
Trình duyệt không đầu là gì và trình duyệt không đầu tốt nhất để Scrapping
Specialist in Anti-Bot Strategies
Bài viết này sẽ hướng dẫn bạn về trình duyệt headless là gì, dùng để làm gì, Chrome headless là gì và những trình duyệt nào khác phổ biến nhất ở chế độ headless. Chúng ta cũng sẽ thảo luận về những hạn chế chính của việc kiểm thử trình duyệt headless.
Cứ tiếp tục cuộn xuống nào!
Tại sao 20 triệu nhà phát triển tin tưởng chúng tôi?
Làm thế nào để bạn điều hướng thế giới phức tạp của các trình duyệt headless? Bạn cần một hướng dẫn viên dày dạn kinh nghiệm, người đã vượt qua nhiều khó khăn và chiến thắng. Đó là nơi chúng tôi xuất hiện!
Tại Scrapeless, chúng tôi đã khám phá các kỹ thuật thu thập dữ liệu web và tự động hóa trong nhiều năm. Nhóm của chúng tôi đã dành hơn 15.000 giờ nghiên cứu các giải pháp trình duyệt headless khác nhau, từ các giải pháp lâu đời như PhantomJS đến các giải pháp mới hơn như Playwright.
Chúng tôi đã tận mắt chứng kiến cách một trình duyệt headless có thể tạo nên hoặc phá hỏng một dự án. Chúng tôi đã gỡ lỗi và khắc phục vô số sự cố, tối ưu hóa hiệu suất cho các hoạt động thu thập dữ liệu quy mô lớn và thậm chí phát triển các giải pháp tùy chỉnh khi các tùy chọn có sẵn trên thị trường không đáp ứng được.
Cho dù bạn đang tìm cách tự động hóa kiểm thử, thu thập dữ liệu quy mô lớn hay chỉ tìm hiểu về trình duyệt headless, chúng tôi đều có thể giúp đỡ!
Trình duyệt Headless là gì?
Trước tiên, hãy cùng tìm hiểu những "thủ thuật" vô hình này là gì và chúng hoạt động như thế nào!
Một trình duyệt headless giống như một ninja trong thế giới web – bí mật, hiệu quả và mạnh mẽ. Về cơ bản, đó là một trình duyệt web không được trang bị giao diện người dùng đồ họa (GUI). Nó chủ yếu được sử dụng bởi các kỹ sư kiểm thử phần mềm vì một trình duyệt không có GUI không cần phải vẽ nội dung trực quan và do đó chạy nhanh hơn. Một trong những lợi thế lớn nhất của trình duyệt headless là chúng có thể chạy trên máy chủ không hỗ trợ GUI.
Hãy tưởng tượng Chrome hoặc Firefox, nhưng bạn không thể nhìn thấy dữ liệu trang đang tải và hiển thị, bạn hoàn toàn điều khiển nó thông qua mã hoặc giao diện dòng lệnh.
Bạn đã bao giờ nghi ngờ sức mạnh của những trình duyệt như vậy chưa? Đừng hiểu lầm nữa! Chúng có thể thực hiện hầu hết tất cả các chức năng của trình duyệt truyền thống:
- Hiển thị trang web
- Thực thi JavaScript
- Quản lý cookie và phiên
- Xử lý các yêu cầu mạng
Sự khác biệt duy nhất là: chúng làm tất cả những điều này mà không hiển thị bất cứ thứ gì trên màn hình. Điều này làm cho chúng hoàn hảo cho các tác vụ tự động hóa, kiểm thử và trích xuất dữ liệu.
Các thành phần chính của trình duyệt headless
Lưu ý: Khi sử dụng trình duyệt headless, hãy đặc biệt chú ý đến công cụ JavaScript. Sự khác biệt trong các công cụ JS đôi khi có thể dẫn đến hành vi bất ngờ, đặc biệt là khi xử lý các ứng dụng web hiện đại.
- Công cụ trình duyệt: Thành phần cốt lõi diễn giải HTML, CSS và JavaScript. Các công cụ phổ biến bao gồm Blink (Chrome), Gecko (Firefox) và WebKit (Safari).
- Công cụ JavaScript: Chịu trách nhiệm thực thi mã JavaScript. Ví dụ bao gồm V8 (Chrome) và SpiderMonkey (Firefox).
- Công cụ hiển thị: Trong trình duyệt headless, thành phần này vẫn xử lý bố cục trang, nhưng không tạo ra đầu ra trực quan.
- Stack mạng: Xử lý tất cả các liên lạc mạng, bao gồm các yêu cầu và phản hồi HTTP.
- Giao diện API hoặc lệnh: Trình duyệt headless không cung cấp GUI, mà thay vào đó cung cấp API hoặc giao diện dòng lệnh để điều khiển và tương tác.
- DOM (Mô hình đối tượng tài liệu): Một biểu diễn theo chương trình về cấu trúc của một trang web.
Công dụng chính của trình duyệt headless
- Thu thập dữ liệu web: được sử dụng để thu thập nội dung động và các trang cần thực thi việc hiển thị JavaScript. Ví dụ: thu thập thông tin sản phẩm, giá cả được tạo động, v.v.
- Kiểm thử tự động: kiểm thử hành vi giao diện người dùng của các ứng dụng web, nhưng không cần mở cửa sổ thực tế. Thường được sử dụng trong các quy trình CI/CD để xác minh các chức năng front-end.
- Giám sát hiệu suất: phát hiện thời gian tải trang web, hiệu suất hiển thị, v.v.
- Tạo ảnh chụp màn hình và xuất PDF: tạo ảnh chụp màn hình của các trang web hoặc chuyển đổi chúng thành PDF.
- Giám sát trang web: phát hiện xem trang web có đang hoạt động như mong muốn không và có lỗi hoặc thay đổi nào không.
Nhược điểm và Hạn chế
- Thử thách gỡ lỗi: Thiếu phản hồi trực quan có thể khiến một số vấn đề khó chẩn đoán hơn. Yêu cầu một phương pháp gỡ lỗi khác với các trình duyệt chính thống.
- Cường độ tài nguyên: Mặc dù hiệu quả hơn so với trình duyệt đầy đủ, chúng vẫn có thể tốn nhiều tài nguyên cho các hoạt động quy mô lớn.
- Hiển thị không đầy đủ: Một số yếu tố trực quan hoặc hoạt ảnh phức tạp có thể không hiển thị chính xác.
- Phát hiện bởi các trang web: Các trang web nâng cao có thể phát hiện và chặn trình duyệt headless. Cần có công nghệ bổ sung để bắt chước hành vi của trình duyệt "thực".
- Khó khăn trong việc học: Yêu cầu kiến thức lập trình và hiểu biết về công nghệ web. Mỗi giải pháp trình duyệt headless đều có API và tính năng riêng cần được làm chủ.
Sự khác biệt giữa trình duyệt Headless và trình duyệt thông thường: 5 điểm khác biệt chính
| Thuộc tính | Trình duyệt Headless | Trình duyệt thông thường |
|---|---|---|
| Giao diện người dùng | Không có giao diện người dùng (vô hình) | Giao diện người dùng đầy đủ (cửa sổ, menu, v.v.) |
| Tương tác | Không thể tương tác trực tiếp bằng chuột hoặc bàn phím | Người dùng có thể hoạt động trực tiếp (nhấp chuột, nhập liệu, v.v.) |
| Hiệu suất | Nhẹ hơn vì không hiển thị đồ họa hoặc hiển thị nội dung trang | Nặng hơn vì hiển thị đồ họa và hoạt ảnh của trang |
| Trường hợp sử dụng | Kiểm thử tự động, thu thập dữ liệu web, giám sát, v.v. | Duyệt web hàng ngày, hoạt động và tương tác |
| Sử dụng tài nguyên | Tương đối thấp, phù hợp với máy chủ hoặc môi trường script | Tương đối cao, yêu cầu nhiều tài nguyên hệ thống hơn |
5 trình duyệt Headless phổ biến
Top 1. Trình duyệt Scrapeless Scraping - trình duyệt headless tốt nhất năm 2025
Trình duyệt Scrapeless Scraping là một trình duyệt headless hiệu suất cao để thu thập dữ liệu được thiết kế để hợp lý hóa quy trình trích xuất dữ liệu từ các trang web động. Nó cho phép các nhà phát triển vận hành và giám sát các trình duyệt headless một cách hiệu quả mà không cần máy chủ chuyên dụng, làm cho việc tự động hóa web và thu thập dữ liệu trở nên dễ tiếp cận hơn.
Các bước sử dụng:
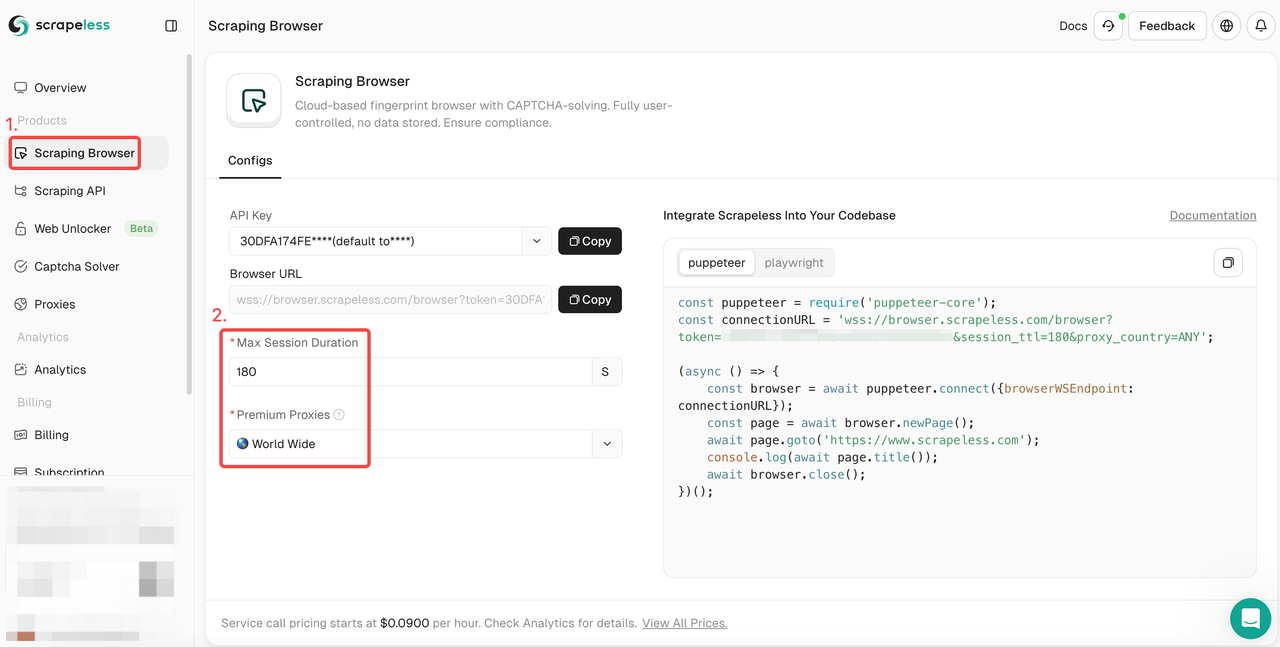
- Bước 1. Đăng nhập Scrapeless
- Bước 2. Nhập "Trình duyệt Scraping"
- Bước 3. Thiết lập các tham số theo nhu cầu của bạn.
- Bước 4. Sao chép các mã mẫu để tích hợp vào dự án của bạn:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //input API token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Bạn muốn biết thêm chi tiết? Tài liệu của chúng tôi sẽ giúp bạn rất nhiều:
Puppeteer:
- Cài đặt các thư viện cần thiết
Đầu tiên, cài đặt puppeteer-core, một phiên bản nhẹ của Puppeteer được thiết kế để kết nối với phiên bản trình duyệt hiện có:
Bash
npm install puppeteer-core- Viết mã để kết nối với trình duyệt scraping
Trong mã Puppeteer của bạn, hãy kết nối với Trình duyệt Scraping bằng phương pháp sau:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Bằng cách này, bạn có thể tận dụng cơ sở hạ tầng của Trình duyệt Scraping, bao gồm khả năng mở rộng, luân chuyển IP và truy cập toàn cầu.
- Ví dụ:
Dưới đây là một số hoạt động Puppeteer phổ biến sau khi tích hợp với Trình duyệt Scraping:
- Điều hướng và trích xuất nội dung trang
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Ảnh chụp màn hình
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- Chạy script tùy chỉnh
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Playwright:
- Cài đặt các thư viện cần thiết
Đầu tiên, cài đặt playwright-core, một phiên bản nhẹ của Playwright kết nối với phiên bản trình duyệt hiện có:
Bash
npm install playwright-core- Viết mã để kết nối với trình duyệt scraping
Trong mã Playwright, hãy kết nối với Trình duyệt Scraping bằng phương pháp sau:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Điều này cho phép bạn tận dụng cơ sở hạ tầng của Trình duyệt Scraping, bao gồm khả năng mở rộng, luân chuyển IP và truy cập toàn cầu.
- Ví dụ
Dưới đây là một số hoạt động Playwright phổ biến sau khi tích hợp với Trình duyệt Scraping:
- Điều hướng và trích xuất nội dung trang
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Ảnh chụp màn hình
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Screenshot saved as example.png');
await browser.close();- Chạy script tùy chỉnh
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Page title:', result);
await browser.close();Bài viết liên quan: Trình duyệt Scraping AI tốt nhất để thu thập và giám sát dữ liệu từ bất kỳ trang web nào
Top 2. Playwright
Được phát triển bởi Microsoft, Playwright cung cấp một API duy nhất để quản lý các trình duyệt dựa trên Chromium, Firefox và WebKit. Nó có thể được sử dụng để tự động hóa nhiều trình duyệt với API cấp cao. Trước khi thiết lập Playwright để kiểm thử trình duyệt headless, hãy đảm bảo bạn đã cài đặt phiên bản Node.JS và npm mới nhất trên hệ thống của mình.
Playwright đã nhanh chóng thu hút sự chú ý trong cộng đồng tự động hóa, phần lớn là do các tính năng độc đáo của nó:
- Hỗ trợ đa trình duyệt (Chrome, Firefox, Safari).
- Cơ chế chờ tự động mạnh mẽ.
- Khả năng chặn mạng mạnh mẽ.
- Hỗ trợ nhiều ngôn ngữ (JavaScript, Python, .NET, Java).
Top 3. Puppeteer
Được phát triển bởi Google, Puppeteer cung cấp một API cấp cao để điều khiển Chrome hoặc Chromium thông qua Giao thức DevTools. Đây là lựa chọn được nhiều nhà phát triển JavaScript ưa thích.
- Tích hợp sâu với Chrome/Chromium
- API toàn diện để điều khiển trình duyệt
- Hỗ trợ tích hợp để tạo PDF và ảnh chụp màn hình
Top 4. Selenium
Selenium là một công cụ mã nguồn mở, miễn phí, rất tuyệt vời để tự động hóa. Nó hỗ trợ nhiều trình duyệt chạy trên các hệ điều hành khác nhau. Selenium Web Driver cung cấp hỗ trợ nâng cao cho các trang web động, có thể mang lại kết quả tuyệt vời khi sử dụng Selenium Headless. Ngoài ra, bạn có thể sử dụng Headless Chrome hoặc Headless Firefox để thực hiện Selenium trình duyệt headless.
- Hỗ trợ nhiều ngôn ngữ lập trình
- Tương thích với nhiều trình duyệt (Chrome, Firefox, Safari, Edge)
- Hệ sinh thái khổng lồ các công cụ và tiện ích mở rộng
Top 5. Cypress
Cypree rất xuất sắc trong việc kiểm thử end-to-end các ứng dụng web, đặc biệt là các ứng dụng một trang. Mặc dù Cypress chủ yếu tập trung vào việc kiểm thử end-to-end, nhưng nó rất phổ biến nhờ cách tiếp cận thân thiện với nhà phát triển và khả năng gỡ lỗi mạnh mẽ.
- Nạp lại trực tiếp
- Gỡ lỗi du hành thời gian
- Sử dụng truy cập gốc vào DOM và lớp mạng
Kiểm thử Headless Chrome là gì?
Nếu bạn là một nhà phát triển, bạn có thể quen thuộc với việc kiểm thử dựa trên giao diện người dùng (UI), điều này đảm bảo rằng các ứng dụng hoạt động chính xác theo thời gian. Tuy nhiên, một trong những thách thức lớn đối với việc kiểm thử dựa trên UI là sự ổn định—đặc biệt là khi các kiểm thử không tương tác nhất quán với trình duyệt.
Kiểm thử trình duyệt headless cung cấp giải pháp cho vấn đề này. Không giống như kiểm thử dựa trên UI, nó cho phép kiểm thử end-to-end mà không cần tải giao diện người dùng của ứng dụng. Phương pháp này không chỉ tăng tốc quá trình kiểm thử mà còn đảm bảo tương tác trực tiếp với trang, giảm thiểu sự không ổn định. Kết quả là, các kiểm thử trở nên nhanh hơn, đáng tin cậy hơn và hiệu quả hơn.
Khi nào bạn nên sử dụng kiểm thử trình duyệt Headless?
Kiểm thử trình duyệt headless đặc biệt hữu ích trong các trường hợp tài nguyên bị hạn chế hoặc khi cần thực hiện các tác vụ tự động hóa một cách hiệu quả. Dưới đây là một số trường hợp sử dụng phổ biến:
- Tương tác HTML tự động
Mô phỏng các hành động của người dùng như gửi biểu mẫu, nhấp vào nút và lựa chọn menu thả xuống. Trình duyệt Headless cho phép bạn xác minh các phản hồi đối với các tương tác này một cách hiệu quả. - Kiểm thử thực thi JavaScript
Kiểm thử việc thực thi JavaScript trong các trang web để xác thực nội dung động. Điều này đặc biệt hữu ích đối với các ứng dụng có việc hiển thị ở phía client phức tạp. - Thu thập dữ liệu web
Bỏ qua các biện pháp chống thu thập dữ liệu cơ bản, tải nội dung động và trích xuất dữ liệu từ các trang web. Trình duyệt Headless là lý tưởng cho các tác vụ thu thập dữ liệu liên quan đến việc hiển thị front-end phức tạp. - Giám sát mạng và kiểm thử hiệu suất
Giám sát các yêu cầu mạng, phân tích thời gian tải và xác định các điểm nghẽn hiệu suất, làm cho nó có giá trị đối với việc tối ưu hóa hiệu suất trang web. - Xử lý các yêu cầu Ajax
Đảm bảo rằng các trang dựa vào Ajax để tải dữ liệu hiển thị chính xác bằng cách chụp và xử lý các yêu cầu này. - Tạo ảnh chụp màn hình trang web
Tạo ảnh chụp màn hình để xác định các vấn đề về bố cục hoặc nội dung trong quá trình kiểm thử, tạo tài liệu hoặc thực hiện kiểm tra trực quan các trang web.
Kết luận
Thật là một ngày tuyệt vời! Khi chúng ta cập cảng tàu duyệt headless, rõ ràng là chúng ta đang ở vị trí tiên phong của một cuộc cách mạng trong tự động hóa web và trích xuất dữ liệu.
Kiểm thử trình duyệt headless là một cách nhanh hơn, đáng tin cậy hơn và hiệu quả hơn để kiểm thử các ứng dụng web trên trình duyệt. Tuy nhiên, khi bạn kiểm thử bằng trình duyệt máy tính để bàn thực tế, nó cung cấp một biểu diễn chân thực về trang web của bạn.
Bạn có thể là headless và thực tế cùng một lúc không? Tất nhiên rồi! Trình duyệt Scrapeless Scraping kết hợp những điểm tốt nhất của cả hai thế giới. Nó cho phép bạn tự động hóa các trang web một cách dễ dàng.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


