
Raspe Google Jobs para criar facilmente listas de empregos usando Scrapeless
Advanced Data Extraction Specialist
Encontrar os dados corretos de emprego rapidamente pode ser um desafio, mas com as ferramentas certas, isso se torna fácil. Raspar vagas de emprego do Google Jobs pode ajudar empresas, sites de empregos e desenvolvedores a coletar informações precisas e atualizadas sobre empregos. Automatizando o processo, você pode facilmente compilar listas completas de empregos, filtrar por local ou tipo de emprego e integrar esses dados à sua plataforma. Neste artigo, mostraremos como raspar o Google Jobs de forma eficiente e criar listas de empregos relevantes e precisas.
O que é o Google Jobs?
O Google Jobs é um mecanismo de busca de empregos especializado fornecido pelo Google que agrega vagas de emprego de diversas fontes, incluindo sites de empregos, sites de empresas e agências de recrutamento. Lançado em 2017, o Google Jobs visa simplificar o processo de busca de emprego, oferecendo uma plataforma unificada para os usuários descobrirem oportunidades de emprego em diferentes setores e locais.
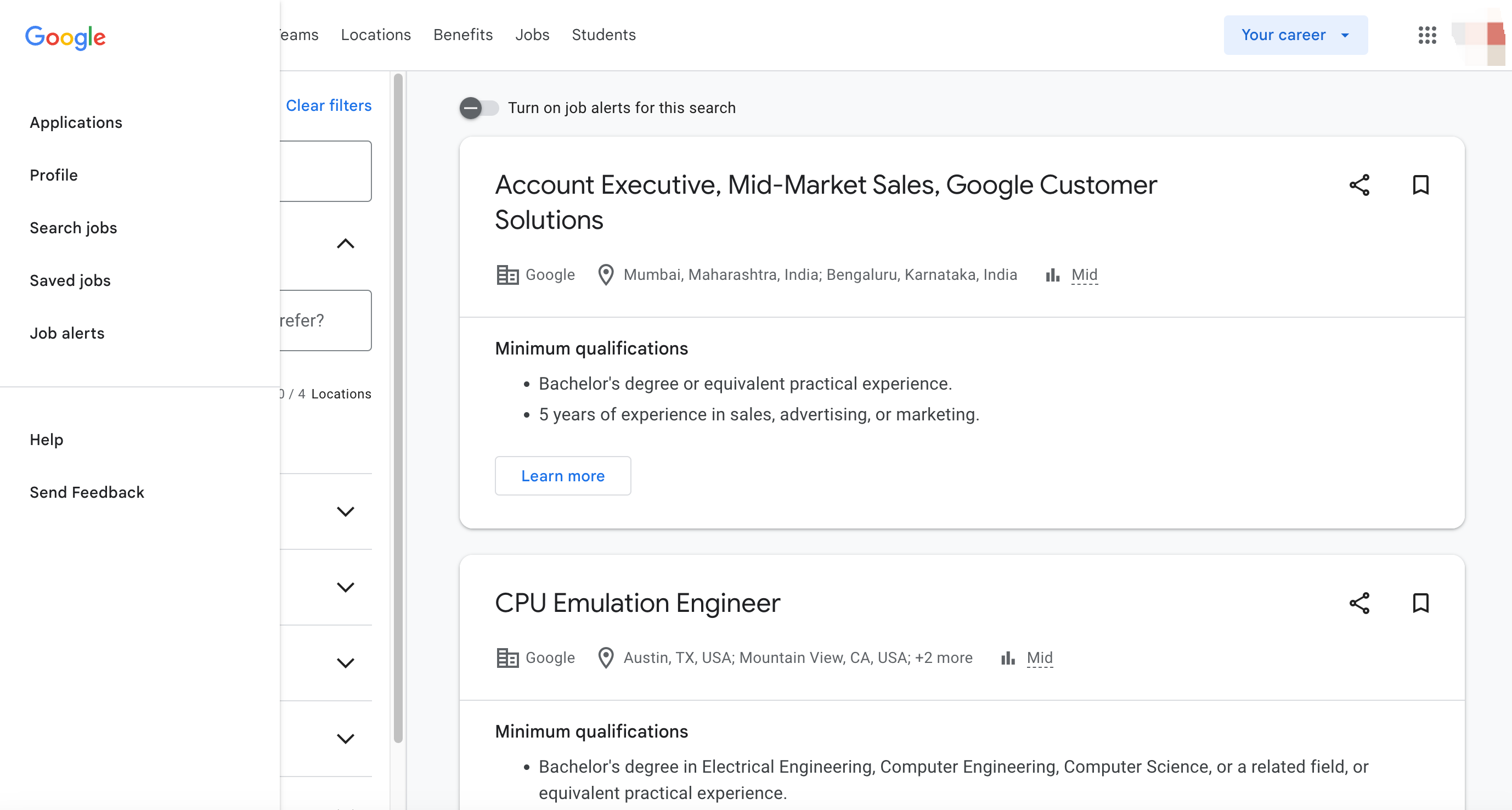
Por que raspar o Google Jobs?
Raspar o Google Jobs oferece várias vantagens para empresas, candidatos a emprego e sites de empregos. Aqui estão alguns dos principais motivos pelos quais você deve considerar raspar dados do Google Jobs:
1. Listagens de empregos completas
O Google Jobs agrega vagas de emprego de várias fontes confiáveis, tornando-se um local central para dados de empregos.
2. Busca personalizável
Você pode filtrar os resultados de empregos com base em critérios específicos, como local, cargo e faixa salarial, o que fornece resultados personalizados para seu público.
3. Automação que economiza tempo
Ao automatizar a raspagem do Google Jobs, você pode garantir que seu site ou aplicativo sempre tenha vagas de emprego atualizadas, eliminando a necessidade de atualizações manuais.
4. Vantagem competitiva
Se você está administrando um site de empregos ou um site de recrutamento, ter acesso aos dados do Google Jobs pode fornecer uma vantagem competitiva, oferecendo vagas de emprego completas que atraem candidatos a emprego.
Raspe o Google Jobs para criar facilmente listas de empregos usando Python
Encontrar os empregos certos pode ser uma tarefa assustadora, mas com o Scrapeless, você pode coletar rápida e eficientemente vagas de emprego do Google Jobs e integrá-las às suas próprias ferramentas. Neste artigo, mostraremos como usar a API Scrapeless para raspar dados de empregos e criar suas próprias listas de empregos.
Scrapeless é uma ferramenta de raspagem da web poderosa e fácil de usar que permite coletar dados estruturados de uma variedade de fontes, incluindo o Google Jobs, sem ter que lidar com as complexidades da raspagem por conta própria.

Vantagens do Scrapeless
-
Dados precisos e completos: Fornece informações precisas sobre empregos, cobrindo conteúdo-chave, como cargo, nome da empresa, local de trabalho, faixa salarial, descrição do emprego etc.
-
Suporta personalização de múltiplos parâmetros: Permite que os desenvolvedores usem mais de 10 parâmetros personalizados, como tipo de emprego (integral, parcial etc.), requisitos de experiência, área de atuação etc., para filtrar com precisão os dados de emprego-alvo.
-
Cobertura multirregional: Pode capturar os resultados da busca do Google Jobs em diferentes países e regiões para atender às necessidades de expansão de negócios globais.
-
Especificação de formato: Dados de saída em formato JSON padronizado, o que é conveniente para os desenvolvedores integrarem e processarem em diferentes sistemas e programas.
-
Fácil de integrar: Fornece uma interface de API simples, que é conveniente para os desenvolvedores chamarem e integrarem usando linguagens de programação comuns (como Python, Java etc.).
-
Atualização em tempo real: Garanta que os dados de emprego obtidos sejam em tempo real e reflitam as informações de recrutamento mais recentes de forma oportuna.
Cadastre-se agora e receba US$ 2 em créditos gratuitos para experimentar todos os nossos recursos poderosos. Não perca!
Passo 1: Crie um ambiente de rastreamento de dados do Google Job
Primeiro, precisamos criar um ambiente de rastreamento de dados e preparar as seguintes ferramentas:
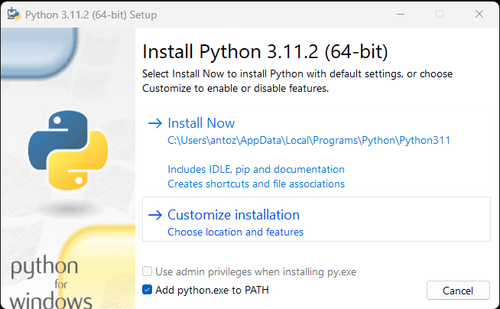
1. Python: Este é o software principal para executar o Python. Você pode baixar a versão que precisamos no link do site oficial, como mostrado na figura abaixo, mas é recomendável não baixar a versão mais recente. Você pode baixar 1 a 2 versões anteriores à versão mais recente.
2. IDE Python: Qualquer IDE que suporte Python servirá, mas recomendamos o PyCharm, que é um software de ferramenta de desenvolvimento IDE projetado especificamente para Python. Quanto à versão do PyCharm, recomendamos a edição gratuita do PyCharm Community.
3. Pip: Você pode usar o Python Package Index para instalar as bibliotecas necessárias para executar seus programas com um único comando.
Observação: Se você for um usuário do Windows, não se esqueça de marcar a opção "Adicionar python.exe ao PATH" no assistente de instalação. Isso permitirá que o Windows use o Python e os comandos no terminal. Como o Python 3.4 ou posterior o inclui por padrão, você não precisa instalá-lo manualmente.
Por meio das etapas acima, o ambiente para rastrear dados do Google Job é configurado. Em seguida, você pode usar o PyCharm baixado em combinação com o Scraperless para rastrear dados do Google Job.
Passo 2: Use o PyCharm e o Scrapeless para raspar dados do Google Jobs
- Inicie o PyCharm e selecione Arquivo > Novo projeto... na barra de menu.
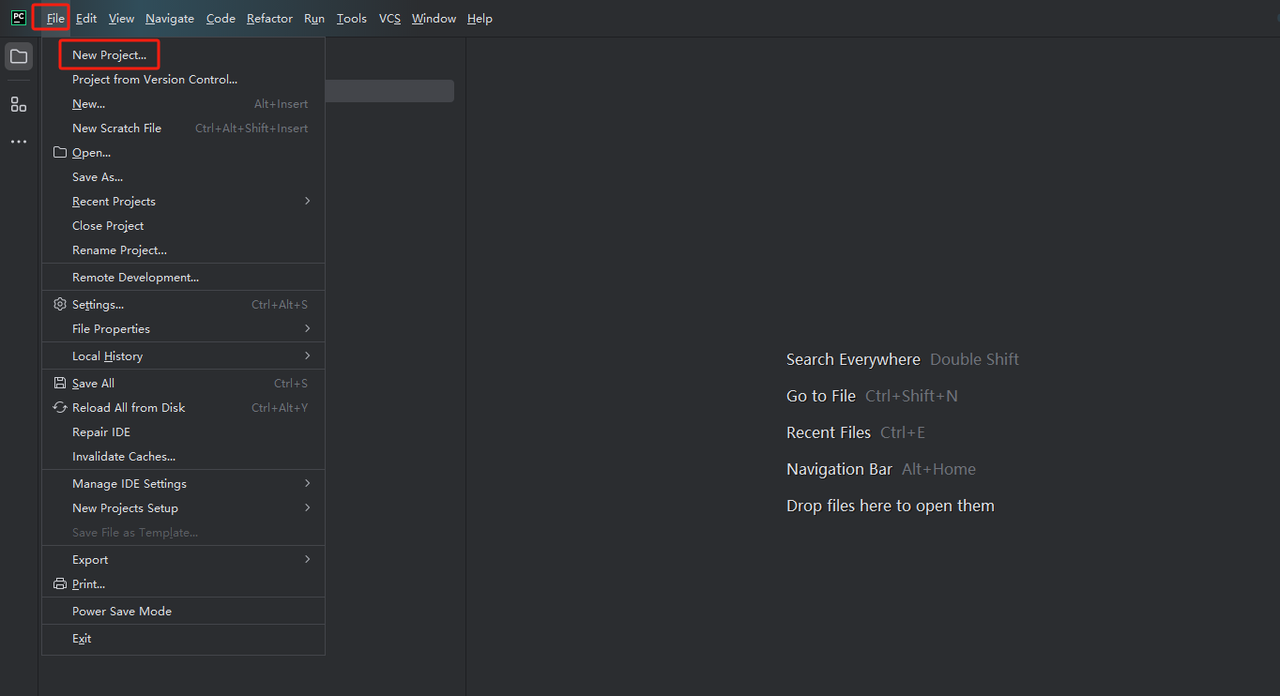
- Em seguida, na janela que aparecer, selecione Pure Python no menu à esquerda e configure seu projeto da seguinte forma:
Observação: Na caixa vermelha abaixo, selecione o caminho de instalação do Python baixado na primeira etapa da configuração do ambiente
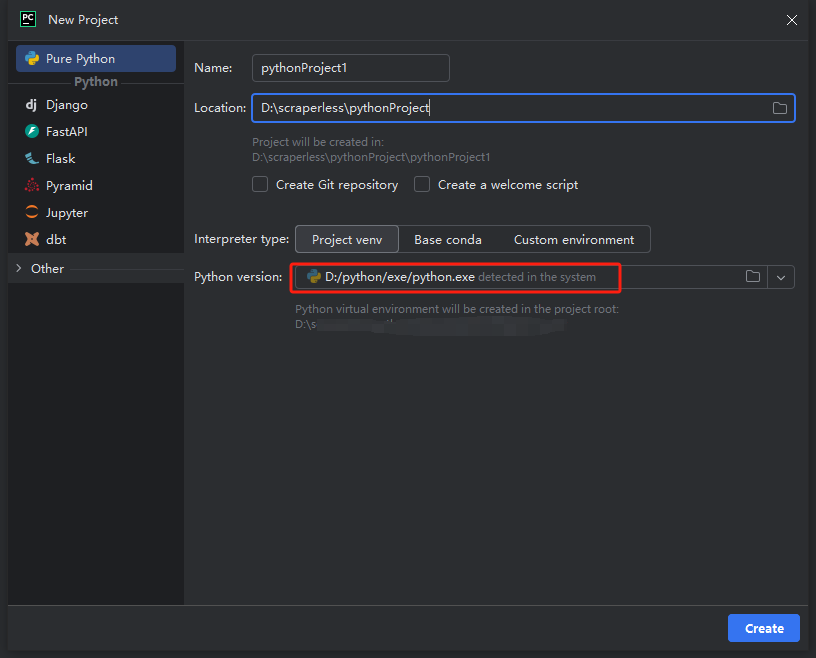
- Você pode criar um projeto chamado python-scraper, marcar a opção "Criar script de boas-vindas main.py na pasta" e clicar no botão "Criar". Depois que o PyCharm configurar o projeto por um tempo, você deverá ver o seguinte:
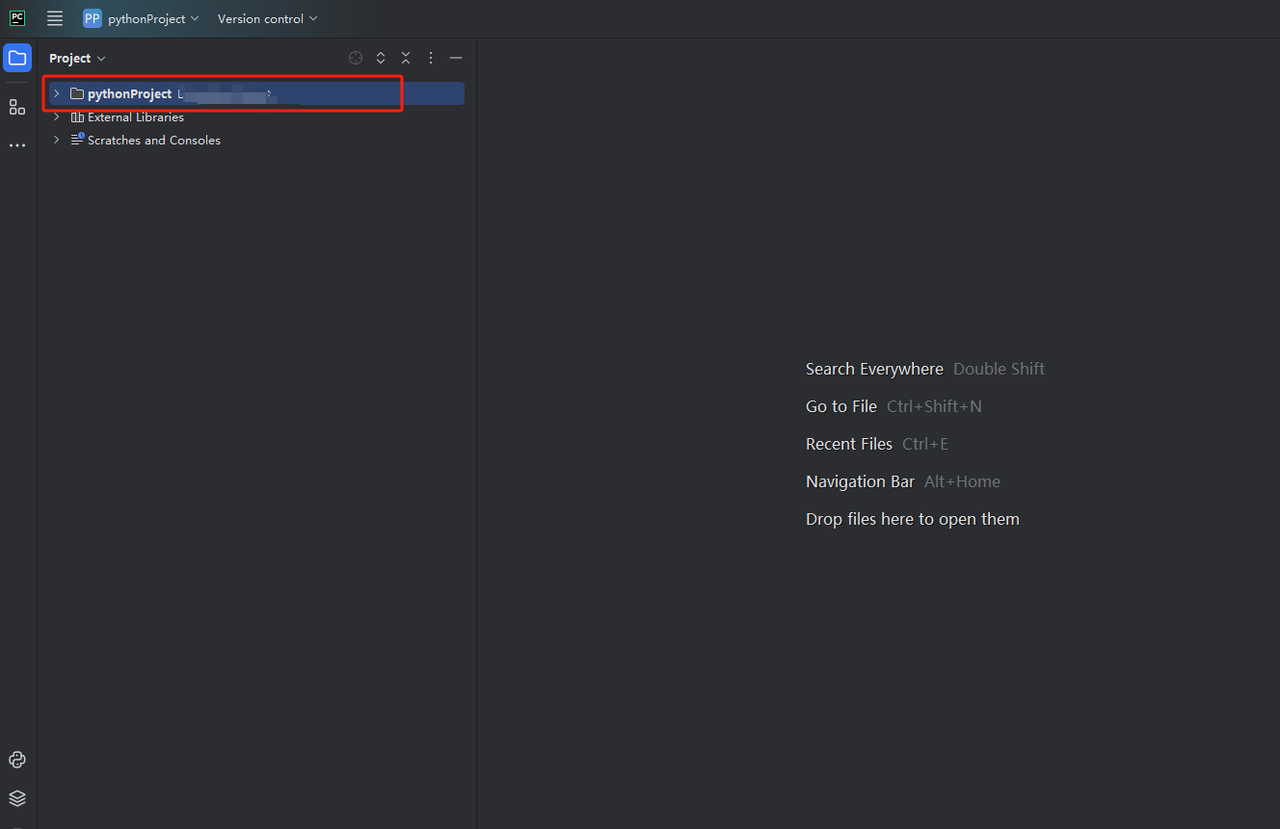
- Em seguida, clique com o botão direito para criar um novo arquivo Python.
- Para verificar se tudo está funcionando corretamente, abra a guia Terminal na parte inferior da tela e digite: python main.py. Após iniciar este comando, você obterá: Olá, PyCharm.
Passo 3: Obtenha a chave da API Scrapeless
Agora você pode copiar diretamente o código Scrapeless para o PyCharm e executá-lo, para que possa obter os dados no formato JSON do Google Job. No entanto, você precisa obter primeiro a chave da API Scrapeless. As etapas são as seguintes:
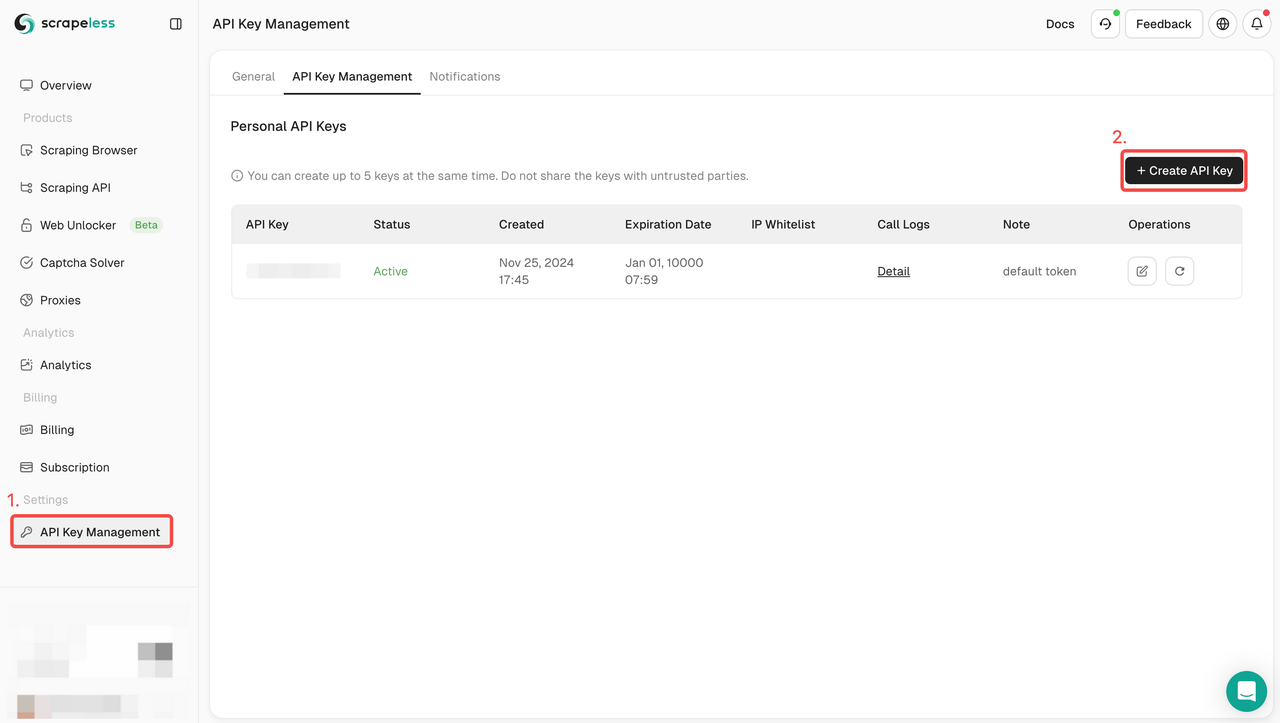
- Se você ainda não tem uma conta, por favor, cadastre-se no Scrapeless. Após o cadastro, faça login no seu painel.
- No seu painel Scrapeless, navegue até Gerenciamento de chave de API e clique em Criar chave de API. Você receberá sua chave de API. Basta colocar o mouse sobre ela e clicar nela para copiá-la. Esta chave será usada para autenticar sua solicitação ao chamar a API Scrapeless.
Passo 4: Entenda os parâmetros da API Scrapeless
A API Scrapeless fornece vários parâmetros que você pode usar para filtrar e refinar os dados que deseja recuperar. Aqui estão os principais parâmetros da API para raspar informações do Google Job:
| Parâmetros | Obrigatório | Descrição |
|---|---|---|
| engine | VERDADEIRO | Defina o parâmetro como google_jobs para usar o mecanismo de API do Google Jobs. |
| q | VERDADEIRO | O parâmetro define a consulta que você deseja pesquisar. |
| uule | FALSO | O parâmetro é o local codificado do Google que você deseja usar para a pesquisa. Os parâmetros uule e location não podem ser usados juntos. |
| google_domain | FALSO | O parâmetro define o domínio do Google a ser usado. O padrão é google.com. Acesse a página de domínios do Google para obter uma lista completa de domínios do Google compatíveis. |
| gl | FALSO | O parâmetro define o país a ser usado para a pesquisa do Google. É um código de país de duas letras (por exemplo, us para Estados Unidos, uk para Reino Unido, fr para França). Acesse a página de países do Google para obter uma lista completa de países do Google compatíveis. |
| hl | FALSO | O parâmetro define o idioma a ser usado para a pesquisa de empregos do Google. É um código de idioma de duas letras (por exemplo, en para inglês, es para espanhol, fr para francês). Acesse a página de idiomas do Google para obter uma lista completa de idiomas do Google compatíveis. |
| next_page_token | FALSO | O parâmetro define o token da próxima página. É usado para recuperar a próxima página de resultados. Até 10 resultados são retornados por página. O token da próxima página pode ser encontrado na resposta JSON do SerpApi: pagination -> next_page_token. |
| lrad | VERDADEIRO | Define o raio de pesquisa em quilômetros. Não limita estritamente o raio. |
| ltype | VERDADEIRO | O parâmetro filtrará os resultados por trabalho em casa. |
| uds | VERDADEIRO | O parâmetro permite filtrar a pesquisa. É uma string fornecida pelo Google como filtro. Os valores uds são fornecidos na seção: filtros com uds, valores q e link fornecidos para cada filtro. |
Passo 5: Como integrar a API Scrapeless à sua ferramenta de raspagem
Depois de obter a chave da API, você pode começar a integrar a API Scrapeless à sua própria ferramenta de raspagem. Aqui está um exemplo de como chamar a API Scrapeless e recuperar dados usando Python e solicitações.
Código de amostra para rastrear informações de emprego do Google usando a API Scrapeless:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_jobs",
"q": "barista new york",
}
payload = Payload("scraper.google.jobs", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Erro:", response.status_code, response.text)
return
print("corpo", response.text)
if __name__ == "__main__":
send_request()Passo 6: Analise os dados resultantes
Os dados resultantes da API Scrapeless conterão informações detalhadas no formato JSON. A seguir, há um exemplo parcial dos dados resultantes. As informações específicas podem ser visualizadas na documentação da API.
{
"filters": [
{
"name": "Salary",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=Barista+new+york+salary&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQIDRAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J",
"q": "Barista new york salary"
}
},
{
"name": "Remote",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista%2Bnew%2Byork+remote&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQICxAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU",
"q": "barista+new+york remote"
}
},
{
"name": "Date posted",
"options": [
{
"name": "Yesterday",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york since yesterday&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAC",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw",
"q": "barista new york since yesterday"
}
},
{
"name": "Last 3 days",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 3 days&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAD",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg",
"q": "barista new york in the last 3 days"
}
},
{
"name": "Last week",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last Campos principais nos resultados:
- title: cargo.
- company: empresa oferecendo o emprego
- link: link para a vaga de emprego
- location: local de trabalho
- date_posted: data em que a vaga foi publicada
Agora você pode usar esses dados para criar um site de empregos, enviar notificações ou integrar dados de empregos ao seu site ou aplicativo existente.
Procurando uma maneira fácil de coletar vagas de emprego?
Comece a usar a API do Google Jobs do Scrapeless hoje mesmo! Obtenha dados de emprego precisos e em tempo real sem esforço e otimize seu processo de busca de emprego. Experimente agora e veja a diferença!
Explore outras fontes de dados populares para recrutamento e análise de mercado de trabalho
Além do Google Jobs, muitas outras plataformas também fornecem dados valiosos de recrutamento e tendências do setor, adequadas para análises mais amplas de dados de recrutamento. Por exemplo, Crunchbase, Indeed e LinkedIn são todas fontes importantes de dados para recrutamento e análise de mercado de talentos.
- O Crunchbase fornece informações detalhadas sobre startups, financiamento corporativo, tendências do setor etc., o que é muito útil para estudar as necessidades de recrutamento da empresa e as tendências do mercado.
- O Indeed é uma das maiores plataformas de recrutamento do mundo, com informações ricas sobre empregos, dados salariais e tendências do setor, adequadas para análise de empregos, previsão salarial e pesquisa de mercado de talentos.
- O LinkedIn fornece redes sociais profissionais globais e dados de recrutamento, que podem ajudar a analisar o fluxo de talentos, os requisitos de habilidades e as tendências de desenvolvimento de empregos.
Se seu negócio não se limita ao rastreamento do Google Jobs, você também pode considerar o uso de ferramentas como o Scrapeless para obter dados de recrutamento dessas plataformas para enriquecer ainda mais sua análise de recrutamento e pesquisa de mercado.
Se você tiver necessidades de rastreamento semelhantes ou quiser aprender como usar as ferramentas Scrapeless para rastrear dados do Crunchbase, Indeed, LinkedIn e outras plataformas, por favor, entre em contato conosco. Forneceremos soluções personalizadas para ajudá-lo a concluir eficientemente o rastreamento e a análise de dados.
Scrapeless Deep SerpApi: Sua poderosa ferramenta de API do Google SERP
O Deep SerpApi é uma API de mecanismo de busca especializada projetada especificamente para modelos de linguagem grandes (LLMs) e agentes de IA. Ele oferece informações em tempo real, precisas e imparciais, permitindo que os aplicativos de IA recuperem e processem dados do Google e além de forma eficiente.
✅ Interface abrangente de cobertura de dados: abrange mais de 20 cenários do Google SERP e mecanismos de busca convencionais.
✅ Custo-benefício: O Deep SerpApi oferece preços a partir de US$ 0,10 por mil consultas, com tempo de resposta de 1 a 2 segundos, permitindo que desenvolvedores e empresas obtenham dados de forma eficiente e com baixo custo.
✅ Capacidades avançadas de integração de dados: pode integrar informações de todos os canais online e mecanismos de busca disponíveis.
✅ Obtenha atualizações em tempo real com dados atualizados nas últimas 24 horas.
Como parte de nossa roadmap futura, estamos totalmente comprometidos em atender às necessidades dos desenvolvedores de IA, simplificando a integração de informações da web dinâmica em soluções baseadas em IA. O objetivo é fornecer uma API tudo-em-um que permita a busca e a extração de dados perfeita com uma única chamada.
🎺🎺Anúncio emocionante!
Programa de suporte para desenvolvedores: Integre o Scrapeless Deep SerpApi às suas ferramentas, aplicativos ou projetos de IA. [Já apoiamos o Dify e em breve apoiaremos o Langchain, Langflow, FlowiseAI e outras estruturas]. Em seguida, compartilhe seus resultados no GitHub ou nas redes sociais e você receberá suporte para desenvolvedores gratuito por 1 a 12 meses, até US$ 500 por mês.
FAQ
P1: Como obter uma chave de API para o Scrapeless?
Cadastre-se em scrapeless.com, faça login no seu painel e gere uma chave de API na seção Gerenciamento de chave de API.
P2: Posso raspar empregos de outros sites?
Sim, o Scrapeless suporta a raspagem de uma variedade de sites de vagas de emprego e muitos outros tipos de dados. A API do Google Jobs é apenas um exemplo.
P3: Posso raspar empregos do Google gratuitamente?
O Scrapeless oferece uma avaliação gratuita limitada. Para continuar, você precisará de um plano pago, que lhe dará acesso a limites mais altos e recursos mais avançados.
P4: O que mais o Scrapeless oferece?
Além do Google Jobs, o Scrapeless pode raspar muitos tipos de dados, incluindo Google Maps, Google Flights, Google Trends e muito mais.
Conclusão
Raspar empregos do Google com a API Scrapeless é uma maneira poderosa e fácil de coletar vagas de emprego para seus próprios projetos. Com apenas algumas linhas de código, você pode integrar o Scrapeless ao seu raspador e automatizar o processo de extração de dados de emprego.
Aproveitando os recursos do Scrapeless, você pode criar rapidamente listas de empregos do mecanismo de busca de empregos do Google, economizando tempo e concentrando-se na criação do seu site de empregos ou aplicativo.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


