
什么是无头浏览器以及最佳的无头浏览器用于抓取
Specialist in Anti-Bot Strategies
本文将介绍什么是无头浏览器,它的用途,什么是无头Chrome,以及其他哪些浏览器在无头模式下最受欢迎。我们还将讨论无头浏览器测试的主要局限性。
继续滚动!
为什么2000万开发者信任我们?
您如何驾驭复杂的无头浏览器世界?您需要一位久经沙场的向导,一位克服重重困难并最终获胜的向导。这就是我们的优势所在!
在Scrapeless,我们多年来一直在探索网络抓取和自动化技术。我们的团队花费了超过15000小时研究各种无头浏览器解决方案,从PhantomJS等老牌解决方案到Playwright等较新的解决方案。
我们亲身体会到无头浏览器如何成就或破坏一个项目。我们调试并修复了无数问题,优化了大规模抓取操作的性能,甚至在现成选项无法满足需求时开发了定制解决方案。
无论您是想自动化测试,大规模抓取数据,还是只是学习无头浏览的来龙去脉,我们都能提供帮助!
什么是无头浏览器?
让我们首先了解这些隐形的强大工具是什么以及它们是如何工作的!
无头浏览器就像网络世界中的忍者——隐秘、高效且强大。本质上,它是一个没有图形用户界面(GUI)的网页浏览器。它主要被软件测试工程师使用,因为没有GUI的浏览器不需要绘制视觉内容,因此运行速度更快。无头浏览器的最大优势之一是它可以在没有GUI支持的服务器上运行。
想象一下Chrome或Firefox,但您根本看不到页面数据加载和显示,您可以完全通过代码或命令行界面控制它。
您是否曾经怀疑过此类浏览器的强大功能?不要再误解了!它们几乎可以执行传统浏览器的所有功能:
- 渲染网页
- 执行JavaScript
- 管理Cookie和会话
- 处理网络请求
唯一的区别是:它们在不显示任何屏幕内容的情况下完成所有这些操作。这使得它们非常适合自动化、测试和数据提取任务。
无头浏览器的关键组件
**注意:**使用无头浏览器时,请特别注意JavaScript引擎。JS引擎的差异有时会导致意外行为,尤其是在处理现代Web应用程序时。
- **浏览器引擎:**解释HTML、CSS和JavaScript的核心组件。常见的引擎包括Blink(Chrome)、Gecko(Firefox)和WebKit(Safari)。
- **JavaScript引擎:**负责执行JavaScript代码。示例包括V8(Chrome)和SpiderMonkey(Firefox)。
- **渲染引擎:**在无头浏览器中,此组件仍然处理页面布局,但不产生视觉输出。
- **网络堆栈:**处理所有网络通信,包括HTTP请求和响应。
- **API或命令界面:**无头浏览器不提供GUI,而是提供API或命令行界面进行控制和交互。
- **DOM(文档对象模型):**网页结构的程序化表示。
无头浏览器的主要用途
- **网络爬取:**用于爬取需要执行JavaScript渲染的动态内容和页面。例如:爬取产品信息、动态生成的價格等。
- **自动化测试:**测试Web应用程序的用户界面行为,但不打开实际窗口。通常在CI/CD流程中用于验证前端功能。
- **性能监控:**检测网页加载时间、渲染性能等。
- **屏幕截图生成和PDF导出:**生成网页的屏幕截图或将其转换为PDF。
- **网站监控:**检测网站是否按预期运行,以及是否存在错误或更改。
缺点和局限性
- **调试挑战:**缺乏视觉反馈会使某些问题的诊断更加困难。需要采用与主流浏览器不同的调试方法。
- **资源密集型:**虽然比完整的浏览器更高效,但对于大规模操作仍然可能非常消耗资源。
- **渲染不完整:**某些复杂的视觉元素或动画可能无法正确渲染。
- **被网站检测:**高级网站可能会检测并阻止无头浏览器。需要额外的技术来模拟“真实”浏览器的行为。
- **学习曲线:**需要编程知识和对Web技术的了解。每个无头浏览器解决方案都有其自身的API和功能需要掌握。
无头浏览器与普通浏览器的区别:5个关键差异
| 属性 | 无头浏览器 | 普通浏览器 |
|---|---|---|
| 用户界面 | 无用户界面(不可见) | 完整的用户界面(窗口、菜单等) |
| 交互性 | 不能通过鼠标或键盘直接交互 | 用户可以直接操作(点击、输入等) |
| 性能 | 轻量级,因为它不渲染图形或显示页面内容 | 更重量级,因为它渲染页面图形和动画 |
| 用例 | 自动化测试、网络抓取、监控等 | 日常浏览、操作和交互 |
| 资源消耗 | 相对较低,适用于服务器或脚本环境 | 相对较高,需要更多系统资源 |
5个流行的无头浏览器
Top 1. Scrapeless 抓取浏览器 - 2025年最佳无头浏览器
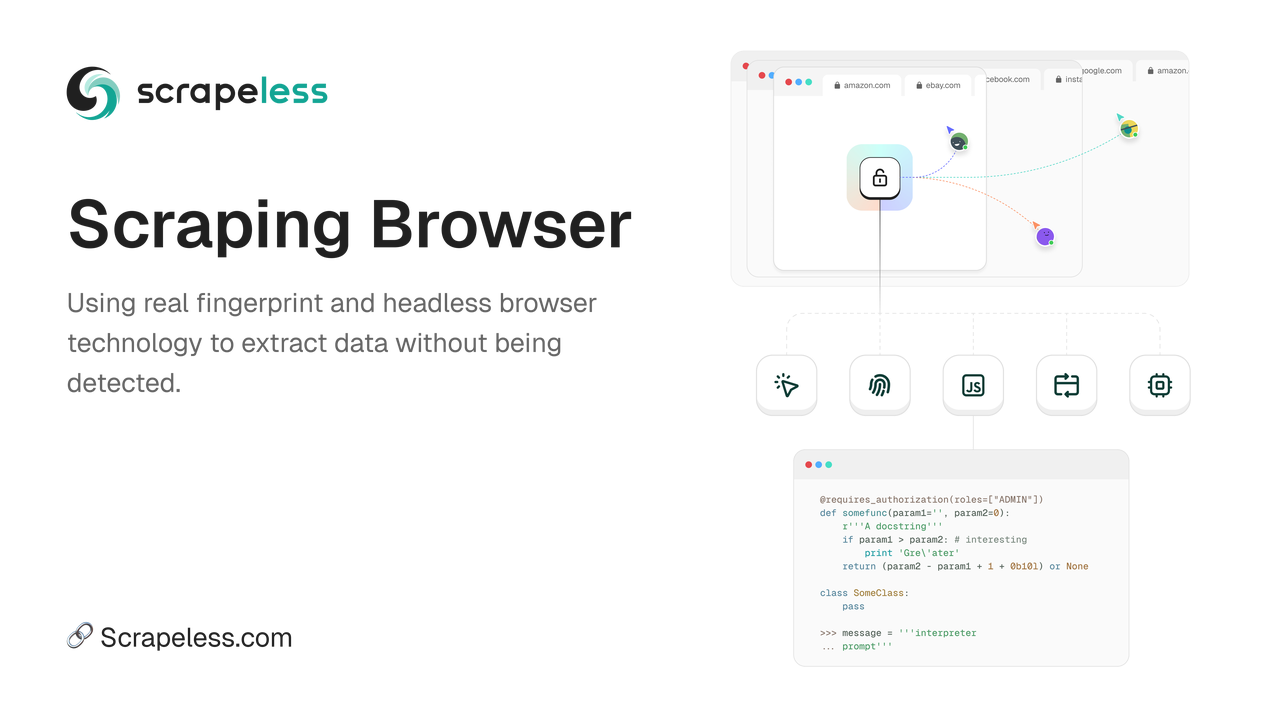
Scrapeless 抓取浏览器是一款用于抓取的高性能无头浏览器,旨在简化从动态网站提取数据的过程。它使开发人员能够高效地操作和监督无头浏览器,而无需专用服务器,从而使Web自动化和数据收集更容易实现。
使用方法:
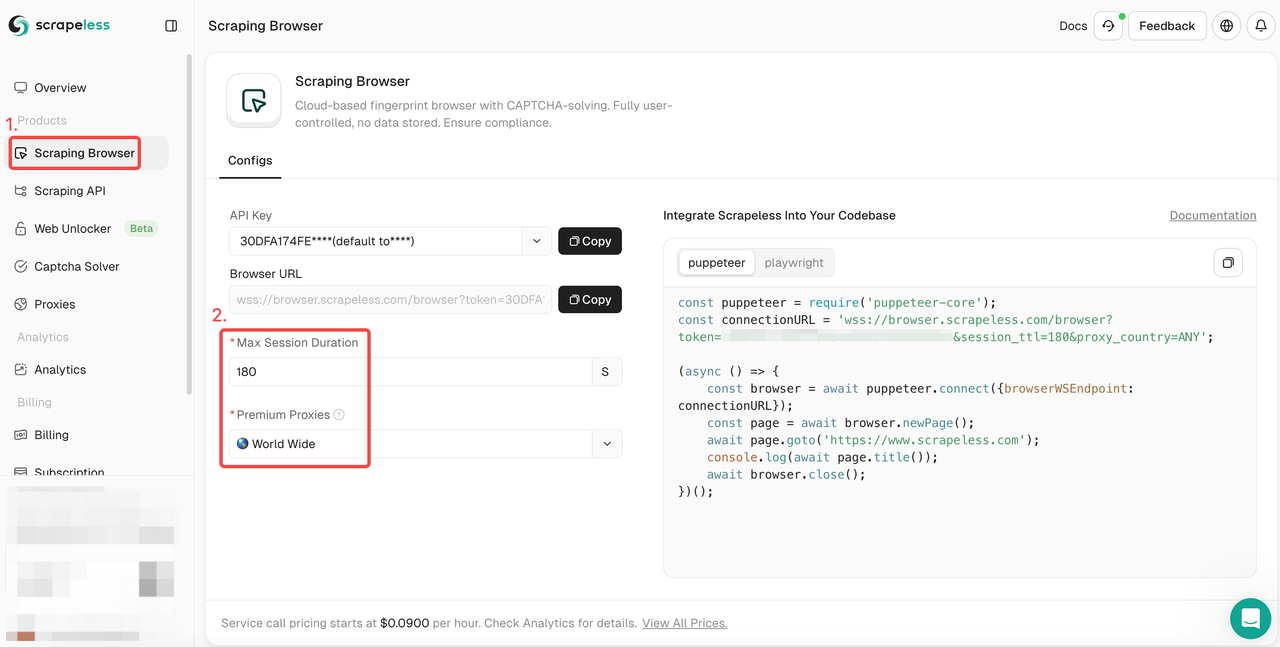
- 步骤1. 登录 Scrapeless
- 步骤2. 进入“抓取浏览器”
- 步骤3. 根据您的需求设置参数。
- 步骤4. 复制用于集成到您的项目的示例代码:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //输入API令牌
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //输入API令牌
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();想要了解更多详情?我们的文档 将会帮您很多:
Puppeteer:
- 安装必要的库
首先,安装puppeteer-core,这是一个轻量级的Puppeteer版本,旨在连接到现有的浏览器实例:
Bash
npm install puppeteer-core- 编写代码以连接到抓取浏览器
在您的Puppeteer代码中,使用以下方法连接到抓取浏览器:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();这样,您可以利用抓取浏览器的基础设施,包括可扩展性、IP轮换和全球访问。
- 示例:
以下是与抓取浏览器集成后的一些常见Puppeteer操作:
- 导航和页面内容提取
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- 屏幕截图
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- 运行自定义脚本
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Playwright:
- 安装必要的库
首先,安装playwright-core,这是一个轻量级的Playwright版本,用于连接到现有的浏览器实例:
Bash
npm install playwright-core- 编写代码以连接到抓取浏览器
在Playwright代码中,使用以下方法连接到抓取浏览器:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();这使您可以利用抓取浏览器的基础设施,包括可扩展性、IP轮换和全球访问。
- 示例
以下是与抓取浏览器集成后的一些常见Playwright操作:
- 导航和页面内容提取
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- 屏幕截图
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- 运行自定义脚本
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Top 2. Playwright
由Microsoft开发,Playwright提供了一个单一的API来管理基于Chromium、Firefox和WebKit的浏览器。它可以使用高级API来自动化多个浏览器。在设置用于无头浏览器测试的Playwright之前,请确保您的系统上安装了最新版本的Node.JS和npm。
Playwright已迅速在自动化社区中获得关注,这很大程度上归功于其独特的特性:
- 跨浏览器支持(Chrome、Firefox、Safari)。
- 功能强大的自动等待机制。
- 功能强大的网络拦截功能。
- 支持多种语言(JavaScript、Python、.NET、Java)。
Top 3. Puppeteer
由Google开发,Puppeteer提供了一个高级API,用于通过DevTools协议控制Chrome或Chromium。它是许多JavaScript开发人员的首选。
- 与Chrome/Chromium深度集成
- 完整的浏览器控制API
- 内置支持生成PDF和屏幕截图
Top 4. Selenium
Selenium是一个免费的开源工具,非常适合自动化。它支持在不同操作系统上运行的各种浏览器。Selenium Web Driver为动态网页提供了增强的支持,这可以使用Selenium Headless提供出色的结果。此外,您可以使用Headless Chrome或Headless Firefox执行无头浏览器Selenium。
- 支持多种编程语言
- 与各种浏览器兼容(Chrome、Firefox、Safari、Edge)
- 庞大的工具和扩展生态系统
Top 5. Cypress
Cypree擅长对Web应用程序(尤其是单页应用程序)进行端到端测试。尽管Cypress主要关注端到端测试,但它因其对开发人员友好的方法和强大的调试功能而受到欢迎。
- 实时重载
- 时间旅行调试
- 使用对DOM和网络层的本机访问
什么是无头Chrome测试?
如果您是开发人员,您可能熟悉UI驱动的测试,它确保应用程序随着时间的推移能够正确运行。但是,UI驱动测试的主要挑战之一是稳定性——尤其是在测试无法与浏览器一致地交互时。
无头浏览器测试为此问题提供了解决方案。与UI驱动测试不同,它允许在不加载应用程序的用户界面的情况下进行端到端测试。这种方法不仅加快了测试过程,而且确保了与页面的直接交互,减少了不稳定性。因此,测试变得更快、更可靠和更高效。
什么时候应该使用无头浏览器测试?
在资源受限或需要高效执行自动化任务的情况下,无头浏览器测试尤其有用。以下是一些常见的用例:
- 自动化HTML交互
模拟用户操作,例如表单提交、按钮点击和下拉菜单选择。无头浏览器允许您有效地验证对这些交互的响应。 - JavaScript执行测试
测试网页中JavaScript的执行,以验证动态内容。这对于具有大量客户端渲染的应用程序尤其有用。 - 网络抓取
绕过基本的防抓取措施,加载动态内容,并从网页中提取数据。无头浏览器非常适合涉及复杂前端渲染的抓取任务。 - 网络监控和性能测试
监控网络请求,分析加载时间并识别性能瓶颈,使其成为网站性能优化的宝贵工具。 - 处理Ajax请求
通过捕获和处理这些请求,确保依赖Ajax进行数据加载的页面能够正确显示。 - 生成网页截图
创建屏幕截图以在测试期间识别布局或内容问题,生成文档或执行网页的视觉检查。
总结
多么美好的一天!当我们停靠无头浏览的船只时,很明显我们处于Web自动化和数据提取革命的前沿。
无头浏览器测试是一种更快、更可靠、更高效的测试Web应用程序的方法。但是,当您使用真实的桌面浏览器进行测试时,它提供了您网站的真实表示。
您可以同时是无头和真实的?当然可以!Scrapeless 抓取浏览器结合了两全其美之处。它允许您轻松自动化网页。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


