
Raspador Web Amazon com Node.JS - Tutorial JavaScript 2025
Expert Network Defense Engineer
Amazon é uma plataforma líder global de e-commerce com dados valiosos de produtos para pesquisa de mercado e monitoramento de preços. Usando JavaScript e Node.js com Playwright, podemos construir um web scraper em JavaScript para extrair esses dados, mas desafios como renderização de JavaScript, detecção anti-bot e CAPTCHAs tornam a raspagem manual difícil.
A API de Raspagem Amazon da Scrapeless oferece uma solução mais rápida e confiável ao lidar com CAPTCHAs, proxies e desbloqueio de sites, garantindo dados precisos em tempo real sem detecção. Este tutorial abordará ambas as abordagens, mostrando por que a Scrapeless é a melhor escolha para raspagem eficiente de dados da Amazon. 🚀
Desafios na Raspagem da Amazon
Raspar dados da Amazon apresenta vários desafios devido às suas fortes proteções anti-bot:
- Renderização de JavaScript: A Amazon depende fortemente de JavaScript, tornando difícil extrair dados com solicitações HTTP simples. Um scraper JavaScript usando Playwright ou ferramentas semelhantes é necessário para renderizar conteúdo dinâmico.
- Proteção CAPTCHA: Desafios frequentes de CAPTCHA interrompem a raspagem e exigem mecanismos de resolução para continuar a extração de dados.
- Bloqueio de IP e Limites de Taxa: A Amazon detecta e bloqueia solicitações repetidas do mesmo IP, necessitando de proxies rotativos ou outras técnicas de evasão.
- Mudanças Frequentes no Site: A Amazon atualiza a estrutura do seu site regularmente, o que pode quebrar scripts de raspagem e exigir manutenção constante.
Como Criar seu scraper JavaScript com Node.js?
No exemplo a seguir, usaremos JavaScript para raspar a Amazon e armazenar os dados extraídos em um arquivo JSON local.
Preparando para a Raspagem
Precisamos configurar as ferramentas necessárias do web scraper Node.js no início:
Neste artigo, usarei o Playwright, um projeto open-source altamente ativo com inúmeros colaboradores. Desenvolvido pela Microsoft, ele suporta vários navegadores (Chromium, Firefox e WebKit) e várias linguagens de programação (Node.js, Python, .NET e Java), tornando-o um dos frameworks de raspagem JavaScript mais populares atualmente.
Aqui, certifique-se de que sua versão do Node.js seja 18 ou superior, em seguida, execute o script a seguir para instalar o Playwright:
Bash
# pnpm
pnpm create playwright
# yarn
yarn create playwright
# npm
npm init playwright@latestFrustrado com o bloqueio na web e a construção de projetos que dão dor de cabeça?
Junte-se à Nossa Comunidade e obtenha a solução eficaz com Teste Gratuito!
Etapa 1. Inspecione a Página de Destino
Antes de raspar, tente visitar https://www.amazon.com/. Se esta for sua primeira vez acessando o site, você pode encontrar um CAPTCHA.
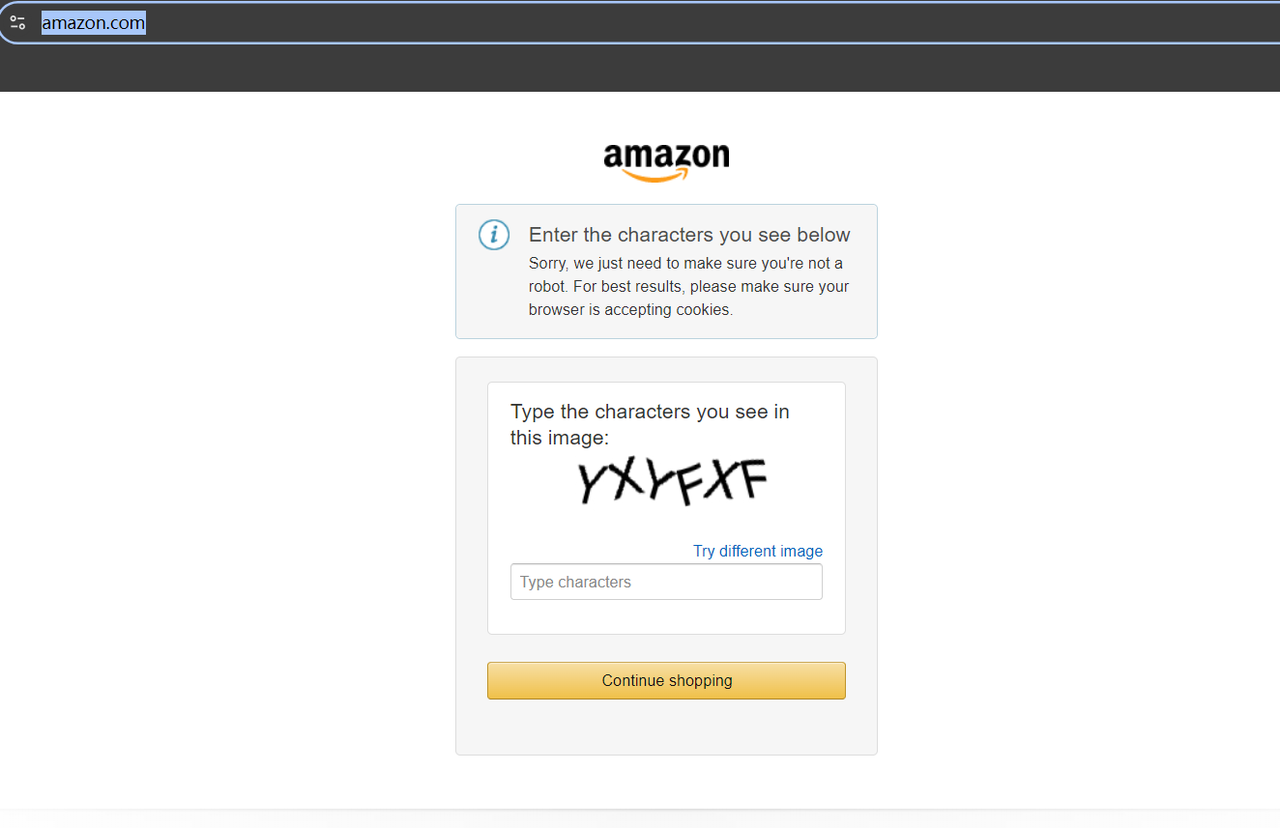
Mas não se preocupe — não precisamos passar pelo incômodo de encontrar uma ferramenta de resolução de CAPTCHA. Em vez disso, basta acessar o domínio da Amazon específico da sua região ou da localização do seu proxy, e você não ativará um CAPTCHA.
Por exemplo, vamos visitar https://www.amazon.co.uk/, o domínio da Amazon do Reino Unido. Você verá a página carregar sem problemas. Agora, tente inserir a palavra-chave do produto desejado na barra de pesquisa no topo ou acesse diretamente os resultados da pesquisa por meio de uma URL, como:
Bash
https://www.amazon.co.uk/s?k=jacketNa URL, o valor após /s?k= representa a palavra-chave do produto. Acessando a URL acima, você verá produtos relacionados a camisas na Amazon.
Agora, abra as Ferramentas do Desenvolvedor (F12) para inspecionar a estrutura HTML da página. Use o cursor para destacar os elementos e identificar os dados que precisaremos raspar mais tarde.
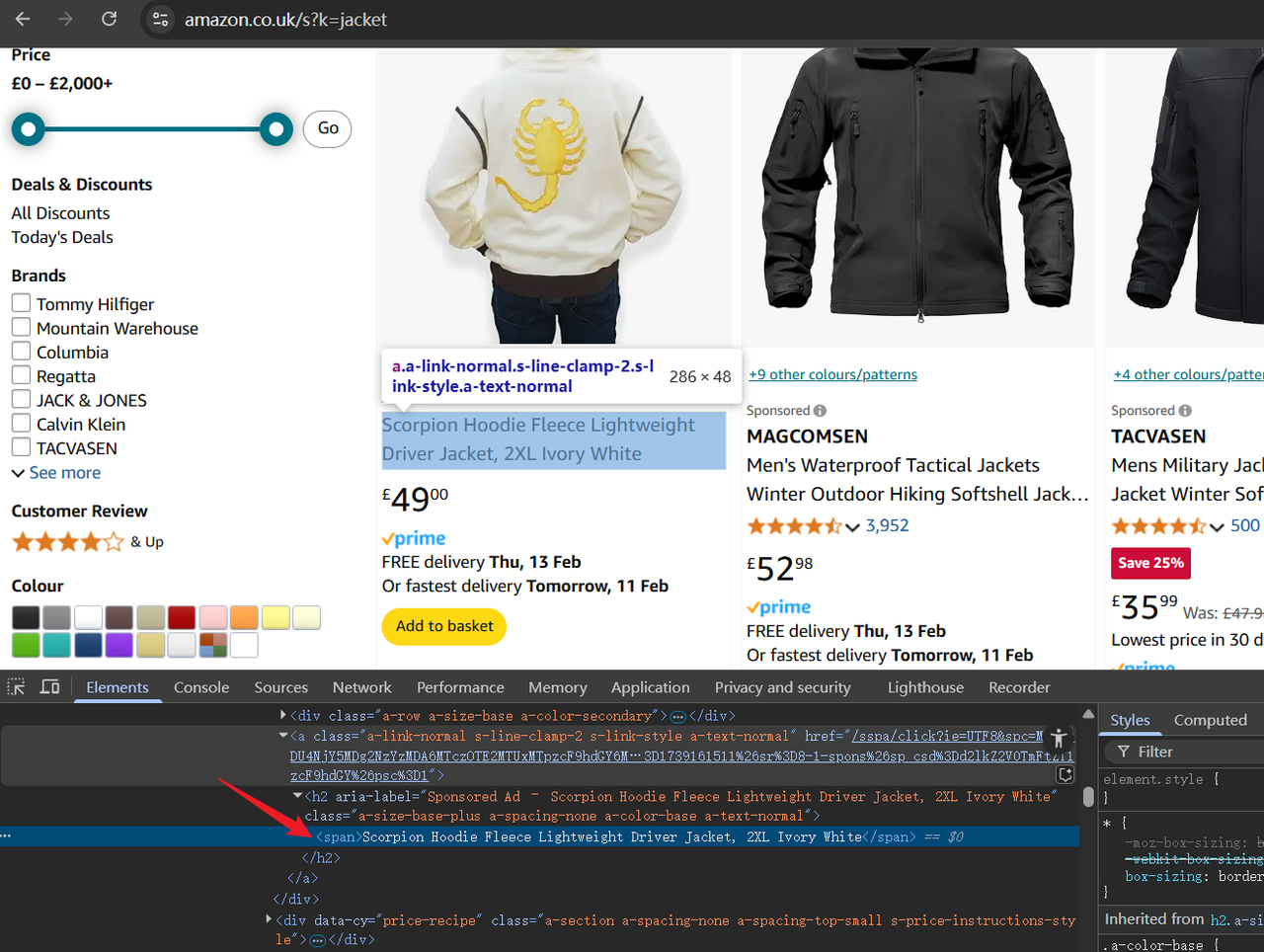
Etapa 2. Escrevendo o Script
Primeiro, vamos adicionar um pedaço de código inicial no topo do script. O código a seguir recebe o primeiro argumento do script como a palavra-chave do produto Amazon, que será usada para raspar mais tarde:
JavaScript
const productName = process.argv.slice(2);
if (productName.length !== 1) {console.error('product name CLI arguments missing!');
process.exit(2);
}Em seguida, precisamos:
- Importar o Playwright para interagir com o navegador.
- Navegar até a página de resultados de pesquisa da Amazon.
- Adicionar uma captura de tela para verificar o acesso bem-sucedido.
JavaScript
import playwright from "playwright";
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// Adicionar uma captura de tela para depuração
await page.screenshot({ path: 'amazon_page.png' })Agora, usaremos page.$$ para buscar todos os contêineres de produtos, iterar sobre eles e extrair os dados relevantes. Esses dados são então armazenados na matriz productDataList e impressos:
JavaScript
// Obter todos os contêineres de resultados de pesquisa
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// Extrair detalhes do produto: título, classificação, URL da imagem e preço
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
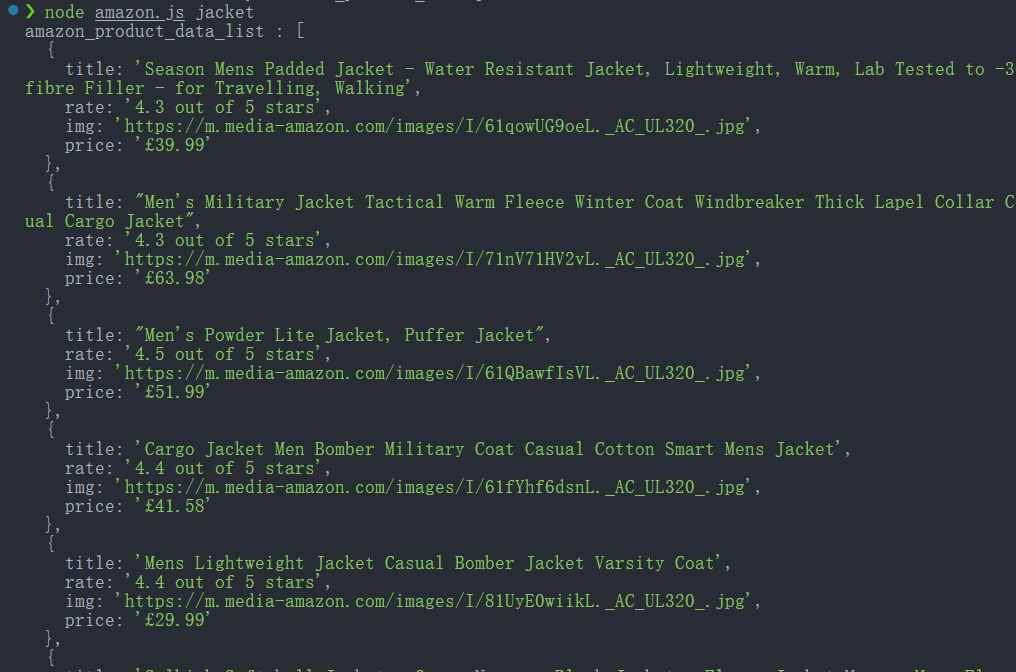
console.log('amazon_product_data_list :', productDataList);
await browser.close();Execute o script usando:
Bash
node amazon.js jacketSe bem-sucedido, o console imprimirá os dados do produto extraídos.
Etapa 3. Salvando Dados Raspados como um Arquivo JSON
Simplesmente imprimir dados no console não é suficiente para uma análise adequada. Vamos salvar os dados extraídos em um arquivo JSON usando o módulo fs do Node.js:
JavaScript
import fs from 'fs'
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')Bem, vamos descobrir o script completo:
JavaScript
import playwright from "playwright";
import fs from 'fs'
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// Adicionar uma captura de tela para depuração
await page.screenshot({ path: 'amazon_page.png' })
// Obter todos os contêineres de resultados de pesquisa
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// Extrair detalhes do produto: título, classificação, URL da imagem e preço
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > a > h2 > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')
await browser.close();Agora, após executar o script, os dados não serão apenas impressos no console, mas também salvos como um arquivo JSON (amazon_product_data.json).
Evite Ser Bloqueado ao Raspar a Amazon
Raspar dados da Amazon pode ser desafiador devido às suas rígidas medidas anti-bot, mas usar o Desbloqueio Web da Scrapeless ajuda a contornar essas restrições de forma eficaz.
A Amazon emprega técnicas de detecção de bot, como limitação de taxa de IP, impressão digital do navegador e verificação de CAPTCHA para evitar acesso automatizado. O Desbloqueio Web da Scrapeless supera esses obstáculos rotando proxies residenciais, imitando o comportamento do usuário real e lidando com a renderização de conteúdo dinâmico.
Integrando a Scrapeless com navegadores sem cabeça como playwright ou Playwright, os usuários podem raspar os dados do produto da Amazon sem serem bloqueados, garantindo um processo de extração de dados eficiente e sem problemas.
Melhores Práticas e Considerações de Raspagem em JavaScript
Ao construir um web scraper em JavaScript, é crucial otimizar a eficiência, lidar com conteúdo dinâmico e evitar armadilhas comuns. Aqui estão algumas melhores práticas e considerações importantes:
- Lidando com Páginas Renderizadas em JavaScript
Muitos sites modernos carregam conteúdo dinamicamente usando JavaScript. Solicitações HTTP tradicionais (como Axios ou Fetch) não capturarão esse conteúdo. Em vez disso, use navegadores sem cabeça como playwright, Playwright ou Selenium para renderizar e extrair dados de páginas com muito JavaScript. - Gerenciando Concorrência para Raspagem Mais Rápida
Executar scrapers sequencialmente pode ser lento. Implemente concorrência lançando várias tarefas de raspagem paralelas para melhorar o desempenho. Use async/await com Promises e gerencie um sistema de fila para equilibrar a carga de raspagem de forma eficiente. - Respeitando robots.txt e Políticas do Site
Antes de raspar, verifique o arquivorobots.txtde um site para determinar suas regras de raspagem. Ignorar essas regras pode resultar em proibições de IP ou problemas legais. Além disso, considere usar rotação de user-agent e limitação de solicitações para minimizar o impacto no servidor de destino. - Evitando Firewalls de Aplicação Web (WAFs)
Os sites implantam WAFs como Akamai, Cloudflare e PerimeterX para bloquear tráfego automatizado. Técnicas como persistência de sessão, evasão de impressão digital do navegador e ferramentas de resolução de CAPTCHA podem ajudar a mitigar a detecção e o bloqueio. - Gerenciamento e Desduplicação Eficientes de URLs
Certifique-se de que seu scraper não visite as mesmas URLs várias vezes mantendo um conjunto de URLs visitadas. Implemente técnicas de canonicalização para normalizar URLs e evitar a coleta de dados duplicados. - Lidando com Paginação e Rolagem Infinita
Os sites costumam usar paginação ou rolagem infinita para carregar conteúdo dinamicamente. Identifique a estrutura de paginação (por exemplo,?page=2) ou use navegadores sem cabeça para simular a rolagem e extrair todo o conteúdo. - Otimização de Extração e Armazenamento de Dados
Após extrair os dados, formate-os corretamente e armazene-os de forma eficiente. Salve dados estruturados em JSON, CSV ou bancos de dados como MongoDB ou PostgreSQL para melhor processamento e análise. - Raspagem Distribuída para Raspagem em Grande Escala
Para tarefas de raspagem em grande escala, distribua a carga de trabalho entre várias máquinas ou instâncias em nuvem usando frameworks de raspagem baseados em filas ou soluções de navegador em nuvem. Isso evita a sobrecarga de um único sistema e melhora a tolerância a falhas.
Usando a API de Raspagem Scrapeless para uma Solução Mais Rápida e Confiável
Integrando a Scrapeless com navegadores sem cabeça como Playwright, os usuários podem construir um scraper em JavaScript para extrair dados de produtos da Amazon sem serem bloqueados, garantindo um processo de extração de dados eficiente e sem problemas.
Recursos:
✅ Obtenha acesso instantâneo aos dados mais recentes com apenas uma chamada de API.
✅ Mais de 200 solicitações simultâneas por segundo com mais de 100 milhões de solicitações por mês.
✅ Cada solicitação leva uma média de 5 segundos, garantindo a recuperação de dados em tempo real sem cache.
✅ Suporta regras de raspagem personalizadas para atender a diferentes necessidades
✅ Suporta raspagem multiplataforma, além da Amazon, também pode suportar outras plataformas de e-commerce: Shopee, Shein, etc.
✅ Pague apenas pelas pesquisas bem-sucedidas
Por que escolher a Scrapeless?
- Dados em Tempo Real: Garante listagens de produtos atualizadas e precisas.
- Desbloqueio de Site Integrado: Ignora automaticamente restrições e CAPTCHAs.
- Legalidade: A Scrapeless fornece uma maneira legal e compatível de acessar os resultados da pesquisa.
- Confiabilidade: A API usa técnicas sofisticadas para evitar a detecção, garantindo a coleta ininterrupta de dados.
- Facilidade de Uso: A Scrapeless oferece uma API simples que se integra facilmente ao Python, tornando-a ideal para desenvolvedores que precisam de acesso rápido aos dados de resultados de pesquisa.
- Personalizável: Você pode adaptar os resultados às suas necessidades, como especificar o tipo de conteúdo (por exemplo, listagens orgânicas, anúncios, etc.).
A API de Raspagem Scrapeless é cara?
A Scrapeless oferece uma plataforma de raspagem web confiável e escalável a preços competitivos (vs. Zenrows & Apify), garantindo excelente valor para seus usuários:
- Navegador de Raspagem: A partir de US$ 0,09 por hora
- API de Raspagem: A partir de US$ 0,8 por 1k URLs
- Desbloqueio Web: US$ 0,20 por 1k URLs
- Resolutor de CAPTCHA: A partir de US$ 0,80 por 1k URLs
- Proxies: US$ 2,80 por GB
Ao se inscrever, você pode aproveitar descontos de até 20% de desconto em cada serviço.
Como implementar a API de Raspagem Amazon da Scrapeless
Se você está procurando extrair números ASIN de páginas de produtos da Amazon, a Scrapeless fornece uma maneira simples e eficaz de fazê-lo. Usando a API Amazon Scraper da Scrapeless, você pode facilmente obter números ASIN juntamente com outros detalhes importantes do produto.
Etapa 1. Faça login na Scrapeless.
Etapa 2. Clique em API de Raspagem > selecionar Amazon para entrar na página de raspagem da Shopee.
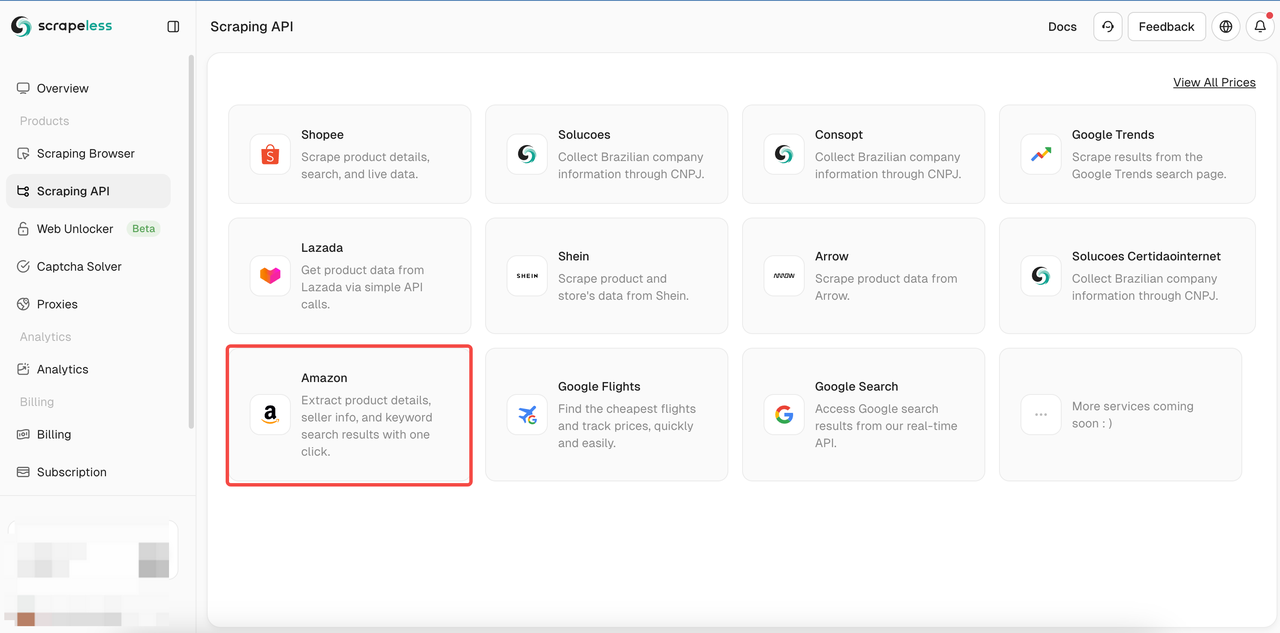
Etapa 3. Cole o link para a página do produto da Amazon que você deseja rastrear na caixa de entrada. E selecione o tipo de dados a rastrear.
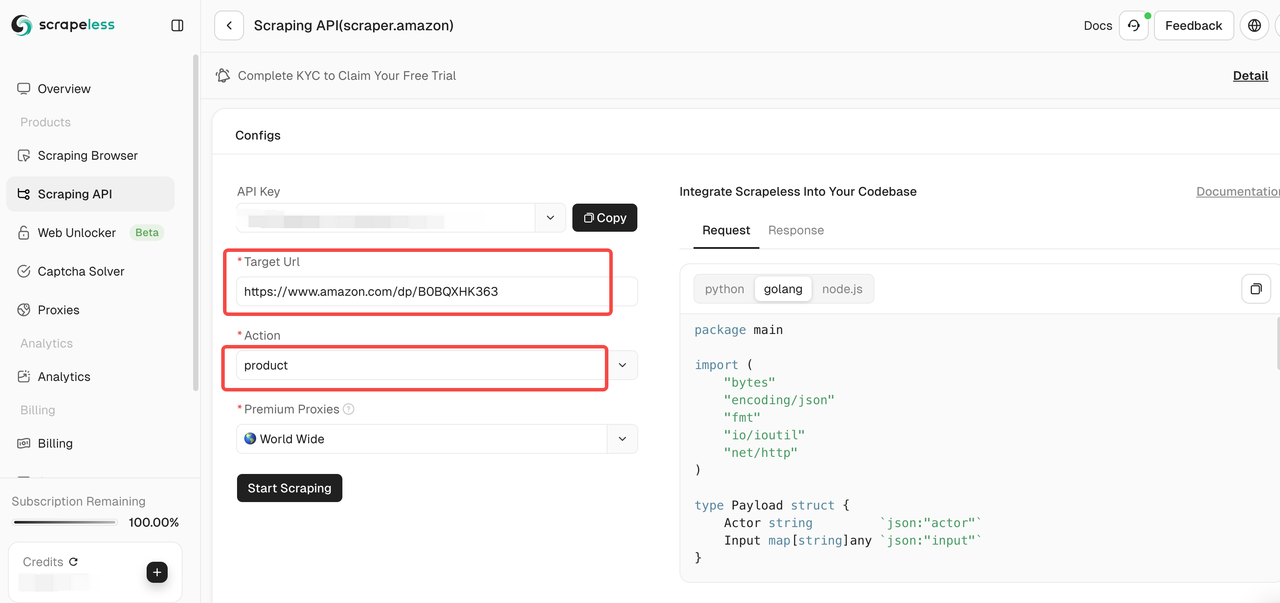
Na página da ferramenta, você pode selecionar o tipo de dados a rastrear:
- Vendedor: Rastreie informações do vendedor, incluindo nome do vendedor, classificação, informações de contato, etc.
- Produto: Rastreie detalhes do produto, como título, preço, classificação, comentários, etc.
- Palavras-chave: Rastreie palavras-chave relacionadas ao produto para ajudá-lo a analisar o SEO do produto e as tendências de mercado.
Etapa 4. Depois de confirmar que o link de entrada e o tipo de dados selecionado estão corretos, clique no botão "Iniciar Raspagem". O sistema iniciará o rastreamento de dados e exibirá os resultados rastreados no painel do lado direito da página.
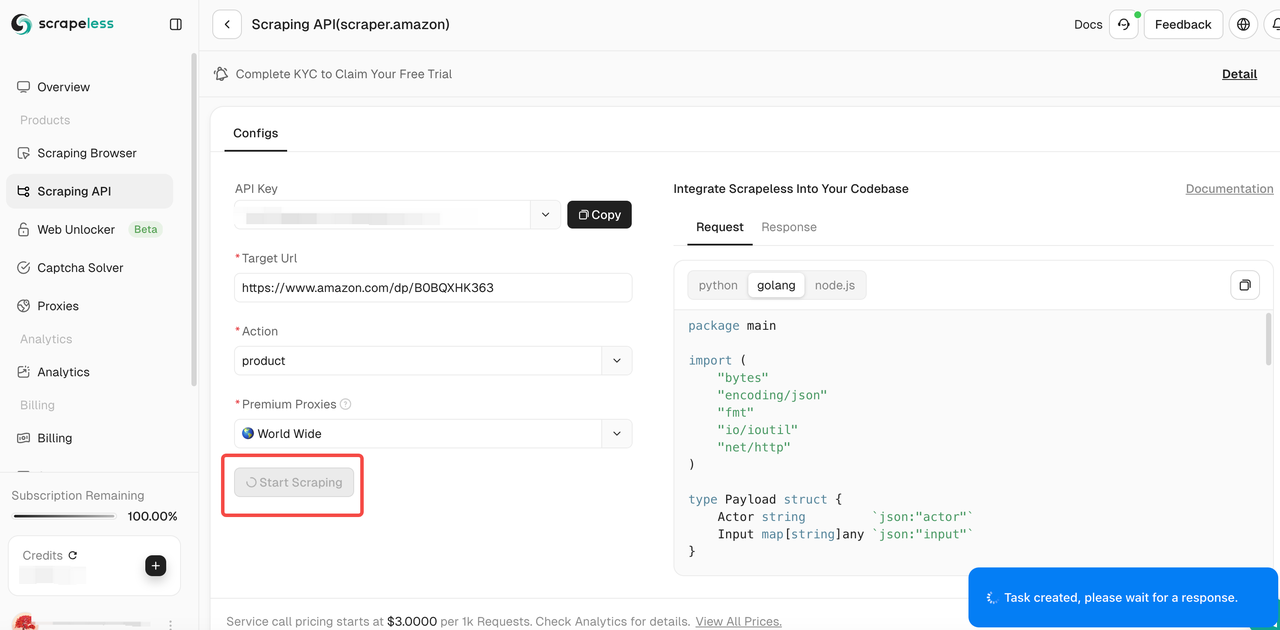
Etapa 5. Após a conclusão do rastreamento, você pode visualizar os dados rastreados no painel à direita. Os resultados serão exibidos em um formato claro para facilitar a análise.
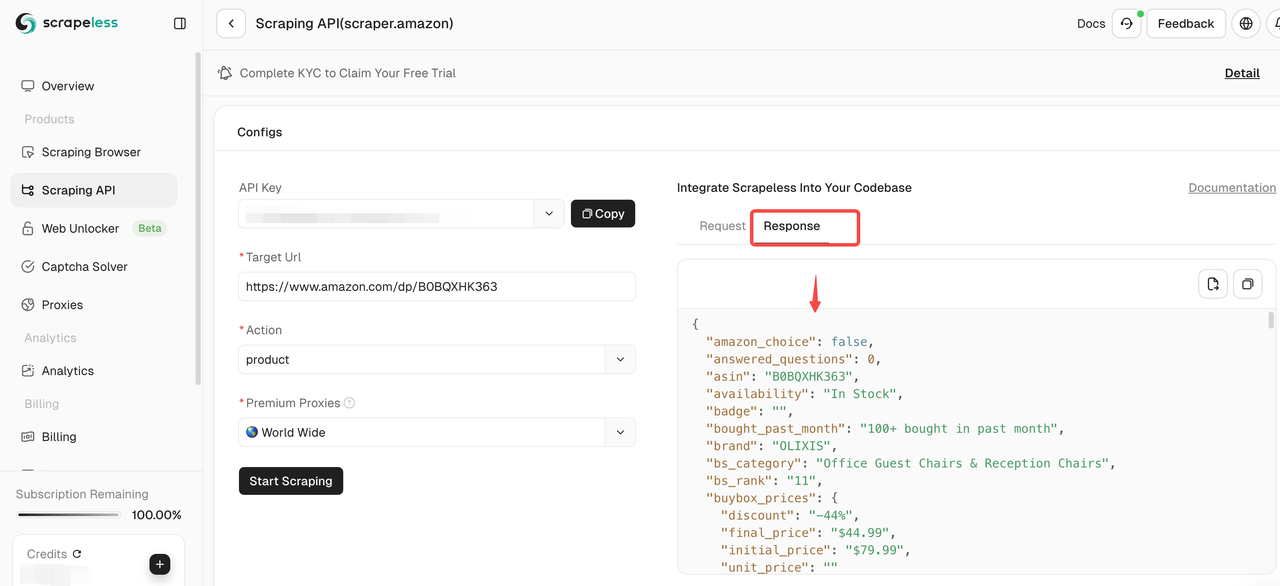
Se você precisar rastrear outros produtos, clique em Continuar para inserir um novo link da Amazon e repita as etapas acima!
Você também pode integrar diretamente nossos códigos ao seu projeto:
Node.js
JavaScript
const https = require('https');
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/scraper/request`;
const token = " "; // API Token
const inputData = {
action: "product",
url: " " // Product URL
};
const payload = new Payload("scraper.amazon", inputData);
const jsonPayload = JSON.stringify(payload);
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token
}
};
const req = https.request(url, options, (res) => {
let body = '';
res.on('data', (chunk) => {
body += chunk;
});
res.on('end', () => {
console.log("body", body);
});
});
req.on('error', (error) => {
console.error('Error:', error);
});
req.write(jsonPayload);
req.end();
}
sendRequest();Python
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " ## API Token
headers = {
"x-api-token": token
}
input_data = {
"action": "product",
"url": " " ## Product URL
}
payload = Payload("scraper.amazon", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Golang
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := " " // API Token
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"action": "product",
"url": " ", // Product URL
}
payload := Payload{
Actor: "scraper.amazon",
Input: inputData,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}Conclusão: A Melhor Maneira de Raspar a Amazon em 2025
Construir um scraper JavaScript com Node.js oferece controle total sobre o processo de raspagem, mas apresenta desafios como lidar com conteúdo dinâmico, resolver CAPTCHAs, gerenciar proxies e evitar detecção. Requer esforço técnico significativo e manutenção contínua.
Para raspagem em grande escala, eficiente e indetectável, a API da Scrapeless é a melhor escolha. Ela elimina as complexidades da detecção de bot, tornando a extração de dados fácil e escalável!
🚀 Experimente a API de Raspagem Amazon da Scrapeless hoje para uma experiência de raspagem rápida, confiável e sem preocupações!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


