
Cách vượt qua phát hiện bot?
Senior Web Scraping Engineer
Trong cuộc chiến giữa tự động hóa và an ninh, các cơ chế chống bot đã trở thành người gác cổng của web, chặn đứng các bot không mong muốn trong khi thường gây cản trở cho việc thu thập dữ liệu hợp pháp.
Từ các trang đăng nhập đến các trang thương mại điện tử, những biện pháp phòng thủ này—đặc biệt là CAPTCHA—có thể là một rào cản khó chịu cho các công cụ thu thập dữ liệu và tự động hóa. Có cách nào để vượt qua chúng không?
Bài viết này đi sâu vào thế giới của các hệ thống chống bot, khám phá cách chúng phát hiện ra sự tự động hóa và khám phá các chiến lược đạo đức để vượt qua các hạn chế mà không vi phạm các ranh giới pháp lý hoặc đạo đức.
Hãy bắt đầu đọc nào!
Tại sao lại có phát hiện chống bot?
Chà, trước tiên hãy tận hưởng một chuyến du lịch. Hãy tưởng tượng bạn đang điều hành một cửa hàng nơi khách hàng có thể duyệt sản phẩm một cách tự do, nhưng cứ vài phút, một bóng người đeo mặt nạ lao vào, lấy tất cả sản phẩm của bạn và biến mất. Bạn nghĩ gì về điều đó?
Đó là cảm giác của các trang web về các bot! Phát hiện chống bot tồn tại để tách biệt người dùng thật và các kịch bản tự động, bảo vệ chống lại việc lén lút đăng nhập, đánh cắp nội dung và thu thập dữ liệu web một cách dữ dội.
Từ CAPTCHA đến dấu vân tay trình duyệt, những người bảo vệ kỹ thuật số này làm việc không nghỉ để giữ các bot xấu bên ngoài—nhưng đôi khi, họ cũng cản trở những nhà phát triển có ý định tốt chỉ đang cố gắng lấy dữ liệu của mình.
Vậy có cách nào để vượt qua họ mà không vi phạm quy tắc không? Chúng ta hãy cùng tìm hiểu thêm.
Các cơ chế chống bot phổ biến
- Xác thực tiêu đề: Xác thực tiêu đề phân tích các tiêu đề HTTP đến và kiểm tra xem có nên chặn chúng không.
- Chặn IP: Hạn chế quyền truy cập dựa trên địa chỉ IP.
- Giới hạn tần suất: Giới hạn số lượng yêu cầu từ một IP duy nhất.
- Dấu vân tay trình duyệt: Phân tích các thuộc tính và hành vi của trình duyệt.
- Dấu vân tay TLS: Dấu vân tay TLS phát hiện bot bằng cách phân tích các tham số bắt tay và chặn các yêu cầu có giá trị bất ngờ.
- Bẫy mật ong: Những cái bẫy vô hình để lure bot.
- Thách thức CAPTCHA: Những thách thức được thiết kế dễ dàng cho con người nhưng khó khăn cho bot.
CAPTCHA: Một cơ chế chống bot quan trọng
CAPTCHA là gì?
CAPTCHA, viết tắt của Completely Automated Public Turing test to tell Computers and Humans Apart, là một cơ chế an ninh được thiết kế để phân biệt người dùng thật với các bot tự động. Bằng cách đưa ra các thách thức dễ cho con người nhưng khó cho máy móc, CAPTCHA giúp ngăn chặn các hoạt động độc hại như spam, lén lút đăng nhập và thu thập dữ liệu web tự động.
Các loại CAPTCHA:
- CAPTCHA dựa trên văn bản: Người dùng phải nhận diện và nhập văn bản bị biến dạng hoặc bị che khuất, điều này khó khăn cho bot để giải mã.
- CAPTCHA dựa trên hình ảnh: Người dùng nhận diện các đối tượng trong hình ảnh, chẳng hạn như đèn giao thông hoặc cửa hàng, một nhiệm vụ yêu cầu kỹ năng nhận dạng hình ảnh vượt qua hầu hết các bot.
- reCAPTCHA: Hệ thống CAPTCHA tiên tiến của Google bao gồm nhiều hình thức—xác minh hộp kiểm đơn giản (“Tôi không phải là robot”), thách thức chọn hình ảnh và các CAPTCHA vô hình phân tích hành vi người dùng mà không cần tương tác rõ ràng.
- hCAPTCHA: Một lựa chọn tập trung vào quyền riêng tư thay thế cho reCAPTCHA, được thiết kế để giảm thiểu theo dõi dữ liệu trong khi vẫn cung cấp bảo vệ hiệu quả trước bot.
Cách thức hoạt động của CAPTCHA:
CAPTCHA hoạt động theo cơ chế thách thức-phản hồi, nơi người dùng phải hoàn thành một nhiệm vụ để chứng minh họ là con người. Hệ thống đánh giá các phản hồi và hành vi, chẳng hạn như chuyển động chuột, tốc độ gõ, hoặc mẫu tương tác, để xác định tính xác thực.
Các hệ thống CAPTCHA hiện đại tận dụng machine learning để điều chỉnh mức độ khó của chúng dựa trên khả năng của bot đang phát triển. Chúng phân tích dữ liệu hành vi, áp dụng các đánh giá dựa trên rủi ro và thậm chí tích hợp các dấu hiệu sinh học để tăng cường độ chính xác và an ninh, khiến cho các bot ngày càng khó khăn hơn để vượt qua những biện pháp phòng thủ này.
Thực hành tốt nhất để vượt qua các bot chống lại
Tại sao chọn Scrapeless?
Scrapeless có một Giải mã CAPTCHA mạnh mẽ, cho phép điều hướng liền mạch qua các trang web được bảo vệ bởi CAPTCHA và đảm bảo việc trích xuất dữ liệu không bị gián đoạn.
- Giá cả hợp lý: Scrapeless cung cấp các giải pháp giải mã CAPTCHA tiết kiệm chi phí mà không làm giảm hiệu quả.
- Tính ổn định và đáng tin cậy: Với một lịch sử đã được chứng minh, Scrapeless liên tục giải quyết CAPTCHA dưới các khối lượng công việc cao, đảm bảo quá trình tự động hóa diễn ra suôn sẻ.
- Tỷ lệ thành công cao: Không còn rào cản CAPTCHA—Scrapeless đạt tỷ lệ thành công 99,99% trong việc vượt qua các thách thức CAPTCHA.
- Khả năng mở rộng: Dễ dàng xử lý hàng ngàn yêu cầu được bảo vệ bởi CAPTCHA, được hỗ trợ bởi hạ tầng vững chắc của Scrapeless.
Scrapeless có đắt không?
Scrapeless cung cấp một nền tảng thu thập dữ liệu web đáng tin cậy và có thể mở rộng với mức giá cạnh tranh (so với Zenrows & Apify), đảm bảo giá trị tuyệt vời cho người dùng của mình:
- Giải mã CAPTCHA: Từ 0.8 USD cho 1k URL
- Trình duyệt thu thập dữ liệu: Từ 0.09 USD mỗi giờ
- API thu thập dữ liệu: Từ 0.8 USD cho 1k URL
- Mở khóa web: 0.2 USD cho 1k URL
- Proxy: 2,8 đô la mỗi GB
Tham gia cộng đồng của chúng tôi để Dùng thử miễn phí và nhận thêm ưu đãi!
Bỏ qua phát hiện bot: Hướng dẫn Giải mã CAPTCHA không có dấu hiệu
- Bước 1. Đăng nhập vào Scrapeless.
- Bước 2. Nhập giao diện "Giải mã CAPTCHA". Nhấp vào dịch vụ mở khóa reCAPTCHA và chọn loại reCAPTCHA mà bạn cần điều chỉnh: thông thường hoặc doanh nghiệp.
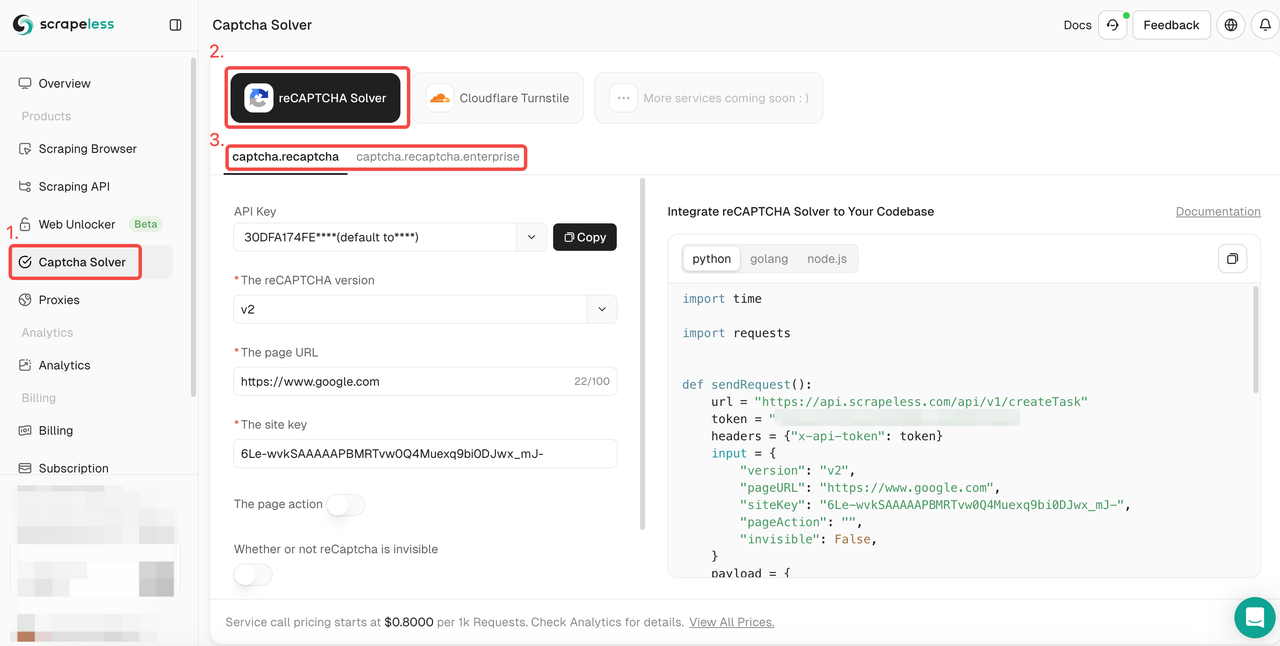
- Bước 3. Cấu hình thông tin cần thiết trong hộp thao tác bên trái: phiên bản reCAPTCHA, URL trang, khóa trang, hành động, proxy, v.v.
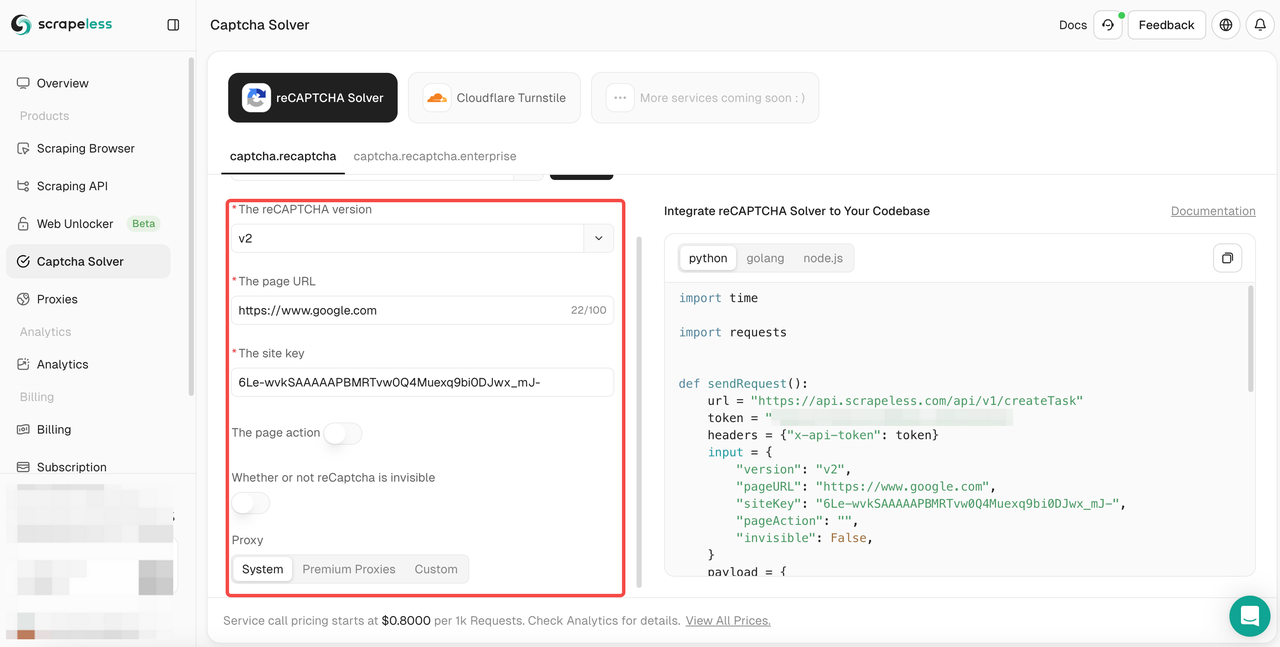
- Bước 4. Sau khi hoàn tất cấu hình, bạn có thể nhận được phản hồi mã liên quan trong hộp mã bên phải. Bạn chỉ cần sao chép nó và tích hợp vào chương trình của mình. Ở đây, chúng tôi lấy ví dụ về việc lấy dữ liệu từ scrapeless.com. Hãy mở khóa reCAPTCHA v2, sử dụng proxy Premium và cấu hình nó thành "Singapore", và đặt hành động trang thành "Lấy dữ liệu". Dưới đây là phản hồi mã mà tôi nhận được:
Python
import time
import requests
def sendRequest():
url = "https://api.scrapeless.com/api/v1/createTask"
token = "xxx"
headers = {"x-api-token": token}
input = {
"version": "v2",
"pageURL": "https://www.scrapeless.com/en",
"siteKey": "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-",
"pageAction": "scraping",
"invisible": False,
}
payload = {
"actor": "captcha.recaptcha",
"input": input
}
# Tạo tác vụ
result = requests.post(url, json=payload, headers=headers).json()
taskId = result.get("taskId")
if not taskId:
print("Tạo tác vụ không thành công:", result)
return
print(f"Tạo một tác vụ: {taskId}")
# Lấy kết quả
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + taskId
resp = requests.get(url, headers=headers)
result = resp.json()
if resp.status_code != 200:
print("tác vụ thất bại:", resp.text)
return
if result.get("success"):
return result["solution"]["token"]
data = sendRequest()
print(data)actor: Diễn viên của tác vụ hiện tạistate: Trạng thái của tác vụ hiện tạisuccess: Tình trạng thành công của tác vụtaskId: Nếu tác vụ được tạo thành công, bạn sẽ nhận được một taskId. Sau đó, bạn cần sử dụng taskId này để truy vấn kết quảsolution: Nếu tác vụ thành công, bạn sẽ nhận được giải phápmessage: Nếu tác vụ thất bại, vui lòng kiểm tra thông báo lỗi này
Để biết thêm thông tin, vui lòng tham khảo tài liệu hướng dẫn của chúng tôi.
Chiến lược Nâng cao để Bỏ qua Anti bot với Giải mã CAPTCHA
Bỏ qua các biện pháp chống bot, như CAPTCHAs, cần một sự kết hợp giữa việc lấy dữ liệu đầy tôn trọng và các kỹ thuật tiên tiến. Dưới đây là cách để duy trì hiệu quả và đạo đức trong các hoạt động lấy dữ liệu của bạn.
Thực hành Lấy dữ liệu Tôn trọng
- Tuân thủ robots.txt: Luôn kiểm tra tệp
robots.txtcủa trang web để tuân theo các hướng dẫn về những gì có thể được lấy. - Giới hạn Tốc độ Yêu cầu: Giới thiệu thời gian ngẫu nhiên giữa các yêu cầu để bắt chước cách duyệt web của con người, tránh các yêu cầu nhanh chóng, liên tiếp có thể kích hoạt chặn.
- Xoay vòng User Agents: Sử dụng một nhóm các user agents thực tế để mô phỏng các trình duyệt và thiết bị khác nhau, ngăn chặn phát hiện từ các chuỗi user-agent tĩnh.
Các Kỹ thuật Tiên tiến
- Proxy Dân cư: Sử dụng proxy dân cư để phân phối các yêu cầu trên nhiều địa chỉ IP, làm cho websites khó chặn bạn hơn.
- Trình duyệt Headless: Các công cụ như Puppeteer và Selenium mô phỏng các tương tác của người dùng thực sự, làm cho hệ thống chống bot khó phát hiện hoạt động lấy dữ liệu của bạn hơn.
- Học Máy cho Chống phát hiện: Đào tạo bot để tái tạo hành vi của con người gần gũi hơn bằng cách phân tích các mô hình duyệt web, giảm thiểu khả năng bị đánh dấu là bot.
Kết thúc
Chúc mừng! Bạn đã học được rất nhiều về phát hiện bot. Bạn đã từ cơ bản trở thành một bậc thầy trong việc chống phát hiện!
Bây giờ bạn đã biết:
- Bot chống là gì.
- Một số thực hành tốt nhất để bỏ qua các kỹ thuật chống bot.
- Một số cơ chế phổ biến mà bot chống dựa vào.
- Cách để bỏ qua tất cả chúng.
Bạn có thể khám phá thêm các kỹ thuật chống lấy dữ liệu, nhưng, bất kể trình thu thập dữ liệu của bạn tinh vi đến đâu, một số kỹ thuật vẫn có thể chặn nó.
Tất cả các vấn đề này có thể được tránh bằng cách sử dụng Scrapeless, một API lấy dữ liệu web với proxy tiên tiến, xoay vòng IP tích hợp, khả năng trình duyệt headless và khả năng vượt qua chống bot tiên tiến. Đây là một cách đơn giản hơn để lấy dữ liệu từ web.
Bắt đầu dùng thử miễn phí ngay bây giờ!
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


