
Como configurar o ChromeDriver não detectado no Scrapeless?
Advanced Data Extraction Specialist
Descubra como o Undetected ChromeDriver ajuda a bypassar sistemas anti-bot para web scraping, juntamente com orientações passo a passo, métodos avançados e limitações principais. Além disso, conheça o Scrapeless - uma alternativa mais robusta para necessidades profissionais de scraping.
Neste guia, você aprenderá:
- O que é o Undetected ChromeDriver e como ele pode ser útil
- Como ele minimiza a detecção de bots
- Como usá-lo com Python para web scraping
- Uso e métodos avançados
- Suas principais limitações e desvantagens
- Alternativa recomendada: Scrapeless
- Análise técnica dos mecanismos de detecção de anti-bot
Vamos mergulhar!
O que é o Undetected ChromeDriver?
O Undetected ChromeDriver é uma biblioteca Python que fornece uma versão otimizada do ChromeDriver do Selenium. Esta foi corrigida para limitar a detecção por serviços anti-bot como:
- Imperva
- DataDome
- Distil Networks
- e mais...
Ele também pode ajudar a bypassar certas proteções do Cloudflare, embora isso possa ser mais desafiador.
Se você já usou ferramentas de automação de navegador como o Selenium, sabe que elas permitem controlar navegadores programaticamente. Para tornar isso possível, elas configuram os navegadores de maneira diferente da configuração normal do usuário.
Sistemas anti-bot procuram por essas diferenças, ou "vazamentos", para identificar bots de navegador automatizados. O Undetected ChromeDriver corrige os drivers do Chrome para minimizar esses sinais evidentes, reduzindo a detecção de bots. Isso o torna ideal para web scraping em sites protegidos por medidas de anti-scraping!
Como funciona o Undetected ChromeDriver?
O Undetected ChromeDriver reduz a detecção de Cloudflare, Imperva, DataDome e soluções semelhantes empregando as seguintes técnicas:
- Renomeando variáveis do Selenium para imitar aquelas usadas por navegadores reais
- Usando strings de User-Agent legítimas e reais para evitar a detecção
- Permitindo que o usuário simule interações naturais de humanos
- Gerenciando cookies e sessões adequadamente enquanto navega em sites
- Permitindo o uso de proxies para bypassar bloqueios de IP e prevenir limitação de taxa
Esses métodos ajudam o navegador controlado pela biblioteca a contornar várias defesas de anti-scraping de maneira eficaz.
Usando o Undetected ChromeDriver para Web Scraping: Guia Passo a Passo
Passo #1: Pré-requisitos e Configuração do Projeto
O Undetected ChromeDriver tem os seguintes pré-requisitos:
- Última versão do Chrome
- Python 3.6+: Se o Python 3.6 ou superior não estiver instalado em sua máquina, baixe-o do site oficial e siga as instruções de instalação.
Nota: A biblioteca baixa e corrige automaticamente o binário do driver para você, então não há necessidade de baixar manualmente o ChromeDriver.
Crie um diretório para seu projeto:
language
mkdir undetected-chromedriver-scraper
cd undetected-chromedriver-scraper
python -m venv envAtive o ambiente virtual:
language
# No Linux ou macOS
source env/bin/activate
# No Windows
env\Scripts\activatePasso #2: Instale o Undetected ChromeDriver
Instale o Undetected ChromeDriver via o pacote pip:
language
pip install undetected_chromedriverEssa biblioteca instalará automaticamente o Selenium, já que é uma de suas dependências.
Passo #3: Configuração Inicial
Crie um arquivo scraper.py e importe undetected_chromedriver:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Inicializar uma instância do Chrome
driver = uc.Chrome()
# Conectar à página alvo
driver.get("https://scrapeless.com")
# Lógica de scraping...
# Fechar o navegador
driver.quit()Passo #4: Implementar a Lógica de Scraping
Agora vamos adicionar a lógica para extrair dados da página da Apple:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
import time
# Criar uma instância do driver web do Chrome
driver = uc.Chrome()
# Conectar-se ao site da Apple
driver.get("https://www.apple.com/fr/")
# Dar à página algum tempo para carregar completamente
time.sleep(3)
# Dicionário para armazenar informações dos produtos
apple_products = {}
try:
# Encontrar seções de produtos (usando as classes do HTML fornecido)
product_sections = driver.find_elements(By.CSS_SELECTOR, ".homepage-section.collection-module .unit-wrapper")
for i, section in enumerate(product_sections):
try:
# Extrair nome do produto (título)
headline = section.find_element(By.CSS_SELECTOR, ".headline, .logo-image").get_attribute("textContent").strip()
# Extrair descrição (subtítulo)
python
subhead_element = section.find_element(By.CSS_SELECTOR, ".subhead")
subhead = subhead_element.text
# Obter o link se estiver disponível
link = ""
try:
link_element = section.find_element(By.CSS_SELECTOR, ".unit-link")
link = link_element.get_attribute("href")
except:
pass
apple_products[f"product_{i+1}"] = {
"name": headline,
"description": subhead,
"link": link
}
except Exception as e:
print(f"Erro ao processar a seção {i+1}: {e}")
# Exportar os dados extraídos para JSON
with open("apple_products.json", "w", encoding="utf-8") as json_file:
json.dump(apple_products, json_file, indent=4, ensure_ascii=False)
print(f"Extraídos com sucesso {len(apple_products)} produtos da Apple")
except Exception as e:
print(f"Erro durante a extração: {e}")
finally:
# Fechar o navegador e liberar seus recursos
driver.quit()Execute com:
language
python scraper.pyChromeDriver Indetectável: Uso Avançado
Agora que você sabe como a biblioteca funciona, está pronto para explorar alguns cenários mais avançados.
Escolher uma Versão Específica do Chrome
Você pode especificar uma versão particular do Chrome para a biblioteca usar configurando o argumento version_main:
language
import undetected_chromedriver as uc
# Especificar a versão alvo do Chrome
driver = uc.Chrome(version_main=105)Com Sintaxe
Para evitar chamar manualmente o método quit() quando você não precisar mais do driver, você pode usar a sintaxe with:
language
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("https://example.com")
# Resto do seu código...Limitações do ChromeDriver Indetectável
Embora o undetected_chromedriver seja uma biblioteca Python poderosa, ele possui algumas limitações conhecidas:
Bloqueios de IP
A biblioteca não oculta seu endereço IP. Se você estiver executando um script de um datacenter, as chances de detecção ainda ocorrerem são altas. Da mesma forma, se seu IP doméstico tiver uma má reputação, você também pode ser bloqueado.
Para ocultar seu IP, você precisa integrar o navegador controlado a um servidor proxy, conforme demonstrado anteriormente.
Sem Suporte para Navegação GUI
Devido ao funcionamento interno do módulo, você deve navegar programaticamente usando o método get(). Evite usar a GUI do navegador para navegação manual—interagir com a página usando o teclado ou mouse aumenta o risco de detecção.
Suporte Limitado para Modo Headless
Oficialmente, o modo headless não é totalmente suportado pela biblioteca undetected_chromedriver. No entanto, você pode experimentar com:
language
driver = uc.Chrome(headless=True)Problemas de Estabilidade
Os resultados podem variar devido a inúmeros fatores. Nenhuma garantia é fornecida, exceto esforços contínuos para entender e enfrentar algoritmos de detecção. Um script que contorna com sucesso sistemas anti-bot hoje pode falhar amanhã se os métodos de proteção receberem atualizações.
Alternativa Recomendada: Scrapeless
Dadas as limitações do ChromeDriver Indetectável, o Scrapeless oferece uma alternativa mais robusta e confiável para raspagem da web sem ser bloqueado.
Protegemos firmemente a privacidade do site. Todos os dados neste blog são públicos e são usados apenas como demonstração do processo de crawling. Não salvamos nenhuma informação e dados.
Por que o Scrapeless é Superior
Scrapeless é um serviço de navegador remoto que aborda os problemas inerentes à abordagem do ChromeDriver Indetectável:
-
Atualizações constantes: Ao contrário do ChromeDriver Indetectável, que pode parar de funcionar após atualizações do sistema anti-bot, o Scrapeless é continuamente atualizado pela sua equipe.
-
Rotação de IP embutida: O Scrapeless oferece rotação automática de IP, eliminando o problema de bloqueio de IP do ChromeDriver Indetectável.
-
Configuração otimizada: Os navegadores Scrapeless já estão otimizados para evitar detecção, o que simplifica muito o processo.
-
Solução automática de CAPTCHA: O Scrapeless pode resolver automaticamente os CAPTCHAs que você pode encontrar.
-
Compatível com múltiplos frameworks: Funciona com Playwright, Puppeteer e outras ferramentas de automação.
Faça login no Scrapeless para um teste gratuito.
Leitura recomendada: Como Bypassar Cloudflare Com Puppeteer
Como usar o Scrapeless para raspar a web (sem ser bloqueado)
Aqui está como implementar uma solução semelhante com Scrapeless usando Playwright:
Passo 1: Registre-se e faça login no Scrapeless
Passo 2: Obtenha a CHAVE da API Scrapeless
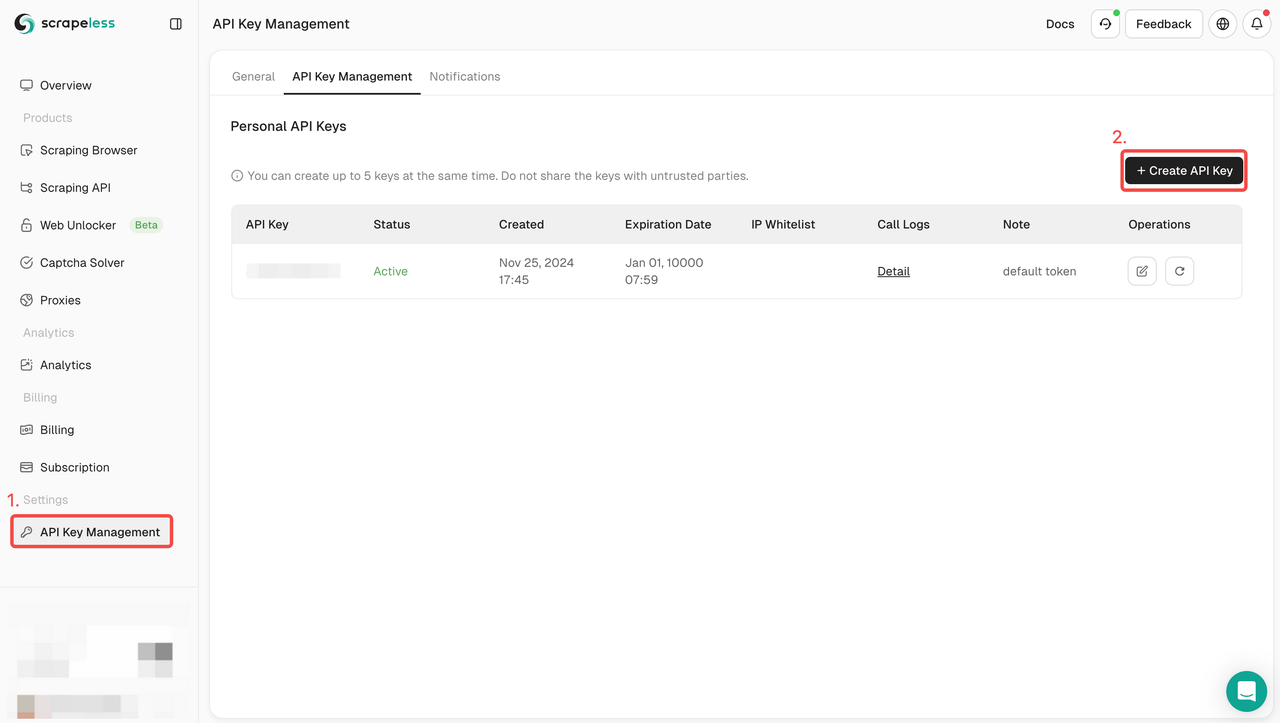
Passo 3: Você pode integrar o seguinte código em seu projeto
language
const {chromium} = require('playwright-core');
// URL de conexão Scrapeless com seu token
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOUR_TOKEN_HERE&session_ttl=180&proxy_country=ANY';
(async () => {
// Conectar ao navegador remoto Scrapeless
const browser = await chromium.connectOverCDP(connectionURL);
try {
// Criar uma nova página
const page = await browser.newPage();
// Navegar para o site da Apple
console.log('Navegando para o site da Apple...');
await page.goto('https://www.apple.com/fr/', {
waitUntil: 'domcontentloaded',
timeout: 60000
});
console.log('Página carregada com sucesso');
// Esperar pelas seções de produtos estarem disponíveis
await page.waitForSelector('.homepage-section.collection-module', { timeout: 10000 });
// Obter produtos em destaque da página inicial
const products = await page.evaluate(() => {
const results = [];
// Obter todas as seções de produtos
const productSections = document.querySelectorAll('.homepage-section.collection-module .unit-wrapper');
productSections.forEach((section, index) => {
try {
// Obter nome do produto - pode estar em .headline ou .logo-image
const headlineEl = section.querySelector('.headline') || section.querySelector('.logo-image');
const headline = headlineEl ? headlineEl.textContent.trim() : 'Produto Desconhecido';
// Obter descrição do produto
const subheadEl = section.querySelector('.subhead');
const subhead = subheadEl ? subheadEl.textContent.trim() : '';
// Obter link do produto
const linkEl = section.querySelector('.unit-link');
const link = linkEl ? linkEl.getAttribute('href') : '';
results.push({
name: headline,
description: subhead,
link: link
});
} catch (err) {
console.error(`Erro ao processar a seção ${index}: ${err.message}`);
}
});
return results;
});
// Exibir os resultados
console.log('Produtos da Apple encontrados:');
console.log(JSON.stringify(products, null, 2));
console.log(`Total de produtos encontrados: ${products.length}`);
} catch (error) {
console.error('Ocorreu um erro:', error);
} finally {
// Fechar o navegador
await browser.close();
console.log('Navegador fechado');
}
})();Você também pode participar do Scrapeless Discord para participar do programa de suporte ao desenvolvedor e receber até 500k créditos de uso da API SERP gratuitamente.
Análise Técnica Aprimorada
Detecção de Bots: Como Funciona
Sistemas anti-bot usam várias técnicas para detectar automação:
-
Impressão digital do navegador: Coleta dezenas de propriedades do navegador (fontes, canvas, WebGL, etc.) para criar uma assinatura única.
-
Detecção de WebDriver: Procura a presença da API WebDriver ou seus artefatos.
-
Análise comportamental: Analisa movimentos do mouse, cliques, velocidade de digitação que diferem entre humanos e bots.
-
Detecção de anomalias de navegação: Identifica padrões suspeitos, como solicitações muito rápidas ou falta de carregamento de imagens/CSS.
Leitura recomendada: Como Bypass Anti Bot
Como o Undetected ChromeDriver Ignora a Detecção
O Undetected ChromeDriver contorna essas detecções por meio de:
-
Remoção de indicadores WebDriver: Elimina a propriedade
navigator.webdrivere outros rastros do WebDriver. -
Patch de Cdc_: Modifica variáveis do Controlador do Chrome Driver que são assinaturas conhecidas do ChromeDriver.
-
Uso de User-Agents realistas: Substitui User-Agents padrão por strings atualizadas.
-
Minimização de alterações na configuração: Reduz as alterações no comportamento padrão do navegador Chrome.
Código técnico mostrando como o Undetected ChromeDriver modifica o driver:
language
Trecho simplificado do código-fonte do Undetected ChromeDriver
def _patch_driver_executable():
"""
Modifica o binário do ChromeDriver para remover sinais de automação
"""
linect = 0
replacement = os.urandom(32).hex()
with io.open(self.executable_path, "r+b") as fh:
for line in iter(lambda: fh.readline(), b""):
if b"cdc_" in line.lower():
fh.seek(-len(line), 1)
newline = re.sub(
b"cdc_.{22}", b"cdc_" + replacement.encode(), line
)
fh.write(newline)
linect += 1
return linectPor que o Scrapeless é Mais Eficaz
Scrapeless adota uma abordagem diferente ao:
-
Ambiente pré-configurado: Usando navegadores já otimizados para imitar usuários humanos.
-
Infraestrutura com base na nuvem: Executando navegadores na nuvem com a devida identificação.
-
Rotação inteligente de proxy: Rotacionando automaticamente os IPs com base no site-alvo.
-
Gerenciamento avançado de impressões digitais: Mantendo impressões digitais de navegador consistentes durante toda a sessão.
-
Supressão de WebRTC, Canvas e Plugins: Bloqueando técnicas comuns de identificação.
Faça login no Scrapeless para um teste gratuito.
Conclusão
Neste artigo, você aprendeu como lidar com a detecção de bots no Selenium usando Undetected ChromeDriver. Esta biblioteca fornece uma versão corrigida do ChromeDriver para raspagem de dados sem ser bloqueado.
O desafio é que tecnologias avançadas de anti-bot como o Cloudflare ainda conseguirão detectar e bloquear seus scripts. Bibliotecas como undetected_chromedriver são instáveis—embora possam funcionar hoje, podem não funcionar amanhã.
Para necessidades profissionais de raspagem, soluções baseadas na nuvem como o Scrapeless oferecem uma alternativa mais robusta. Elas fornecem navegadores remotos pré-configurados especificamente projetados para contornar medidas anti-bot, com recursos adicionais como rotação de IP e resolução de CAPTCHA.
A escolha entre Undetected ChromeDriver e Scrapeless depende das suas necessidades específicas:
- Undetected ChromeDriver: Bom para projetos menores, gratuito e de código aberto, mas requer mais manutenção e pode ser menos confiável.
- Scrapeless: Melhor para necessidades profissionais de raspagem, mais confiável, constantemente atualizado, mas com um custo de assinatura.
Ao entender como essas tecnologias de contorno de anti-bot funcionam, você pode escolher a ferramenta certa para seus projetos de raspagem na web e evitar as armadilhas comuns da coleta de dados automatizada.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


