
Qwen 2.5-Max 'Pensando (QwQ)' Lançado: Intensificando a Competição em LLMs
Senior Web Scraping Engineer
A "Guerra Contínua" dos Modelos de IA
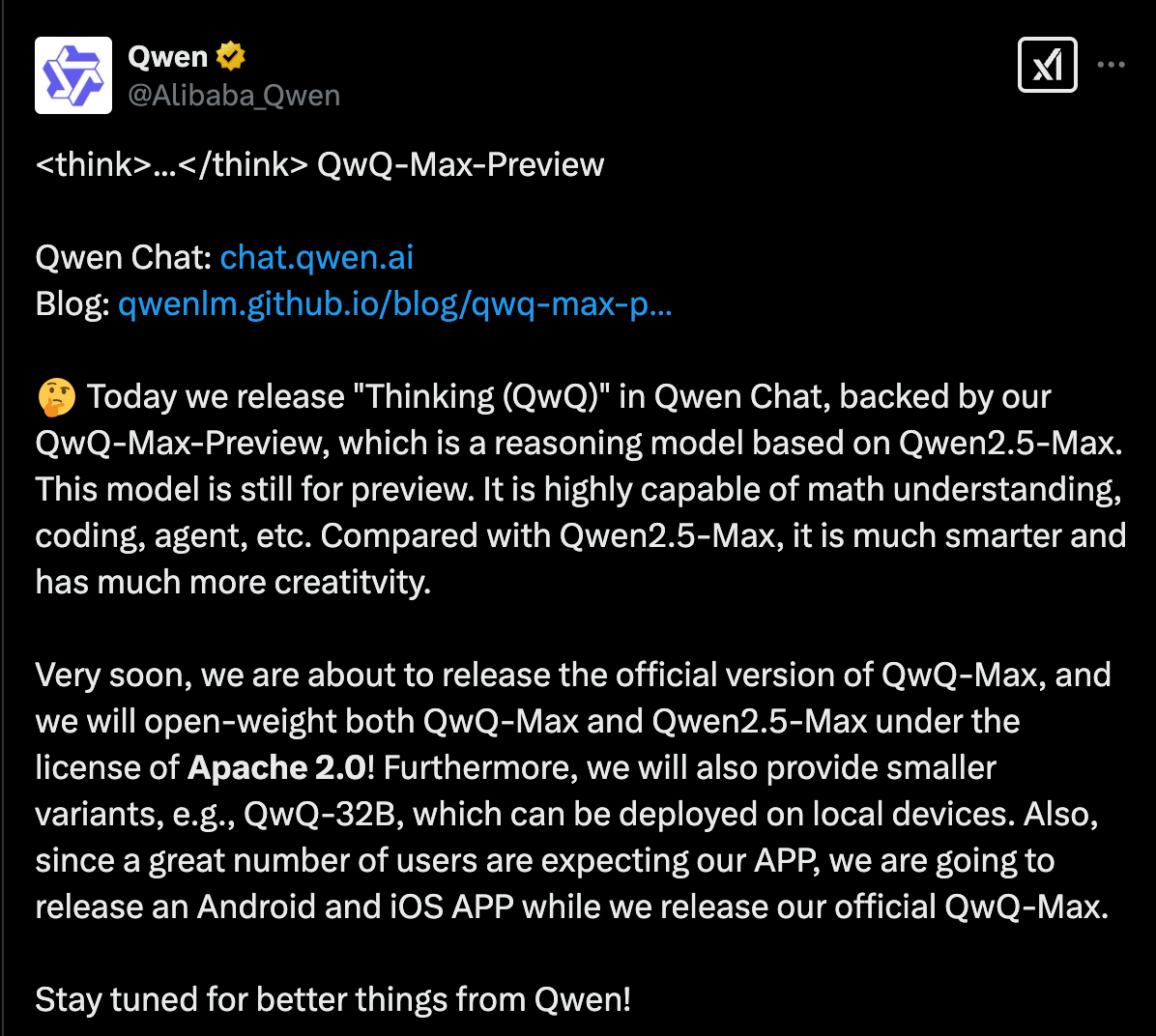
Às 5h01 da manhã de 25 de fevereiro de 2025, a Alibaba anunciou na plataforma X o lançamento do modelo de inferência profunda QwQ-Max-Preview (nomeado "Thinking (QwQ)" no Qwen Chat), baseado no Qwen2.5-Max. Também tornou totalmente open-source o QwQ-Max e o Qwen2.5-Max. Além disso, uma versão leve, QwQ-32B, será lançada em breve para suportar implantação local, e os aplicativos móveis para iOS/Android também estão em fase de planejamento.
Como o Qwen 2.5-Max se comporta?
Em nossos testes, o desempenho deste modelo é competitivo com GPT-4o, DeepSeek-V3, Llama-3.1-405B e Claude 3.5 Sonnet em tarefas como matemática, programação e geração multimodal.
Comparação de desempenho de benchmark
- Arena-Hard (Benchmark de Preferência): O Qwen2.5-Max obteve 89,4, superando o DeepSeek V3 (85,5) e o Claude 3.5 Sonnet (85,2).
- MMLU-Pro (Conhecimento e Raciocínio): O Qwen2.5-Max obteve 76,1, ligeiramente superior ao DeepSeek V3 (75,9), mas ligeiramente inferior ao Claude 3.5 Sonnet (78,0) e ao GPT-4o (77,0).
- GPQA-Diamond (QA de Senso Comum): O Qwen2.5-Max obteve 60,1, superando por pouco o DeepSeek V3 (59,1), enquanto o Claude 3.5 Sonnet liderou com 65,0.
- LiveCodeBench (Capacidade de Codificação): O Qwen2.5-Max obteve 38,7, aproximadamente equivalente ao DeepSeek V3 (37,6), mas atrás do Claude 3.5 Sonnet (38,9).
- LiveBench (Capacidade Geral): O Qwen2.5-Max obteve 62,2, assumindo a liderança sobre o DeepSeek V3 (60,5) e o Claude 3.5 Sonnet (60,3).
No geral, o Qwen2.5-Max mostrou ser um modelo de IA abrangente, com excelente desempenho em tarefas baseadas em preferência e capacidades gerais de IA, mantendo habilidades de conhecimento e codificação competitivas.
Além disso, o Qwen2.5-Max suporta a geração de trechos de código, análise de arquivos e compreensão de imagens através da função Artifacts. Uma única chamada pode lidar com conteúdo de vídeo com mais de 1 hora.
Verdade dos Dados
- A Lacuna entre a Iteração do Modelo e a Atualização de Dados: Ferramentas tradicionais têm um ciclo de atualização de dados de vários dias, enquanto o Qwen2.5-Max alcança atualização de conhecimento dinâmica com 20 trilhões de tokens de dados de pré-treinamento.
- O Risco da Lacuna de Geração Tecnológica: A Gartner prevê que, até 2025, o desempenho do modelo de IA melhorará 15% a cada três meses, e a infraestrutura de dados atrasada levará a uma fratura de competitividade.
Comparação de dados em tempo real de modelos populares
1. Comparação da Velocidade de Processamento de Texto Longo
| Modelo | Velocidade de Processamento (segundos/mil palavras) |
|---|---|
| Qwen 2.5-Max | 0,5 |
| GPT-4 | 0,6 |
| DeepSeek-V3 | 0,575 |
| Llama-3.1-405B | 0,600 |
2. Comparação do Tamanho do Conjunto de Dados de Treinamento
| Modelo | Tamanho do Conjunto de Dados de Treinamento (trilhões de palavras) |
|---|---|
| Qwen 2.5-Max | 2 |
| GPT-4 | 1,5 |
| DeepSeek-V3 | 1,8 |
| Llama-3.1-405B | 1,7 |
3. Comparação do Tempo Médio de Resposta
| Modelo | Tempo Médio de Resposta (segundos) |
|---|---|
| Qwen 2.5-Max | 0,3 |
| GPT-4 | 0,5 |
| DeepSeek-V3 | 0,4 |
| Llama-3.1-405B | 0,45 |
4. Comparação da Frequência de Atualização
| Modelo | Frequência de Atualização |
|---|---|
| Qwen 2.5-Max | Uma vez por mês |
| GPT-4 | Uma vez por trimestre |
| DeepSeek-V3 | A cada dois meses |
| Llama-3.1-405B | A cada três meses |
Que aspectos afetam diretamente o desenvolvimento de modelos de dados?
Na competição de IA, a qualidade da infraestrutura de dados determina diretamente o limite superior do modelo. Ferramentas de extração de dados em tempo real influenciam o desenvolvimento de ferramentas de IA por meio de três capacidades principais:
A amplitude da cobertura de dados
Embora o Qwen2.5-Max suporte 29 idiomas, sua versão open-source ainda depende de corpora públicas, resultando em cobertura de dados limitada. Portanto, é necessária uma ferramenta de extração de informações que integre inúmeras interfaces de dados e fontes de dados para garantir a abrangência e a precisão dos dados do modelo.
A velocidade da atualização de informações
O desempenho do modelo de IA se itera a cada três meses, mas os crawlers tradicionais são limitados por mecanismos anti-raspagem (como captchas e carregamento dinâmico), com um ciclo de atualização de dados de vários dias. Claramente, as capacidades de aquisição e iteração de dados das ferramentas de extração de informações precisam ser continuamente atualizadas para garantir a atualidade dos dados.
Suporte multimodal
A demanda por dados multimodais por modelos de IA está crescendo, mas os crawlers tradicionais têm uma taxa de erro de 40% na análise de tabelas PDF e levam mais de 10 minutos para extrair legendas de vídeo. Modelos de IA poderosos devem integrar tecnologia de extração de dados estruturados, analisar automaticamente tabelas PDF, legendas de vídeo e metadados de imagem e garantir a precisão.
Scrapeless Deep SerpApi: Uma Ferramenta Favorável para o Desenvolvimento de LLMs
Se o Qwen 2.5-Max inaugura o desenvolvimento contínuo da IA, então o Scrapeless Deep SerpApi é a arma-chave que impulsiona essa mudança.
Deep SerpApi é um mecanismo de busca dedicado a modelos de linguagem grandes (LLMs) e agentes de IA. Ele fornece informações em tempo real, precisas e imparciais, permitindo que aplicativos de IA recuperem e processem dados de forma eficaz:
✅ Possui mais de 20 interfaces de cenário da API de pesquisa do Google integradas e está conectado aos dados dos principais mecanismos de busca.
✅ Abrange mais de 20 tipos de dados, como resultados de busca, notícias, vídeos e imagens.
✅ Suporta atualizações de dados históricos nas últimas 24 horas.
No planejamento futuro do produto, consideraremos totalmente as necessidades dos desenvolvedores de IA. Simplificaremos o processo de integração de informações da web dinâmica em soluções impulsionadas por IA e, finalmente, realizaremos uma API ALL-in-One que permite a pesquisa e extração de dados da web com um único clique. Além disso, manteremos o menor preço neste campo por muito tempo: US$ 0,1-US$ 0,3/1K consultas.
O Evento Mais Crucial! 🔔 O Programa de Suporte ao Desenvolvedor foi lançado:
Você pode integrar o Scrapeless em suas ferramentas de IA, aplicativos ou qualquer projeto em que esteja trabalhando. Suportamos frameworks como Dify (Langchain, Langflow, FlowiseAI, e muitos outros estão chegando em breve!). Você também pode integrar o Scrapeless de outras maneiras que se adequam ao seu projeto.
Assim que sua integração estiver concluída, compartilhe seu trabalho conosco através do GitHub ou mídia social e forneça comprovante de integração. Em troca, forneceremos 500 mil consultas gratuitas por 1 mês para ajudá-lo a maximizar os benefícios de nossos produtos.
Junte-se à nossa comunidade e obtenha detalhes de nossa administradora: Emily Fann!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


