
Cách vượt qua thử thách Cloudflare năm 2025: Hướng dẫn đầy đủ
Advanced Data Extraction Specialist
Cloudflare liên tục phát triển các biện pháp bảo mật, khiến các phương pháp scraping truyền thống ngày càng khó vượt qua các thử thách như cloudflare-challenge và Cloudflare Turnstile. Các công cụ mã nguồn mở như FlareSolverr đã trở nên vô hiệu do các bản cập nhật của Cloudflare, khiến các nhà phát triển phải tìm kiếm các giải pháp mới.
Trong hướng dẫn này, chúng ta sẽ khám phá các phương pháp hiệu quả nhất trong năm 2025 để vượt qua các thử thách bảo mật của Cloudflare, bao gồm:
- Scrapeless Scraping Browser – Một API trình duyệt headless để scraping liền mạch
- Scrapeless Web Unlocker – Một API mạnh mẽ để xử lý và tương tác JS
Cho dù bạn là chuyên gia tự động hóa web hay người mới bắt đầu, hướng dẫn này cung cấp các giải pháp từng bước để giúp bạn trích xuất dữ liệu mà không gặp phải trở ngại.
PHẦN 1: Hiểu về Thử thách Cloudflare và Các Lớp Bảo mật
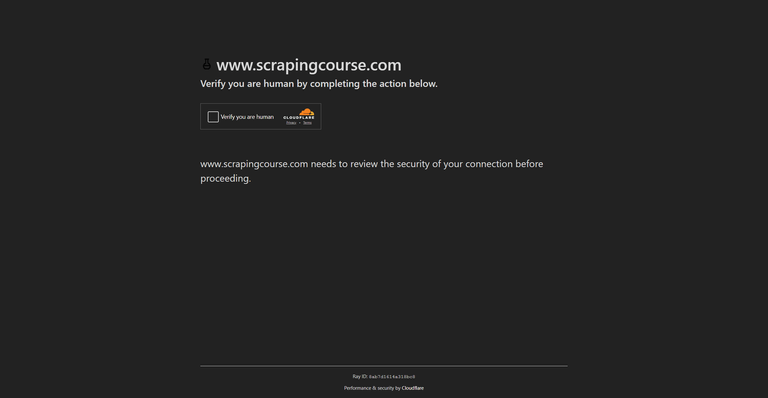
Trước khi tìm hiểu các giải pháp, điều cần thiết là hiểu các cơ chế bảo mật chính của Cloudflare chặn các yêu cầu tự động:
1. Thử thách Cloudflare JS
Thử thách JavaScript của Cloudflare (cloudflare-challenge) yêu cầu trình duyệt thực thi một script trước khi truy cập trang được yêu cầu. Script này tạo ra một token xóa được lưu trữ trong cookie (cf_clearance). Bot và scraper không có khả năng thực thi JavaScript sẽ không vượt qua được thử thách này.
2. Cloudflare Turnstile
Turnstile là thay thế CAPTCHA của Cloudflare, phát hiện lưu lượng truy cập không phải của con người một cách động. Nó thường yêu cầu thực thi JavaScript và theo dõi hành vi để hoàn thành.
3. Dấu vân tay trình duyệt
Cloudflare sử dụng dấu vân tay tiên tiến để phát hiện các tương tác không phải của con người. Điều này bao gồm việc phân tích:
- Dấu vân tay TLS (chữ ký JA3)
- Tiêu đề HTTP và thứ tự
- WebGL, Canvas, và Dấu vân tay Âm thanh
4. Hạn chế tốc độ và chặn IP
Ngay cả khi bạn vượt qua thử thách một lần, các yêu cầu lặp lại từ cùng một IP có thể kích hoạt lệnh cấm hoặc tăng mức độ bảo mật.
PHẦN 2: Thử thách Cloudflare JS Khác với các Thử thách Khác như thế nào?
Không giống như CAPTCHA, yêu cầu tương tác của người dùng, Thử thách JS chạy tự động ở chế độ nền, làm cho nó ít gây khó chịu hơn đối với người dùng hợp pháp trong khi vẫn chặn lưu lượng truy cập đáng ngờ. Tuy nhiên, đối với các công cụ web scraper và tự động hóa, việc vượt qua Thử thách JS có thể khó khăn vì nhiều client HTTP cơ bản và trình duyệt headless không thể thực thi JavaScript chính xác.
PHẦN 3: Vượt qua Thử thách Cloudflare JS với Scrapeless Scraping Browser
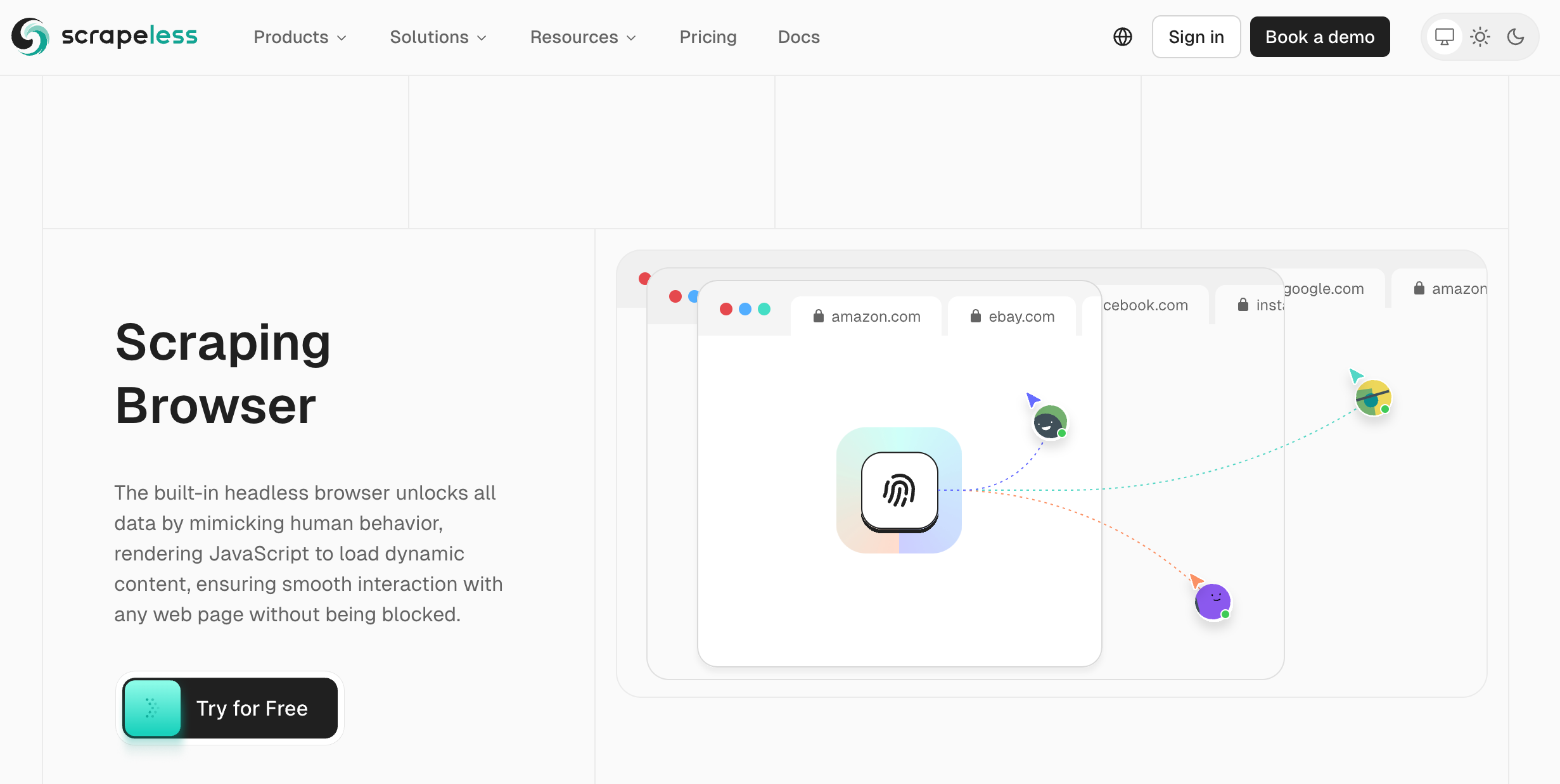
3.1 Scrapeless Scraping Browser là gì?
Scrapeless Scraping Browser là một giải pháp hiệu năng cao cung cấp môi trường trình duyệt headless, cho phép bạn vượt qua các thử thách JavaScript mà không cần duy trì cơ sở hạ tầng của riêng mình. Nó tích hợp với Puppeteer và Playwright để tự động hóa liền mạch.
Scrapeless Scraping Browser là công cụ bypass Cloudflare tiên tiến nhất, nó cung cấp:
✔️ Tỷ lệ thành công 99,9% để vượt qua thử thách Cloudflare
✔️ Tương thích liền mạch với Puppeteer / Playwright
✔️ Được điều khiển bởi AI, tự động thích ứng với các chính sách bảo mật mới nhất
✔️ Hỗ trợ proxy toàn cầu, giảm nguy cơ bị cấm
3.2 Cài đặt & Cấu hình khóa API
Trước khi sử dụng Scrapeless Scraping Browser, hãy lấy khóa API:
- Đăng ký trên bảng điều khiển Scrapeless
- Lấy khóa API của bạn từ tab cài đặt
🎁 Nhận 10.000 yêu cầu API miễn phí cho người dùng mới! Đăng ký ngay
3.3 Triển khai Bypass Cloudflare với Trình duyệt Scrapeless
Kết nối với Scrapeless Browserless WebSocket
Scrapeless cung cấp kết nối WebSocket cho phép Puppeteer tương tác trực tiếp với trình duyệt headless, do đó vượt qua thử thách Cloudflare.
👉 Địa chỉ kết nối WebSocket đầy đủ:
wss://browser.scrapeless.com/browser?token=APIKey&session_ttl=180&proxy_country=ANYVí dụ mã: Vượt qua thử thách Cloudflare
Chúng ta chỉ cần chuẩn bị mã sau để kết nối với dịch vụ browserless của Scrapeless.
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com';
const query = new URLSearchParams({
token: API_KEY,
session_ttl: '180', // Chu kỳ sống của phiên trình duyệt, tính bằng giây
proxy_country: 'GB', // Quốc gia đại lý
proxy_session_id: 'test_session_id', // ID phiên proxy được sử dụng để giữ nguyên IP proxy. Thời gian phiên mặc định là 3 phút, dựa trên cài đặt proxy_session_duration.
proxy_session_duration: '5' // Thời gian phiên đại lý, đơn vị phút
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')📢 Hãy thử Scrapeless miễn phí ngay hôm nay và dễ dàng vượt qua Cloudflare! 👉 Đăng ký ngay
Truy cập trang web được bảo vệ bởi Cloudflare & xác minh ảnh chụp màn hình
Tiếp theo, chúng ta sử dụng scrapeless browserless để truy cập trực tiếp vào trang kiểm tra cloudflare-challenge và thêm ảnh chụp màn hình, cho phép chúng ta thấy hiệu quả rất trực quan. Trước khi chụp ảnh màn hình, vui lòng lưu ý rằng bạn cần sử dụng waitForSelector để chờ các phần tử trên trang, đảm bảo rằng thử thách Cloudflare đã được vượt qua thành công.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// Bằng cách chờ các phần tử trên trang web, đảm bảo rằng thử thách Cloudflare đã được vượt qua thành công.
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
await page.screenshot({path: 'challenge-bypass.png'});Chúc mừng! 🎉 bạn đã vượt qua thử thách cloudflare với scrapeless browserless.

Lấy cookie cf_clearance và Tiêu đề
Ngoài ra, sau khi vượt qua thử thách Cloudflare, bạn cũng có thể lấy tiêu đề yêu cầu và cookie cf_clearance từ trang thành công.
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueBật chặn yêu cầu để chụp tiêu đề yêu cầu, khớp các yêu cầu trang sau khi thử thách cloudflare.
await page.setRequestInterception(true);
page.on('request', request => {
// Khớp các yêu cầu trang sau khi thử thách cloudflare
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});PHẦN 4: Vượt qua Cloudflare Turnstile với Scrapeless Scraping Browser
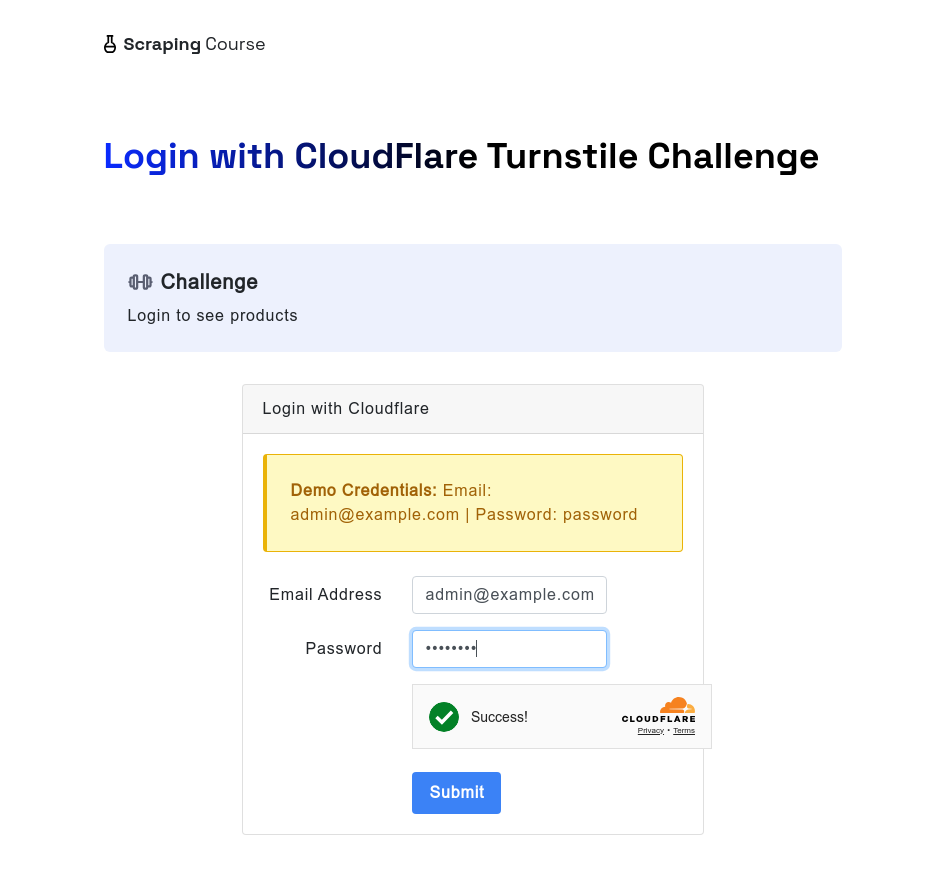
Tương tự, khi gặp Cloudflare Turnstile, trình duyệt scrapeless vẫn có thể xử lý nó tự động. Ví dụ dưới đây truy cập trang kiểm tra cloudflare-turnstile. Sau khi nhập tên người dùng và mật khẩu, nó sử dụng phương thức waitForFunction để chờ dữ liệu từ window.turnstile.getResponse(), đảm bảo rằng thử thách đã được vượt qua thành công. Sau đó, nó chụp ảnh màn hình và nhấp vào nút đăng nhập để điều hướng đến trang tiếp theo.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Chờ turnstile mở khóa thành công
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });Sau khi thực thi script này, bạn sẽ có thể thấy hiệu ứng mở khóa thông qua ảnh chụp màn hình.
PHẦN 5: Sử dụng Scrapeless Web Unlocker để Xử lý JavaScript
Scrapeless Web Unlocker cho phép xử lý JavaScript và tương tác động, làm cho nó trở thành một công cụ hiệu quả để vượt qua Cloudflare.
Xử lý JavaScript
Xử lý JavaScript cho phép xử lý nội dung được tải động và SPA (Ứng dụng trang đơn). Cho phép môi trường trình duyệt hoàn chỉnh, hỗ trợ các tương tác và yêu cầu hiển thị trang phức tạp hơn.
js_render=true, chúng ta sẽ sử dụng trình duyệt để yêu cầu
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"js_render": true
},
"proxy": {
"country": "US"
}
}Hướng dẫn JavaScript
Cung cấp một tập hợp các chỉ thị JavaScript rộng rãi cho phép bạn tương tác động với các trang web.
Các chỉ thị này cho phép bạn nhấp vào các phần tử, điền vào biểu mẫu, gửi biểu mẫu hoặc chờ các phần tử cụ thể xuất hiện, cung cấp tính linh hoạt cho các tác vụ như nhấp vào nút “đọc thêm” hoặc gửi biểu mẫu.
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"js_render": true,
"js_instructions": [
{
"wait_for": [
".dynamic-content",
30000
]
// Chờ phần tử
},
{
"click": [
"#load-more",
1000
]
// Nhấp vào phần tử
},
{
"fill": [
"#search-input",
"search term"
]
// Điền vào biểu mẫu
},
{
"keyboard": [
"press",
"Enter"
]
// Mô phỏng nhấn phím
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Thực thi JS tùy chỉnh
}
]
}
}Ví dụ vượt qua thử thách
Ví dụ mã sau sử dụng axios để thực hiện yêu cầu đến dịch vụ Web Unlocker của Scrapeless. Nó bật js_render và sử dụng chỉ thị wait_for của tham số js_instructions để chờ một phần tử trên trang sau khi thử thách Cloudflare đã được vượt qua:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
js_render: true,
js_instructions: [
{
wait_for: [
"main.page-content .challenge-info",
30000
]
}
]
},
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();🎉 Sau khi thực hiện script ở trên, bạn sẽ có thể thấy HTML của trang đã vượt qua thử thách Cloudflare thành công trong bảng điều khiển.
Scrapeless - Giải pháp mở khóa trang web động mạnh mẽ hơn
Đối với các trang web động, tải Ajax và ứng dụng trang đơn (SPA), Scrapeless cung cấp Web Unlocker, có thể tự động giải quyết các thử thách Cloudflare để tránh bị phát hiện là robot.
✅ Tự động bypass được điều khiển bởi AI, thích ứng với các bản cập nhật chống thu thập dữ liệu của Cloudflare
✅ Hỗ trợ nhóm proxy toàn cầu, bypass ổn định các hạn chế IP
✅ Tương thích liền mạch với Puppeteer / Playwright
💡 Hãy thử Scrapeless Web Unlocker ngay bây giờ và dễ dàng thu thập dữ liệu trang web động! 👉 Trải nghiệm ngay
Câu hỏi thường gặp về thử thách cloudflare
Câu hỏi: Thử thách Cloudflare là gì?
Đáp: Thử thách Cloudflare là biện pháp bảo mật được sử dụng để bảo vệ các trang web khỏi các hoạt động độc hại như tấn công bot và tấn công DDoS. Khi Cloudflare phát hiện hành vi đáng ngờ, nó sẽ đưa ra một thử thách cho người truy cập để xác minh rằng họ là người dùng hợp pháp.
Câu hỏi: Tại sao tôi bị thách thức trên một trang web được bảo vệ bởi Cloudflare?
Đáp: Bạn có thể bị thách thức vì một số lý do, bao gồm điểm đe dọa cao liên quan đến địa chỉ IP của bạn, lịch sử hoạt động đáng ngờ từ IP của bạn, phát hiện lưu lượng truy cập tự động giống bot hoặc các quy tắc cụ thể do chủ sở hữu trang web đặt ra nhắm mục tiêu vào khu vực hoặc tác nhân người dùng của bạn. Cloudflare cũng xác minh rằng trình duyệt của bạn đáp ứng các tiêu chuẩn nhất định.
Câu hỏi: Có những loại thử thách Cloudflare khác nhau là gì?
Đáp: Cloudflare sử dụng các loại thử thách khác nhau, bao gồm Thử thách được Quản lý, Thử thách JS và Thử thách Tương tác. Thử thách được Quản lý được khuyến nghị, nơi Cloudflare động lựa chọn loại thử thách phù hợp dựa trên đặc điểm yêu cầu. Thử thách JS hiển thị một trang yêu cầu xử lý JavaScript bằng trình duyệt. Thử thách Tương tác yêu cầu người truy cập tương tác với trang để giải các câu đố.
Câu hỏi: Thử thách được Quản lý là gì?
Đáp: Thử thách được Quản lý là một hệ thống động, nơi Cloudflare chọn loại thử thách phù hợp dựa trên đặc điểm của yêu cầu. Điều này có thể bao gồm các trang thử thách không tương tác, các thử thách tương tác tùy chỉnh hoặc Mã thông báo Truy cập Riêng tư. Mục tiêu là giảm thiểu việc sử dụng CAPTCHA và giảm thời gian người dùng dành để giải chúng.
Tham gia Cộng đồng Discord Scrapeless ngay hôm nay! 🚀 Kết nối với các chuyên gia scraper, nhận mẹo độc quyền về việc vượt qua các thử thách Cloudflare và cập nhật các tính năng mới nhất. Nhấp vào đây để tham gia ngay.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


