
5 Trình Duyệt Lấy Dữ Liệu Hàng Đầu 2025 | Chỉ Nhớ Mà Khóc!
Expert Network Defense Engineer
Web Scraping Là Gì Và Nó Được Sử Dụng Như Thế Nào?
Web scraping là một công nghệ dùng để trích xuất dữ liệu từ Internet, thường bằng cách tự động thu thập và cấu trúc thông tin trên trang web. Quá trình scraping thường bao gồm truy cập vào một trang web bằng cách gửi yêu cầu HTTP, lấy nội dung trang và sau đó phân tích cú pháp và trích xuất dữ liệu cần thiết, chẳng hạn như văn bản, hình ảnh, liên kết, dữ liệu bảng, v.v.
Scraping là một trong những công nghệ cốt lõi cho việc thu thập dữ liệu quy mô lớn và được sử dụng rộng rãi trong nhiều lĩnh vực, chẳng hạn như theo dõi giá cả, nghiên cứu thị trường, phân tích đối thủ cạnh tranh, tổng hợp tin tức và nghiên cứu học thuật. Vì dữ liệu của nhiều trang web được trình bày dưới dạng các trang HTML, nên web scraping có thể chuyển đổi những nội dung này thành dữ liệu có cấu trúc để phân tích và sử dụng sau này.
Web Scraping Hoạt Động Như Thế Nào?
Bước 1. Gửi yêu cầu: Công cụ web scraping của bạn trước tiên sẽ gửi yêu cầu HTTP đến trang web mục tiêu để mô phỏng hành vi duyệt web của người dùng thực.
Bước 2. Lấy nội dung trang web: Trang web sẽ trả về nội dung trang HTML, và scraper sẽ phân tích cú pháp nó.
Bước 3. Phân tích dữ liệu: Nó sử dụng các công cụ phân tích cú pháp HTML (chẳng hạn như BeautifulSoup, lxml, v.v.) để trích xuất dữ liệu cụ thể trên trang.
Bước 4. Lưu trữ dữ liệu: Dữ liệu được trích xuất có thể được lưu trữ ở các định dạng như CSV, JSON hoặc cơ sở dữ liệu để xử lý và phân tích sau này.
Các trình duyệt scraping thường thực hiện các bước này tự động, cung cấp quá trình scraping hiệu quả và đáng tin cậy hơn.
Cách Chọn Một Trình Duyệt Web Scraper
Có nhiều cách để truy cập dữ liệu web. Ngay cả khi bạn đã thu hẹp phạm vi xuống các trình duyệt web scraper, các công cụ với nhiều tính năng gây nhầm lẫn xuất hiện trong kết quả tìm kiếm vẫn có thể khiến việc đưa ra quyết định trở nên khó khăn.
Trước khi chọn một trình duyệt web scraper, bạn có thể xem xét các khía cạnh sau:
- Thiết bị: Nếu bạn là người dùng Mac hoặc Linux, bạn nên đảm bảo rằng công cụ hỗ trợ hệ thống của bạn vì hầu hết các trình duyệt web scraper chỉ khả dụng cho Windows.
- Dịch vụ đám mây: Dịch vụ đám mây rất quan trọng nếu bạn muốn truy cập dữ liệu trên nhiều thiết bị bất cứ lúc nào.
- Truy cập API và proxy IP: Web scraping có những thách thức riêng và các kỹ thuật chống scraping. Xoay vòng IP và truy cập API sẽ giúp bạn không bao giờ bị chặn.
- Tích hợp: Bạn sẽ sử dụng dữ liệu sau này như thế nào? Các tùy chọn tích hợp có thể tự động hóa tốt hơn toàn bộ quá trình xử lý dữ liệu.
- Đào tạo: Nếu bạn không giỏi lập trình, tốt hơn hết là nên đảm bảo rằng có các hướng dẫn và hỗ trợ để giúp bạn trong suốt quá trình scraping dữ liệu.
- Giá cả: Chi phí của các trình duyệt web scraper luôn là một yếu tố cần xem xét và nó khác nhau rất nhiều giữa các nhà cung cấp.
Top 5 Trình Duyệt Scraping
1. Scrapeless
Trình Duyệt Scraping Scrapeless cung cấp một nền tảng serverless hiệu suất cao được thiết kế để đơn giản hóa quá trình trích xuất dữ liệu từ các trang web động. Thông qua tích hợp liền mạch với Puppeteer, các nhà phát triển có thể chạy, quản lý và giám sát các trình duyệt headless mà không cần máy chủ chuyên dụng, cho phép tự động hóa web và thu thập dữ liệu hiệu quả.
Với mạng lưới toàn cầu bao phủ 195 quốc gia và hơn 70 triệu IP dân cư, Trình Duyệt Scraping cung cấp thời gian hoạt động 99,9% và tỷ lệ thành công cao. Nó bỏ qua các trở ngại phổ biến như chặn IP và CAPTCHA, làm cho nó lý tưởng cho tự động hóa web phức tạp và thu thập dữ liệu dựa trên AI. Hoàn hảo cho người dùng cần một giải pháp scraping web đáng tin cậy, có khả năng mở rộng.
Làm thế nào để tích hợp công cụ scraping web này vào dự án của bạn? Hãy làm theo các bước của tôi ngay bây giờ!
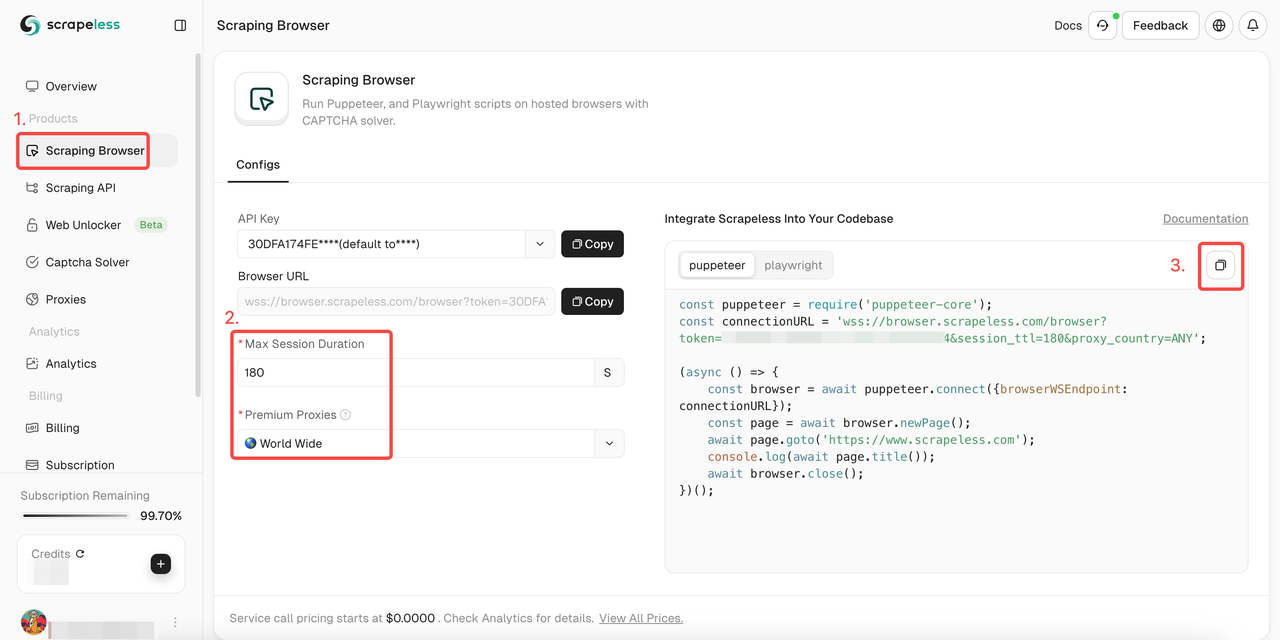
- Đăng nhập Scrapeless
- Nhập "Trình Duyệt Scraping"
- Đặt tham số theo nhu cầu của bạn
- Sao chép các mã mẫu để tích hợp vào dự án của bạn
- Mã mẫu:
- Puppeteer
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //nhập token của bạn
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- Playwright
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //nhập token của bạn
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- Muốn biết thêm chi tiết? Tài liệu của chúng tôi sẽ giúp bạn rất nhiều!
2. ParseHub
Parsehub là một công cụ web scraping phổ biến sử dụng JavaScript, công nghệ AJAX, cookie, v.v. để thu thập dữ liệu từ các trang web. Nó hỗ trợ các hệ thống Windows, Mac OS X và Linux.
Parsehub sử dụng công nghệ máy học để đọc, phân tích tài liệu web và chuyển đổi chúng thành dữ liệu có liên quan. Nhưng nó không hoàn toàn miễn phí, bạn chỉ có thể thiết lập tối đa năm tác vụ scraping miễn phí.
3. Import
Import.io là một phần mềm tích hợp dữ liệu web SaaS độc đáo. Nó cung cấp cho người dùng cuối một môi trường trực quan để thiết kế và tùy chỉnh quy trình làm việc thu thập dữ liệu.
Nó bao gồm toàn bộ vòng đời trích xuất web từ trích xuất dữ liệu đến phân tích trên một nền tảng. Và bạn cũng có thể dễ dàng tích hợp vào các hệ thống khác.
Ngoài trình duyệt scraping được lưu trữ đầy đủ, chúng ta cũng có thể sử dụng các plugin hoặc tiện ích mở rộng mạnh mẽ:
4. Webscraper
Web Scraper có tiện ích mở rộng Chrome và tiện ích mở rộng đám mây.
Đối với phiên bản tiện ích mở rộng Chrome, bạn có thể tạo sơ đồ trang web (kế hoạch) về cách điều hướng trang web và dữ liệu nào nên được scraping.
Tiện ích mở rộng đám mây có thể scraping một lượng lớn dữ liệu và chạy nhiều tác vụ scraping đồng thời. Bạn có thể xuất dữ liệu sang CSV hoặc lưu trữ dữ liệu trong Couch DB.
5. Dexi
Dexi.io dành nhiều hơn cho người dùng nâng cao có kỹ năng lập trình thành thạo. Nó có ba loại chương trình để bạn tạo các tác vụ scraping - trình trích xuất, trình thu thập và đường dẫn. Nó cung cấp nhiều công cụ cho phép bạn trích xuất dữ liệu chính xác hơn. Với các tính năng hiện đại của nó, bạn sẽ có thể xử lý thông tin chi tiết trên bất kỳ trang web nào.
Tuy nhiên, nếu bạn không có kỹ năng lập trình, bạn có thể cần dành một chút thời gian để làm quen với nó trước khi bạn có thể tạo ra một robot scraping web.
Tại Sao Trình Duyệt Scraping Có Thể Nâng Cao Công Việc Của Bạn?
Các trình duyệt scraping (chẳng hạn như Puppeteer, Playwright, v.v.) có thể cải thiện đáng kể hiệu quả thu thập web vì những lý do sau:
- Hỗ trợ nội dung động: Các trình duyệt scraping có thể xử lý nội dung trang được tạo động bằng JavaScript bằng cách cung cấp khả năng hiển thị trình duyệt đầy đủ và thu thập thêm dữ liệu hợp lệ.
- Mô phỏng hành vi người dùng thực: Các trình duyệt scraping có thể mô phỏng hành vi người dùng thực, chẳng hạn như nhấp chuột, cuộn, nhập dữ liệu, v.v., để tránh bị phát hiện bởi các cơ chế chống thu thập.
- Cải thiện độ ổn định: Các trình duyệt scraping có thể cải thiện tỷ lệ thành công và độ ổn định của việc thu thập bằng cách tích hợp quản lý proxy, các giải pháp mã xác minh tự động và các chức năng khác.
- Hỗ trợ đa nền tảng: Nhiều trình duyệt thu thập hỗ trợ hoạt động đa nền tảng và có thể chạy trên các hệ điều hành khác nhau (Windows, Linux, MacOS, v.v.), cung cấp nhiều tính linh hoạt hơn.
- Hỗ trợ đồng thời cao: Một số trình duyệt thu thập (chẳng hạn như Browserless) cũng cung cấp dịch vụ đám mây, hỗ trợ thu thập đồng thời cao và thu thập dữ liệu quy mô lớn, phù hợp với các trường hợp cần xử lý lượng lớn dữ liệu.
Suy Nghĩ Cuối Cùng
Công cụ scraping web nào phù hợp nhất với bạn, trình duyệt Scraping hay tiện ích mở rộng scraping? Bạn chắc chắn muốn sử dụng công cụ thuận tiện và hiệu quả nhất để scraping web nhanh chóng. Hãy thử Scrapeless ngay bây giờ!
Trình duyệt scraping Scrapeless làm cho việc scraping web đơn giản và hiệu quả. Với việc bỏ qua CAPTCHA và xoay vòng IP thông minh, bạn có thể tránh bị chặn trang web và dễ dàng đạt được việc scraping dữ liệu.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


