
Como extrair dados de cotação de ações do Google Finance em Python
Advanced Data Extraction Specialist
No mundo acelerado das finanças, o acesso a dados atualizados e precisos do mercado de ações é essencial para investidores, traders e analistas. O Google Finance é um recurso inestimável que fornece cotações de ações em tempo real, dados financeiros históricos, notícias e taxas de câmbio. Aprender a extrair esses dados usando Python pode ser muito benéfico para aqueles que procuram agregar dados, realizar análise de sentimento, fazer previsões de mercado ou gerenciar riscos de forma eficaz.
Por que extrair dados do Google Finance?
Extrair dados do Google Finance pode ser benéfico por vários motivos, incluindo:
- Dados de ações em tempo real – Acesse preços de ações atualizados, tendências de mercado e desempenho histórico.
- Análise de mercado automatizada – Colete dados financeiros em larga escala para análise de tendências, gestão de portfólio ou negociação algorítmica.
- Insights da empresa – Reúna resumos financeiros, relatórios de lucros e desempenho de ações para pesquisa de investimentos.
- Pesquisa de concorrentes e do setor – Monitore a saúde financeira dos concorrentes e as tendências do setor para tomar decisões baseadas em dados.
- Análise de notícias e sentimento – Extraia artigos e atualizações de notícias relacionados a ações ou setores específicos para rastreamento de sentimento.
O que será extraído
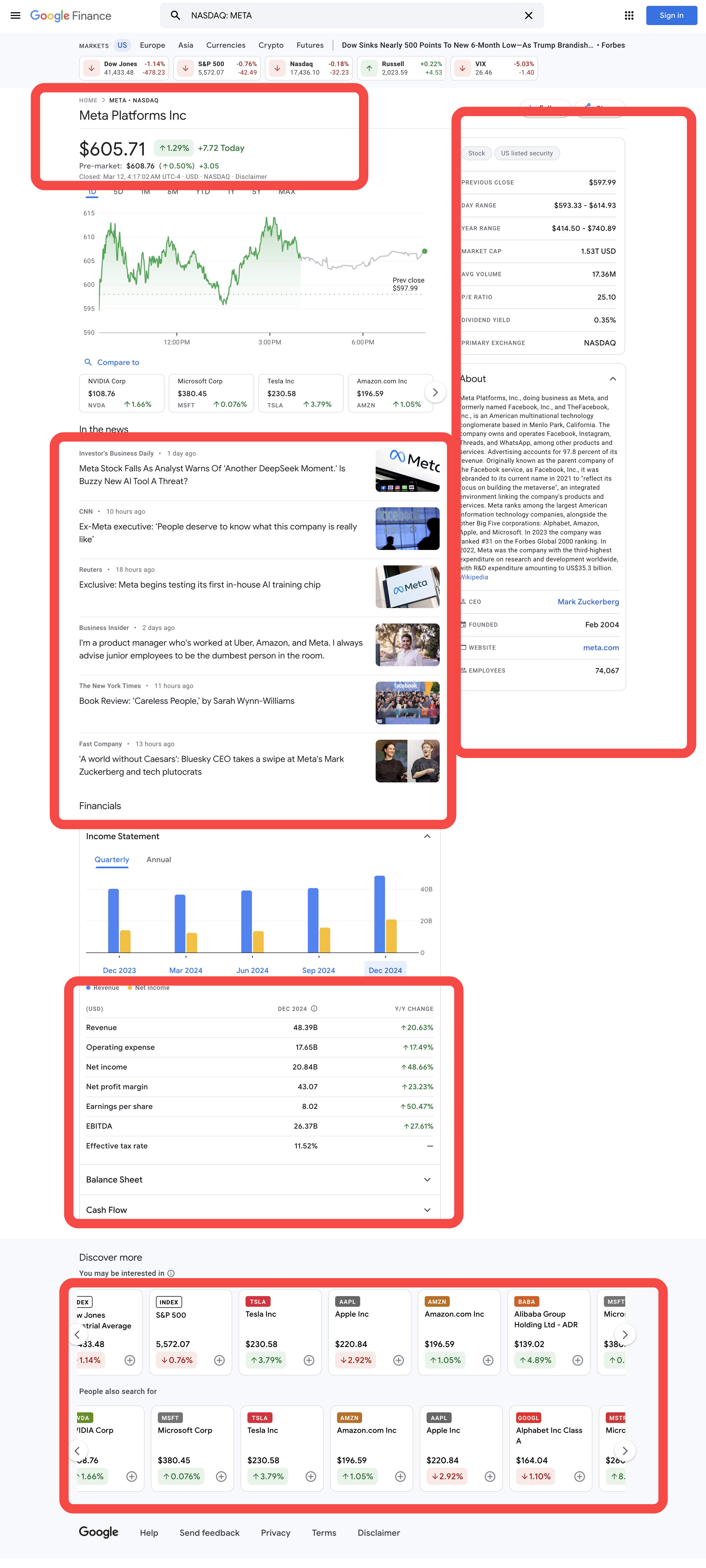
Como extrair dados de cotação de ações do Google Finance em Python
Passo 1. Configurar o ambiente
-
Python: O software é o núcleo da execução do Python. Você pode baixar a versão que precisamos no site oficial, conforme mostrado abaixo. No entanto, não é recomendável baixar a versão mais recente. Você pode baixar 1.2 versões anteriores à versão mais recente.
-
IDE Python: Qualquer IDE que suporte Python funcionará, mas recomendamos o PyCharm. É uma ferramenta de desenvolvimento projetada especificamente para Python. Para a versão do PyCharm, recomendamos a edição gratuita PyCharm Community
Nota: Se você for um usuário do Windows, não se esqueça de marcar a opção "Adicionar python.exe ao PATH" durante o assistente de instalação. Isso permitirá que o Windows use o Python e comandos no terminal. Como o Python 3.4 ou posterior o inclui por padrão, você não precisa instalá-lo manualmente.
Agora você pode verificar se o Python está instalado abrindo o terminal ou prompt de comando e inserindo o seguinte comando:
python --versionPasso 2. Instalar dependências
É recomendável criar um ambiente virtual para gerenciar as dependências do projeto e evitar conflitos com outros projetos Python. Navegue até o diretório do projeto no terminal e execute o seguinte comando para criar um ambiente virtual chamado google_lens:
python -m venv google_financeAtive o ambiente virtual com base em seu sistema:
- Windows:
language
google_finance_env\Scripts\activate- MacOS/Linux:
language
source google_finance_env/bin/activateApós ativar o ambiente virtual, instale as bibliotecas Python necessárias para web scraping. A biblioteca para enviar solicitações em Python é requests, e a biblioteca principal para extrair dados é BeautifulSoup4. Instale-as usando os seguintes comandos:
language
pip install requests
pip install beautifulsoup4
pip install playwrightPasso 3. Extrair dados
Para extrair informações de ações do Google Finance, primeiro precisamos entender como usar a URL do site para extrair a ação desejada. Vamos usar o índice Nasdaq como exemplo, que contém várias ações das quais podemos obter informações. Para acessar o símbolo de cada ação, podemos usar o filtro de ações Nasdaq neste link. Agora, vamos definir META como nossa ação alvo. Com o índice e a ação em mãos, podemos criar o primeiro trecho do script.
Protegemos firmemente a privacidade do site. Todos os dados neste blog são públicos e são usados apenas como demonstração do processo de extração. Não salvamos nenhuma informação e dados.
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"Agora podemos usar a biblioteca Requests para fazer uma solicitação HTTP em TARGET_URL e criar uma instância Beautiful Soup para extrair o conteúdo HTML.
language
fazer uma solicitação HTTP
page = requests.get(TARGET_URL)# use um analisador HTML para obter o conteúdo de "page"
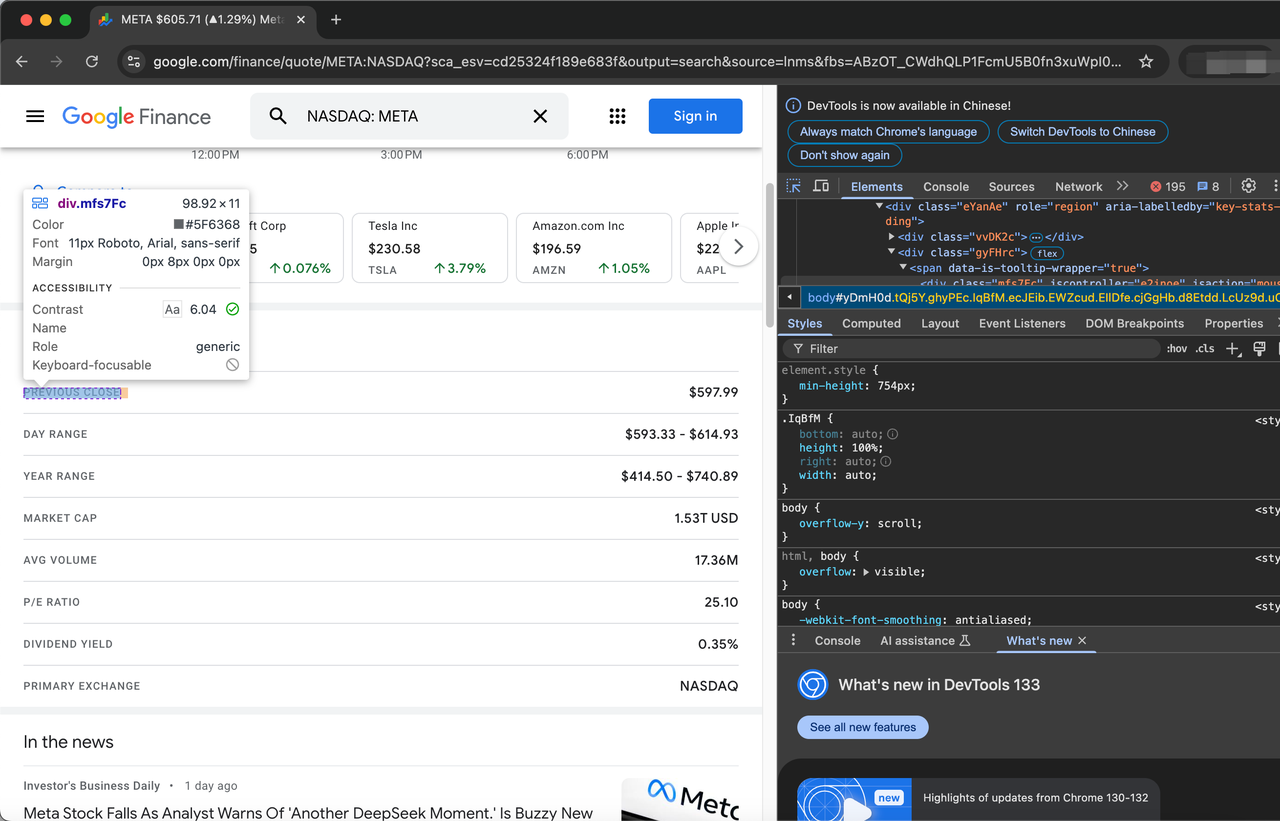
soup = BeautifulSoup(page.content, "html.parser")Antes de começarmos a extração, precisamos primeiro processar o elemento HTML (TARGET_URL) inspecionando a página da web.
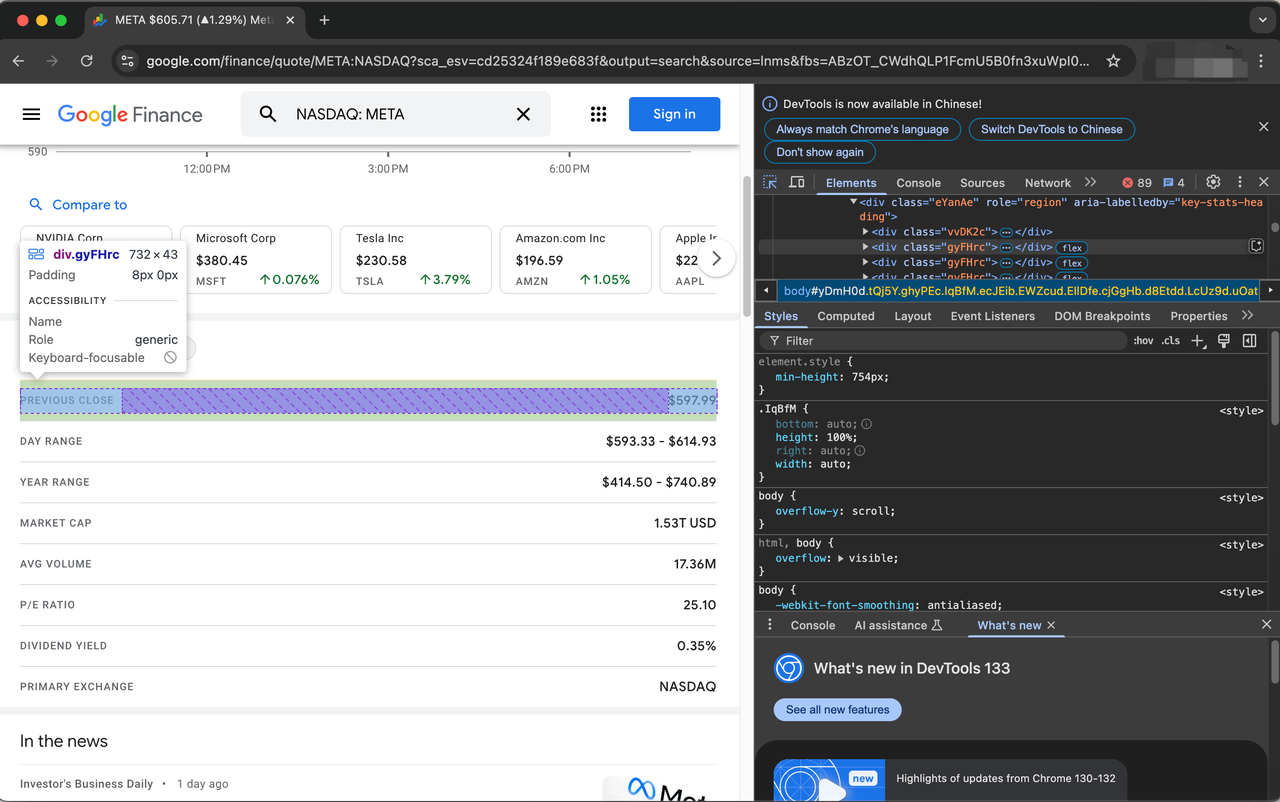
Os itens que descrevem as ações são representados pela classe gyFHrc. Dentro de cada um desses elementos, há uma classe que representa o título do item (por exemplo, "Último Preço de Fechamento") e o valor correspondente (por exemplo, US$ 597,99). O título pode ser obtido da classe mfs7Fc, enquanto o valor vem da classe P6K39c.
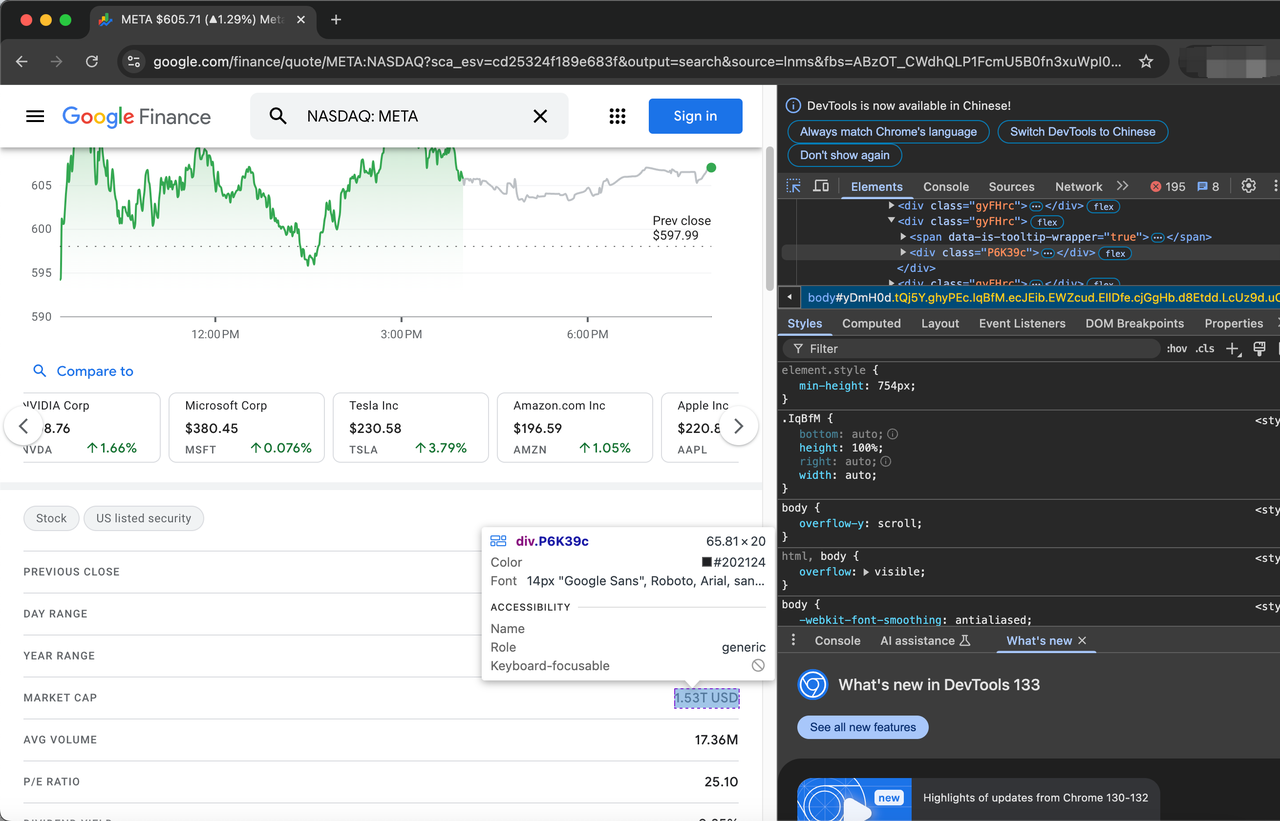
A lista completa de itens a serem extraídos é a seguinte:
- Fechamento anterior
- Faixa diária
- Faixa anual
- Valor de mercado
- Volume médio
- Índice P/L
- Dividend Yield
- Bolsa principal
- CEO
- Fundada
- Site
- Funcionários
Agora vamos ver como buscar esses itens usando código Python.
# obter os itens que descrevem a ação
items = soup.find_all("div", {"class": "gyFHrc"})
# criar um dicionário para armazenar a descrição da ação
stock_description = {}
# iterar sobre os itens e adicioná-los ao dicionário
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)Este é apenas um exemplo de um script simples que pode ser integrado a um bot de negociação, aplicativo ou um painel simples para rastrear suas ações favoritas.
Código completo
Há muitos mais atributos de dados que você pode obter da página, mas, por enquanto, o código completo se parece um pouco com isso.
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"# fazer uma solicitação HTTP
page = requests.get(TARGET_URL)# usar um analisador HTML para obter o conteúdo de "page"
soup = BeautifulSoup(page.content, "html.parser")# obter os itens que descrevem a ação
items = soup.find_all("div", {"class": "gyFHrc"})# criar um dicionário para armazenar a descrição da ação
stock_description = {}# iterar sobre os itens e adicioná-los ao dicionáriofor item in items:
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_valueAqui estão alguns exemplos dos resultados:

Limitações ao extrair dados do Google Finance
Usando o método acima, você pode criar um pequeno scraper, mas se você for fazer scraping em larga escala, este scraper não continuará fornecendo dados. O Google é muito sensível à extração de dados e acabará bloqueando seu IP.
Assim que seu IP for bloqueado, você não poderá extrair nada e seu pipeline de dados acabará sendo interrompido. Então, como superar este problema? Existe uma solução muito simples e é usar a API de extração de dados do Google Finance.
Vamos ver como extrair dados ilimitados do Google Finance usando esta API.
Por que usar a API de extração de dados do Google Finance Scrapeless
Qualidade e precisão dos dados
- Dados de alta precisão: Scrapeless SerpApi sempre fornece dados precisos, confiáveis e atualizados do Google Finance, garantindo que os usuários possam obter as informações de mercado mais autênticas e úteis.
- Atualizações em tempo real: Ser capaz de obter os dados mais recentes do Google Finance em tempo real, incluindo cotações de ações em tempo real, tendências de mercado, etc., é essencial para os usuários que precisam tomar decisões de investimento oportunas.
Suporte multilíngue e localização
- Suporte multilíngue: Suporta vários idiomas, e os usuários podem obter dados financeiros em diferentes idiomas de acordo com suas necessidades para atender às necessidades de usuários em diferentes regiões do mundo.
- Personalização de localização: Você pode obter resultados de pesquisa personalizados com base em locais geográficos, tipos de dispositivos e outros parâmetros especificados, o que é muito útil para analisar as condições de mercado em diferentes regiões ou realizar pesquisas de mercado localizadas.
Vantagens de desempenho e custo
- Velocidade super rápida: Com um tempo médio de resposta de apenas 1-2 segundos, o Scrapeless SerpApi é uma das APIs de extração de dados de busca mais rápidas do mercado, que pode fornecer rapidamente aos usuários os dados necessários.
- Custo-benefício: O Scrapeless SerpApi fornece APIs de pesquisa do Google a apenas US$ 0,1 por mil consultas. Este modelo de preços é muito econômico para projetos de extração de dados em larga escala.
Integração - Fácil integração: O Scrapeless SerpApi suporta integração com várias linguagens de programação populares (como Python, Node.js, Golang, etc.), e os usuários podem integrá-lo facilmente em seus próprios aplicativos ou ferramentas de análise.
Estabilidade e confiabilidade - Alta disponibilidade: O Scrapeless SerpApi possui alta disponibilidade e estabilidade de serviço, o que pode garantir um serviço ininterrupto aos usuários durante a extração de dados de longo prazo e alta frequência.
- Suporte profissional: O Scrapeless SerpApi fornece suporte técnico profissional e atendimento ao cliente para ajudar os usuários a resolver problemas encontrados durante o uso e garantir que os usuários possam obter e usar os dados sem problemas.
Como extrair dados do Google Finance com o Scrapeless
Passo 1: Cadastre-se no Scrapeless e obtenha uma chave de API
- Se você ainda não tem uma conta Scrapeless, visite o site Scrapeless e cadastre-se. Você pode obter 20.000 consultas de pesquisa gratuitas.
- Depois de cadastrado, faça login no seu painel.
- No painel, navegue até Gerenciamento de chaves de API e clique em Criar chave de API. Copie a chave de API gerada, que será sua credencial de autenticação ao chamar a API Scrapeless.
Passo 2: Acesse o Deep SerpApi Playground
- Em seguida, navegue até a seção "Deep SerpApi".
![Navegue até a seção "Deep SerpApi"]](https://assets.scrapeless.com/prod/posts/scrape-google-finance-python/d614e31ce7686a4df82888093b444db5.png)
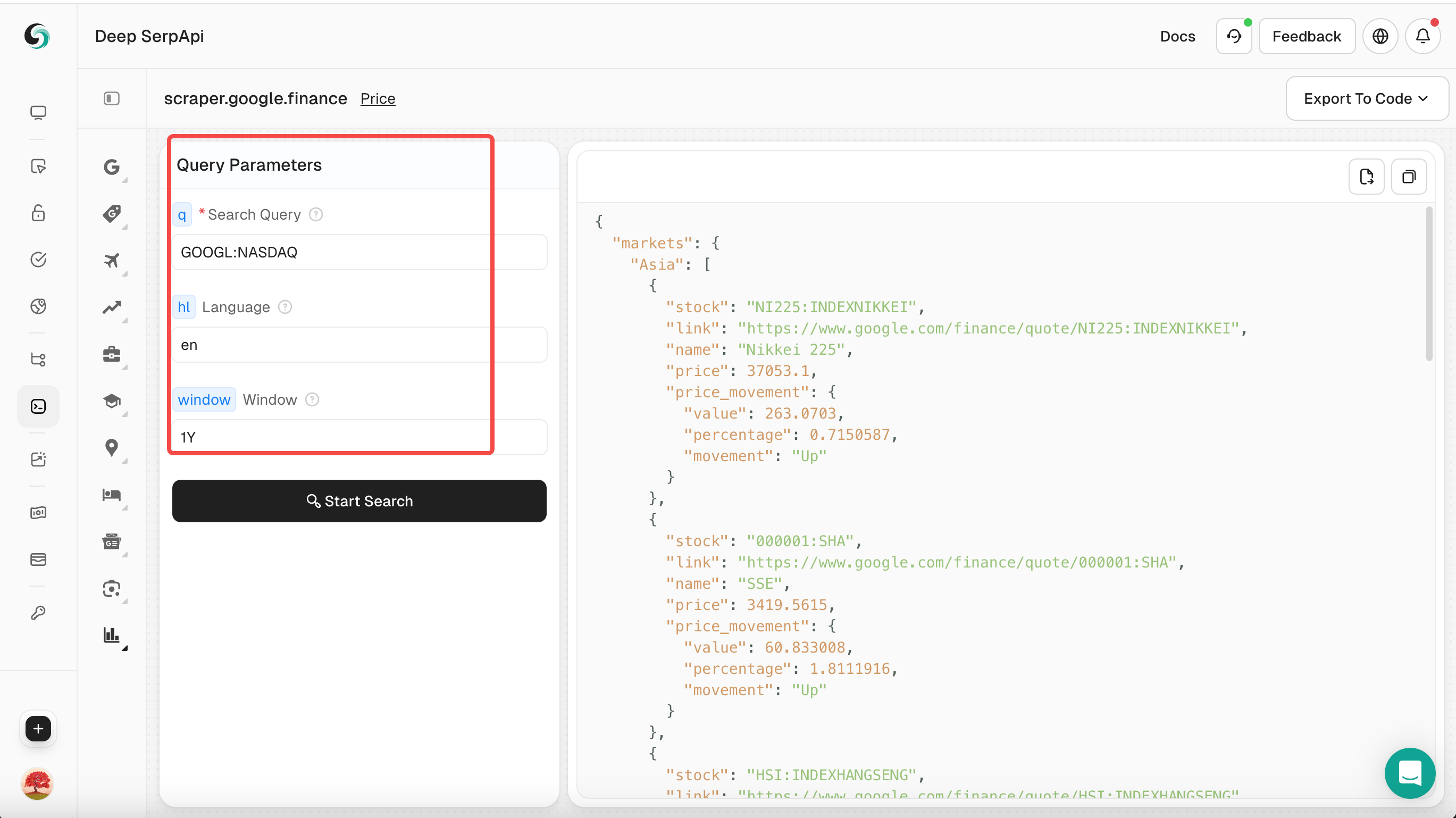
Passo 3: Definir parâmetros de pesquisa
- No Playground, insira sua palavra-chave de pesquisa, como "GOOGL:NASDAQ".
- Defina outros parâmetros, como termo de pesquisa, idioma, tempo etc.
Você também pode clicar para visualizar a documentação oficial da API do Scrapeless para aprender sobre os parâmetros do Google Finance.
Passo 4: Realizar uma pesquisa
- Clique no botão "Iniciar pesquisa" e o Playground enviará uma solicitação para a Deep Serp API e retornará dados JSON estruturados.
Passo 5: Visualizar e exportar dados
- Navegue pelos dados JSON retornados para visualizar informações detalhadas.
- Se necessário, você pode clicar em "Copiar" no canto superior direito para exportar os dados para os formatos CSV ou JSON para análise posterior.
Suporte gratuito para desenvolvedores:
Integre o Scrapeless Deep SerpApi em sua ferramenta de IA, aplicativo ou projeto (já suportamos Dify e daremos suporte a Langchain, Langflow, FlowiseAI e outras estruturas no futuro).
Compartilhe os resultados da sua integração nas redes sociais e você receberá de 1 a 12 meses de suporte gratuito para desenvolvedores, com até 500 mil usos por mês.
Aproveite esta oportunidade para melhorar seu projeto e desfrutar de mais suporte de desenvolvimento! Você também pode entrar em contato com Liam via Discord para obter mais detalhes.
Como integrar a API Scrapeless
Aqui está o código de exemplo para extrair resultados do Google Finance usando a API Scrapeless:
language
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "sua chave de api"
headers = {
"x-api-token": token
}
input_data = {
"q": "GOOG:NASDAQ",
"window": "MAX",
.....
}
payload = Payload("scraper.google.finance", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Erro:", response.status_code, response.text)
return
print("corpo", response.text)
if __name__ == "__main__":
send_request()Ajuste os parâmetros de consulta conforme necessário para obter resultados mais precisos. Para obter mais informações sobre os parâmetros da API, você pode consultar a documentação oficial da API Scrapeless.
Você deve substituir SUA-CHAVE-DE-API pela chave de API que você copiou.
Recursos adicionais
Como extrair dados do Google Notícias com Python
Como contornar o Cloudflare com Puppeteer
Como extrair resultados do Google Lens com Scrapeless
Conclusão
Em conclusão, extrair dados de cotação de ações do Google Finance em Python é uma técnica poderosa para acessar informações financeiras em tempo real. Ao utilizar bibliotecas como requests e BeautifulSoup, ou ferramentas mais avançadas como Selenium, você pode extrair e analisar dados de mercado de forma eficiente para informar suas decisões de investimento. Lembre-se de respeitar os termos de serviço do site e considere usar APIs oficiais quando disponíveis para acesso sustentável a dados.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.



{kind=link}