
Como raspar resultados do Google Lens com Scrapeless
Advanced Data Extraction Specialist
O que é o Google Lens?
O Google Lens é um aplicativo baseado em inteligência artificial e tecnologia de reconhecimento de imagem que pode identificar objetos, texto, marcos e outros conteúdos através da câmera ou imagens, e fornecer informações relevantes.
É legal raspar dados do Google Lens?
Raspar dados do Google Lens não é ilegal, mas existem várias diretrizes legais e éticas que precisam ser seguidas. Os usuários devem entender os Termos de Serviço do Google, as leis de privacidade de dados e os direitos de propriedade intelectual para garantir que suas atividades estejam em conformidade. Seguindo as melhores práticas e mantendo-se informado sobre os desenvolvimentos legais, você pode minimizar o risco de problemas legais associados à raspagem da web.
Desafios na Raspagem do Google Lens
- Tecnologia avançada anti-bot: O Google monitora os padrões de tráfego de rede. Um grande número de solicitações repetitivas de rastreadores pode ser detectado rapidamente, levando a proibições de IP, o que interrompe o processo de rastreamento.
Leitura recomendada: Anti-Bot: O que é e como evitá-lo - Conteúdo renderizado em JavaScript: Grande parte dos dados do Google Lens é gerada dinamicamente por JavaScript, que é inacessível aos rastreadores tradicionais, exigindo o uso de navegadores sem cabeça, como Puppeteer ou Selenium, mas isso aumenta a complexidade e o consumo de recursos.
- Proteção CAPTCHA: O Google usa CAPTCHA para autenticar usuários humanos. Os rastreadores podem encontrar desafios CAPTCHA que são difíceis de resolver programaticamente.
- Atualizações frequentes do site: O Google muda regularmente a estrutura e o layout do Google Lens. O código de rastreamento pode ficar rapidamente desatualizado, e os seletores XPath ou CSS usados para extração de dados podem parar de funcionar. Monitoramento e atualizações constantes são necessários.
Guia passo a passo para raspar o Google Lens com Python
Passo 1. Configurar o ambiente
- Python: O software é o núcleo da execução do Python. Você pode baixar a versão que precisamos do site oficial, conforme mostrado abaixo. No entanto, não é recomendado baixar a versão mais recente. Você pode baixar 1.2 versões anteriores à versão mais recente.
- IDE Python: Qualquer IDE que suporte Python funcionará, mas recomendamos o PyCharm. É uma ferramenta de desenvolvimento projetada especificamente para Python. Para a versão do PyCharm, recomendamos a edição gratuita do PyCharm Community
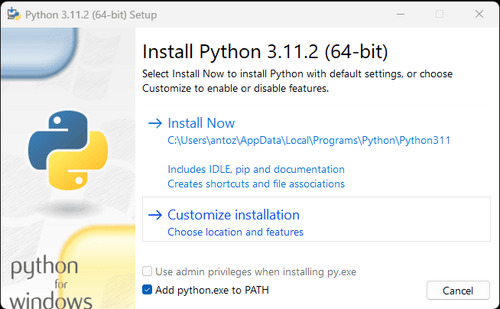
Observação: Se você for um usuário do Windows, não se esqueça de marcar a opção "Adicionar python.exe ao PATH" durante o assistente de instalação. Isso permitirá que o Windows use o Python e comandos no terminal. Como o Python 3.4 ou posterior inclui isso por padrão, você não precisa instalá-lo manualmente.
Agora você pode verificar se o Python está instalado abrindo o terminal ou prompt de comando e inserindo o seguinte comando:
python --versionPasso 2. Instalar Dependências
É recomendado criar um ambiente virtual para gerenciar as dependências do projeto e evitar conflitos com outros projetos Python. Navegue até o diretório do projeto no terminal e execute o seguinte comando para criar um ambiente virtual chamado google_lens:
python -m venv google_lensAtive o ambiente virtual com base em seu sistema:
Windows:
google_lens_env\Scripts\activateMacOS/Linux:
source google_lens_env/bin/activateApós ativar o ambiente virtual, instale as bibliotecas Python necessárias para a raspagem da web. A biblioteca para enviar solicitações em Python é requests, e a biblioteca principal para raspar dados é BeautifulSoup4. Instale-as usando os seguintes comandos:
pip install requests
pip install beautifulsoup4
pip install playwrightPasso 3. Raspar Dados
Abra o Google Lens (https://www.google.com/?olud) em seu navegador e procure por "https://i.imgur.com/HBrB8p0.png". Abaixo está o resultado da pesquisa:
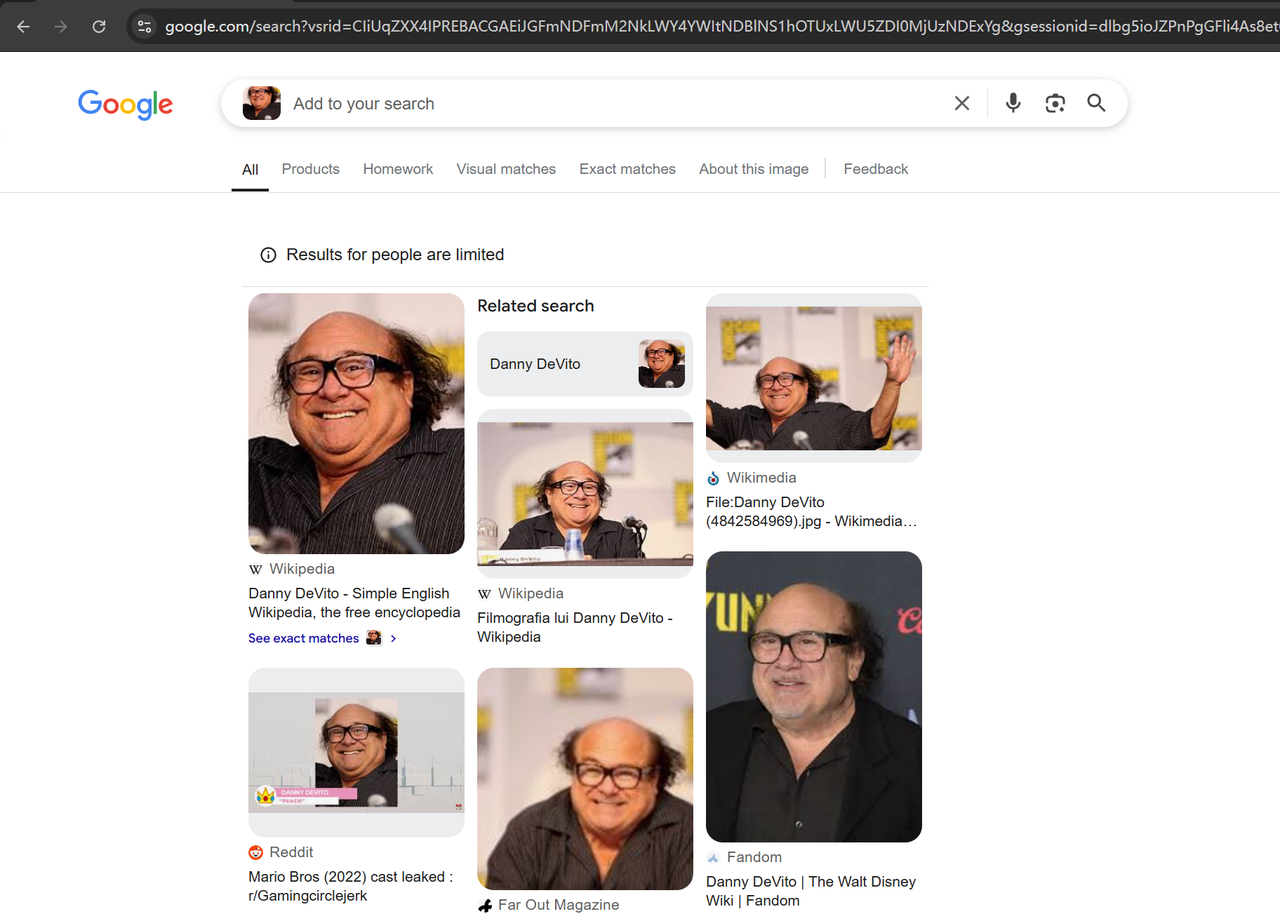
Raspar informações de título e imagem
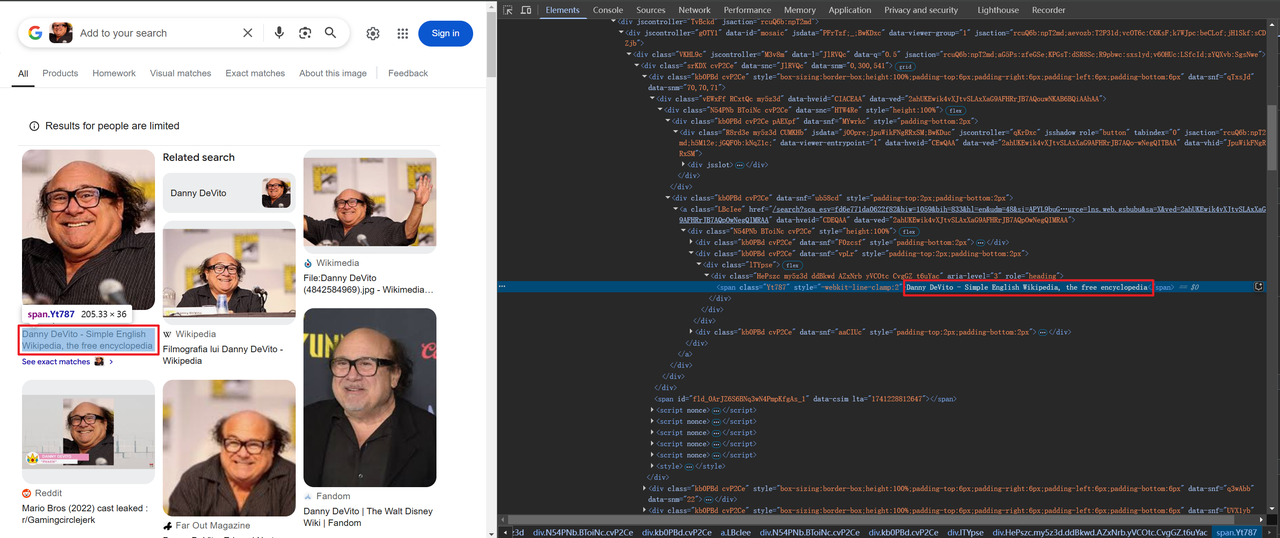
Algumas imagens são codificadas em base64, enquanto outras são vinculadas via HTTP,por exemplo:
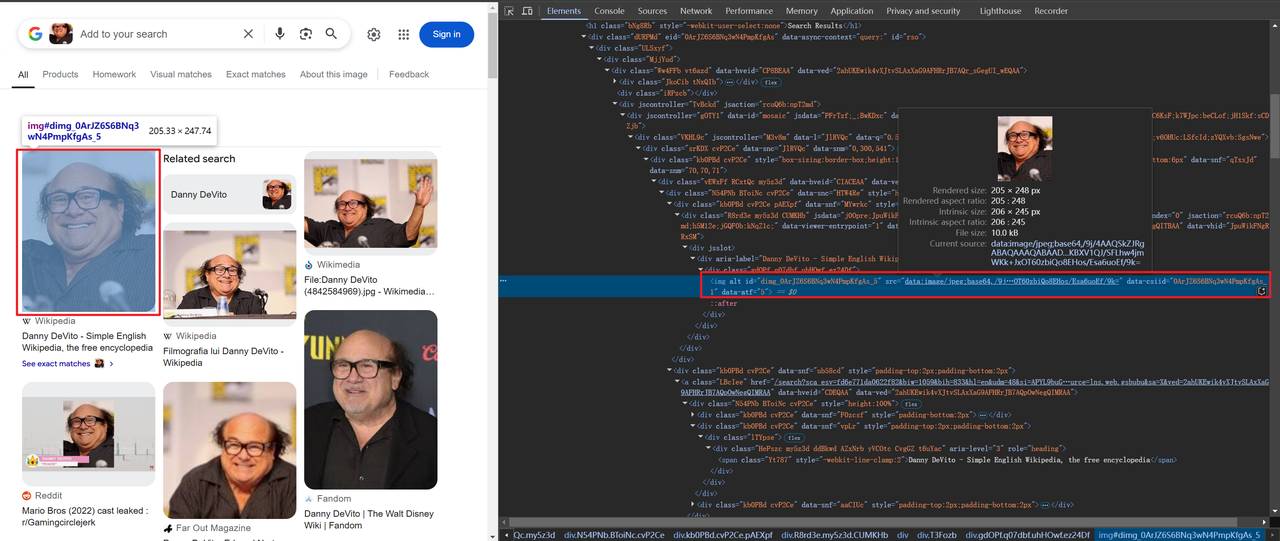
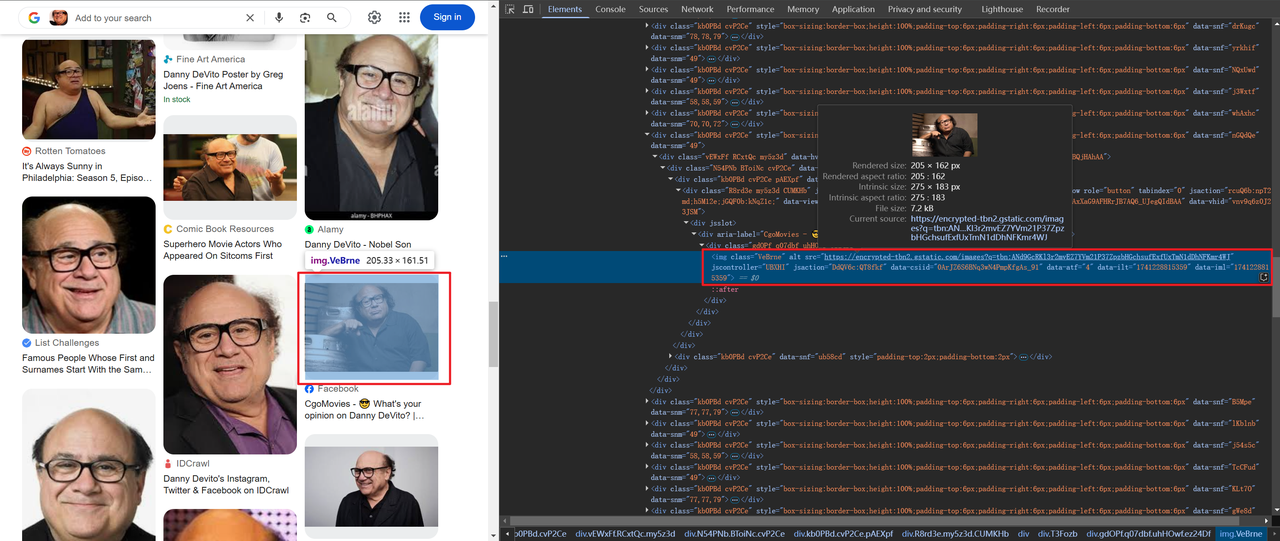
O código para obter informações de título e imagem é o seguinte:
# Armazena informações da lente em um dicionário
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}Como precisamos raspar todos os dados da página, não apenas um, precisamos percorrer e raspar os dados acima. O código completo é o seguinte:
import json
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwright
def scrape(url: str) -> str:
with sync_playwright() as p:
# Inicia o navegador e desabilita alguns recursos que podem causar detecção
browser = p.chromium.launch(
headless=True,
args=[
"--disable-blink-features=AutomationControlled",
"--disable-dev-shm-usage",
"--disable-gpu",
"--disable-extensions",
],
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
bypass_csp=True,
)
page = context.new_page()
page.goto(url)
page.wait_for_selector("body", state="attached")
# Aguarda 2 segundos para garantir que a página esteja totalmente carregada ou renderizada
page.wait_for_timeout(2000)
html_content = page.content()
browser.close()
return html_content
def main():
url = "https://lens.google.com/uploadbyurl?url=https%3A%2F%2Fi.imgur.com%2FHBrB8p0.png"
html_content = scrape(url)
soup = BeautifulSoup(html_content, 'html.parser')
# Obtém os dados principais da página
items = soup.find('div', {'jscontroller': 'M3v8m'}).find("div")
# montagem circular
assembly = lens_info(items)
# Salva os resultados em um arquivo JSON
with open('google_lens_data.json', 'w') as json_file:
json.dump(assembly, json_file, indent=4)
def lens_info(items):
lens_data = []
for item in items:
# Armazena informações da lente em um dicionário
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}
lens_data.append(img_info)
return lens_data
if __name__ == "__main__":
main()Passo 4. Resultados de Saída
Um arquivo chamado google_lens_data.json será gerado em seu diretório PyCharm. A saída é a seguinte (Exemplo parcial):
[
{
"title": "Danny DeVito - Wikipedia",
"thumbnail": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAQEhAQEBAQEB
},
{
"title": "Devito Danny Royalty-Free Images, Stock Photos & Pictures | Shutterstock",
"thumbnail": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcSO6Pkv_UmXiianiCh52nD5s89d7KrlgQQox-f-K9FtXVILvHh_"
},
{
"title": "DATA | Celebrity Stats | Page 62",
"thumbnail": "https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcQ9juRVpW6sjE3OANTKIJzGEkiwUpjCI20Z1ydvJBCEDf3-NcQE"
},
{
"title": "Danny DeVito, Grand opening of Buca di Beppo italian restaurant on Universal City Walk Universal City, California - 28.01.09 Stock Photo - Alamy",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQq_07f-Unr7Y5BXjSJ224RlAidV9pzccqjucD4VF7VkJEJJqBk"
}
]Ferramentas mais eficientes: Como raspar resultados do Google Lens com Scrapeless
O Scrapeless fornece uma ferramenta poderosa que ajuda os desenvolvedores a raspar facilmente os resultados da pesquisa do Google Lens sem escrever código complexo. Aqui estão as etapas detalhadas para integrar a API Scrapeless em sua ferramenta de rastreamento Python:
Passo 1: Cadastre-se no Scrapeless e obtenha uma chave de API
- Se você ainda não possui uma conta Scrapeless, visite o site Scrapeless e cadastre-se.
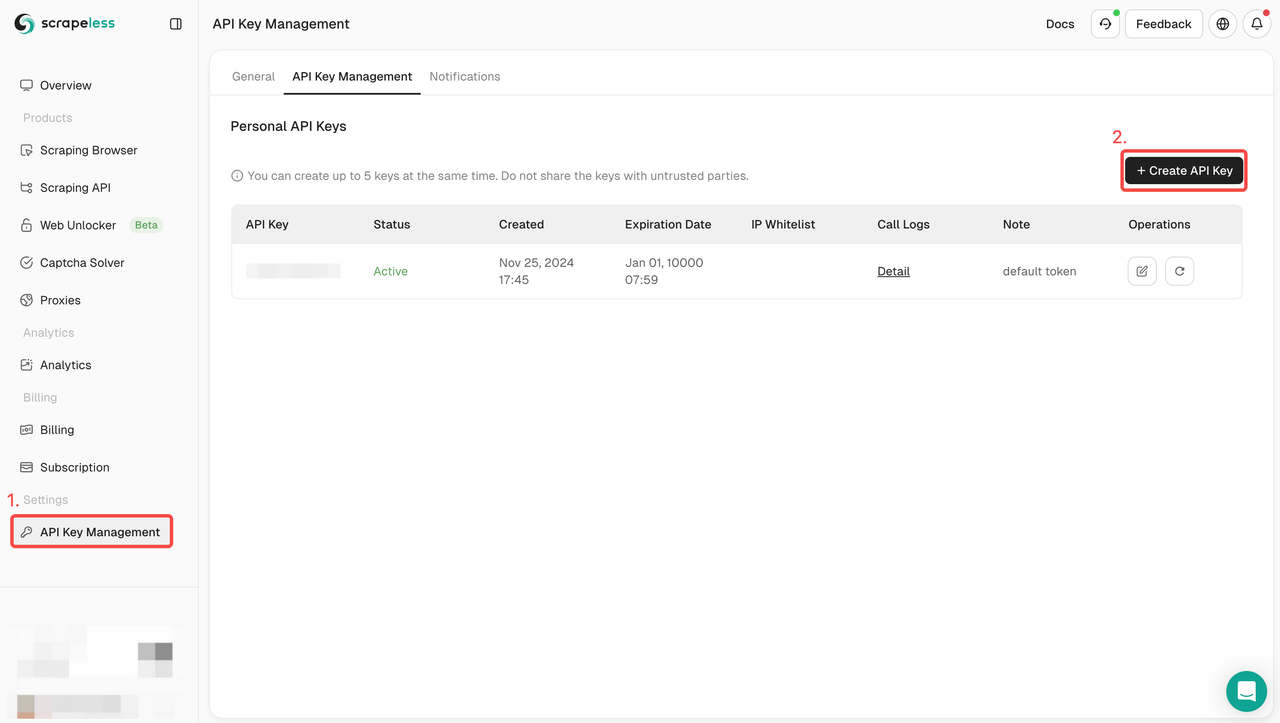
- Depois de se registrar, faça login no seu painel.
- No painel, navegue até Gerenciamento de chave de API e clique em Criar chave de API. Copie a chave de API gerada, que será sua credencial de autenticação ao chamar a API Scrapeless.
Passo 2: Escreva um script Python para integrar a API Scrapeless
O seguinte é um código de amostra para raspar os resultados do Google Lens usando a API Scrapeless:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
engine: "google_lens",
hl: "en",
country: "jp",
url: "https://s3.zoommer.ge/zoommer-images/thumbs/0170510_apple-macbook-pro-13-inch-2022-mneh3lla-m2-chip-8gb256gb-ssd-space-grey-apple-m25nm-apple-8-core-gpu_550.jpeg",
}
payload = Payload("scraper.google.lens", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Observações
Segurança da chave de API: Certifique-se de não expor sua chave de API no repositório de código público.
Otimização de consultas: Ajuste os parâmetros de consulta de acordo com suas necessidades para obter resultados mais precisos. Para obter mais informações sobre os parâmetros da API, você pode consultar a documentação oficial da API do Scrapeless
Por que escolher o Scrapeless para raspar o Google Lens
O Scrapeless é uma poderosa ferramenta de raspagem da web baseada em IA projetada para raspagem da web eficiente e estável.
1. Dados em tempo real e resultados de alta qualidade
O Scrapeless fornece resultados de pesquisa do Google Lens em tempo real e pode retornar resultados de pesquisa do Google Lens em 1 a 2 segundos. Garante que os dados que os usuários obtêm estejam sempre atualizados.
2. Preço acessível
O preço do Scrapeless é muito competitivo, com preços tão baixos quanto apenas US$ 0,1 por 1.000 consultas.
3. Suporte a funções poderosas
O Scrapeless suporta vários tipos de pesquisa, incluindo mais de 20 cenários de resultados de pesquisa do Google. Ele pode retornar dados estruturados em formato JSON, o que é conveniente para os usuários analisarem e usarem rapidamente.
Scrapeless Deep SerpAPI: Uma poderosa solução de dados de pesquisa em tempo real
Scrapeless Deep SerpApi é uma plataforma de dados de pesquisa em tempo real projetada para aplicativos de IA e modelos de geração aumentada por recuperação (RAG). Ele fornece dados de resultados de pesquisa do Google em tempo real, precisos e estruturados, suportando mais de 20 tipos de SERP do Google, incluindo Pesquisa Google, Tendências Google, Google Shopping, Google Flights, Google Hotels, Google Maps, etc.

Recursos principais
- Atualização de dados em tempo real: baseada em atualizações de dados nas últimas 24 horas, garantindo a pontualidade e a precisão das informações.
- Suporte multilíngue e geolocalização: suporta multilíngue e geolocalização, e pode personalizar os resultados da pesquisa com base na localização, tipo de dispositivo e idioma do usuário.
- Resposta rápida: o tempo médio de resposta é de apenas 1 a 2 segundos, adequado para recuperação de dados de alta frequência e grande escala.
- Integração perfeita: compatível com linguagens de programação convencionais, como Python, Node.js, Golang, etc., fácil de integrar a projetos existentes.
- Custo-efetivo: com um preço tão baixo quanto US$ 0,1 por 1.000 consultas, é a solução SERP mais econômica do mercado.
Ofertas especiais
- Teste gratuito: um teste gratuito é fornecido, e os usuários podem experimentar todos os recursos.
- Programa de suporte a desenvolvedores: os 100 primeiros usuários podem obter uma cota gratuita de chamadas de API no valor de US$ 50 (500.000 consultas), adequada para testes e projetos de expansão.
Se você tiver alguma dúvida ou requisito de personalização, pode entrar em contato com Liam clicando no link do Discord.
Conclusão
Neste artigo, detalhamos como usar o Scrapeless para rastrear os resultados da pesquisa do Google Lens. Com a poderosa API fornecida pelo Scrapeless, desenvolvedores e pesquisadores podem obter facilmente dados visuais em tempo real e de alta qualidade sem escrever código complexo ou se preocupar com mecanismos anti-rastreamento. A eficiência e a flexibilidade do Scrapeless o tornam uma ferramenta ideal para processar dados do Google Lens.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.



{kind=link}