
Como contornar o Cloudflare com Puppeteer
Advanced Data Extraction Specialist
No campo da coleta de dados e web scraping, desenvolvedores frequentemente enfrentam um problema espinhoso: como contornar efetivamente o mecanismo de proteção do Cloudflare. Como um serviço amplamente utilizado de segurança e otimização de desempenho de sites em todo o mundo, as funções anti-crawler e firewall do Cloudflare trazem desafios consideráveis à raspagem de dados. Este problema é particularmente evidente ao usar o Puppeteer para web scraping. Este artigo explorará a fundo como usar o Scrapeless Scraping Browser, combinado com o Puppeteer, para facilmente superar as limitações do Cloudflare e iniciar uma jornada de coleta de dados eficiente e estável.
Como o Cloudflare detecta bots
O Cloudflare detecta bots usando uma combinação de técnicas, incluindo:
- Análise de Comportamento – Monitora movimentos do mouse, pressionamento de teclas, comportamento de rolagem e padrões de interação para distinguir usuários humanos de bots.
- Reputação de IP – Usa um banco de dados global de inteligência de ameaças para identificar endereços IP suspeitos com base em atividades passadas.
- Testes de Desafio-Resposta – Implanta CAPTCHAs ou desafios JavaScript para verificar se um visitante é humano.
- Fingerprinting – Analisa as características do navegador, cabeçalhos HTTP e atributos do dispositivo para detectar automação.
- Limitação de Taxa – Sinaliza padrões de solicitação incomuns, como comportamentos de navegação de alta frequência ou não humanos.
- Aprendizado de Máquina – Usa modelos de IA treinados em vastas quantidades de dados de tráfego para identificar comportamentos semelhantes a bots.
- TLS Fingerprinting – Examina como as conexões TLS são estabelecidas para diferenciar entre navegadores reais e scripts automatizados.
- Monitoramento de Execução de JavaScript – Verifica se o JavaScript é executado corretamente para detectar navegadores headless e bots que desabilitam scripts.
Por que o Puppeteer sozinho não consegue contornar o Cloudflare
Aqui está a tradução com a palavra-chave principal "contornar Cloudflare" inserida:
1. Mecanismos de Detecção Complexos do Cloudflare
O Cloudflare usa vários métodos para detectar e distinguir entre usuários humanos e ferramentas automatizadas como o Puppeteer, incluindo análise de comportamento, verificações de reputação de IP e fingerprinting HTTP. Esses mecanismos dificultam que o Puppeteer sozinho contorne o Cloudflare.
2. O Comportamento Padrão do Puppeteer é Facilmente Identificado
Por padrão, o Puppeteer exibe comportamentos que diferem dos usuários humanos, como:
- Strings de agente de usuário fixas que não correspondem aos navegadores típicos.
- Falta de interações humanas, como movimentos do mouse não naturais ou padrões de clique.
- Cabeçalhos de solicitação distintos que o revelam como uma ferramenta automatizada.
3. Mecanismos de Desafio do Cloudflare
Quando o Cloudflare detecta tráfego suspeito, ele aciona desafios como CAPTCHAs ou etapas de verificação. O Puppeteer sozinho não consegue resolver esses desafios, tornando impossível contornar o Cloudflare sem ferramentas adicionais.
4. Necessidade de Configuração e Ferramentas Extras
Para contornar o Cloudflare, o Puppeteer requer configurações adicionais, como:
- Simular comportamento humano com atrasos aleatórios e interações realistas.
- Usar IPs proxy para evitar proibições de IP.
- Modificar cabeçalhos de solicitação para imitar navegadores reais.
- Integrar serviços de resolução de CAPTCHA como o 2Captcha.
5. Regras de Detecção Continuamente Atualizadas
O Cloudflare atualiza regularmente seus algoritmos de detecção, tornando os métodos antigos de contorno ineficazes com o tempo.
Em resumo, o Puppeteer sozinho luta para contornar a detecção do Cloudflare. Ele precisa ser combinado com outras técnicas e ferramentas para simular o comportamento humano e lidar com os desafios do Cloudflare de forma eficaz.
Método #1: Contornar o Cloudflare usando puppeteer-extra-plugin-stealth
O puppeteer-extra-plugin-stealth é uma correção que ajuda a contornar o Cloudflare mascarando as propriedades do navegador automatizado do Puppeteer, fazendo-o parecer um navegador real.
Por exemplo, o plugin Stealth substitui a propriedade WebDriver e substitui a flag HeadlessChrome por Chrome para mascarar sinais de automação. Ele também simula outras propriedades legítimas do navegador, como chrome.runtime, o que o faz parecer headful mesmo no modo headless.
O plugin Puppeteer Stealth usa uma API semelhante à do Puppeteer base, portanto, não há curva de aprendizado para desenvolvedores que já usam o Puppeteer.
Vamos contornar o CoinTracker, um site com proteção Cloudflare simples, para ver como o Puppeteer Stealth funciona.
Primeiro, instale o plugin:
npm install puppeteer-extra puppeteer-extra-plugin-stealthAgora, importe as bibliotecas necessárias e adicione o plugin Stealth. Em seguida, solicite o site protegido e tire uma captura de tela de sua página inicial:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'load',
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();O plugin Puppeteer Stealth contorna o Cloudflare e tira uma captura de tela da página inicial do site, conforme mostrado:
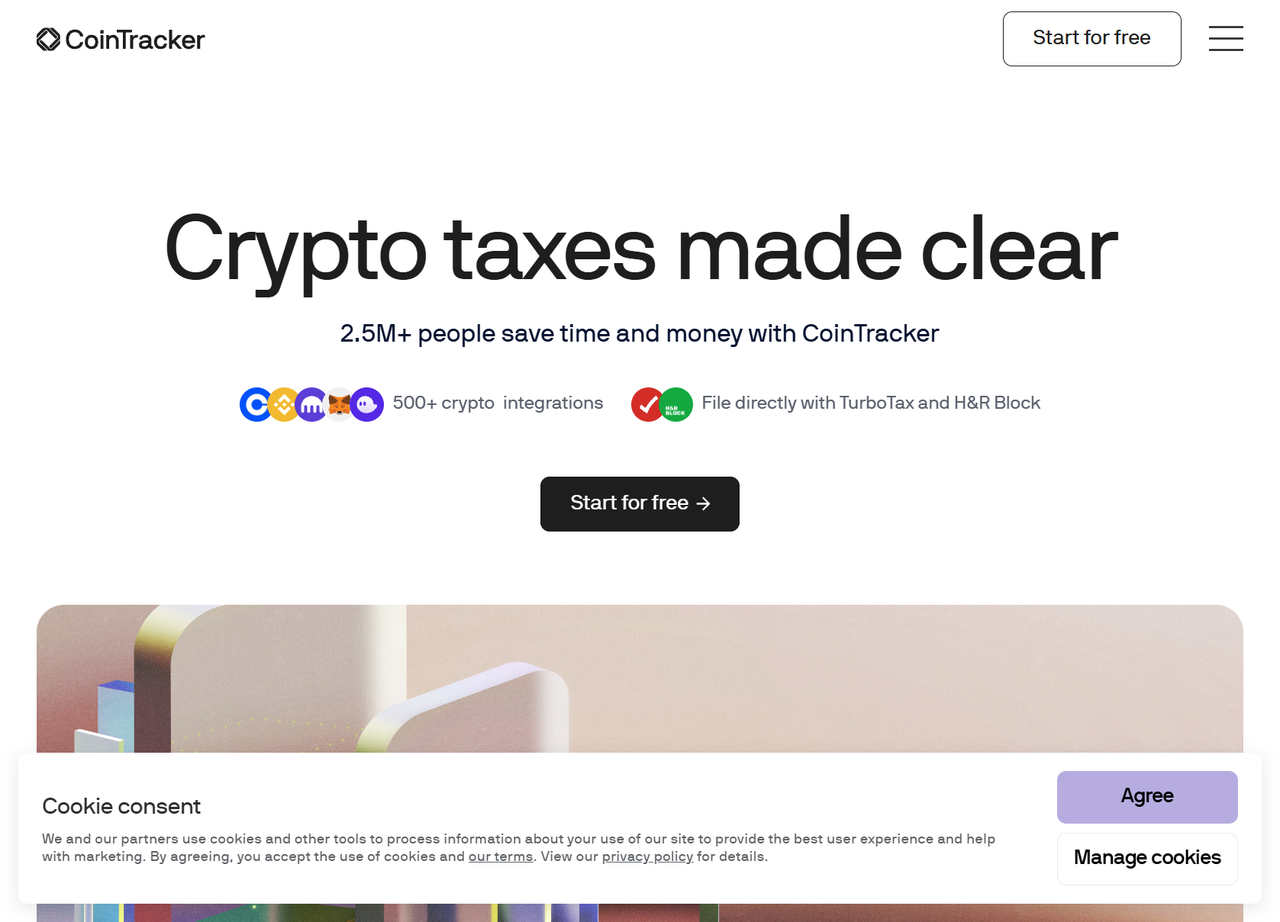
Você contornou com sucesso a detecção do Cloudflare.
Claro, o site de destino atual é fácil de acessar porque não aplica nenhuma técnica de detecção sofisticada.
O plugin Puppeteer Stealth pode lidar com medidas de segurança mais avançadas? A resposta é...
O plugin Stealth é bloqueado, como mostrado na figura.
Limitações do plugin Puppeteer Stealth
Alguns sites usam verificações de segurança do Cloudflare mais avançadas do que outros. Nesses casos, mascarar as propriedades de automação do Puppeteer usando a técnica de evasão do Cloudflare puppeteer-extra-plugin-stealth é insuficiente para passar.
Por exemplo, o Puppeteer Stealth foi bloqueado ao tentar acessar a página de desafio do Cloudflare.
Experimente você mesmo substituindo o URL de destino anterior pelo URL da página de desafio:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();O plugin Stealth foi bloqueado, conforme mostrado:
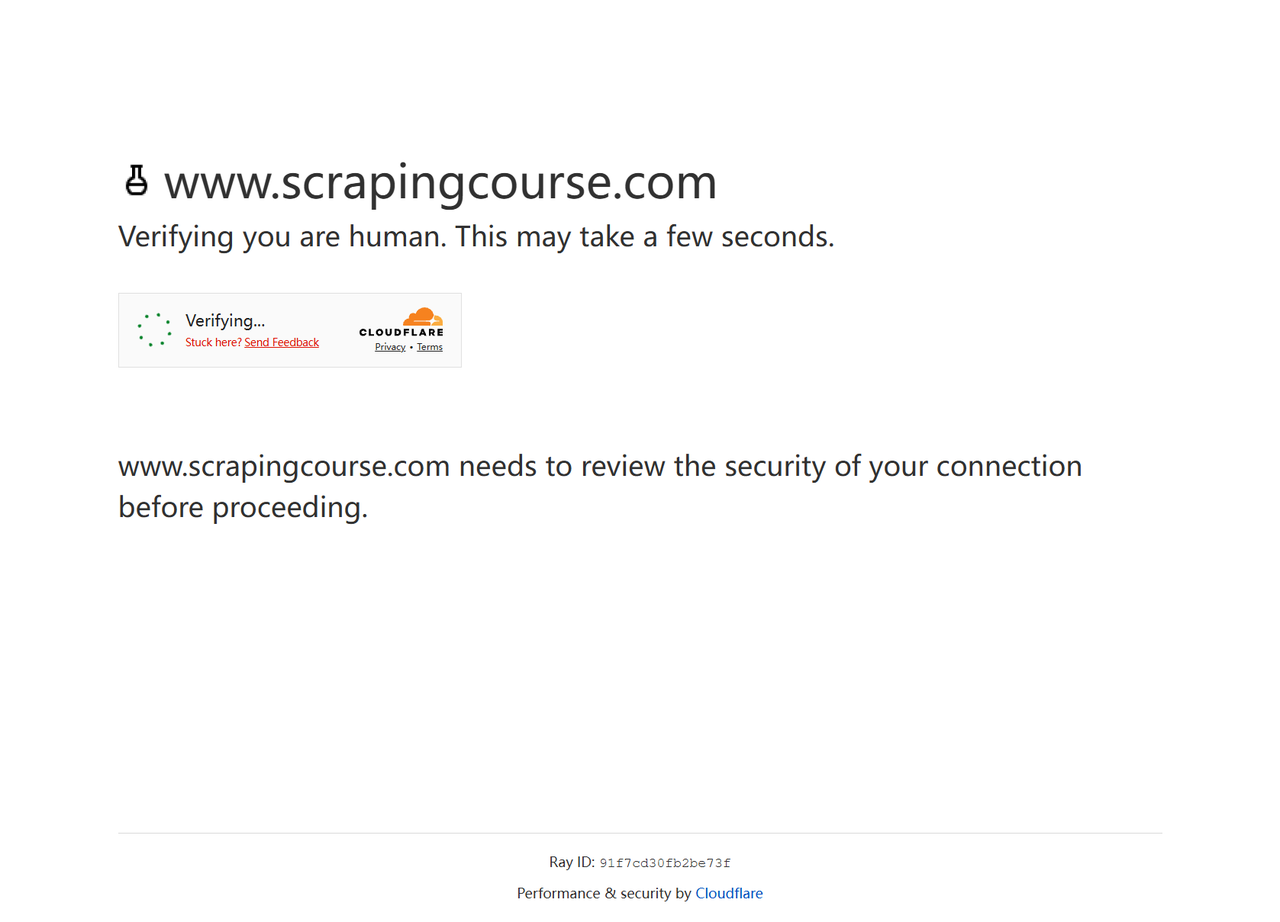
Os resultados indicam que um sistema anti-bot do Cloudflare mais avançado detectou o plugin Stealth como um bot. O plugin Stealth ainda possui alguns traços detectáveis, como renderização inconsistente de WebGL ou Canvas, denunciando-o como um bot.
Como você pode resolver essas limitações e extrair dados de sites complicados? A resposta é Scrapeless.
Método 2: Contornar o Cloudflare usando Scrapeless e Puppeteer
A maneira mais fácil de evitar as limitações do Puppeteer e seu plugin Stealth é integrar a biblioteca com o Scrapeless Scraping Browser. Com o Scrapeless Scraping Browser, seu scraper Puppeteer é fortalecido com evasões avançadas para parecer um humano e contornar a detecção anti-bot.
Tudo o que você precisa fazer é adicionar uma única linha de código ao seu script Puppeteer existente, e o Scraping Browser o ajudará a lidar com o fingerprinting principal do navegador, adicionar plugins e extensões ausentes, gerenciar a rotação de proxy residencial e muito mais.
O Scraping Browser também é executado na nuvem, evitando a sobrecarga de memória da execução de instâncias de navegador locais. Esse recurso o torna altamente escalonável.
Recursos-chave do Scrpeless Scraping Browser
Scrpeless Scraping Browser é uma ferramenta projetada para extração de dados da web eficiente e em larga escala:
- Simule comportamentos de interação humana reais para contornar mecanismos anti-crawler avançados, como detecção de fingerprinting de navegador e fingerprinting TLS.
- Suporte à solução automática de vários tipos de códigos de verificação, incluindo cf_challenge, para garantir um processo de rastreamento ininterrupto.
- Integração perfeita de ferramentas populares como Puppeteer e Playwright para simplificar o processo de desenvolvimento e suportar o lançamento de tarefas automatizadas com uma única linha de código.
Como integrar o Scraping Browser com o Puppeteer
O Scrapeless requer puppeteer-core, uma versão do Puppeteer que não baixa o binário do Chrome. Portanto, certifique-se de instalá-lo:
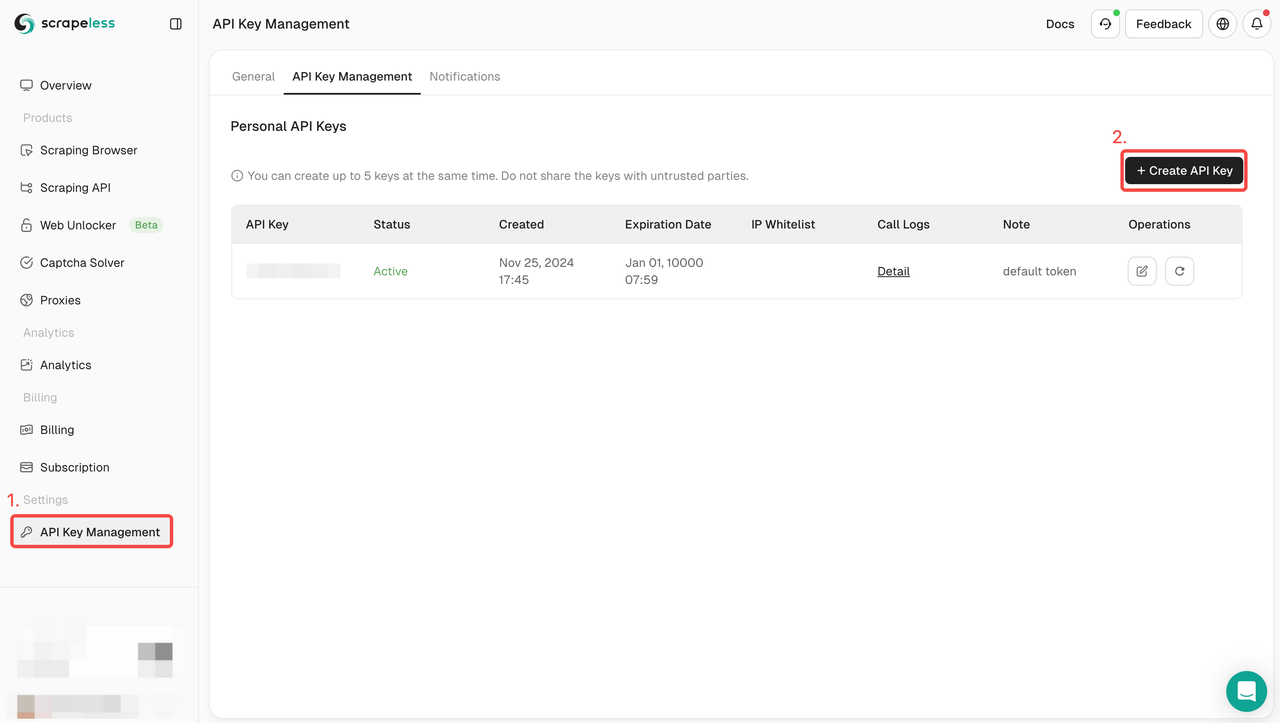
npm install puppeteer-coreEtapa 1. Cadastre-se no Scrapeless, clique em Gerenciamento de Chave API > Criar Chave API para criar sua Chave API Scrapeless.
Cadastre-se no Scrapeless e obtenha uma versão de teste gratuita. Se você tiver alguma dúvida, também pode entrar em contato com Liam via Discord
Etapa 2. Em seguida, vá para o Scraping Browser e copie seu URL do navegador.
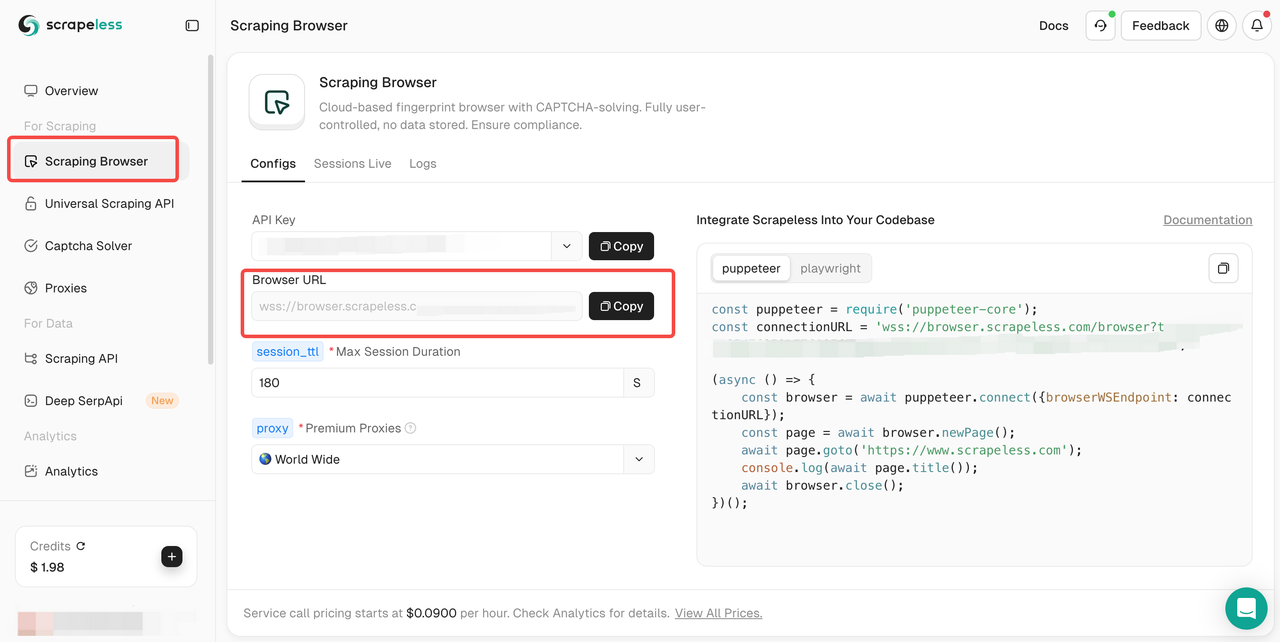
Integre o URL do navegador copiado ao seu script Puppeteer da seguinte maneira:
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// set up browser environment
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// create a new page
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
//take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();Você precisa substituir https://www.scrapingcourse.com/cloudflare-challenge por qualquer site com cloudflare-challenge;
Também substitua sua Chave API Scrapeless na parte do token.
O código acima acessa e tira uma captura de tela da página protegida. Veja o resultado abaixo:
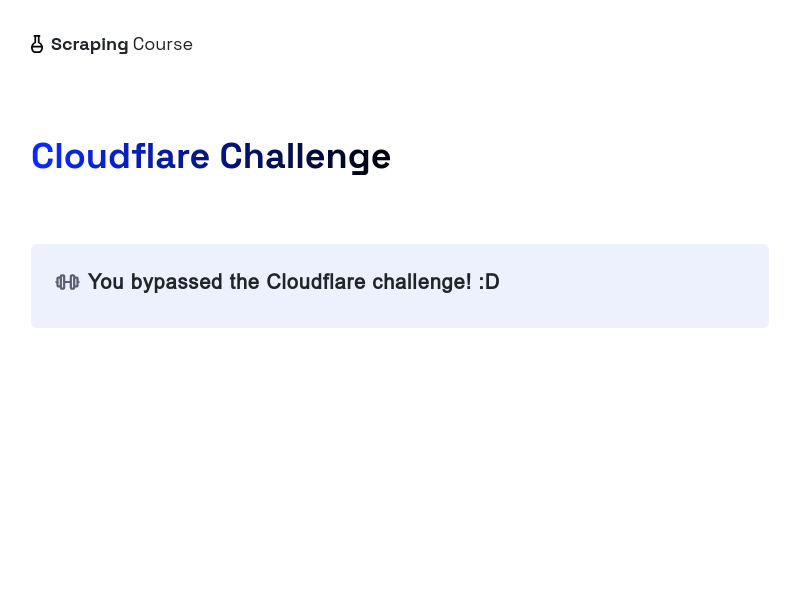
Parabéns 🎉! Você contornou com sucesso o Cloudflare usando Puppeteer e Scrapeless.
Benefícios da Integração do Scrapeless Scraping Browser no Puppeteer para Contornar o Cloudflare
Integrar o Scrapeless Scraping Browser no Puppeteer para contornar o Cloudflare tem os seguintes benefícios:
- Aumentar a Anti-Detecção
O Puppeteer sozinho possui recursos de automação claros (por exemplo, atributo navigator.webdriver, flag de agente de usuário HeadlessChrome), facilitando a identificação do Cloudflare como um bot. O Scrapeless Scraping Browser pode imitar impressões digitais de navegadores reais (tipo, agente de usuário, resolução de tela, etc.), ocultando efetivamente os recursos de automação do Puppeteer, reduzindo o risco de detecção do Cloudflare e aumentando as taxas de sucesso de rastreamento.
- Simplificar a Configuração e Integração
O Scrapeless Scraping Browser oferece APIs e métodos de integração fáceis de usar. Os desenvolvedores podem adicionar uma pequena quantidade de código aos scripts Puppeteer existentes para aproveitar seus poderosos recursos anti-detecção, sem precisar entender os detalhes internos do Puppeteer ou os mecanismos anti-rastreamento do Cloudflare. Isso reduz as barreiras e a carga de trabalho de desenvolvimento.
- Melhorar a Manutenção do Código
Usar o Scrapeless Scraping Browser reduz a dependência das configurações subjacentes do Puppeteer e scripts personalizados. Isso torna o código mais limpo e claro, facilitando a manutenção e as atualizações futuras.
Recursos Adicionais
Como Contornar o Desafio do Cloudflare Guia Completo
O que é Fingerprinting TCP/IP?
Como Raspar Notícias do Google com Python
Documentação oficial da API Scrapeless
Conclusão
Em resumo, contornar o Cloudflare com o Puppeteer requer ferramentas e métodos eficazes. O Scrapeless Scraping Browser oferece uma solução simples, porém poderosa, aprimorando a anti-detecção, simplificando a integração e melhorando a manutenção. Sempre garanta o cumprimento legal ao raspar.
Melhore a eficiência do seu negócio e escolha as soluções personalizadas de nível empresarial do Scrapeless Scraping Browser. Oferecemos serviços de coleta de dados profissionais e eficientes.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


