
Cách dùng Python để Scrape dữ liệu Expedia?
Expert Network Defense Engineer
Expedia là trang web hàng đầu dành cho khách du lịch! Người dùng có thể dễ dàng tìm thấy thông tin du lịch toàn diện và chính xác trên đó: từ giá vé máy bay đến cho thuê kỳ nghỉ và cho thuê xe hơi. Ngoài việc tìm kiếm thông tin, Expedia cũng cho phép người dùng đặt vé máy bay, chỗ ở và phương tiện thuê trực tiếp trên trang web của mình, biến nó thành một nguồn tài nguyên quý giá cho dữ liệu liên quan đến du lịch.
Tuy nhiên, Expedia không cung cấp API scraping, điều này khiến việc trực tiếp scrape một lượng lớn thông tin chuyến bay trở nên khó khăn. Do số lượng trang lớn, việc thu thập dữ liệu này bằng tay là không khả thi.
Hãy tìm hiểu thêm về cách dễ dàng scrape thông tin chuyến bay chính xác trên Expedia trong bài viết này.
Bắt đầu đọc ngay!
Tại sao dữ liệu của Expedia lại quan trọng?
Bằng cách crawl dữ liệu của Expedia, bạn có thể thu được thông tin thị trường phong phú để giúp các công ty đưa ra quyết định thông minh hơn trong ngành du lịch. Cho dù đó là tối ưu hóa chiến lược hoạt động hay cung cấp cho khách hàng các lựa chọn tiết kiệm chi phí hơn, những dữ liệu này đều có thể đóng vai trò quan trọng.
- Phân tích thị trường: Phân tích xu hướng thị trường và giá cả cạnh tranh để giúp các đại lý du lịch phát triển chiến lược cạnh tranh hơn.
- So sánh giá: So sánh giá trên các nền tảng khác nhau theo thời gian thực để đảm bảo lựa chọn tốt nhất cho khách hàng.
- Giám sát hàng tồn kho: Theo dõi hàng tồn kho vé máy bay, khách sạn và cho thuê xe hơi, và điều chỉnh nguồn cung kịp thời để đáp ứng nhu cầu.
- Dự báo xu hướng: Dự đoán xu hướng du lịch dựa trên dữ liệu lịch sử và lên kế hoạch nguồn lực trước.
Tại sao việc scrape dữ liệu từ Expedia lại khó khăn?
Giống như hầu hết các trang web hiện đại, Expedia là một trang web động sử dụng rất nhiều JavaScript để hiển thị nội dung và xử lý tương tác của người dùng. Do đó, việc scrape bằng các công cụ scrape web dựa trên HTML truyền thống như Beautiful Soup và Cheerio là khó khăn vì chúng không thể thực thi JavaScript.
2 Phương pháp để Scrape dữ liệu Expedia bằng Python
Phương pháp 1. Scrapeless Scraping API (Lựa chọn tốt nhất)
Scrapeless là một bộ công cụ tất cả trong một mạnh mẽ và hiệu quả để trích xuất dữ liệu từ Expedia và các trang web liên quan đến du lịch khác. Nó cung cấp một cách liền mạch để thu thập thông tin có giá trị mà không gặp phải những thách thức kỹ thuật của việc tự xây dựng trình scrape của riêng bạn.
Scrapeless cung cấp dịch vụ API scraping Expedia giá cả phải chăng, ổn định và an toàn. Nó giúp bạn có được chi tiết chuyến bay và khách sạn trong vòng 3 giây. Bạn chỉ cần cấu hình các tham số và nhập mã thông báo API của mình.
- Trích xuất dữ liệu toàn diện: Scrapeless có thể scrape dữ liệu du lịch bao gồm chuyến bay, giá khách sạn, cho thuê xe hơi, và hơn thế nữa, đảm bảo bạn có được tất cả thông tin cần thiết.
- Giải pháp tùy chỉnh: Có sẵn các giải pháp scraping được thiết kế riêng để đáp ứng nhu cầu kinh doanh cụ thể của bạn, cho dù đó là để phân tích thị trường, giá cả cạnh tranh hay giám sát hàng tồn kho.
- Xử lý nội dung động: Các kỹ thuật tiên tiến để quản lý các trang web sử dụng nhiều JavaScript đảm bảo trích xuất dữ liệu đầy đủ và chính xác.
- Khả năng mở rộng và đáng tin cậy: Có khả năng xử lý việc scrape dữ liệu quy mô lớn để cung cấp các dự án một cách đáng tin cậy và hiệu quả, cung cấp cho bạn dữ liệu kịp thời và nhất quán.
- Chuyển dữ liệu: Bạn có thể chuyển mã Scrapeless trực tiếp vào cơ sở dữ liệu của mình, đảm bảo tích hợp liền mạch với các hệ thống hiện có của bạn. Scrapeless hỗ trợ trả về và xuất dữ liệu định dạng JSON.
- Tuân thủ và đạo đức: Scrapeless đảm bảo tuân thủ các hướng dẫn pháp lý và đạo đức, tôn trọng các điều khoản dịch vụ của trang web và các quy định về quyền riêng tư dữ liệu.
Phương pháp 2. Tự xây dựng trình scrape Expedia Python của riêng bạn
Nhược điểm:
- Xây dựng công cụ scrape Google Maps của riêng bạn rất tốn thời gian.
- Bạn có thể gặp phải những thách thức như bị chặn IP, xác minh CAPTCHA, thiết lập nhiều proxy và quản lý giới hạn yêu cầu.
Scrape dữ liệu Expedia bằng Scrapeless với Python
Tiếp theo, chúng ta sẽ giải thích chi tiết cách kết hợp Python và Scrapeless API để crawl dữ liệu chuyến bay của Expedia.
Khi phát triển mà không có Scrapeless API, việc crawl trang web Expedia có thể yêu cầu xem xét tốc độ yêu cầu, proxy, kiểm soát rủi ro, gửi dữ liệu và các vấn đề khác, nhưng bây giờ sử dụng Scrapeless API, bạn chỉ cần cấu hình và chỉnh sửa cấu hình của dữ liệu bạn cần, và sau đó chạy chương trình, bạn có thể nhận được dữ liệu bạn cần.
Lưu ý: Mã và cấu hình liên quan sẽ được hiển thị sau
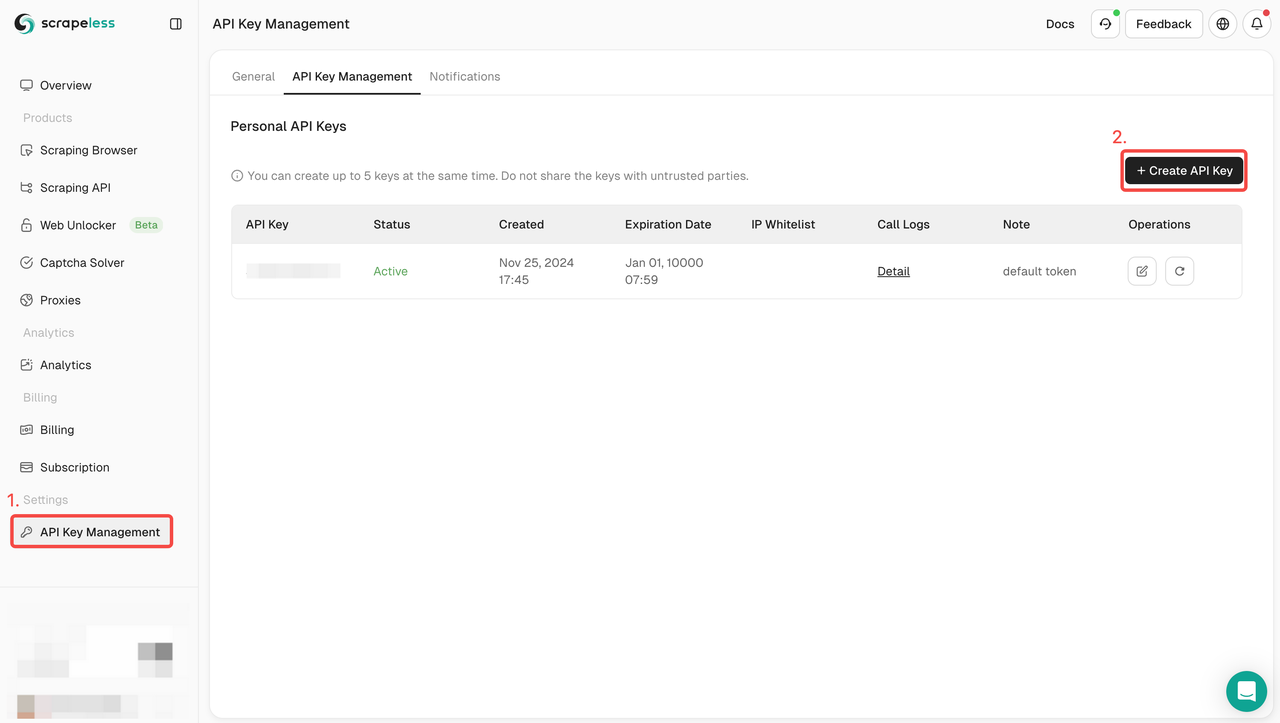
Bước 1. Lấy API Key của bạn
Để bắt đầu, bạn cần lấy API Key của mình từ Bảng điều khiển Scrapeless:
- Đăng nhập vào Bảng điều khiển Scrapeless.
- Điều hướng đến Quản lý API Key.
- Nhấp vào Tạo để tạo API Key duy nhất của bạn.
- Sau khi tạo, chỉ cần nhấp vào API Key để sao chép nó.
Sau khi hoàn tất đăng ký với Scrapeless, bạn sẽ nhận được số dư tìm kiếm miễn phí $2.
Bước 2. Viết mã yêu cầu Scrapeless API
Dưới đây là mã yêu cầu tham chiếu tôi đã viết. Bạn có thể điều chỉnh các giá trị cụ thể theo nhu cầu:
Python
payload = {
"actor": "scraper.expedia", # Dịch vụ cần gọi
"input": {
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan", # Địa chỉ khởi hành
"destination": "New York, NY, United States of America (NYC-All Airports)", # Điểm đến
"date": {"year": 2025, "month": 3, "day": 5}, # Ngày khởi hành
"cabin_class": "PREMIUM_ECONOMY", # Loại khoang
"travelers": {
"adult": 1, # Số lượng người lớn
"children": [], # Tuổi của trẻ em từ 2-17
"infants_on_lap": [], # Tuổi của trẻ sơ sinh từ 0-1
"infants_in_seat": [], # Tuổi của trẻ sơ sinh từ 0-1
},
"size": 20, # Số lượng dữ liệu trả về mỗi truy vấn, tối đa 20
"page": 0, # Số trang được truy vấn
},
}Bước 3. Tích hợp vào Scrapeless API
Nhớ API key mà chúng ta vừa tạo? Chúng ta cần truy cập chính thức vào dịch vụ Scrapeless API sau khi yêu cầu được viết. Vui lòng điền mã thông báo API của bạn vào mã bên dưới:
Python
url = "https://api.scrapeless.com/api/v1/scraper/request"
headers = {"x-api-token": api-key} # Nhập API-key của bạn
res = requests.post(url, json=payload, headers=headers)Toàn bộ mã:
Python
import time
import requests
api_key = "..."
headers = {"x-api-token": api_key}
payload = {
"actor": "scraper.expedia",
"input": {
"page": 0,
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan",
"destination": "New York, NY, United States of America (NYC-All Airports)",
"date": {"year": 2025, "month": 4, "day": 22},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": [],
},
"size": 20,
"page": 0,
},
}
url = "https://api.scrapeless.com/api/v1/scraper/request"
res = requests.post(url, json=payload, headers=headers)
print(data.text)
data = res.json()
# Nếu xảy ra sự cố hết thời gian chờ, chúng tôi trả về id tác vụ
if "taskId" in data:
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + data["taskId"]
resp = requests.get(url, headers=headers)
if resp.status_code != 200:
print("failed:", resp.text)
break
if "data" in resp.json():
print("succeed:", resp.text)
break
print(resp.text)Tham chiếu kết quả scraping

Đọc thêm:
- Làm thế nào để theo dõi chuyến bay rẻ nhất trên Google Flights?
- Làm thế nào để có được thông tin chuyến bay của Kayak?
Scrape dữ liệu Expedia thông qua APIDocs
Bạn cũng có thể scrape dữ liệu chuyến bay của Expedia trực tiếp trong tài liệu API của Scrapeless. Vui lòng tham khảo các bước sau.
- Bước 1. Tạo mã thông báo API của bạn (đã đề cập ở trên).
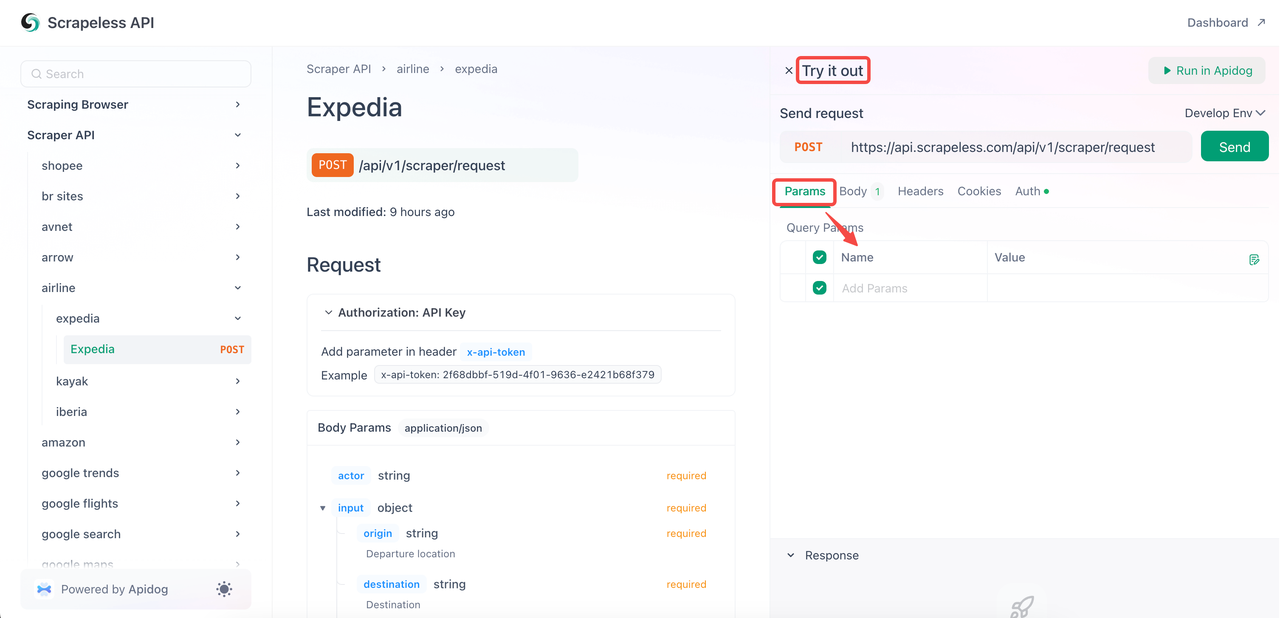
- Bước 2. Truy cập trang Expedia và nhấp vào "Thử nghiệm".
- Bước 3. Cấu hình các tham số bạn cần trong phần
Params. Bạn có thể xem toàn bộ nội dung mã trongBody.
Đây là mã yêu cầu để tham khảo:
Python
{
"actor": "scraper.expedia",
"input": {
"origin": "Tokyo (and vicinity), Tokyo Prefecture, Japan",
"destination": "New York, NY, United States of America (NYC-All Airports)",
"date": {
"year": 2025,
"month": 3,
"day": 5
},
"cabin_class": "PREMIUM_ECONOMY",
"travelers": {
"adult": 1,
"children": [],
"infants_on_lap": [],
"infants_in_seat": []
},
"size": 20,
"page": 0
}
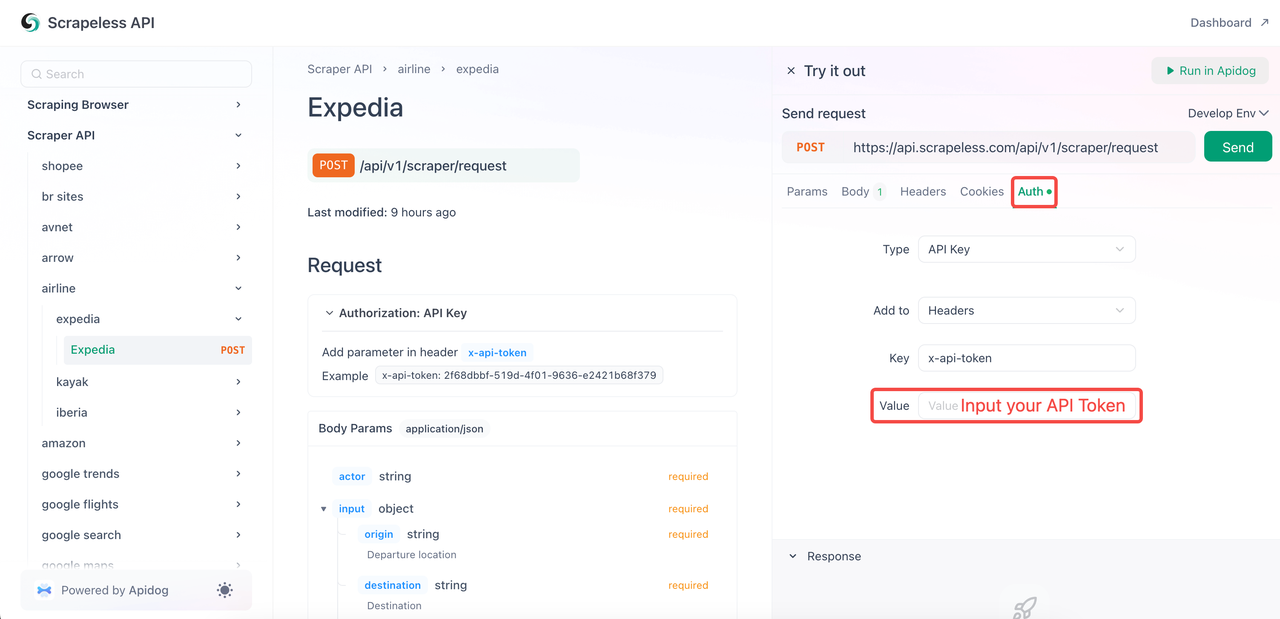
}- Bước 4. Điều quan trọng nhất là nhấp vào "Auth" và dán mã thông báo API của bạn. Cuối cùng, nhấp vào "Gửi" để scrape dữ liệu!
- Tham chiếu kết quả
JSON
{
"data": {
"flightsSearch": {
"flightsSheets": null,
"clientMetadata": {
"pageName": "TYO to NYC flights",
"pageNameAnalytics": {
"__typename": "FlightsAnalytics",
"linkName": "Flight Search Page One Way",
"referrerId": "page.Flight-Search-Oneway"
},
"responseTags": [
"RESPONSE_SUMMARY_HYBRID",
"UNRECOGNIZED",
"UNRECOGNIZED",
"UNRECOGNIZED",
"RESPONSE_SUMMARY_REFINEMENTS_CACHE_LIVE"
],
"responseMetrics": [
{
"name": "LISTINGS_SUPPLY_RESPONSE_TIME",
"value": "1450"
}
],
"evaluatedExperiments": [
{
"bucket": 0,
"id": "FARES_ON_FSR_VARIANT"
},
{
"bucket": 1,
"id": "RECOMMENDED_SORT_V2_ENABLED"
},
{
"bucket": 0,
"id": "CACHE_HYDRATOR_FEATURE"
},
{
"bucket": 0,
"id": "TEST_SEARCH_STACK"
},
{
"bucket": 0,
"id": "NONSTOP_ENABLED"
},
{
"bucket": 1,
"id": "VERTICAL_SLICING_ENABLED"
},
{
"bucket": 0,
"id": "SHARED_UI_LISTINGS_ENABLED"
}
]
},Scrapeless Deep SerpApi đã sẵn sàng!
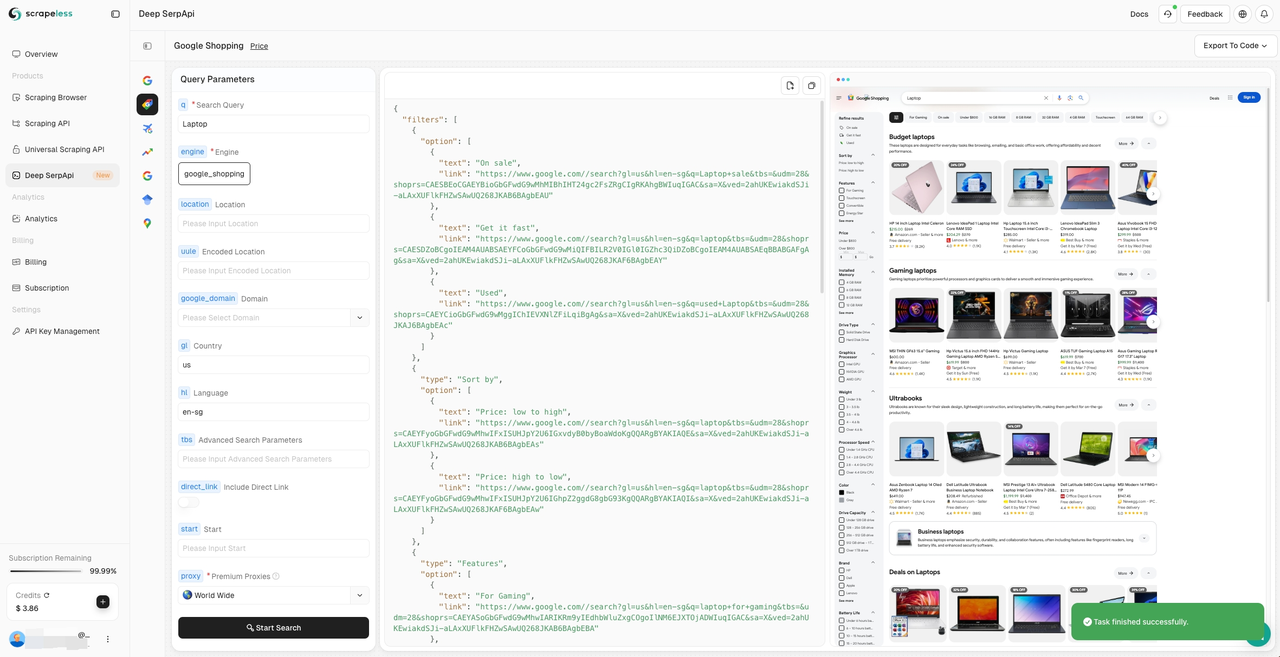
Deep SerpAPi là công cụ tìm kiếm chuyên dụng được thiết kế cho các mô hình ngôn ngữ lớn (LLM) và các tác nhân AI. Nó cung cấp thông tin chính xác, không thiên vị và theo thời gian thực, cho phép các ứng dụng AI truy xuất và xử lý dữ liệu hiệu quả:
✅ Nó có tích hợp sẵn 20+ giao diện kịch bản Google Search API và được kết nối với dữ liệu của các công cụ tìm kiếm chính thống.
✅ Nó bao gồm 20+ loại dữ liệu, chẳng hạn như kết quả tìm kiếm, tin tức, video và hình ảnh.
✅ Nó hỗ trợ cập nhật dữ liệu lịch sử trong vòng 24 giờ qua.
Deep SerpApi sẽ xem xét đầy đủ nhu cầu của các nhà phát triển AI! Chúng tôi sẽ đơn giản hóa quy trình tích hợp thông tin web động vào các giải pháp do AI điều khiển và cuối cùng sẽ hiện thực hóa một API ALL-in-One cho phép tìm kiếm và trích xuất dữ liệu web chỉ bằng một cú nhấp chuột. Hơn nữa, chúng tôi sẽ duy trì mức giá thấp nhất trong lĩnh vực này trong một thời gian dài: 0,1 đô la - 0,3 đô la / 1.000 truy vấn.
Đừng bỏ lỡ Chương trình Tài trợ Nhà phát triển của chúng tôi!
Tham gia cộng đồng của chúng tôi và nhận ngay 500.000 tín dụng miễn phí.
Kết luận
Việc tự xây dựng một trình crawl Python có thể crawl dữ liệu Expedia, nhưng rất dễ gặp phải các trở ngại chặn trang web khác nhau. Nếu bạn muốn crawl dữ liệu chuyến bay của Expedia an toàn hơn, trực tiếp hơn, nhanh hơn và chính xác hơn, bạn có thể thử Scrapeless Scraping API. Chỉ cần cấu hình tham số và điền dữ liệu đơn giản là có thể hoàn thành việc crawl kết quả một cách liền mạch.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


