
Trình duyệt AI cào dữ liệu tốt nhất: Cào và giám sát dữ liệu từ bất kỳ trang web nào
Specialist in Anti-Bot Strategies
Tránh tụt hậu, doanh nghiệp hay sản phẩm cần web scraping. Dữ liệu web cho biết hầu hết mọi thứ về khách hàng tiềm năng, từ giá trung bình họ trả đến các tính năng cần thiết nhất hiện nay.
Làm sao để giảm tải thu thập dữ liệu và nâng cao hiệu quả công việc?
Sử dụng các công cụ web scraping tốt nhất là điều cần thiết để có được dữ liệu chất lượng cao, vì vậy bạn cần đảm bảo có được các công cụ tốt nhất cho công việc.
Bắt đầu đọc bài viết này ngay bây giờ để tìm hiểu tất cả về web scraping và có được trình duyệt scraping tốt nhất!
Tại sao thu thập dữ liệu lại cần thiết?
Thông tin lỗi thời có thể khiến các công ty phân bổ tài nguyên không hiệu quả hoặc bỏ lỡ những cơ hội kiếm tiền mới nhất. Bạn chắc chắn cần dựa vào dữ liệu giá hàng tiêu dùng nhanh từ tuần trước kỳ nghỉ để xây dựng giá cả cho tháng tới.
Dữ liệu web có thể giúp tăng doanh số và năng suất đáng kể. Internet hiện đại vô cùng sôi động - người dùng tạo ra 2,5 quintillion byte dữ liệu mỗi ngày. Cho dù bạn là một công ty khởi nghiệp hay một công ty lớn với nhiều thập kỷ lịch sử, thông tin hữu ích trong dữ liệu Internet có thể giúp bạn thu hút khách hàng tiềm năng từ đối thủ cạnh tranh và khiến họ trả tiền cho sản phẩm của bạn.
Tuy nhiên, khối lượng dữ liệu khách hàng tiềm năng khổng lồ có nghĩa là bạn có thể dành cả đời để trích xuất dữ liệu thủ công và không bao giờ bắt kịp. Và việc trích xuất dữ liệu thủ công cũng gặp phải nhiều thách thức!
Thử thách khi thu thập và theo dõi dữ liệu
1. Các biện pháp chống Scraping
Nhiều trang web triển khai nhiều kỹ thuật khác nhau để phát hiện và chặn các hoạt động scraping. Những biện pháp này được thực hiện để bảo vệ dữ liệu của họ và ngăn chặn việc lạm dụng.
- CAPTCHA: Đây là những câu đố được thiết kế để phân biệt giữa hoạt động của con người và bot. Các dạng CAPTCHA phổ biến bao gồm văn bản bị bóp méo, nhiệm vụ nhận dạng hình ảnh hoặc các hành động nhấp để chọn.
- Hạn chế tốc độ: Các trang web có thể giới hạn số lượng yêu cầu từ một địa chỉ IP trong một khoảng thời gian nhất định để tránh quá tải máy chủ của họ. Nếu gửi quá nhiều yêu cầu trong thời gian ngắn, IP của bạn có thể bị chặn.
- Chặn IP: Các trang web thường theo dõi các địa chỉ IP mà từ đó yêu cầu được thực hiện. Nếu họ phát hiện hành vi scraping, họ có thể chặn hoặc giảm tốc độ truy cập từ IP đó.
- Hiển thị JavaScript: Nhiều trang web hiện đại sử dụng JavaScript để tải nội dung động. Các phương pháp scraping truyền thống (ví dụ: với các thư viện như Requests hoặc BeautifulSoup) có thể gặp khó khăn khi scraping nội dung như vậy.
- Dấu vân tay trình duyệt: Các trang web có thể phát hiện lưu lượng truy cập không phải của con người bằng cách phân tích hành vi và dấu vân tay của trình duyệt, chẳng hạn như độ phân giải màn hình, tiện ích bổ sung đã cài đặt và các đặc điểm khác.
Bị làm phiền vì bị chặn bởi CAPTCHA và phát hiện chống bot?
Scrapeless mở khóa 99,9% trang web
Thử nghiệm miễn phí!
2. Cấu trúc trang web phức tạp và động
Các trang web thường được xây dựng bằng các framework tải dữ liệu động thông qua JavaScript. Các trang web động này thường sử dụng các yêu cầu AJAX để kéo nội dung sau khi trang đã được tải, khiến việc scraping trở nên khó khăn bằng các phương pháp truyền thống.
- Các trang web nặng JavaScript: Scraping nội dung từ các trang web như các hãng tin tức hoặc nền tảng truyền thông xã hội thường yêu cầu khả năng hiển thị JavaScript. Nếu không có điều này, nội dung có thể không có sẵn trong mã nguồn HTML của trang.
- Cuộn vô hạn: Các trang web có cuộn vô hạn (ví dụ: truyền thông xã hội hoặc các trang thương mại điện tử) tải thêm nội dung khi người dùng cuộn xuống. Điều này gây ra thách thức trong việc xác định khi nào tất cả dữ liệu cần thiết đã được tải và cách trích xuất nó một cách hiệu quả.
- Cấu trúc HTML phức tạp: Các trang web có cấu trúc HTML phức tạp (ví dụ: các phần tử lồng nhau, tên thẻ không đều hoặc bố cục không nhất quán) có thể khiến việc phân tích nội dung trở nên khó khăn.
3. Giải pháp chống bot
Các trang web ngày càng triển khai các giải pháp chống bot tinh vi để bảo vệ dữ liệu của họ, điều này có thể khiến việc scraping trở nên khó khăn hơn.
- Dấu vân tay thiết bị: Các trang web có thể sử dụng các kỹ thuật tiên tiến để phát hiện hành vi giống bot, chẳng hạn như phân tích dấu vân tay trình duyệt, cấu hình mạng hoặc thậm chí cả chuyển động chuột của bạn.
- Phân tích hành vi: Một số trang web theo dõi các tương tác của bạn (ví dụ: chuyển động chuột, nhấp chuột và hành vi cuộn) để phát hiện hành vi của bot. Nếu scraper hoạt động theo cách không giống con người, nó có thể kích hoạt các biện pháp chống bot.
Trình duyệt scraping hoạt động như thế nào?
Bước 1. Gửi yêu cầu HTTP
Bước 2. Hiển thị các trang web
Bước 3. Điều hướng trang web
Bước 4. Trích xuất dữ liệu
Bước 5. Xử lý nội dung động
Bước 6. Quản lý phiên và cookie
Bước 7. Xử lý các cơ chế chống scraping
Bước 8. Xử lý lỗi và sự cố
Bước 9. Lưu trữ và xuất dữ liệu
Tại sao trình duyệt scraping có thể vượt qua các thách thức?
Trình duyệt scraping có thể tránh được việc giám sát và chặn trang web một cách hiệu quả, chủ yếu dựa trên các công nghệ chính sau:
1. Trình giải quyết CAPTCHA tích hợp
Trình duyệt scraping tích hợp các dịch vụ giải quyết CAPTCHA, có thể tự động xác định và giải quyết các thách thức CAPTCHA của trang web.
2. Xoay vòng IP
Thông qua việc xoay vòng IP, trình duyệt scraping có thể thường xuyên thay đổi địa chỉ IP của nguồn yêu cầu, điều này có thể ngăn chặn một địa chỉ IP duy nhất thực hiện một số lượng lớn yêu cầu trong một khoảng thời gian ngắn. Sử dụng proxy luân phiên, mỗi yêu cầu có thể sử dụng một địa chỉ IP khác nhau và sau đó bỏ qua việc chặn IP.
3. Ngẫu nhiên hóa User-Agent
Thông qua việc ngẫu nhiên hóa User-Agent, trình duyệt scraping có thể mô phỏng các yêu cầu từ các trình duyệt, thiết bị và hệ điều hành khác nhau, giảm nguy cơ bị xác định là crawler. Bằng cách liên tục thay đổi chuỗi User-Agent, crawler có thể khiến các yêu cầu trông giống như đến từ những người dùng khác nhau chứ không phải từ một công cụ tự động duy nhất.
4. Dấu vân tay thực
Trình duyệt scraping mô phỏng dấu vân tay trình duyệt của người dùng thực, thay vì thay đổi hoặc làm giả dấu vân tay để tránh bị xác định. Dấu vân tay thực có thể khiến crawler hoạt động giống người dùng bình thường hơn, giống như những người dùng khác truy cập trang web bằng cùng một thiết bị và trình duyệt.
Bạn cũng có thể thích: 5 Trình duyệt Scraping tốt nhất năm 2025
Trình duyệt scraping AI tốt nhất - Scrapeless
Trình duyệt Scraping Scrapeless cung cấp nền tảng serverless hiệu suất cao. Nó làm đơn giản hóa hiệu quả quá trình trích xuất dữ liệu từ các trang web động. Các nhà phát triển có thể chạy, quản lý và giám sát các trình duyệt headless mà không cần máy chủ chuyên dụng, cho phép tự động hóa web và thu thập dữ liệu hiệu quả.
Tại sao Scrapeless đặc biệt dành cho web scraping?
Trình duyệt Scraping Scrapeless có mạng lưới toàn cầu bao phủ 195 quốc gia và hơn 70 triệu IP dân cư, một công cụ mở khóa web mạnh mẽ và một trình giải quyết captcha cực kỳ ổn định. Nó lý tưởng cho những người dùng cần một giải pháp web scraping đáng tin cậy và có khả năng mở rộng.
Cách sử dụng trình duyệt scraping Scrapeless?
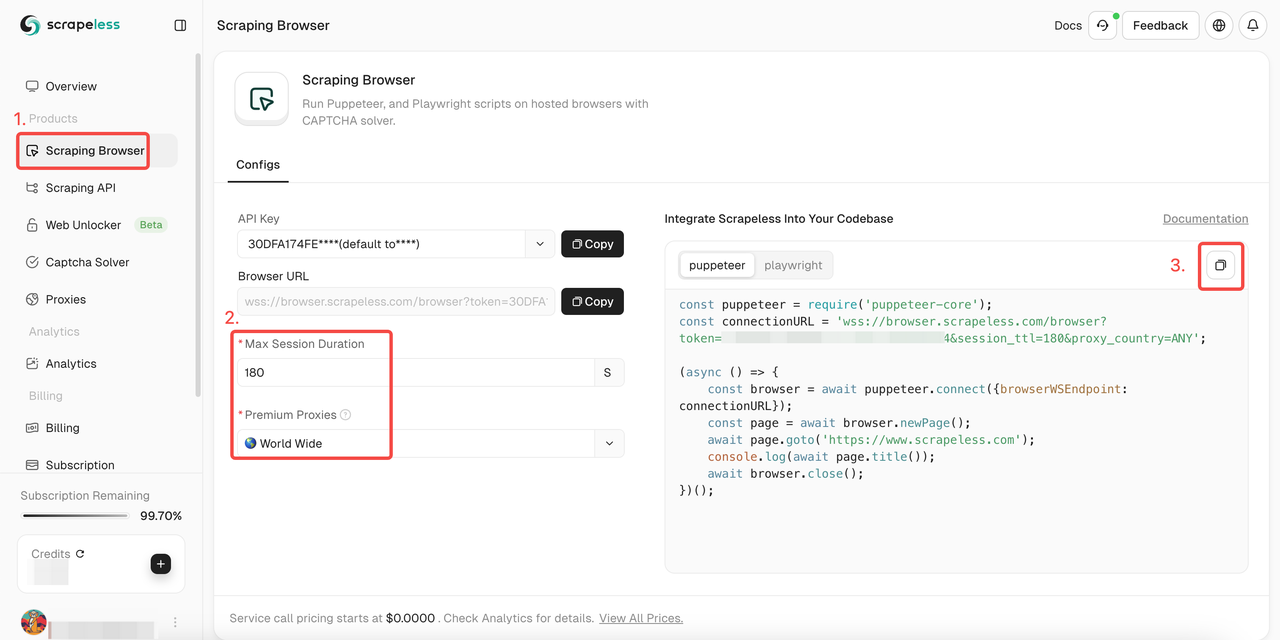
- Bước 1. Đăng nhập Scrapeless
- Bước 2. Nhập "Trình duyệt Scraping"
- Bước 3. Thiết lập các tham số theo nhu cầu của bạn
- Bước 4. Sao chép các mã mẫu để tích hợp vào dự án của bạn:
Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //nhập API token
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //nhập API token
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Muốn biết thêm chi tiết? Tài liệu của chúng tôi sẽ giúp bạn rất nhiều!
Puppeteer:
Bước 1. Cài đặt các thư viện cần thiết
Đầu tiên, cài đặt puppeteer-core, một phiên bản nhẹ của Puppeteer được thiết kế để kết nối với phiên bản trình duyệt hiện có:
Bash
npm install puppeteer-coreBước 2. Viết mã để kết nối với trình duyệt scraping
Trong mã Puppeteer của bạn, hãy kết nối với Trình duyệt Scraping bằng phương pháp sau:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Bằng cách này, bạn có thể tận dụng cơ sở hạ tầng của Trình duyệt Scraping, bao gồm khả năng mở rộng, luân phiên IP và truy cập toàn cầu.
Ví dụ:
Dưới đây là một số hoạt động Puppeteer phổ biến sau khi tích hợp với Trình duyệt Scraping:
- Điều hướng và trích xuất nội dung trang
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Ảnh chụp màn hình
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Ảnh chụp màn hình được lưu dưới dạng example.png');
await browser.close();- Chạy các script tùy chỉnh
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Tiêu đề trang:', result);
await browser.close();Playwright:
Bước 1. Cài đặt các thư viện cần thiết
Đầu tiên, cài đặt playwright-core, một phiên bản nhẹ của Playwright kết nối với phiên bản trình duyệt hiện có:
Bash
npm install playwright-coreBước 2. Viết mã để kết nối với trình duyệt scraping
Trong mã Playwright, hãy kết nối với Trình duyệt Scraping bằng phương pháp sau:
JavaScript
const { chromium } = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Điều này cho phép bạn tận dụng cơ sở hạ tầng của Trình duyệt Scraping, bao gồm khả năng mở rộng, luân phiên IP và truy cập toàn cầu.
Ví dụ
Dưới đây là một số hoạt động Playwright phổ biến sau khi tích hợp với Trình duyệt Scraping:
- Điều hướng và trích xuất nội dung trang
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
console.log(await page.title());
const html = await page.content();
console.log(html);
await browser.close();- Ảnh chụp màn hình
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.screenshot({ path: 'example.png' });
console.log('Ảnh chụp màn hình được lưu dưới dạng example.png');
await browser.close();- Chạy các script tùy chỉnh
JavaScript
const page = await browser.newPage();
await page.goto('https://www.example.com');
const result = await page.evaluate(() => document.title);
console.log('Tiêu đề trang:', result);
await browser.close();8 yếu tố cần xem xét khi chọn một web scraper
- Khả năng trích xuất dữ liệu: Một công cụ web scraping tốt hỗ trợ nhiều định dạng dữ liệu và có thể trích xuất nội dung từ nhiều cấu trúc trang web, bao gồm các trang HTML tĩnh và các trang web động sử dụng JavaScript.
- Tính dễ sử dụng: Đánh giá mức độ khó hiểu, giao diện người dùng và tài liệu có sẵn của công cụ. Những người sử dụng công cụ cần hiểu độ phức tạp của công cụ.
- Khả năng mở rộng: Xem xét khả năng xử lý trích xuất dữ liệu quy mô lớn của công cụ. Khả năng mở rộng về hiệu suất và khả năng đáp ứng số lượng dữ liệu hoặc yêu cầu ngày càng tăng là rất quan trọng.
- Khả năng tự động hóa: Kiểm tra mức độ tự động hóa có sẵn. Tìm kiếm các khả năng lập lịch trình, xử lý CAPTCHA tự động và khả năng tự động quản lý cookie và phiên.
- Hỗ trợ luân phiên IP và proxy: Công cụ cần cung cấp hỗ trợ quản lý proxy và luân phiên IP mạnh mẽ để tránh bị chặn.
- Xử lý và phục hồi lỗi: Khảo sát cách công cụ quản lý lỗi, chẳng hạn như kết nối bị hỏng hoặc thay đổi trang web không mong muốn.
- Tích hợp với các hệ thống khác: Xác định xem công cụ có tích hợp liền mạch với các hệ thống và nền tảng khác hay không, chẳng hạn như cơ sở dữ liệu, dịch vụ đám mây hoặc công cụ phân tích dữ liệu. Khả năng tương thích với API cũng là một lợi thế đáng kể.
- Làm sạch và xử lý dữ liệu: Tìm kiếm các khả năng làm sạch và xử lý dữ liệu được tích hợp sẵn hoặc dễ dàng tích hợp để hợp lý hóa quy trình từ dữ liệu thô sang thông tin có thể sử dụng.
Kết luận
Robot web scraping dễ dàng bị các trang web xác định và dẫn đến việc bị chặn! Làm thế nào để có được quá trình trích xuất dữ liệu trơn tru?
Trình duyệt Scrapeless Scraping tích hợp công cụ mở khóa web, trình giải quyết CAPTCHA, luân phiên IP và proxy thông minh có thể giúp bạn dễ dàng tránh bị trang web chặn và đạt được việc scraping dữ liệu!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


