
如何从Lazada抓取数据 - 最佳Lazada抓取API
Advanced Data Extraction Specialist
从Lazada抓取数据可以洞察宝贵的商品趋势、价格和市场竞争信息,帮助企业做出明智的决策。然而,反抓取保护、动态网页和IP限制等挑战往往使这一过程变得困难。
为了克服这些障碍,使用最佳Lazada抓取API至关重要。这些API旨在绕过常见的障碍并简化数据提取过程,确保企业能够高效地收集其所需的有条理且准确的Lazada数据。
Lazada允许网页抓取吗?
Lazada的服务条款并未禁止网页抓取。但是,尊重平台的政策至关重要。Scrapeless的Lazada抓取工具旨在在合法和道德的范围内运行,优先考虑负责任的数据提取实践,以确保遵守相关准则。
为什么从Lazada抓取数据?
从Lazada抓取数据为电子商务企业提供宝贵的见解。以下是使用Lazada抓取API的好处:
- 市场洞察: 跟踪趋势、热门产品和定价策略,保持竞争力。
- 竞争对手分析: 监控竞争对手的商品列表和价格,调整自身策略。
- 库存优化: 跟踪库存水平和需求,改进库存管理。
- 营销策略: 利用热销类别和关键词的数据优化营销活动。
- 自动化: 自动化数据提取,提高准确性和效率。
Lazada抓取API使数据收集变得轻松,帮助您获得竞争优势。
如何从Lazada抓取数据 - 最佳Lazada抓取API
我们可以使用强大的抓取API来抓取Lazada的产品数据。与编写自己的代码相比,API可以节省时间和精力,让您更快地抓取所需的数据。
Lazada抓取API概述:
- Scrapeless
- Outscraper
- Piloterr
- Setuserv
- Actowiz
1. Scrapeless抓取API
Scrapeless是一个先进的网页抓取平台,专为需要准确、安全和可扩展数据提取的企业和开发人员而设计。它提供先进的解决方案,简化从各种来源(包括Lazada和亚马逊等电子商务平台)收集数据的过程。
凭借其强大的基础设施,Scrapeless无需构建和维护您自己的抓取工具,并轻松处理验证码解决、反机器人系统和IP轮换等复杂挑战。无论您是想收集产品详情、价格趋势还是客户评论,Scrapeless都提供了一种可靠且高效的方式来满足您的数据需求。
主要特点:
- 可定制: 通过调整产品类别、价格范围或地理区域等参数来定制您的抓取需求。
- 可扩展: 处理大量数据,非常适合数据提取需求量大的企业。
- 代理支持: 内置代理轮换确保不间断的数据收集,而无需担心IP封禁。
- 高精度: 提供准确、结构化的数据,可以轻松集成到您的业务运营中进行分析或自动化。
如何使用Scrapeless抓取Lazada数据:
- 步骤1. 登录Scrapeless。并获得免费试用。
- 步骤2. 点击“抓取API”
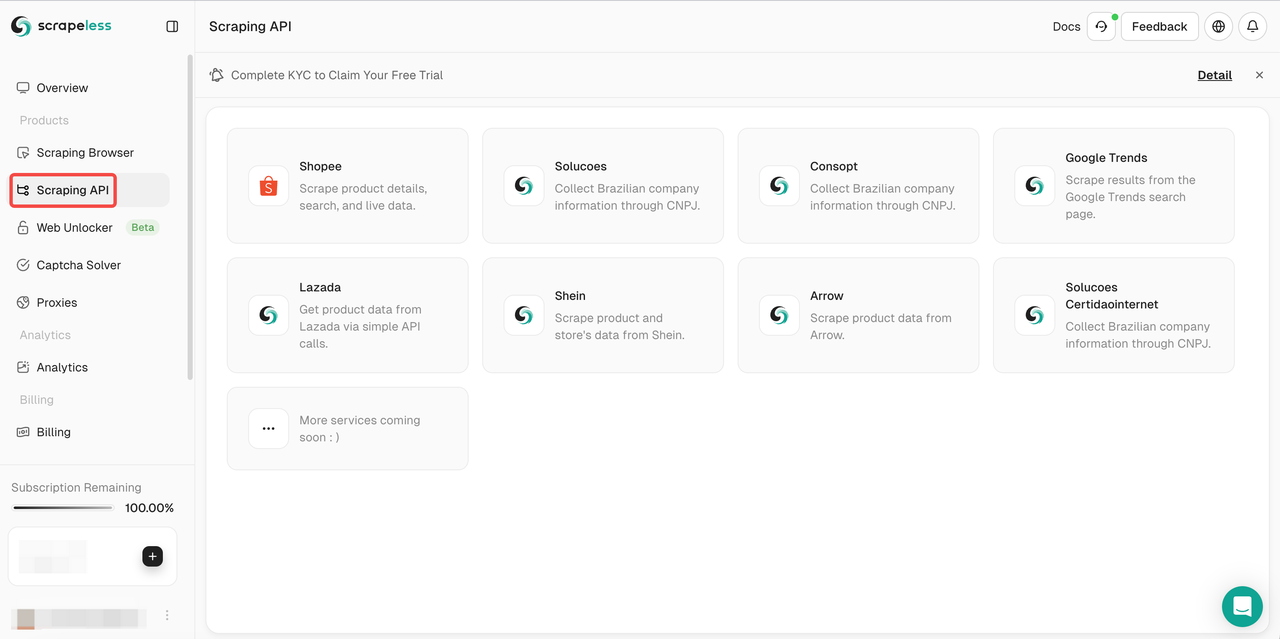
- 步骤3. 选择Lazada并输入Lazada抓取页面。
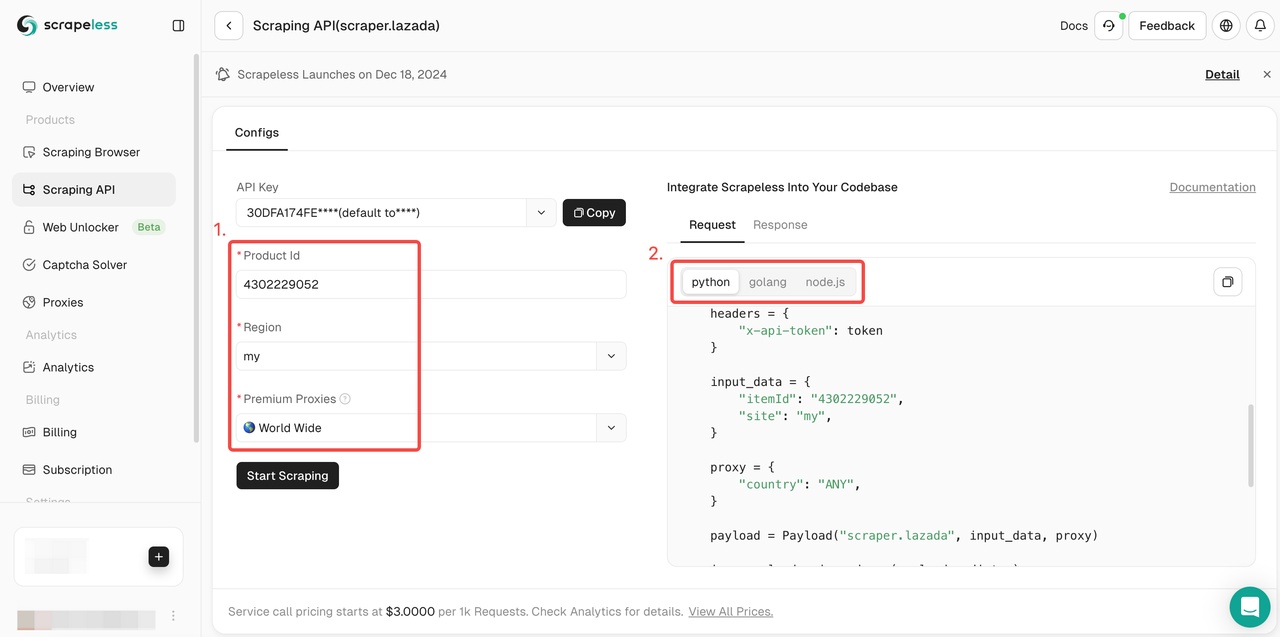
- 步骤4.下拉操作列表并选择要抓取的数据条件设置。然后点击开始抓取。
- 步骤5. 抓取将在几秒钟内成功完成。相应的结构化数据将显示在右侧。
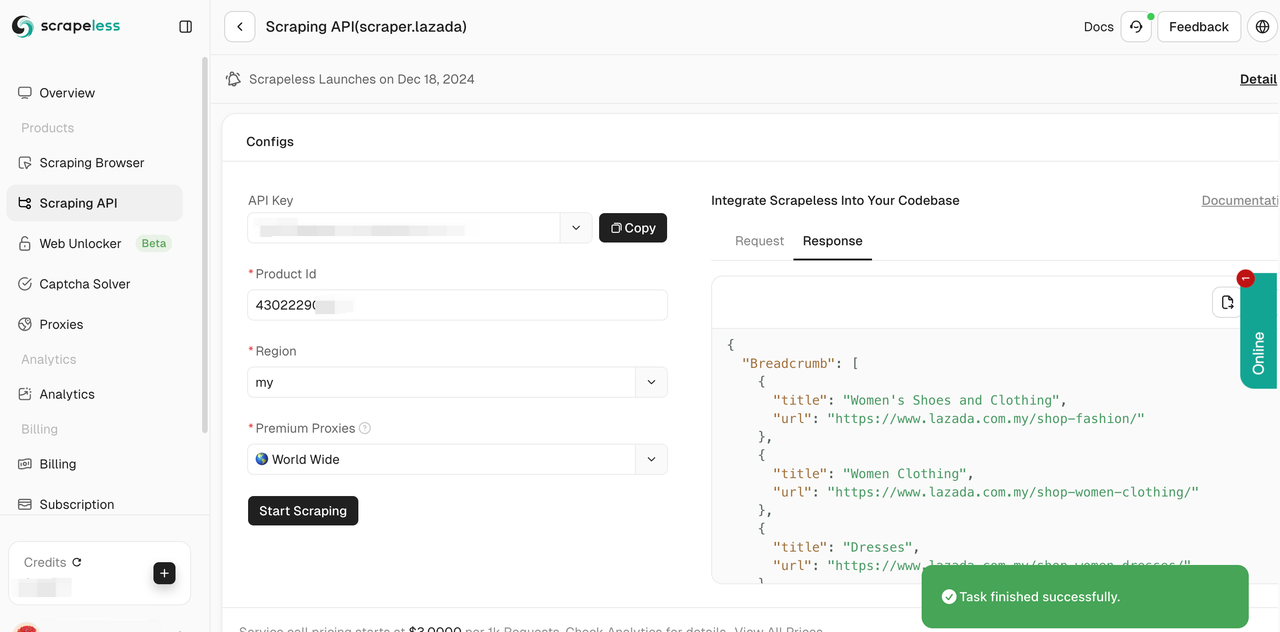
您还可以将我们的参考代码集成到您的项目中,并部署您的大规模数据抓取。这里我们以Python为例。您也可以在我们的客户端中使用Golong和NodeJS。
- Python:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " #您的API令牌
headers = {
"x-api-token": token
}
input_data = {
"itemId": " ", #输入产品ID
"site": "my",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.lazada", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()2. Outscraper
Outscraper是一个通用的多平台爬取工具,适用于Lazada等电商平台的数据采集。其API提供简洁清晰的接口,用户可以快速调用爬取功能,适合初学者或对爬取任务要求不高的用户。
但是,我们被该API的两个重要缺点所排斥:
- 检测能力不足
- 功能单一
3. Piloterr
Piloterr是一个注重高性能和灵活性的抓取工具,适合需要大规模并发和复杂抓取任务的用户。它支持从Lazada和其他电商平台采集数据,同时提供强大的自定义功能和API支持。
我必须指出:
- 技术要求高
- 成本高
4. Setuserv
Setuserv是一个针对中小型企业和个人开发者的经济型爬取工具。它专注于为需要基本数据采集的用户提供可靠的爬取服务。虽然它不像其他高端工具那样复杂,但其易用性和价格优势使其成为入门级选择。
- 功能有限
- 反爬虫性能弱
5. Actowiz
Actowiz是一个提供全面数据爬取服务的解决方案,适合需要长期稳定爬取的企业用户。其爬取功能涵盖Lazada平台上的大部分内容,并提供高级分析功能,帮助用户直接处理爬取的数据。
- 价格高
- 灵活性一般
总结
如果您需要一个高性能且高度灵活的Lazada抓取工具,Scrapeless无疑是最佳选择。其强大的反屏蔽能力和高并发支持使其能够在复杂场景中表现出色。
相关博客:
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


