
Como Raspar Resultados do Google Acadêmico
Advanced Data Extraction Specialist
O Google Scholar é uma ferramenta importante para pesquisadores acadêmicos em todo o mundo encontrarem e obterem literatura, abrangendo artigos, monografias e trabalhos de conferências em diversas áreas. No entanto, devido ao seu rigoroso mecanismo anti-crawler, não é fácil extrair dados do Google Scholar diretamente, especialmente para usuários que precisam de coleta de dados em larga escala.
Neste artigo, apresentaremos dois métodos para extrair dados do Google Scholar: extração manual (Scrapy/Selenium) e API Scrapeless. A extração manual é adequada para coleta de dados em pequena escala, mas pode encontrar restrições de IP e problemas de código de verificação. A API Scrapeless fornece uma solução mais estável e eficiente, especialmente para extração de dados em larga escala, sem a necessidade de manter estratégias adicionais anti-detecção.
Comparando as vantagens e desvantagens dos dois métodos, este artigo ajudará você a escolher a solução mais adequada para alcançar uma coleta de dados eficiente.
Por que extrair dados do Google Scholar?
O Google Scholar fornece valiosos recursos acadêmicos, incluindo artigos de pesquisa, citações, perfis de autores e muito mais. Ao extrair dados do Google Scholar, você pode:
- Coletar artigos de pesquisa sobre um tópico específico.
- Extrair contagens de citações para análise de impacto acadêmico.
- Recuperar perfis de autores e seus trabalhos publicados.
- Automatizar revisões de literatura para fins de pesquisa.
Desafios na extração de dados do Google Scholar
Extrair dados do Google Scholar apresenta desafios como:
- CAPTCHAs: solicitações frequentes podem acionar a proteção anti-bot do Google.
- Bloqueio de IP: o Google pode bloquear IPs que fazem solicitações automatizadas repetidas.
- Conteúdo dinâmico: alguns resultados podem ser carregados dinamicamente via JavaScript.
Para superar esses desafios, recomendamos o uso de uma API dedicada, como a API Scrapeless.
Método 1: Como extrair dados do Google Scholar - Web Scraping Tradicional (Não Recomendado)
Extrair dados do Google Scholar manualmente usando Python (por exemplo, BeautifulSoup, Selenium) é difícil devido às restrições do Google. Exemplo usando requests:
import requests
from bs4 import BeautifulSoup
url = "https://scholar.google.com/scholar?q=machine+learning"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all("div", class_="gs_r")
for result in results:
title = result.find("h3").text if result.find("h3") else "No Title"
print(title)📌 Desvantagens:
- É fácil acionar o mecanismo anti-raspagem do Google, resultando em bloqueio de IP ou encontrando CAPTCHA.
- A estrutura de dados é complexa, e é necessário analisar HTML e processar conteúdo carregado dinamicamente.
- Não é adequado para coleta de dados em larga escala e possui baixa estabilidade.
Esta abordagem não é confiável devido às medidas anti-bot do Google. Em vez disso, usar uma API como a API Scrapeless é a melhor alternativa.
Método 2: Extraindo dados do Google Scholar com a API Scrapeless (Recomendado)
A API Google Scholar do Scrapeless é uma ferramenta projetada para pesquisa acadêmica e análise de dados. Ela pode extrair automaticamente os resultados da pesquisa do Google Scholar para obter informações importantes, como títulos de artigos, autores, datas de publicação e contagens de citações. Ela analisa a SERP (página de resultados do mecanismo de busca) do Google Scholar para fornecer dados JSON estruturados, evitar bloqueio de IP e verificação de código de verificação, e poupar os usuários de terem que lidar com o desenvolvimento complexo de crawlers.
Além disso, o Scrapeless também suporta pesquisa em tempo real, consulta em lote e filtragem de parâmetros personalizados, o que é adequado para pesquisadores, desenvolvedores e analistas de dados.
Recursos principais da API Google Scholar do Scrapeless
- Análise automática: Não há necessidade de escrever crawlers manualmente, obtenha diretamente dados JSON estruturados.
- Dados em tempo real: Suporte a consultas em tempo real para garantir que os resultados do Google Scholar obtidos sejam os mais recentes.
- Mecanismo anti-raspagem: Contorna automaticamente o CAPTCHA e o bloqueio de IP do Google Scholar, sem a necessidade de proxy ou configuração adicional.
- Campos de dados ricos: Fornece dados detalhados, como título do artigo, autor, data de publicação, número de citações, informações do periódico, artigos relacionados, etc.
- Suporte a consulta em lote: Você pode obter resultados de pesquisa para várias palavras-chave ao mesmo tempo para melhorar a eficiência de extração.
- Parâmetros de pesquisa personalizados: Suporte a filtragem de dados por tempo, idioma, tipo de documento, etc., e localização precisa de informações de destino.
- Acesso estável à API: Com base na arquitetura em nuvem, garante estabilidade e confiabilidade durante o acesso concorrente alto.
Cadastre-se gratuitamente e comece a extrair resultados da pesquisa Google agora!
Acesse o Scrapeless agora para obter uma oportunidade de teste gratuita para facilmente extrair dados dos mecanismos de pesquisa do Google para ajudar seus projetos e análises. Funções poderosas da API podem ajudá-lo a obter informações de pesquisa precisas e melhorar a eficiência. Venha experimentar!
📌 Recursos principais da API Scrapeless:
| API | Função | Caso de uso |
|---|---|---|
| API de Autor | Recupera informações acadêmicas (índice H, número de artigos, etc.) | Análise de impacto acadêmico |
| API de Citações | Recupera formatos de citação de artigos (BibTeX, APA, etc.) | Gerenciamento de artigos |
| API de Resultados Orgânicos | Recupera resultados de pesquisa do Google Scholar | Pesquisa acadêmica |
| API de Perfis | Recupera dados de perfil acadêmico | Análise de pesquisa colaborativa |
Como usar a API Google Scholar do Scrapeless
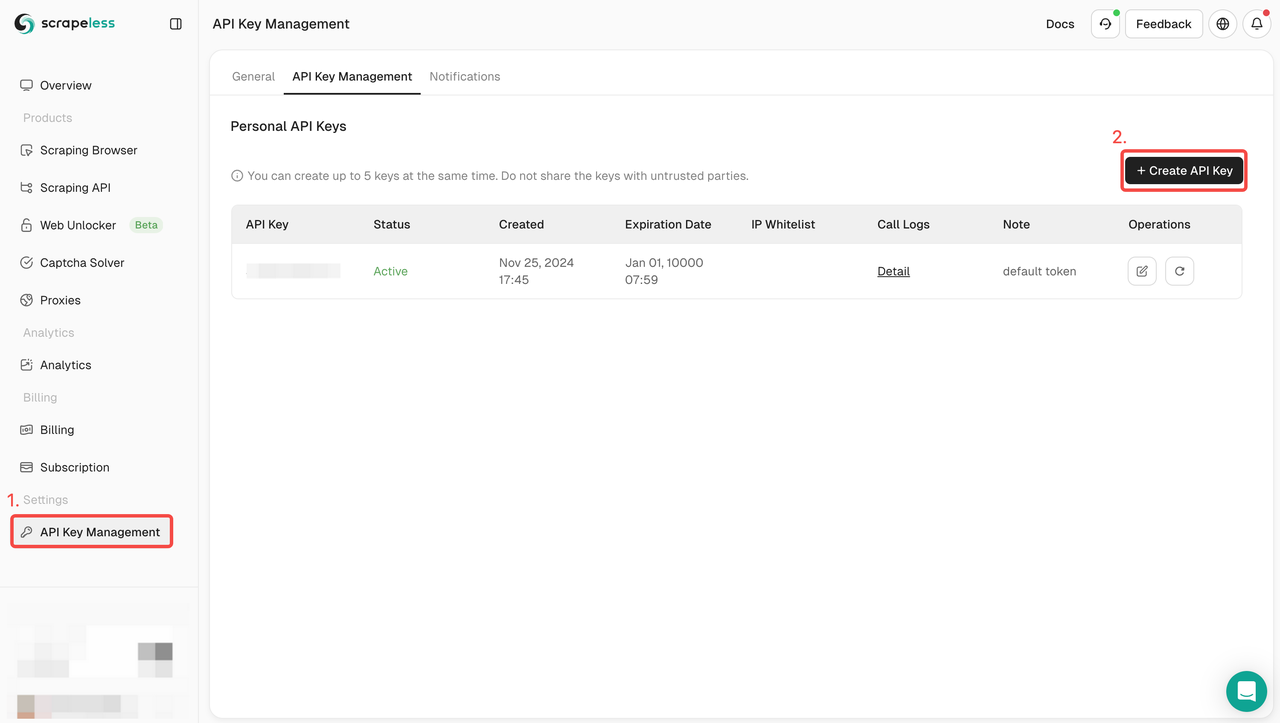
Etapa 1. Obtenha sua chave de API
Para começar, você precisará obter sua chave de API no painel do Scrapeless:
- Faça login no Painel do Scrapeless.
- Navegue até Gerenciamento de chave de API.
- Clique em Criar para gerar sua chave de API exclusiva.
- Depois de criada, basta clicar na chave de API para copiá-la.
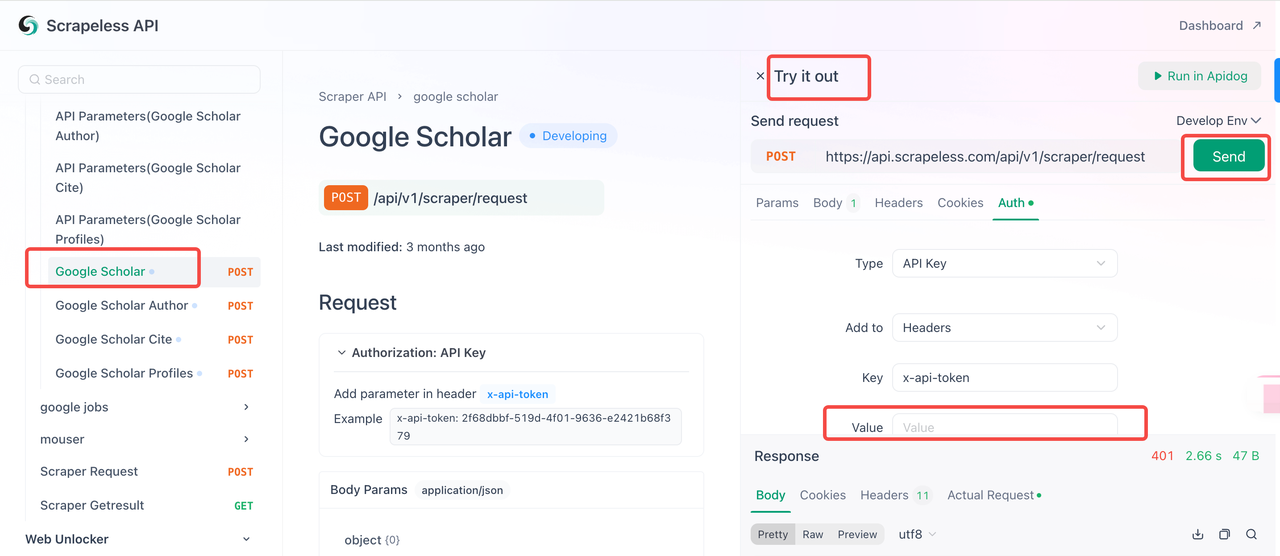
Etapa 2: Use sua chave de API no código
Agora você pode usar sua chave de API para integrar o Scrapeless ao seu projeto. Siga estas etapas para testar e implementar a API:
- Visite a Documentação da API.
- Clique em "Experimente" para o endpoint desejado.
- Insira sua chave de API no campo "Autenticação".
- Clique em "Enviar" para obter a resposta de extração.
Abaixo está um exemplo de código que você pode integrar diretamente ao seu extrator do Google Scholar:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar",
"q": "biology"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Além disso, o Scrapeless também suporta muitas soluções de APIs de extração, como: API de extração da Amazon, API de extração da Shopee, API de extração de voos do Google, API de extração do Google Maps, etc.
API Google Scholar do Scrapeless
A API Google Scholar do Scrapeless é uma ferramenta poderosa que pode extrair artigos acadêmicos, periódicos, livros e outros recursos do Google Scholar por meio de solicitações de API. Permite que os usuários pesquisem por palavras-chave especificadas e obtenham informações detalhadas sobre documentos relacionados, como título, informações de publicação, número de citações, etc.
Parâmetros da API Google Scholar
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
| engine | VERDADEIRO | Definir como google_scholar para usar esta API. |
| q | VERDADEIRO | Consulta de pesquisa (por exemplo, aprendizado de máquina). |
| cites | FALSO | ID exclusivo para encontrar artigos que citam. |
| as_ylo | FALSO | Filtrar resultados de um ano específico. |
| as_yhi | FALSO | Filtrar resultados até um ano específico. |
| hl | FALSO | Configuração de idioma (padrão: en). |
| num | FALSO | Número de resultados (1-20, padrão: 10). |
Exemplo: Extraindo Resultados de Pesquisa do Google Scholar
Código de solicitação:
import requests
import json
Definir a URL de solicitação da API
url = "https://api.scrapeless.com/api/v1/scraper/request"
Definir a carga útil para a solicitação
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar",
"q": "machine learning", # Consulta de pesquisa
"cites": "KNJ0p4CbwgoJ", # Opcional: Encontrar artigos que citam este artigo
"as_ylo": 2015, # Opcional: Filtrar resultados deste ano (ano de início)
"as_yhi": 2023, # Opcional: Filtrar resultados até este ano (ano final)
"hl": "en", # Opcional: Configuração de idioma (o padrão é inglês)
"num": 10 # Opcional: Número de resultados (o padrão é 10)
}
})
Definir cabeçalhos de solicitação
headers = {
'Content-Type': 'application/json'
}
Enviar a solicitação
response = requests.request("POST", url, headers=headers, data=payload)
Imprimir a resposta
print(response.text)Explicação do parâmetro:
- engine: Definido como google_scholar, indicando o uso do Google Scholar para a pesquisa.
- q: A consulta de pesquisa (por exemplo, aprendizado de máquina).
- cites: Opcional. Fornece o ID de um artigo (como KNJ0p4CbwgoJ) para encontrar artigos que o citam.
- as_ylo: Opcional. O ano de início (por exemplo, 2015) para filtrar os resultados.
- as_yhi: Opcional. O ano final (por exemplo, 2023) para filtrar os resultados.
- hl: Opcional. Configuração de idioma, o padrão é en para inglês. Pode ser definido como outros idiomas (por exemplo, zh para chinês).
- num: Opcional. O número de resultados a serem retornados, entre 1 e 20. O padrão é 10.
Exemplo de resposta:
{
"search_information": {
"total_results": 5000000,
"time_taken_displayed": 0.05,
"query_displayed": "machine learning"
},
"organic_result": [
{
"position": 1,
"title": "Uma pesquisa sobre métodos de aprendizado de máquina",
"result_id": "KNJ0p4CbwgoJ",
"link": "https://example.com/article1",
"snippet": "Este artigo fornece uma pesquisa abrangente de métodos de aprendizado de máquina, incluindo aprendizado supervisionado e não supervisionado.",
"publication_info": {
"summary": "Autor1, Autor2 - Journal of Machine Learning, 2020"
}
},
{
"position": 2,
"title": "Aprendizado profundo em inteligência artificial",
"result_id": "KNJ0p4CbwgoK",
"link": "https://example.com/article2",
"snippet": "Este artigo discute as aplicações do aprendizado profundo em várias áreas, incluindo visão computacional e processamento de linguagem natural.",
"publication_info": {
"summary": "Autor3, Autor4 - AI Journal, 2021"
}
}
]
}Estrutura da resposta:
- search_information: Contém detalhes sobre a consulta de pesquisa:
- total_results: O número total de resultados.
- time_taken_displayed: O tempo que levou para exibir os resultados.
- query_displayed: A consulta de pesquisa inserida.
- organic_result: Uma lista dos resultados da pesquisa, cada um com:
- position: A classificação do resultado (por exemplo, 1º, 2º).
- title: O título do artigo.
- result_id: O ID exclusivo do artigo.
- link: A URL para o artigo.
- snippet: Um breve resumo ou extrato do artigo.
- publication_info: Os detalhes da publicação.
Ajustando esses parâmetros, você pode refinar sua pesquisa para obter os resultados mais relevantes do Google Scholar, como limitar os resultados por ano, idioma ou número de resultados.
Quer começar a extrair resultados do Google Scholar? Clique aqui para verificar os detalhes do nosso produto e fazer login agora para começar a usar a API Google Scholar do Scrapeless!
API de Autores do Google Scholar do Scrapeless
A API de Autores do Google Scholar do Scrapeless é uma ferramenta poderosa para obter informações sobre autores acadêmicos no Google Scholar. Ela pode fornecer informações básicas sobre autores, áreas de pesquisa, listas de artigos e dados de citações. Essa API é particularmente adequada para pesquisadores acadêmicos e desenvolvedores extraírem materiais acadêmicos, realizar análises de dados ou integrá-los a outros aplicativos.
Parâmetros da API de Autores do Google Scholar
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
| engine | VERDADEIRO | Definir como google_scholar_author. |
| view_op | FALSO | Visualizar citações ou coautores. |
| sort | FALSO | Classificar por título ou data de publicação. |
| start | FALSO | Deslocamento para paginação. |
| num | FALSO | Número de resultados (máx.: 100). |
| "view_op false" | FALSO | Tem duas opções: view_citation - Selecionar para visualizar citações. citation_id é obrigatório. list_colleagues - Selecionar para visualizar todos os coautores. |
| citation_id | FALSO | É um parâmetro obrigatório quando view_op=view_citation é selecionado. Você pode acessar IDs dentro da nossa resposta JSON estruturada. |
Exemplo: Buscando as Publicações de um Autor
Aqui está um exemplo de código em Python que mostra como usar a API de Autores do Google Scholar do Scrapeless para consultar informações sobre autores acadêmicos:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
# Definir a carga útil da solicitação, especificar o mecanismo de rastreador e o ID do autor
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar_author",
"author_id": "LSsXyncAAAAJ" # Exemplo de ID do autor
}
})
# Definir cabeçalhos de solicitação
headers = {
'Content-Type': 'application/json'
}
# Fazer uma solicitação POST
conn.request("POST", "/api/v1/scraper/request", payload, headers)
# Obter o resultado da resposta
res = conn.getresponse()
# Ler e imprimir dados
data = res.read()
print(data.decode("utf-8"))O resultado retornado pela solicitação da API é uma resposta formatada em JSON contendo informações detalhadas sobre o autor acadêmico, como nome, área acadêmica, instituição, etc. Os dados retornados também incluem uma lista dos artigos e citações do autor. O seguinte é um exemplo simplificado mostrando alguns dos resultados retornados pela API:
{
"name": "John Doe",
"institution": "Harvard University",
"research_areas": [
{
"title": "Epigenética",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:epigenetics"
},
{
"title": "Regulação gênica",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:gene_regulation"
},
{
"title": "Genômica",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:genomics"
},
{
"title": "Fatores de transcrição",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:transcription_factors"
}
...Os dados da resposta contêm informações detalhadas sobre o autor e os resultados da pesquisa. Os campos de resultado específicos incluem:
- research_areas: Lista as áreas de pesquisa do autor, cada uma com um link correspondente apontando para os resultados da pesquisa no Google Scholar.
- thumbnail: URL da imagem do avatar do autor.
- articles: Contém os principais artigos acadêmicos do autor. As informações de cada artigo incluem título, link, autor, periódico de publicação, número de citações, etc.
Por exemplo, as informações detalhadas de um artigo são as seguintes:
- title: Título do artigo
- link: Link do artigo, apontando para a página de citação detalhada no Google Scholar
- citation_id: O ID de citação exclusivo do artigo no Google Scholar
- authors: Lista de todos os autores participantes
- publication: O periódico em que o artigo foi publicado e seu volume e número da edição
- cited_by: O número de vezes que o artigo é citado, e um link para a página de citação é fornecido
Essas informações são muito úteis para pesquisadores acadêmicos e desenvolvedores analisarem as contribuições acadêmicas do autor.
API de Citações do Google Scholar do Scrapeless
A API de Citações do Google Scholar do Scrapeless é uma ferramenta poderosa que permite aos usuários extrair informações de citação de artigos acadêmicos diretamente do Google Scholar. Ela pode recuperar citações formatadas em vários formatos, incluindo MLA, APA, Chicago, Harvard e Vancouver, oferecendo conveniência para pesquisadores, estudantes e desenvolvedores.
Além disso, a API de Citações do Google Scholar do Scrapeless também fornece links de exportação para diferentes ferramentas de gerenciamento de citações (como BibTeX, EndNote, RefMan e RefWorks), permitindo uma integração perfeita com os fluxos de trabalho de referência. Com recuperação de dados em tempo real e saída JSON estruturada, a API de Citações do Google Scholar do Scrapeless simplifica o processo de citação e melhora a eficiência da pesquisa acadêmica.
Parâmetros da API de Citações do Google Scholar
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
| engine | VERDADEIRO | Definir como google_scholar_cite. |
| q | VERDADEIRO | ID de um artigo para recuperar citações. |
| hl | FALSO | Configuração de idioma (padrão: en). |
Exemplo: Extraindo Detalhes da Citação
Aqui está um exemplo de código Python mostrando como fazer uma solicitação à API de Citações do Google Scholar do Scrapeless.
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar_cite",
"q": "s1QWFy06YAYJ"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Exemplo de código de resultado
A API responde com um objeto JSON contendo detalhes de citação em vários formatos:
{
"citations": [
{
"title": "MLA",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "APA",
"snippet": "Masters, P. S. (2006). The molecular biology of coronaviruses. Advances in virus research, 66, 193-292."
},
{
"title": "Chicago",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "Harvard",
"snippet": "Masters, P.S., 2006. The molecular biology of coronaviruses. Advances in virus research, 66, pp.193-292."
},
{
"title": "Vancouver",
...
]
}A API de Citações do Google Scholar do Scrapeless retorna uma estrutura JSON contendo duas seções principais: citations (informações de citação) e links (links de exportação de formato de citação). Abaixo está uma análise detalhada de cada campo:
1. Citações
Este campo é um array onde cada elemento representa um formato de citação diferente, incluindo MLA, APA, Chicago, Harvard e Vancouver. Cada formato inclui os seguintes campos:
| Nome do campo | Tipo de dados | Descrição |
|---|---|---|
| title | String | O nome do formato de citação, como "MLA" ou "APA" |
| snippet | String | O texto da citação no formato respectivo, incluindo o título do artigo, o autor, as informações do periódico, etc. |
Exemplo de dados:
"citations": [
{
"title": "MLA",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "APA",
"snippet": "Masters, P. S. (2006). The molecular biology of coronaviruses. Advances in virus research, 66, 193-292."
}
]Análise de dados:
- title: "MLA" indica que esta entrada segue o formato de citação MLA.
- snippet: O texto da citação inclui o autor Paul S. Masters, o título do artigo The molecular biology of coronaviruses, o periódico Advances in Virus Research, o volume 66 e as páginas 193-292.
2. Links (Links de exportação de citação)
Este campo é um array onde cada elemento fornece um link para exportar a citação em diferentes formatos, como BibTeX, EndNote, RefMan e RefWorks. Cada formato inclui os seguintes campos:
| Nome do campo | Tipo de dados | Descrição |
|---|---|---|
| name | String | O nome do formato de citação, como "BibTeX" ou "EndNote" |
| link | String | Uma URL que permite aos usuários baixar diretamente a citação no formato especificado |
Exemplo de dados:
"links": [
{
"name": "BibTeX",
"link": "https://scholar.googleusercontent.com/scholar.bib?q=info:s1QWFy06YAYJ..."
},
{
"name": "EndNote",
"link": "https://scholar.googleusercontent.com/scholar.enw?q=info:s1QWFy06YAYJ..."
}
]Análise de dados:
- name: "BibTeX" indica que esta entrada é um link de exportação de citação BibTeX.
- link: "https://scholar.googleusercontent.com/scholar.bib?q=info:s1QWFy06YAYJ..." é uma URL direta para acessar a citação BibTeX, que pode ser usada em LaTeX ou outras ferramentas de gerenciamento de referências.
API de Perfis do Google Scholar do Scrapeless
A API de Perfis do Google Scholar do Scrapeless permite que os usuários pesquisem perfis do Google Scholar com base nos nomes dos autores e busquem informações detalhadas, incluindo citações, interesses, afiliações e muito mais. Abaixo está uma visão geral de como usar a API, os parâmetros envolvidos e como interpretar os resultados.
Parâmetros da API de Perfis do Google Scholar
| Parâmetro | Obrigatório | Descrição |
|---|---|---|
| engine | VERDADEIRO | Definir como google_scholar_profiles. |
| mauthors | VERDADEIRO | Nome do autor para pesquisa de perfil. |
| hl | FALSO | Configuração de idioma (padrão: en). |
| after_author | FALSO | Token para paginação. |
Exemplo: Pesquisando um Perfil de Autor
O seguinte código Python demonstra como fazer uma solicitação de API usando o serviço Scrapeless:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar_author",
"author_id": "LSsXyncAAAAJ"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))A API retorna um objeto JSON com informações sobre os resultados da pesquisa. Aqui está um exemplo:
{
"pagination": {
"next": "https://scholar.google.com//citations?view_op=search_authors&hl=en&mauthors=Mike&after_author=pnnfAUQM__8J&astart=10",
"next_page_token": "pnnfAUQM__8J"
},
"profiles": [{
"name": "Mike Robb",
"link": "https://scholar.google.com//citations?hl=en&user=kq0NYnMAAAAJ",
"author_id": "kq0NYnMAAAAJ",
"affiliations": "Departamento de Química, Imperial College",
"email": "Email verificado em imperial.ac.uk",
"cited_by": 230346,
"interests": [
{
"title": "Química computacional",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:computational_chemistry"
},
{
"title": "Química Teórica",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:theoretical_chemistry"
},
{
"title": "interseções cônicas",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:conical_intersections"
},
{
"title": "dinâmica não adiabática",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:non_adiabatic_dynamics"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=kq0NYnMAAAAJ"
},
{
"name": "Mike A. Nalls",
"link": "https://scholar.google.com//citations?hl=en&user=ZjfgPLMAAAAJ",
"author_id": "ZjfgPLMAAAAJ",
"affiliations": "Fundador/consultor da Data Tecnica International + líder em ciência de dados no Centro do NIH para...",
"email": "Email verificado em mail.nih.gov",
"cited_by": 175760,
"interests": [
{
"title": "genética estatística",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:statistical_genetics"
},
{
"title": "neurodegeneração",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:neurodegeneration"
},
{
"title": "ciência de dados",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:data_science"
},
{
"title": "bioestatística",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:biostatistics"
},
{
"title": "genômica",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:genomics"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=ZjfgPLMAAAAJ"
},
{
"name": "mike wright",
"link": "https://scholar.google.com//citations?hl=en&user=RIg9DVEAAAAJ",
"author_id": "RIg9DVEAAAAJ",
"affiliations": "Imperial College",
"email": "Email verificado em imperial.ac.uk",
"cited_by": 131474,
"interests": [
{
"title": "empreendedorismo",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:entrepreneurship"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=RIg9DVEAAAAJ"
},
{
"name": "Mike Lean (MEJ Lean)",
"link": "https://scholar.google.com//citations?hl=en&user=R8PPdbQAAAAJ",
"author_id": "R8PPdbQAAAAJ",
"affiliations": "Professor de Nutrição Humana, Universidade de Glasgow",
"email": "Email verificado em glasgow.ac.uk",
"cited_by": 98488,
"interests": [
{
"title": "Comida",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:food"
},
{
"title": "Nutrição",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:nutrition"
},
{
"title": "Obesidade",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:obesity"
},
{
"title": "Diabetes",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:diabetes"
},
{
"title": "DCV",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:chd"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=R8PPdbQAAAAJ"
},
{
"name": "Mike Schuster",
"link": "https://scholar.google.com//citations?hl=en&user=L9lS9_AAAAAJ",
"author_id": "L9lS9_AAAAAJ",
"affiliations": "Two Sigma",
"email": "Email verificado em twosigma.com",
"cited_by": 96241,
"interests": [
{
"title": "aprendizado de máquina",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:machine_learning"
},
{
"title": "redes neurais",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:neural_networks"
},
{
"title": "aprendizado profundo",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:deep_learning"
},
{
"title": "aprendizado por reforço",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:reinforcement_learning"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=L9lS9_AAAAAJ"
},
{
"name": "prof dr ir Mike SM Jetten",
"link": "https://scholar.google.com//citations?hl=en&user=iXjCKTgAAAAJ",
"author_id": "iXjCKTgAAAAJ",
"affiliations": "Universidade Radboud, Microbiologia, Nijmegen, Países Baixos",
"email": "Email verificado em science.ru.nl",
"cited_by": 88336,
"interests": [
{
"title": "microbiologia anaeróbica",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:anaerobic_microbiology"
},
{
"title": "ciclo do nitrogênio",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:nitrogen_cycle"
},
{
"title": "arqueias metanogênicas",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:methane_archaea"
},
{
"title": "anammox",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:anammox"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=iXjCKTgAAAAJ"
},
{
...
}
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


