
如何使用稳定的代理绕过反机器人检测?
Expert Network Defense Engineer
许多网站已经开始实施反机器人防护措施,因为网络爬虫变得越来越普遍。这些措施涉及复杂的技术,阻止自动化软件获取其信息。网站可能限制您的网络爬虫可以发出的请求数量,或者如果发现您,它会完全阻止您。
您可以找到反机器人检测的最常见方式,并学习如何绕过它。
现在开始滚动吧!
什么是反机器人验证?
反机器人验证技术指的是识别和阻止机器人执行的自动化活动的系统和技术。机器人是指为自主执行在线任务而创建的软件。尽管“机器人”这个名称有负面含义,但并非所有的机器人都是这样的。例如,谷歌爬虫也是机器人!
与此同时,恶意机器人占全球所有在线流量的至少27.7%。它们从事诸如DDoS攻击、垃圾邮件和身份盗窃等犯罪活动。为了保护用户隐私并增强用户体验,网站旨在避免这些活动,甚至可能会禁止您的网络爬虫。
反机器人过滤器使用多种技术,如HTTP头验证、指纹识别和验证码,来区分真实用户和自动化程序。
为什么网站会部署反机器人措施?
对于网站拥有者而言,反机器人技术可以帮助他们消除大多数干扰和挑战:
- 数据保护:反机器人措施防止未经授权抓取敏感或专有信息。
- 服务可靠性:机器人可能消耗过多的服务器资源并降低用户体验,反机器人系统可以减轻这种风险。
- 防止欺诈:反机器人检测系统对抗诸如虚假账户创建、票务炒作和广告欺诈等活动。
- 用户隐私:通过阻止未经授权的机器人,这些系统帮助保护用户数据不被利用。
反机器人技术如何工作?
反机器人系统通过结合多种技术来检测和抵制自动化活动:
头部验证
头部验证是常见的反机器人保护技术。它分析传入HTTP请求的头部,以寻找异常和可疑模式。如果系统检测到任何不正常的情况,它会将请求标记为来自机器人并阻止它们。
所有浏览器请求都带有许多数据在头部。如果某些字段缺失、没有正确的值或顺序不正确,反机器人检查系统将阻止该请求。
行为分析
反机器人验证机制分析用户的互动,如鼠标移动、按键和浏览模式。不自然或高度重复的行为可能表明机器人活动。
IP地址监控
许多网站使用基于位置的阻止方法,包括阻止来自特定地理区域的请求,以限制某些国家的用户访问其内容。政府以类似方式使用这一策略来禁止他们国家内的某些网站。
地理封禁在DNS或ISP级别上实施。
这些系统检查用户的IP地址,以确定用户的位置并决定是否阻止他们。因此,为了抓取被地理封锁的目标,您需要来自允许国家的IP地址。
您需要一个代理服务器来绕过基于位置的阻止政策,优质代理通常允许您选择服务器所在的国家。这样,网络爬虫的查询将来自正确的位置。
您是否厌倦了持续的网络爬虫封锁?
Scrapeless Rotate Proxy帮助避免IP禁令
立即获取免费试用!
浏览器指纹识别
浏览器指纹识别是通过收集用户设备数据来识别网络客户端的过程。它可以通过查看许多因素,如已安装的字体、浏览器插件、屏幕分辨率等,来分辨请求是来自合法用户还是爬虫。
大多数浏览器指纹识别实施策略涉及客户端技术来收集用户数据。
上述脚本收集用户数据以进行指纹识别。
这种反机器人软件通常预期请求来自浏览器。您需要一个无头浏览器来绕过它,否则,您将被识别为机器人。
验证码挑战
网站使用挑战-响应测试或验证码来判断用户是否为人类。反机器人解决方案采用这些技术来阻止爬虫访问网站或执行某些任务,因为人类可以轻松解决这个问题,但机器人很难做到。
用户必须在页面上完成某个活动,例如输入扭曲图片中显示的数字或选择一组图像,以回答验证码。
TLS指纹识别
分析在TLS握手过程中传输的参数被称为TLS指纹识别。反机器人验证系统在识别请求为来自机器人时,如果这些参数与应有的参数不匹配,则会阻止该请求。
请求验证
反机器人验证系统验证HTTP请求的真实性。可疑的头部、无效的用户代理字符串或者缺失的Cookies可能表明请求来自机器人流量。
避免反机器人检测的5种方法
绕过反机器人检查系统可能并不简单,但你可以尝试一些特定的方法。可以考虑的策略清单如下:
1. 无扰动的轮换代理
Scrapeless提供高端的全球清洁IP代理服务,专注于动态住宅IPv4代理。
Scrapeless住宅代理网络拥有超过7000万个IP,涵盖195个国家,提供全面的全球代理支持,推动您的业务增长。
我们支持包括网络爬虫、市场调研、SEO监测、价格比较、社交媒体营销、广告验证和品牌保护等广泛的使用案例,使您能够无缝地在全球市场中运营您的业务。
如何获取您的特殊代理?请按照我的步骤操作:
- 步骤1. 登录 Scrapeless。
- 步骤2. 点击“代理”,并创建一个通道。
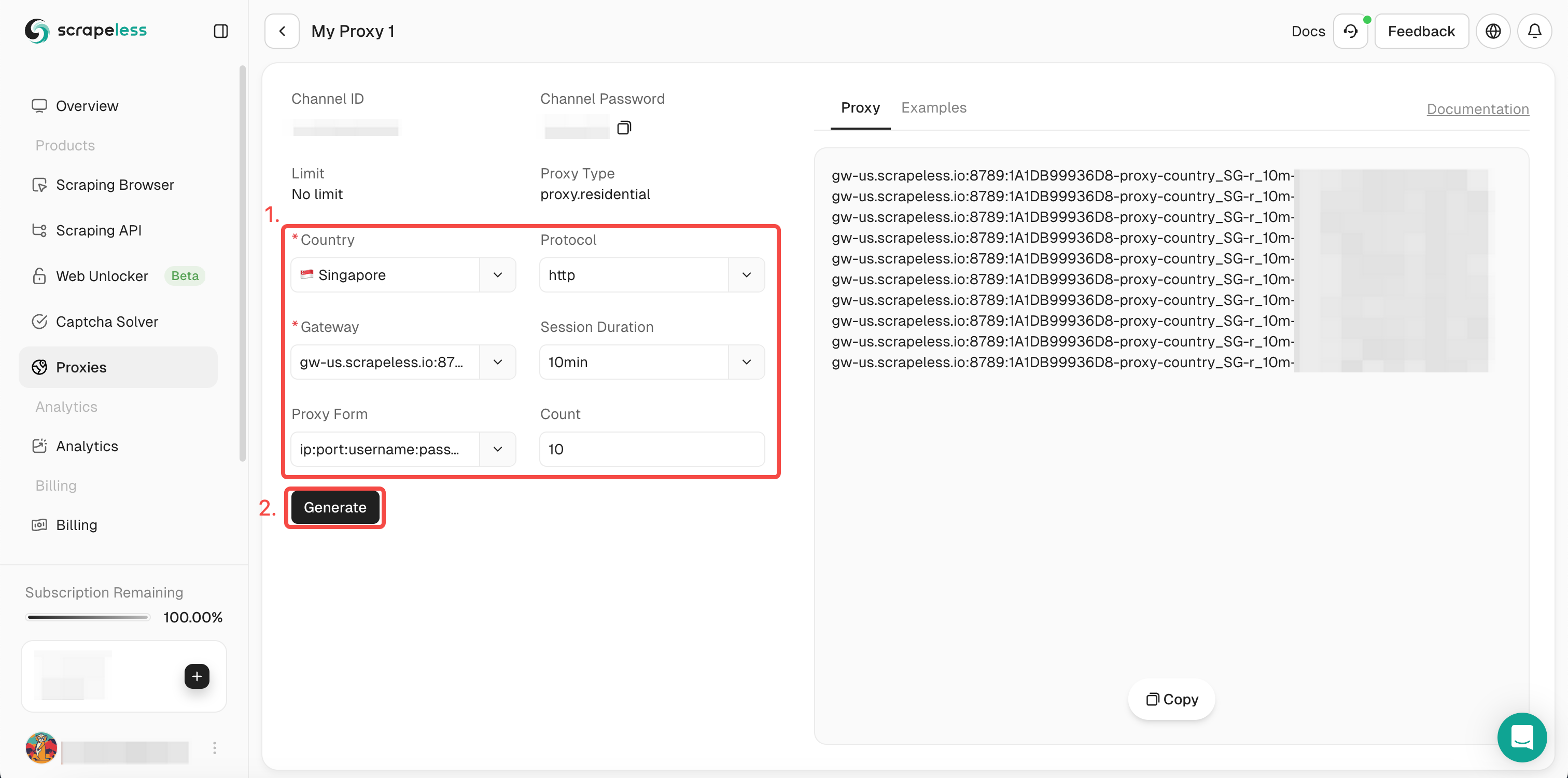
- 步骤3. 在左侧操作框中填写所需信息。然后点击“生成”。过一会儿,您可以在右侧看到我们为您生成的轮换代理。现在只需点击“复制”以使用它。
或者您可以直接将我们的代理代码集成到您的项目中:
- 代码:
C
curl --proxy host:port --proxy-user username:password API_URL- 浏览器:
- Selenium
Python
from seleniumbase import Driver
proxy = 'username:password@gw-us.scrapeless.com:8789'
driver = Driver(browser="chrome", headless=False, proxy=proxy)
driver.get("API_URL")
driver.quit()- Puppeteer
JavaScript
const puppeteer =require('puppeteer');
(async() => {
const proxyUrl = 'http://gw-us.scrapeless.com:8789';
const username = 'username';
const password = 'password';
const browser = await puppeteer.launch({
args: [`--proxy-server=${proxyUrl}`],
headless: false
});
const page = await browser.newPage();
await page.authenticate({ username, password });
await page.goto('API_URL');
await browser.close();
})();2. 遵守robots.txt
此文件作为网站的标准,指示文件或页面是否对机器人可访问或不可访问。网络爬虫可以通过遵循指定的标准来防止反机器人措施的触发。了解有关为网络爬虫目的阅读robot.txt文件的更多信息。
限制来自同一IP地址的查询数量:网络爬虫有时会迅速向一个网站发送许多请求。您可以考虑最小化来自同一IP地址的查询数量,因为这种行为可能会触发反机器人系统。研究使用网络爬虫时绕过速率限制的方法。
3. 修改您的用户代理
用户代理的HTTP头包含一个字符串,这个字符串指示请求来源的浏览器和操作系统。由于这个头已经被修改,请求看起来像是来自普通用户。查看网络爬虫常用用户代理的列表。
4. 使用无头浏览器
无头浏览器没有图形用户界面,但仍然可以控制。使用这样一个工具,您可以通过模拟人类用户的行为(即滚动)来防止您的爬虫被识别为机器人。了解更多关于无头浏览器的信息,以及哪些浏览器适合网络爬虫。
5. 通过在线爬虫API简化流程
通过简单的API调用,网络爬虫API使用户能够在不被反机器人系统检测的情况下抓取网站。因此,网络爬虫变得快速、简单且高效。
立即尝试Scrapeless爬虫API,看看最强大的网络爬虫API能提供什么。
总结
在本教程中,您已经了解了很多关于反机器人检测的内容。绕过反机器人检测对您来说简直是小菜一碟。
哪种方法最有效以避免阻止呢?
使用 Scrapeless 这款在线抓取工具,凭借其先进的验证码解决方案、内置的 IP 轮换、无头浏览器功能和网页解锁器,您可以轻松避开所有这些问题!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


