
如何绕过反机器人检测?
Senior Web Scraping Engineer
在自动化与安全的战斗中,反机器人机制已成为网络的守门人,阻止不必要的机器人的同时,往往妨碍合法的数据收集。
从登录页面到电子商务网站,这些防御措施—尤其是验证码—对于网络爬虫和自动化工具来说,可能是令人沮丧的障碍。有没有办法绕过它们?
本文深入探讨反机器人系统的世界,探索它们如何检测自动化,并揭示在不跨越法律或道德界限的情况下绕过限制的伦理策略。
让我们开始阅读吧!
为什么会有反机器人检测?
好吧,让我们先享受一下旅行。想象一下经营一家商店,顾客可以自由浏览,但每隔几分钟,一个戴面具的人冲进来,抓走你所有的产品,然后消失。你此时想什么?
这就是网站对机器人的感觉!反机器人检测的存在是为了区分真实用户和自动化脚本,防止凭证填充、内容盗窃和激进的网络爬取。
从验证码到浏览器指纹,这些数字保镖不知疲倦地工作,以阻挡坏机器人——但有时,它们也会让那些只是想获取数据的好心开发者绊倒。
那么,有没有不违反规则的办法可以智胜它们呢?我们可以找到更多。
常见的反机器人机制
- 头部验证:头部验证分析传入的HTTP头部,并检查是否需要阻止它们。
- IP封锁:根据IP地址限制访问。
- 速率限制:限制来自单一IP的请求数量。
- 浏览器指纹:分析浏览器属性和行为。
- TLS指纹:TLS指纹通过分析握手参数并阻止具有意外值的请求来检测机器人。
- 蜜罐:隐形陷阱来引诱机器人。
- 验证码挑战:设计易于人类但对机器难的挑战。
验证码:关键的反机器人机制
什么是验证码?
验证码,全称为完全自动化的公共图灵测试,以区分计算机与人类,是一种旨在区分真实用户和自动化机器人的安全机制。通过提出人类容易但机器难以完成的挑战,验证码帮助防止恶意活动,如垃圾邮件、凭证填充和自动网络爬取。
验证码的类型:
- 基于文本的验证码:用户必须识别并输入扭曲或模糊的文本,这对机器人来说是一个挑战。
- 基于图像的验证码:用户识别图像中的物体,如交通灯或商店,这一任务需要超出大多数机器人的视觉识别技能。
- reCAPTCHA:谷歌的高级验证码系统,包括多种形式—简单的复选框验证(“我不是机器人”)、图像选择挑战和分析用户行为而无需明确互动的隐形验证码。
- hCAPTCHA:注重隐私的reCAPTCHA替代品,旨在最小化数据跟踪,同时仍提供有效的机器人保护。
验证码的工作原理:
验证码基于挑战-响应机制,用户必须完成一项任务以证明他们是真实的。系统评估响应和行为,如鼠标移动、打字速度或交互模式,以确定真实性。
现代验证码系统利用机器学习根据不断发展的机器人能力调整其难度级别。它们分析行为数据,采用基于风险的评估,甚至整合生物特征线索,以提高准确性和安全性,越来越难以让机器人绕过这些防御。
绕过反机器人的最佳实践
为什么选择Scrapeless?
Scrapeless拥有强大的验证码解决方案,使得在验证码保护的网站上无缝导航,以确保数据提取不间断。
- 实惠的定价:Scrapeless提供具有成本效益的验证码解决方案,同时不牺牲效率。
- 稳定性和可靠性:凭借良好的业绩记录,Scrapeless在高工作负荷下始终能够成功解决验证码,确保自动化的顺利进行。
- 高成功率:不再有验证码障碍——Scrapeless在绕过验证码挑战方面实现了99.99%的成功率。
- 可扩展性:轻松处理数千个验证码保护的请求,得益于Scrapeless强大的基础设施。
Scrapeless昂贵吗?
Scrapeless以竞争力的价格 (与Zenrows和Apify比较)提供可靠且可扩展的网络爬取平台,确保用户获得良好的价值:
- 验证码解决方案:每1000个URL起价从$0.8
- 爬取浏览器:每小时起价从$0.09
- 爬取API:每1000个URL起价从$0.8
- 网站解锁器:每1000个URL收费$0.2
- 代理:每 GB 2.8 美元
加入我们的社区,以获取免费试用和更多折扣!
绕过反机器人检测:Scrapeless CAPTCHA 解码器指南
- 第一步。登录 Scrapeless。
- 第二步。进入“CAPTCHA 解码器”界面。点击 reCAPTCHA 解锁服务并选择您需要适应的 reCAPTCHA 类型:普通或企业。
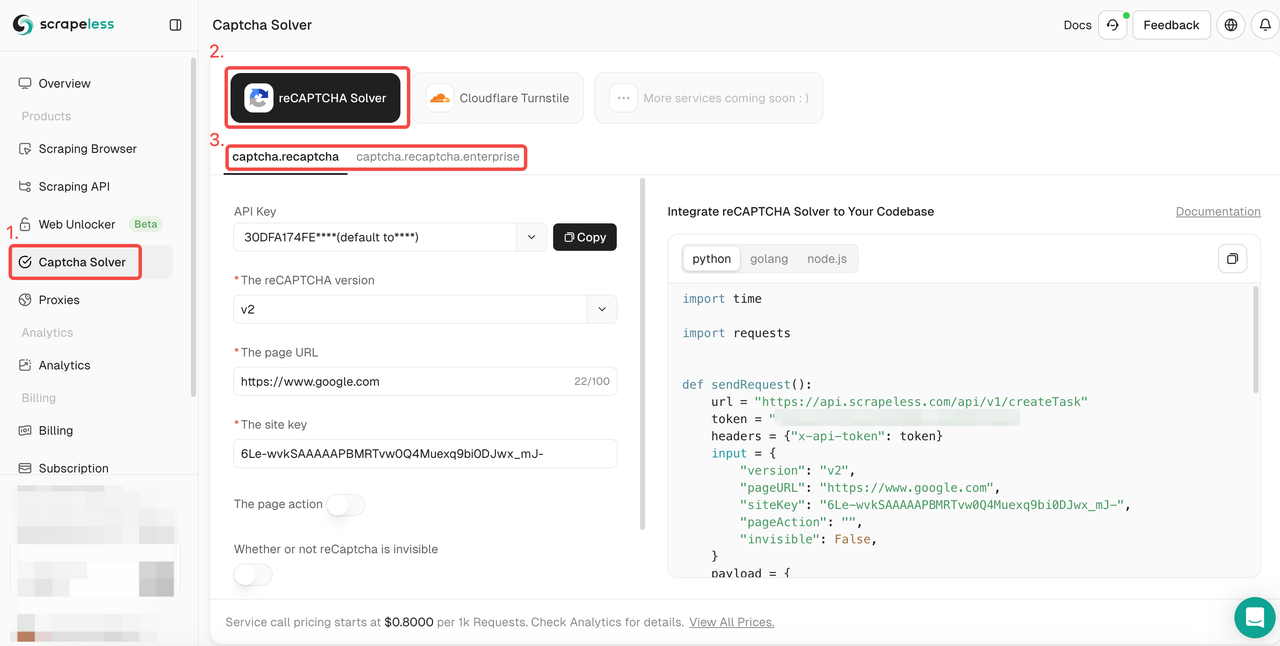
- 第三步。在左侧操作框中配置您需要的相关信息:reCAPTCHA 版本、页面 URL、网站密钥、操作、代理等。
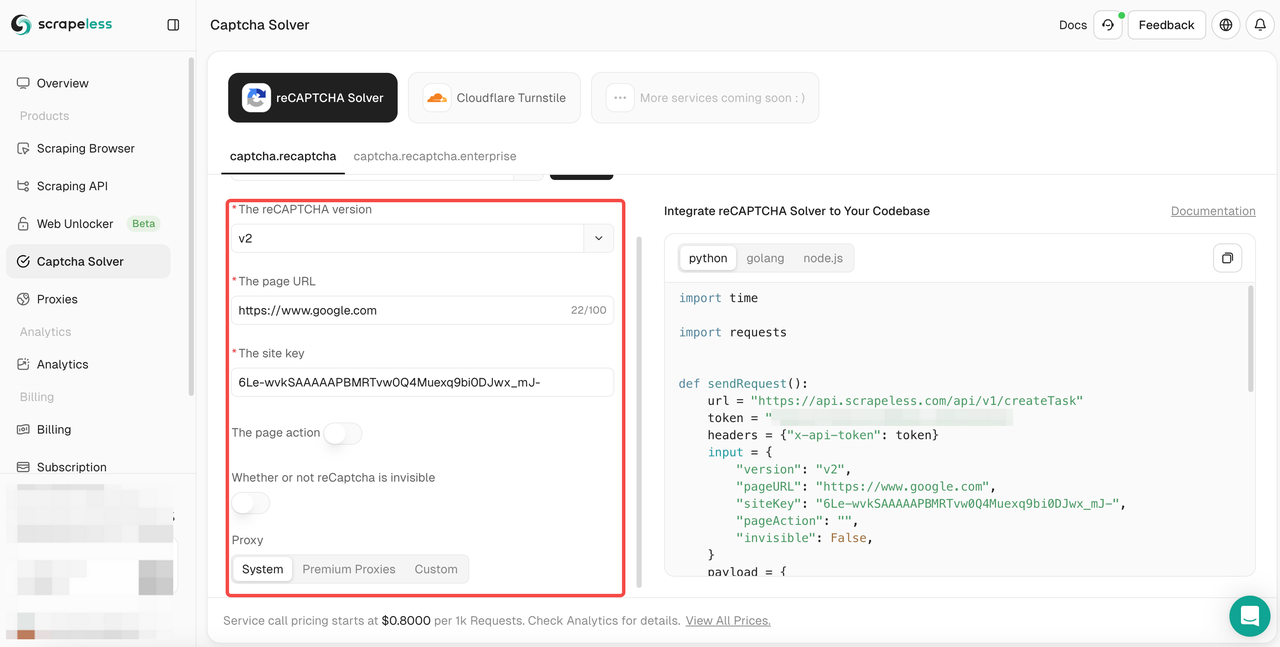
- 第四步。完成配置后,您可以在右侧代码框中获取相关代码反馈。您只需复制并将其集成到您的程序中。这里我们以抓取 scrapeless.com 为例。我们将解锁 v2 reCAPTCHA,使用高级代理并将其配置为“新加坡”,并将页面操作设置为“抓取”。以下是我获得的代码反馈:
Python
import time
import requests
def sendRequest():
url = "https://api.scrapeless.com/api/v1/createTask"
token = "xxx"
headers = {"x-api-token": token}
input = {
"version": "v2",
"pageURL": "https://www.scrapeless.com/en",
"siteKey": "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-",
"pageAction": "scraping",
"invisible": False,
}
payload = {
"actor": "captcha.recaptcha",
"input": input
}
# 创建任务
result = requests.post(url, json=payload, headers=headers).json()
taskId = result.get("taskId")
if not taskId:
print("任务创建失败:", result)
return
print(f"创建了一个任务: {taskId}")
# 查询结果
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + taskId
resp = requests.get(url, headers=headers)
result = resp.json()
if resp.status_code != 200:
print("任务失败:", resp.text)
return
if result.get("success"):
return result["solution"]["token"]
data = sendRequest()
print(data)actor: 当前任务的执行者state: 当前任务的状态success: 任务是否成功taskId: 如果任务成功创建,您将获得一个 taskId。然后您需要使用此 taskId 查询结果solution: 如果任务成功,您将收到解决方案message: 如果任务失败,请检查此错误消息
要获取更多信息,请参考我们的文档教程。
绕过反机器人的高级策略与 CAPTCHA 解码器
绕过反机器人措施,如 CAPTCHA,需要结合尊重抓取和高级技术。以下是保持高效和道德的抓取操作的方法。
尊重抓取实践
- 遵循 robots.txt:始终检查网站的
robots.txt文件,以遵循有关可以抓取内容的指南。 - 限制请求速率:在请求之间引入随机延迟,以模拟人类浏览行为,避免快速、连续的请求触发封锁。
- 轮换用户代理:使用一个真实的用户代理池,以模拟不同的浏览器和设备,避免因静态用户代理字符串而被检测到。
逐步技术
- 住宅代理:使用住宅代理在多个 IP 地址之间分配请求,使网站更难以阻止您。
- 无头浏览器:像 Puppeteer 和 Selenium 这样的工具模拟真实用户交互,使反机器人系统更难检测到您的抓取活动。
- 机器学习反检测:训练机器人更接近人类行为,通过分析浏览模式,减少被标记为机器人的机会。
一切都结束了
恭喜您!您学习了很多关于反机器人检测的知识。您已从基础知识成长为反检测大师!
现在您了解:
- 什么是反机器人。
- 绕过反机器人技术的一些最佳实践。
- 一些反机器人依赖的最流行机制。
- 如何绕过它们。
您可以发现更多反抓取技术,但无论您的抓取器多么复杂,有些技术仍然能够阻止它。
通过使用 Scrapeless,一个具有先进代理、内置 IP 轮换、无头浏览器能力和高级反机器人绕过能力的网页抓取 API,所有这些问题都可以避免。这是抓取网页的更简单方法。
立即开始您的免费试用!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


