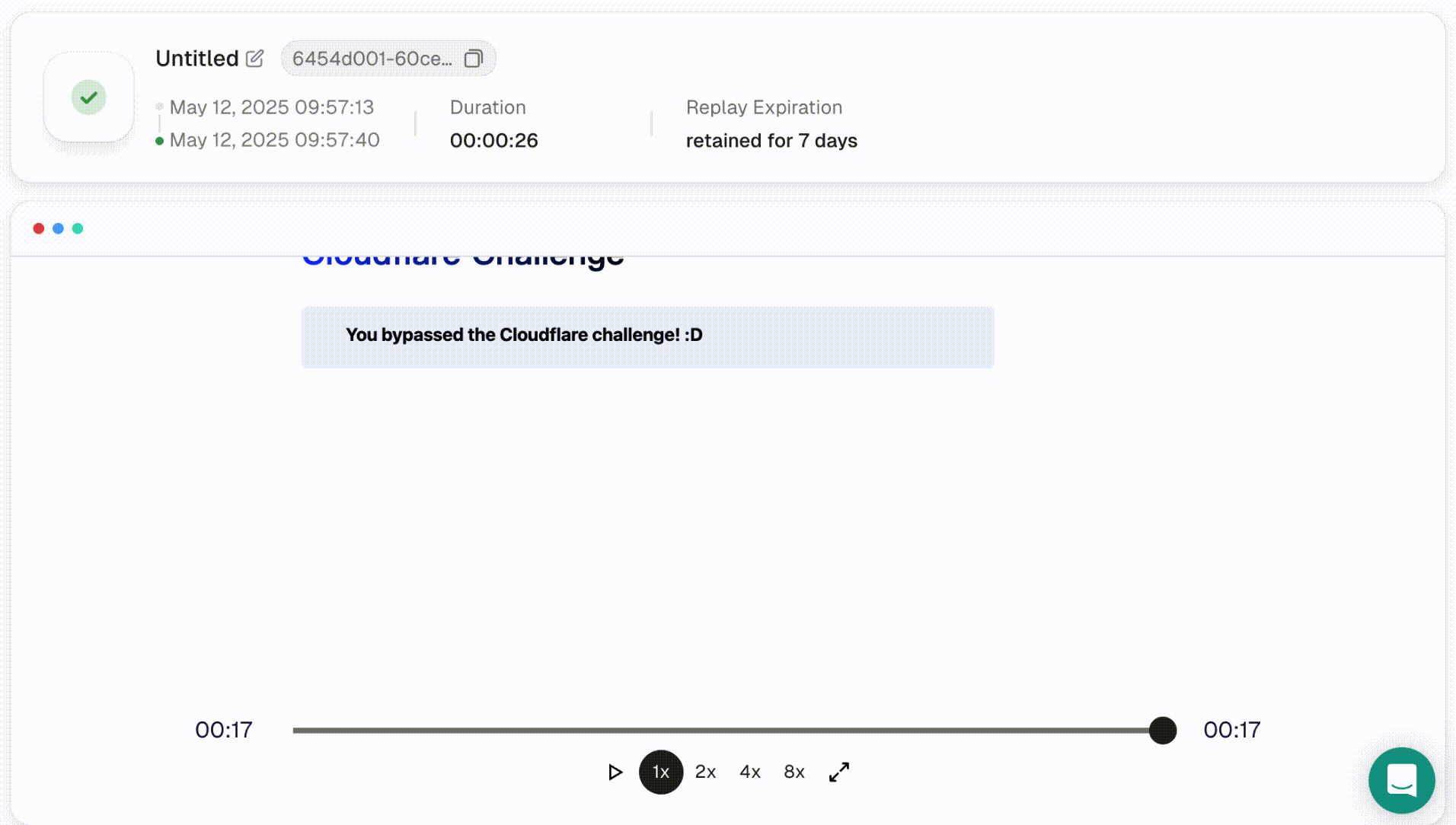
- 从下拉菜单中选择Cloudflare挑战。左侧的代码编辑器会自动填充相关脚本。点击运行以执行它,并在右侧浏览器面板中查看实时过程。
- 一旦脚本运行完毕,你可以使用会话重放更详细地检查结果。此功能支持可调的播放速度,让你回顾完整的会话。
注意:每个会话及其重放数据会保存15天。
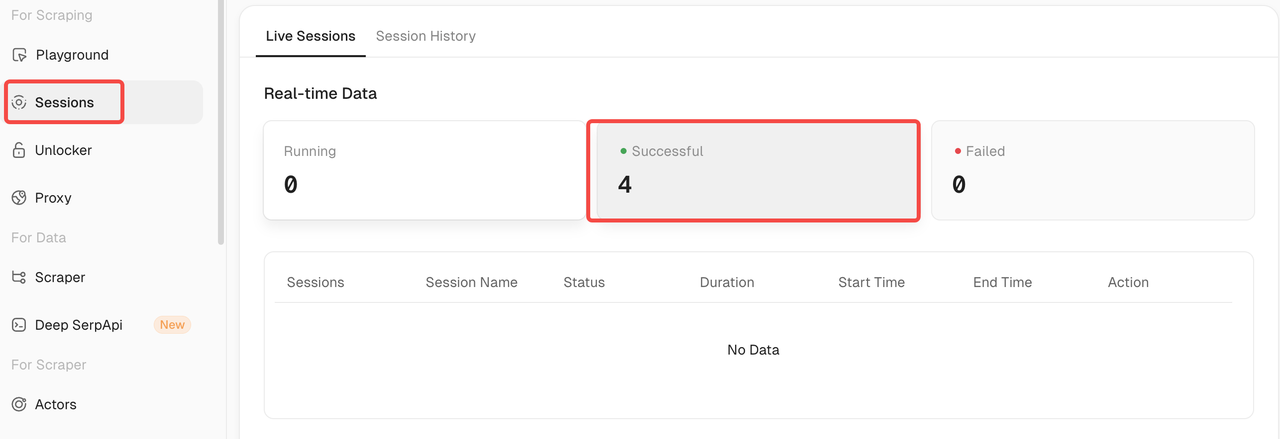
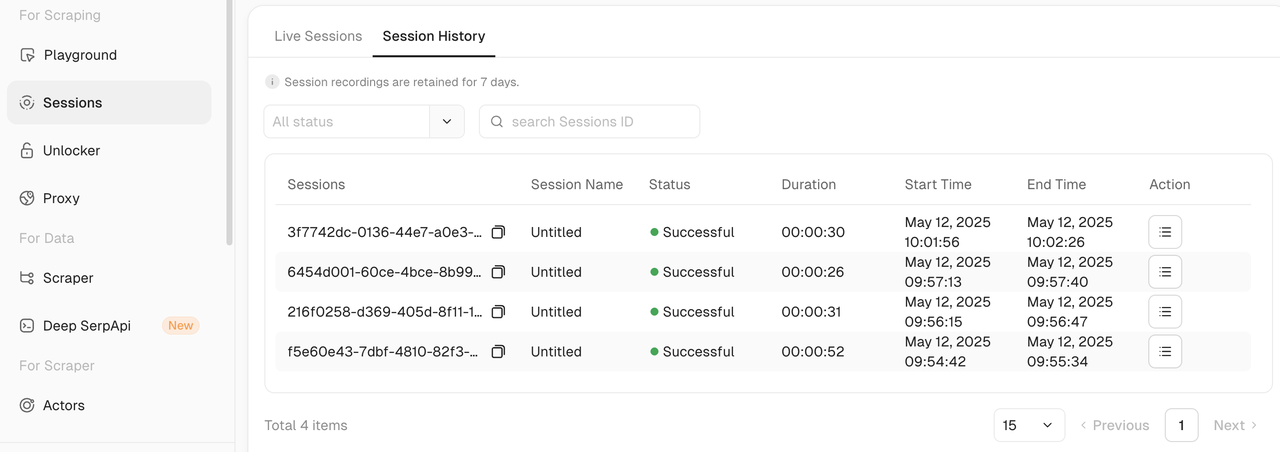
- 你还可以进入Scrapeless仪表板,点击会话,并通过成功进行筛选,以查看你的完整会话历史。
3. 个性化设置面板的增强
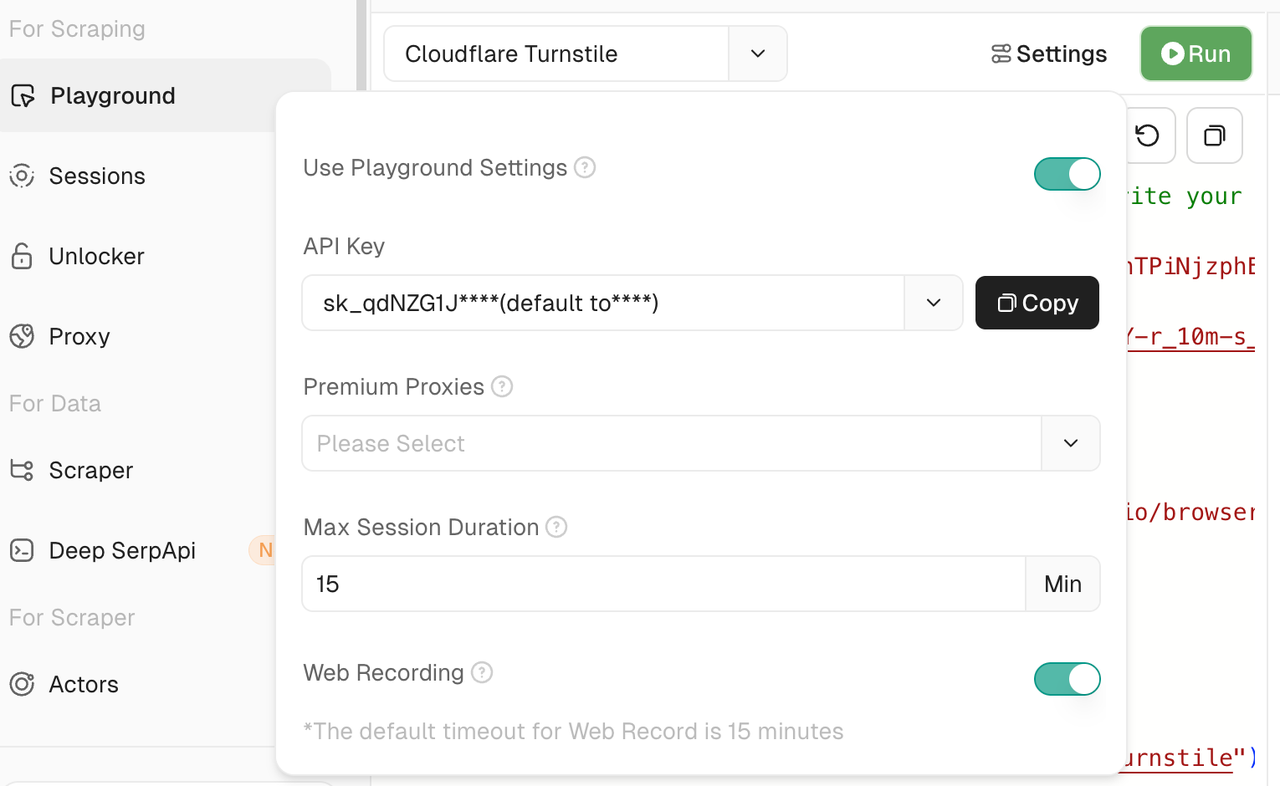
点击设置按钮以访问各种可定制的参数,帮助你在Playground中量身定制体验:
- API密钥显示:查看你当前使用的API凭据—清晰透明。
- 代理选择:在不同的代理线路之间切换,以更好地模拟真实世界的抓取环境。
- 最大超时设置:定义脚本执行的最短时间(以分钟为单位)。默认是15分钟,但可以无限延长。
- 网页录制:录制默认启用。你所有的浏览器交互将被捕获,允许你稍后使用会话重放来重放会话。
注意:
要使用会话重放,您必须在设置面板中启用网页录制。
我们强烈建议您默认保持启用状态,以确保所有浏览器交互都能正确记录。
✅ 没有额外费用 — 会话重放与您的使用免费包含。
4. 开发者友好的实用按钮
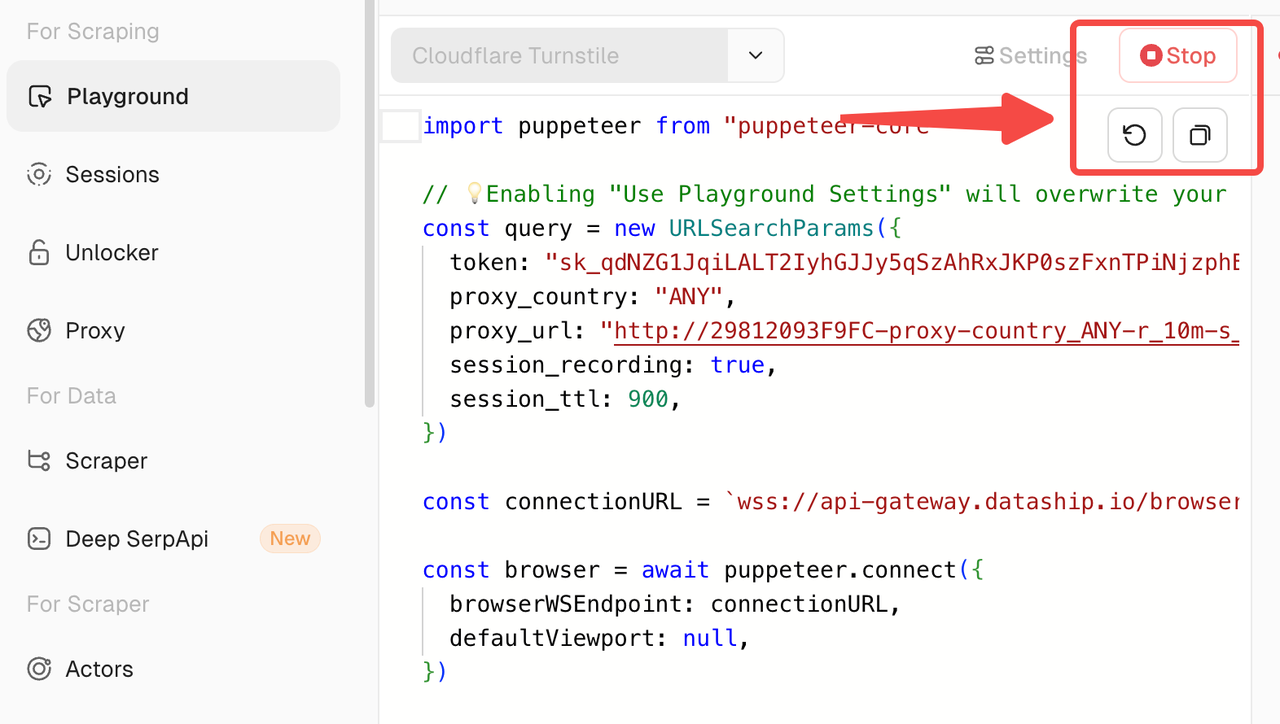
我们还添加了一些实用按钮,以改善您的开发体验:
- 重置:立即将当前脚本重置为默认模板 — 非常适合快速回滚。
- 复制:一键复制当前脚本内容。一个提示将确认:“代码复制成功”。
- 停止:手动终止运行的会话,以避免卡死或浪费资源。
技术背后:是什么驱动Scrapeless Playground?
Scrapeless团队构建了一个强大、高性能的云浏览器基础设施,以支持这一视觉调试体验。我们的平台旨在实现稳定性、可扩展性和高并发,结合无头浏览器技术与事件级监控,准确模拟复杂的网页行为 — 确保所有用户的准确、高效调试。
Scrapeless爬虫浏览器的关键技术亮点
-
高度真实的浏览器环境
- 动态隐身模式:自定义指纹参数,如用户代理、设备信息、区域设置、操作系统、屏幕大小和语言,以模拟真实用户行为。集成的CAPTCHA破解和SDK支持(Node.js、Python)。与Scrapeless Chromium的高级隐身。
- 无头和有头模式:支持两种浏览器模式,以适应多样的反爬虫策略。
-
全球代理和IP管理
- 超过7000万个住宅IP,覆盖195个国家,具有自动轮换和地理目标路由。
- 透明定价:每GB仅需1.26–1.80美元,而其他提供商的价格为9.5美元以上。您也可以使用自己的代理。
-
自动CAPTCHA破解
- 对于reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAF、DataDome等的内置解决方案。
-
会话重放
- 会话检查器:实时监控会话以便调试。
- 实时视图:交互式调试错误,分析用户行为,并检查代理流量以进行优化。
- 会话录制:重放会话步骤,全面分析操作和网络活动。
-
多类型爬取方法
- 爬取:从单个页面提取数据。
- 爬行:全站点提取,带深度控制和网站地图爬行。
- 提取:基于提示从给定页面提取内容。
了解更多关于Scrapeless爬虫浏览器的信息:
未来计划
Playground是Scrapeless提升浏览器自动化质量和产品化过程中的一步。展望未来,Scrapeless团队计划在多个领域进行迭代和升级:
1. 爬取能力的产品化
- 标准化并产品化三大爬取能力:爬取、爬行和提取,以支持多模态数据提取(文本、PDF、文档、图像等)。
- 升级爬虫浏览器功能,包括:
- 代理使用跟踪
- 自定义权限配置
- 针对文件类型会话的优化会话重放
2. 开发者生态系统扩展
- 启动开发者收入共享计划,以激励社区贡献,如插件和用例模板。
3. 基础设施强化
Scrapeless将继续投资于其核心爬虫技术栈,同时增强产品标准化和开发者体验。我们长期目标是构建一个开放、可扩展和开发者友好的自动化平台。
💡 我们欢迎您的反馈!
欢迎加入我们的Discord社区,分享您的经验或建议新功能。
👉 尝试新的Playground,解锁更多浏览器自动化的可能性!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


