
使用Scrapeless从谷歌购物抓取产品详情
Advanced Data Extraction Specialist
在当今竞争激烈的全球商业环境中,网络爬虫技术已成为电子商务公司和零售商保持市场竞争力的核心驱动力。通过智能代理网络从全球数千个目标数据源收集准确的公开数据,企业可以构建动态定价模型,优化库存管理,洞察消费者行为趋势,最终为终端用户提供最具竞争力的产品价格体系。
本指南将系统地演示如何通过专业工具合法获取Google购物平台上的公开产品数据。无论您是寻求构建自身数据管道的技术团队,还是寻求市场情报支持的商业决策者,本文都将为您提供兼具实用性和战略价值的行动框架。
什么是Google购物?
Google购物(以前称为Google产品搜索、Google产品和Froogle)是一个购物平台,用户可以在其中浏览、比较和购买来自众多付费供应商的产品。它不仅允许消费者轻松地从众多品牌中选择自己喜欢的产品,也为零售商提供了一个高效的在线推广渠道。当用户点击产品链接时,他们将直接跳转到供应商的网站完成购买,这使得Google购物成为企业提升产品曝光度和促进销售的有力工具。
Google购物结果页结构概述
浏览Google购物时获得的数据取决于三个关键输入参数:搜索、产品和价格。以下是每个参数的简要分析:
- 搜索:Google购物的产品列表包含每个产品的详细信息,例如ID、标题、描述、价格和库存状态。
- 产品:显示单个产品的详细信息,包括其他零售商的销售情况和产品价格。
- 价格:列出所有零售商的产品价格以及其他信息,例如运费详情、总成本和零售商名称。
搜索结果页
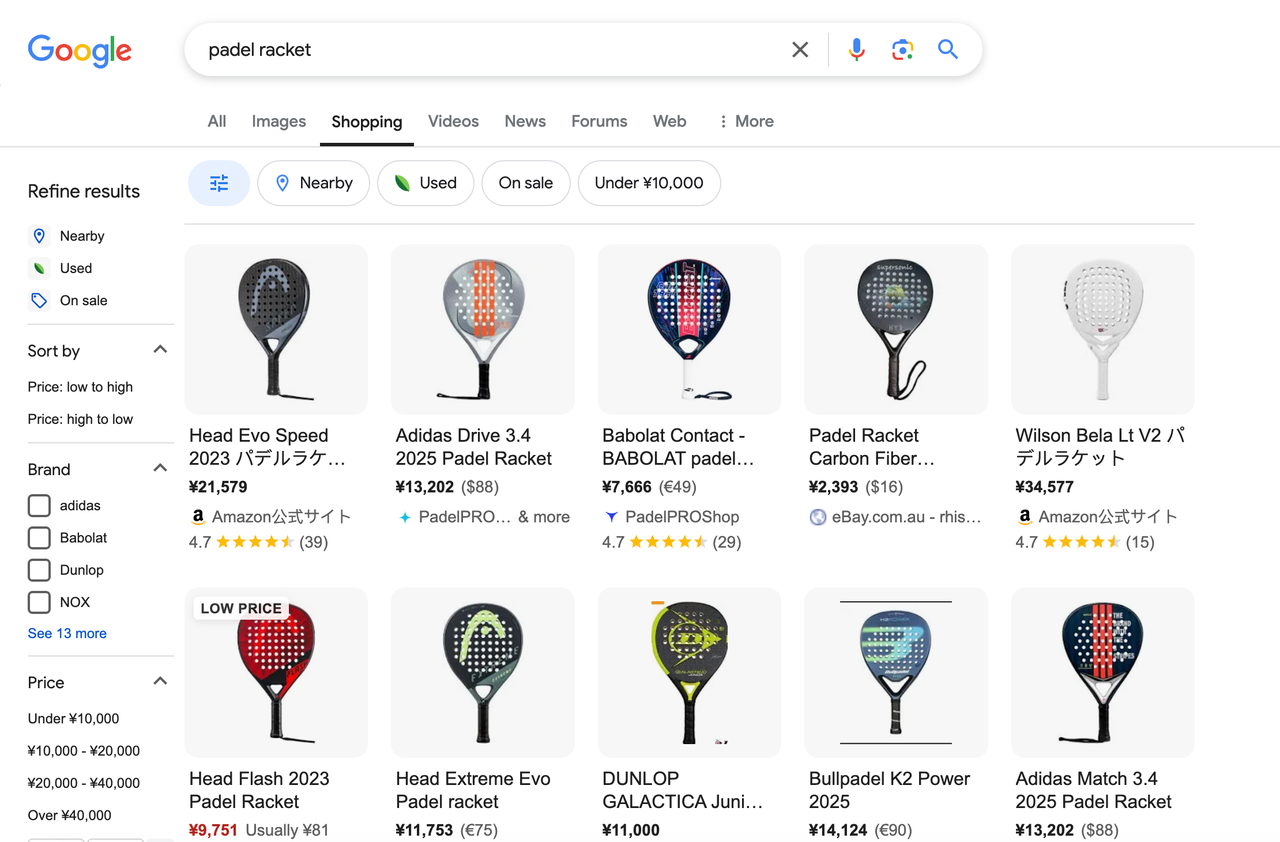
Google购物的搜索结果页显示与用户查询相关的所有产品。例如,搜索“padel racket”时,页面将显示以下元素:
- 搜索栏:允许用户输入关键词搜索产品。
- 产品列表:显示搜索结果中所有产品的详细信息。
- 筛选器:允许用户按价格范围、颜色、款式等筛选产品。
- 排序选项:支持按价格升序/降序、受欢迎程度等属性排序结果。
产品页
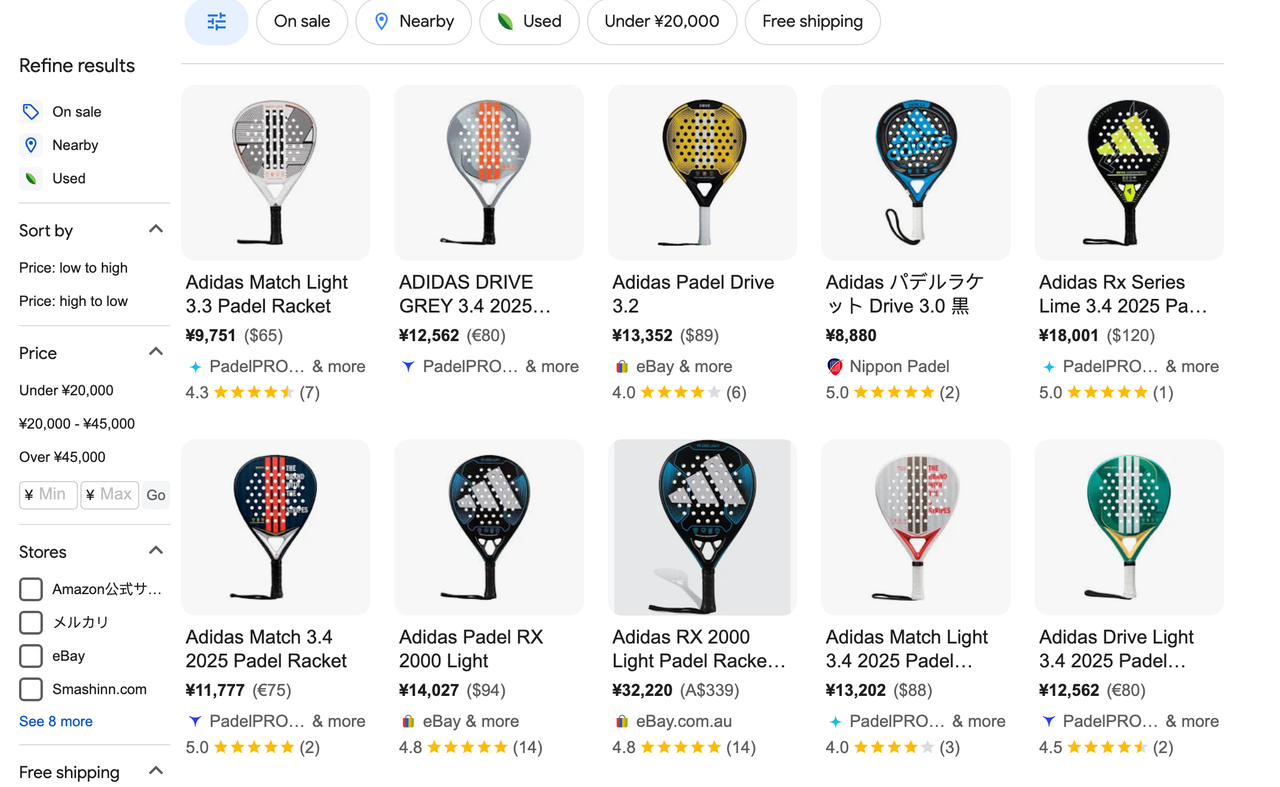
点击搜索结果页中的产品后,用户将跳转到产品页,其中包含以下内容:
- 产品名称:产品的名称。
- 产品亮点:产品核心功能的快速概述。
- 产品详情:产品的详细描述。
- 定价信息:不同零售商提供的价格。
- 产品评论:显示产品评级和客户评论。
- 价格范围:显示不同卖家产品的最低和最高售价。
- 通用规格:提供产品的基本参数。
定价页
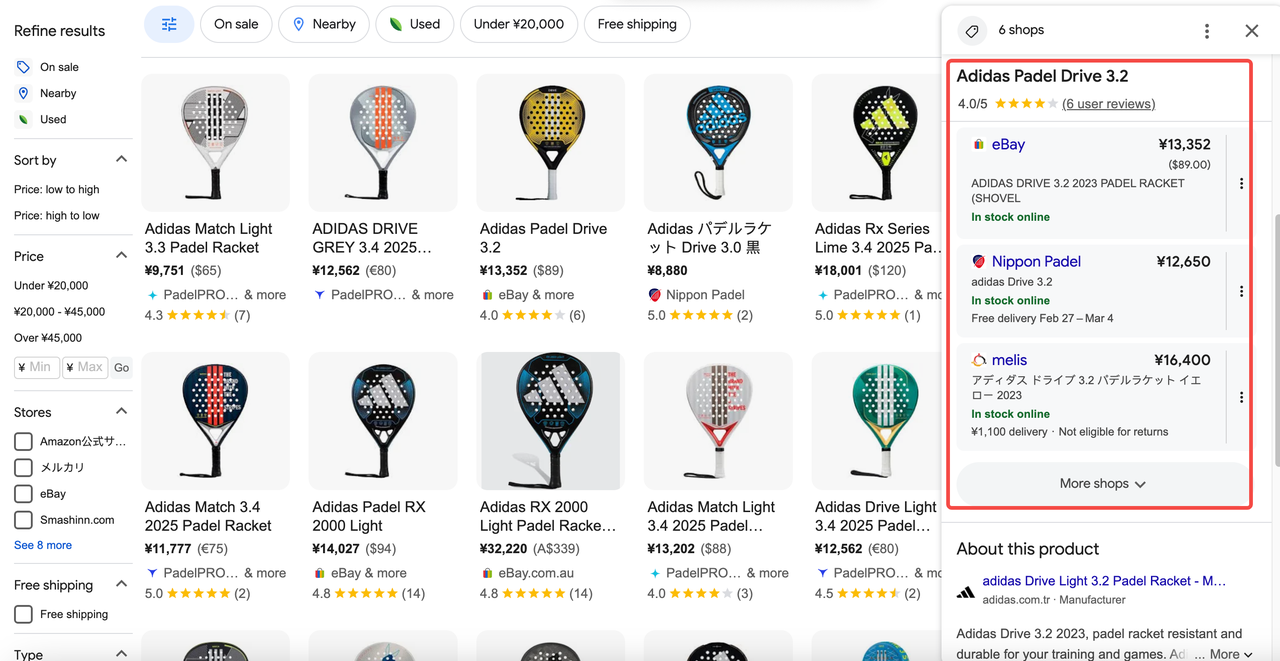
定价页汇总来自不同零售商的产品价格,并显示零售商信誉以及是否提供Google保障等信息。此页面包含以下内容:
- 产品名称:您搜索的产品名称。
- 评级:产品的总体评级和评论数量。
- 按商店分类的价格:列出零售商提供的产品、优惠和购买链接。
- 筛选器:可应用于零售商列表的筛选器。
爬取Google购物结果是否合法?
在某些情况下,抓取数据被认为是合法的:
- 公平使用:在某些司法管辖区,公平使用允许出于研究、教育或非商业用途而有限地抓取数据。
- 公开数据:如果您要抓取的数据是公开的(例如Google购物上的产品定价或描述),那么抓取这些数据似乎是可以的。
如何使用Python爬取Google购物结果[完整指南]
在本综合指南中,我们将逐步引导您完成使用Python爬取Google购物结果的过程。无论您是收集产品详情、价格还是评论,本教程都将提供逐步说明,帮助您设置爬取环境并高效地开始收集数据。我们将利用功能强大的Scrapeless Google购物API简化流程,让您能够专注于构建项目,而无需担心复杂的爬取逻辑或法律问题。
[Scrapeless API技术优势]
- 内置反爬虫引擎(支持Cloudflare/recaptcha v3)
- 自动处理动态渲染的内容
- 提供标准化的数据字段,方便快速集成和分析
- 高效的IP代理池,确保高并发爬取并避免IP封禁
- 实时数据更新,确保捕获最新的Google购物信息
- 全球代理网络,支持多区域数据爬取,确保覆盖不同市场的商品信息
- 高可扩展性,支持大规模数据爬取需求,适用于企业级应用
步骤1:设置Python并安装所需的库
首先,我们需要构建一个数据爬取环境,并准备以下工具:
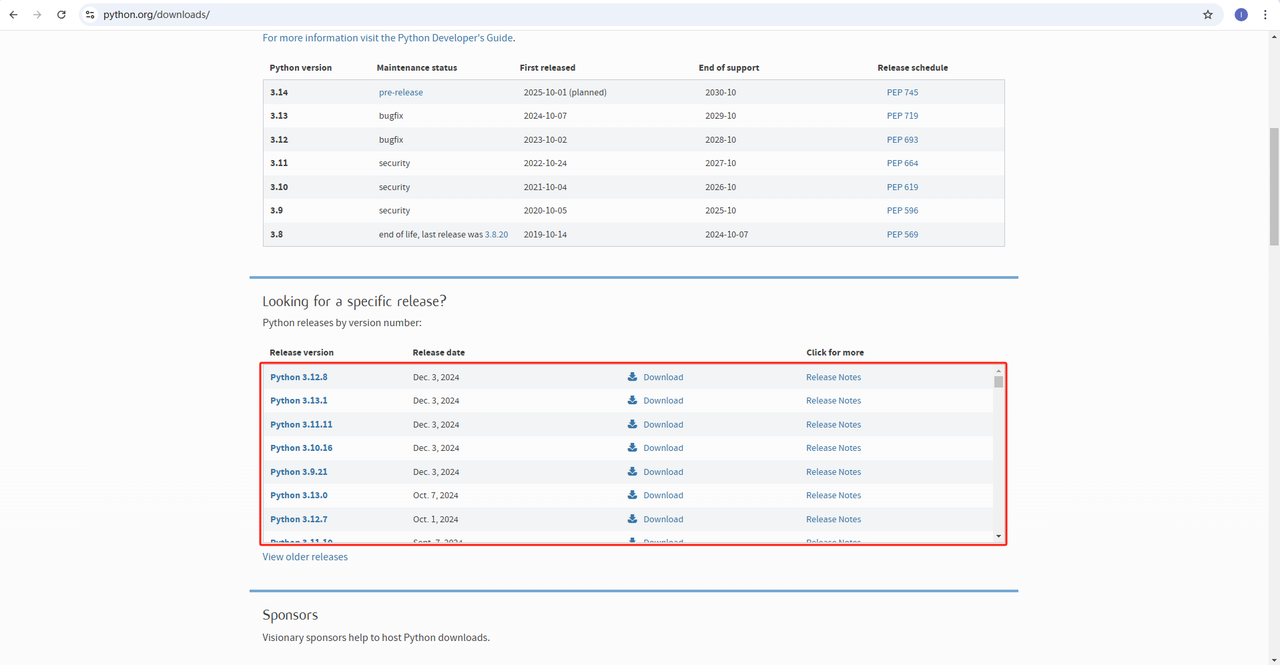
- Python:此处是运行Python的核心软件。您可以从官方网站链接下载所需的版本,如下图所示,但建议不要下载最新版本。您可以下载最新版本之前的1-2个版本。
- Python IDE:任何支持Python的IDE都可以,但我们推荐PyCharm,它是一款专门为Python设计的IDE开发工具软件。对于PyCharm版本,我们推荐免费的PyCharm Community Edition。
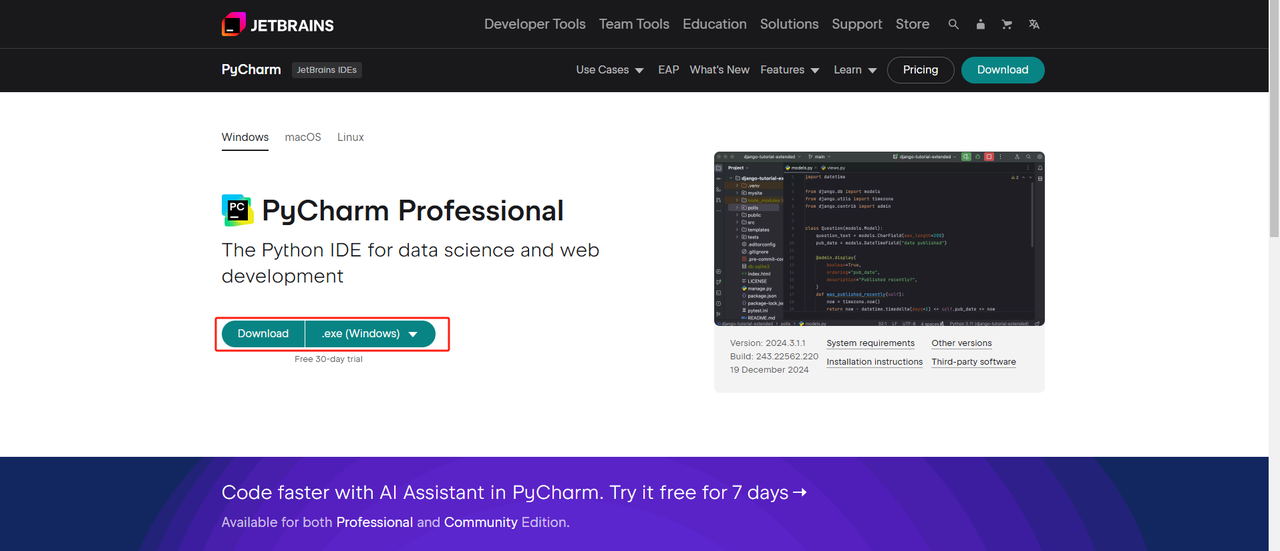
- Pip:您可以使用Python包索引,通过单个命令安装运行程序所需的库。
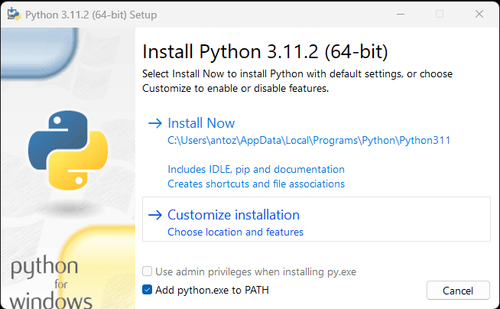
注意:如果您是Windows用户,请不要忘记在安装向导中选中“将python.exe添加到PATH”选项。这将允许Windows在终端中使用Python和命令。由于Python 3.4或更高版本默认包含它,因此您无需手动安装它。
通过以上步骤,就搭建好了爬取Google购物数据的环境。接下来,您可以使用下载的PyCharm结合Scraperless爬取Google购物数据。
步骤2:使用PyCharm和Scrapeless爬取Google购物数据
- 启动PyCharm并从菜单栏中选择文件>新建项目…
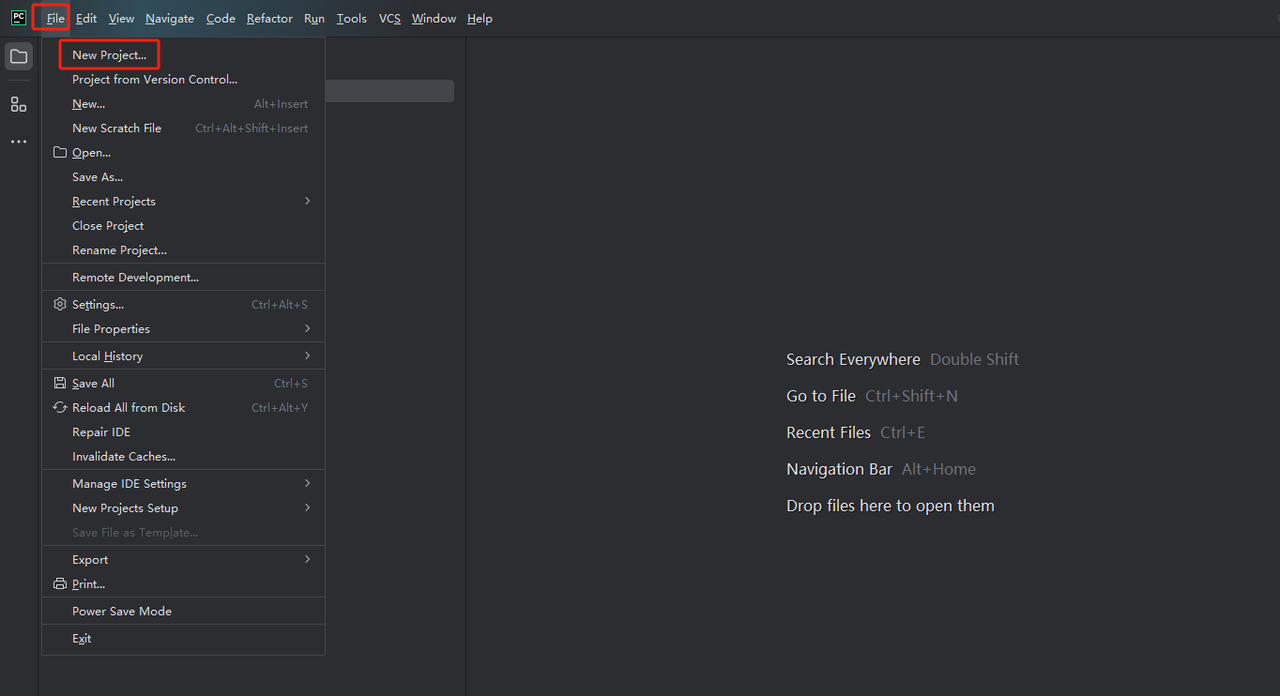
- 然后,在弹出的窗口中,从左侧菜单中选择纯Python,并按照如下方式设置您的项目:
注意:在下面的红色方框中,选择在环境配置第一步中下载的Python安装路径
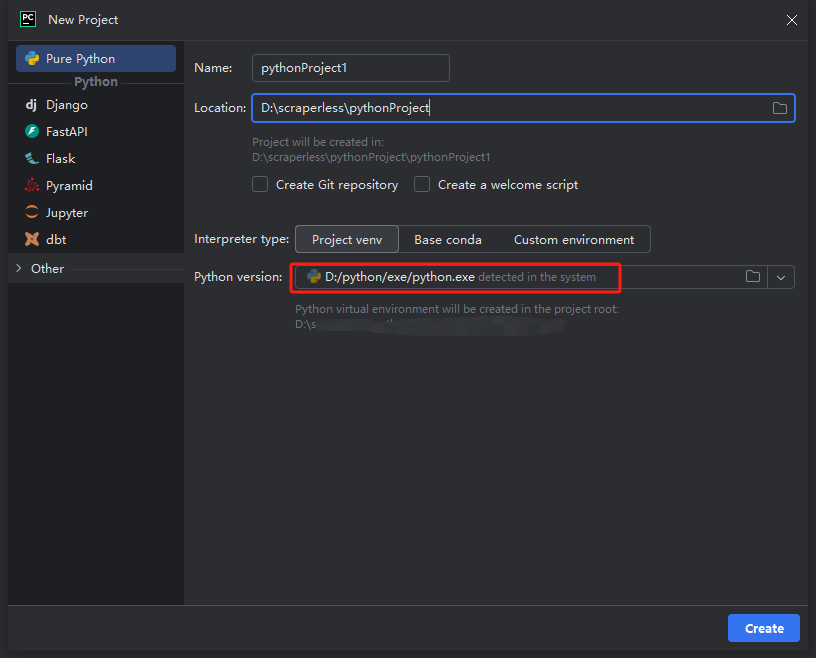
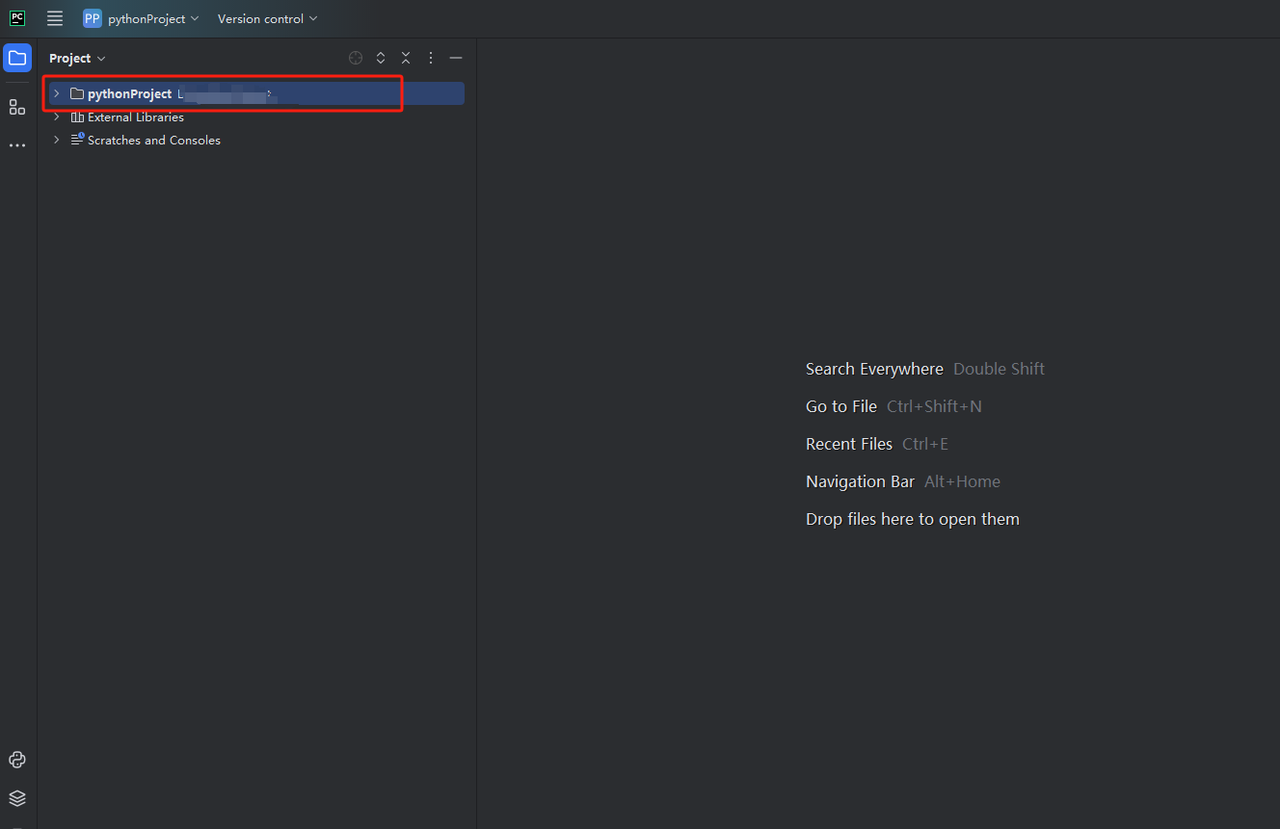
- 您可以创建一个名为python-scraper的项目,选中“在文件夹中创建main.py欢迎脚本选项”,然后点击“创建”按钮。PyCharm设置项目一段时间后,您应该会看到以下内容:
- 然后,右键单击以创建一个新的Python文件。
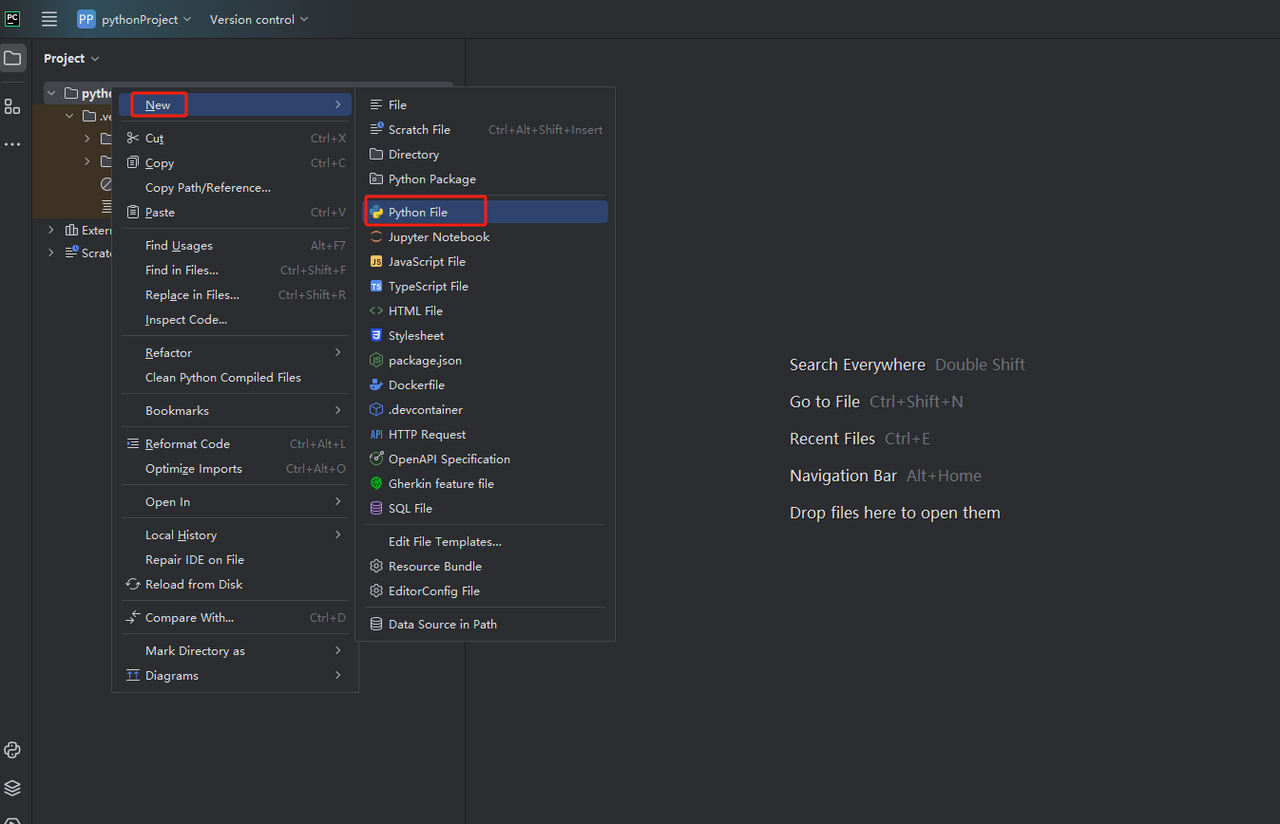
- 要验证一切是否正常工作,请打开屏幕底部的“终端”选项卡,然后键入:python main.py。启动此命令后,您应该会得到:Hi, PyCharm。
步骤3:注册Scrapeless并获取您的API密钥
现在您可以直接将Scrapeless代码复制到PyCharm中并运行它,以便您可以获取Google购物的JSON格式数据。但是您需要先获取Scrapeless API密钥。
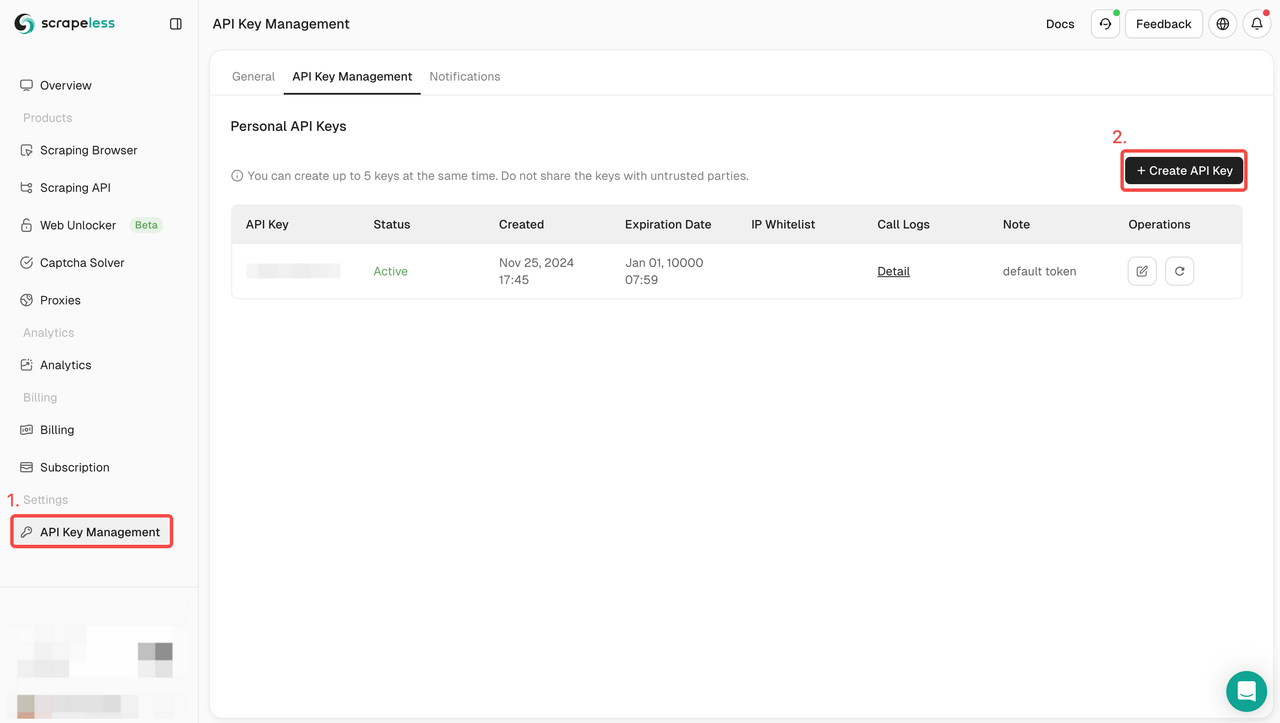
- 如果您还没有帐户,请注册Scrapeless。注册后,登录到您的仪表板。
- 在您的Scrapeless仪表板中,导航到API密钥管理,然后点击创建API密钥。您将获得您的API密钥。只需将鼠标放在上面并点击它即可复制它。此密钥将在调用Scrapeless API时用于验证您的请求。
步骤4:了解Scrapeless Google购物API参数
| 参数 | 必需 | 描述 |
|---|---|---|
| engine | TRUE | 将参数设置为google_shopping以使用Google购物API引擎。 |
| q | TRUE | 参数定义您要搜索的查询。您可以使用在常规Google购物搜索中使用的任何内容。 |
| location | FALSE | 参数定义您希望搜索从何处开始。如果多个位置与请求的位置匹配,我们将选择最受欢迎的一个。location和uule参数不能一起使用。建议在城市级别指定位置。 |
| uule | FALSE | 参数是您要用于搜索的Google编码位置。uule和location参数不能一起使用。 |
| gl | FALSE | 参数定义用于Google搜索的国家/地区。它是两位数的国家代码。(例如,us代表美国,uk代表英国,或fr代表法国)。默认为us。 |
| hl | FALSE | 参数定义用于Google地图搜索的语言。它是两位数的语言代码。(例如,en代表英语,es代表西班牙语,或fr代表法语)。默认为en。 |
| tbs | FALSE | (待搜索)参数定义常规查询字段中不可能实现的高级搜索参数。 |
| direct_link | FALSE | 参数确定搜索结果是否应包含指向每个产品的直接链接。默认情况下,它是false。如果您需要直接链接,请将其设置为true。此参数仅适用于新布局(美国和其他几个国家/地区)。 |
| start | FALSE | 参数定义结果偏移量。它跳过给定数量的结果。它用于分页。(例如,0(默认)是结果的第一页,60是结果的第二页,120是结果的第三页,依此类推)。对于新布局,不推荐使用此参数。 |
| num | FALSE | 参数定义要返回的结果最大数量。(例如,60(默认)返回60个结果,40返回40个结果,100(最大)返回100个结果)。任何大于100的数字都将默认为100。任何小于1的数字都将默认为60。 |
步骤5:如何将Scrapeless API集成到您的爬取工具中
获得API密钥后,您可以开始将Scrapeless API集成到您自己的爬取工具中。以下是如何使用Python和requests调用Scrapeless API并检索数据的示例。
代码集成示例:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_shopping",
"q": "Macbook M3"
}
payload = Payload("scraper.google.shopping", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()将“your_token”替换为您的Scrapeless API密钥。您也可以根据上面的API参数信息自定义您的爬取代码。
步骤6:分析结果数据
Scrapeless API的结果数据将包含JSON格式的详细信息。以下是结果数据的局部示例,具体信息可以在API文档中查看。
探索其他电子商务API进行数据抓取
除了从Google购物抓取产品数据外,您还可以通过其他电子商务平台收集和分析市场趋势,了解不同平台上的产品表现、价格变化和销售趋势。
- 亚马逊API:通过我们的亚马逊API,您可以高效地抓取亚马逊产品数据,了解价格、评论和库存。
- Shopee API:获取Shopee平台的产品数据,深入了解东南亚市场的商品需求。
- Shein API:通过Shein API,分析全球快时尚行业的数据,了解消费者的喜好和趋势。
如果您的业务需要从这些电子商务平台抓取数据,或者您有类似的需求,我们的API接口提供强大的数据抓取能力,让您可以轻松获取多个电子商务平台的产品数据。如果您需要定制化的解决方案,请联系我们的销售团队,我们将根据您的具体需求为您提供最好的服务。
加入我们的Scrapeless Discord社区!🎉 获取Scrapeless免费试用的独家访问权限。不要错过——点击链接,这是一个限时优惠!
Scrapeless Deep SerpApi:您强大的Google SERP API工具
Deep SerpApi是一个专门为大型语言模型(LLM)和AI代理设计的专业搜索引擎API。它提供实时、准确和公正的信息,使AI应用程序能够高效地从Google及其他地方检索和处理数据。
✅ 综合数据覆盖接口:涵盖20多个Google SERP场景和主流搜索引擎。
✅ 经济高效:Deep SerpApi提供从每千次查询0.10美元起的价格,响应时间为1-2秒,使开发人员和企业能够高效且低成本地获取数据。
✅ 高级数据集成能力:可以整合来自所有可用在线渠道和搜索引擎的信息。
✅ 获取实时更新,数据在过去24小时内刷新。
作为我们未来路线图的一部分,我们完全致力于满足AI开发人员的需求,简化动态网络信息与AI驱动解决方案的集成。目标是提供一个一体化API,允许通过单个调用无缝搜索和数据提取。
🎺🎺激动人心的公告!
开发者支持计划:将Scrapeless Deep SerpApi集成到您的AI工具、应用程序或项目中。[我们已经支持Dify,并将很快支持Langchain、Langflow、FlowiseAI和其他框架]。然后在GitHub或社交媒体上分享您的成果,您将获得1-12个月的免费开发者支持,每月最多500美元。
结论
总之,使用Scrapeless抓取Google购物结果提供了一种有效的方法来收集有价值的数据,用于分析、产品研究和比较。通过遵循本文中概述的分步指南,您可以轻松设置必要的工具,将Scrapeless API集成到您的工作流程中,并开始以符合规定且高效的方式提取相关信息。无论您是开发人员还是希望利用Google购物数据的企业主,该过程都简单且可扩展。请记住始终遵守有关网络抓取的法律和道德准则。
常见问题
Q1:如何调整每页的结果数量?
要调整每页返回的结果数量,请使用limit参数。例如,设置"limit": 20将返回每个请求20个结果。
Q2:如何爬取其他页面?
使用page参数爬取其他页面。例如,"page": 2将返回第二页的结果。
Q3:我可以从多个位置爬取数据吗?
是的,您可以使用location参数指定国家或地区。例如,"location": "UK"将从英国抓取Google购物结果。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


