
Como Raspar Dados no Make Automaticamente?
Senior Web Scraping Engineer
Recentemente, lançamos uma integração oficial no Make, agora disponível como um aplicativo público. Este tutorial mostrará como criar um poderoso fluxo de trabalho automatizado que combina nossa API de Pesquisa do Google com o Web Unlocker para extrair dados dos resultados de pesquisa, processá-los com Claude AI e enviá-los para um webhook.
O Que Vamos Construir
Neste tutorial, criaremos um fluxo de trabalho que:
- Dispara automaticamente todos os dias usando agendamento integrado
- Busca no Google por consultas específicas usando a API de Pesquisa do Google da Scrapeless
- Processa cada URL individualmente com o Iterador
- Raspa cada URL com o WebUnlocker da Scrapeless para extrair conteúdo
- Analisa o conteúdo com o Anthropic Claude AI
- Envia os dados processados para um webhook (Discord, Slack, banco de dados, etc.)
Pré-requisitos
- Uma conta no Make.com
- Uma chave API da Scrapeless (obtenha uma em scrapeless.com)
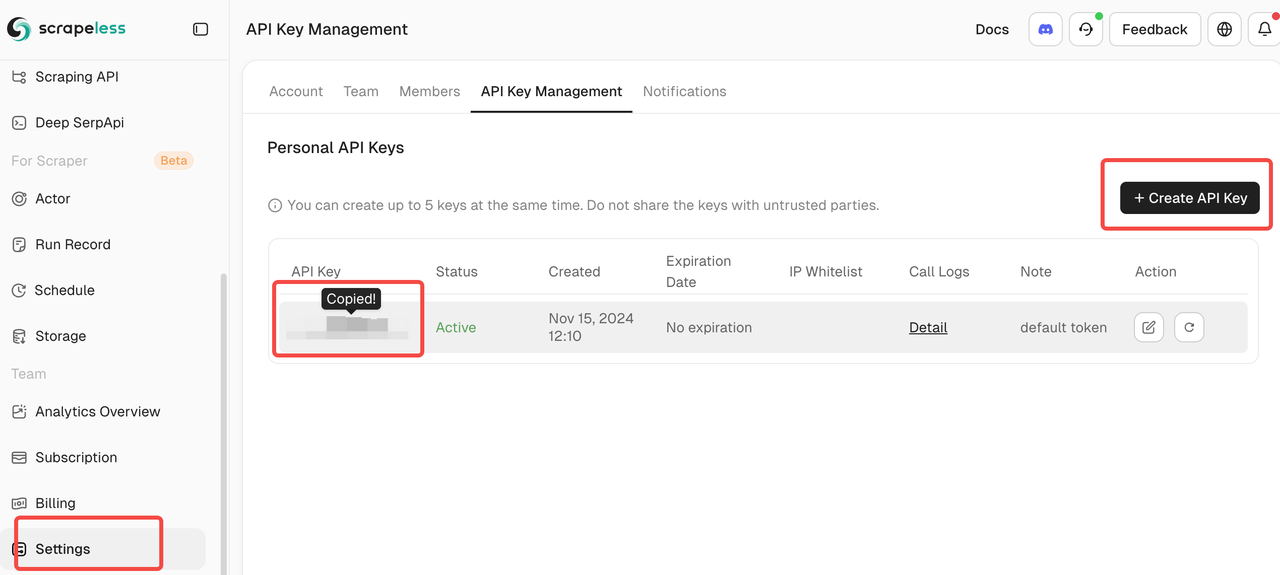
- Uma chave API do Anthropic Claude
- Um endpoint de webhook (webhook do Discord, Zapier, endpoint de banco de dados, etc.)
- Compreensão básica dos fluxos de trabalho do Make.com
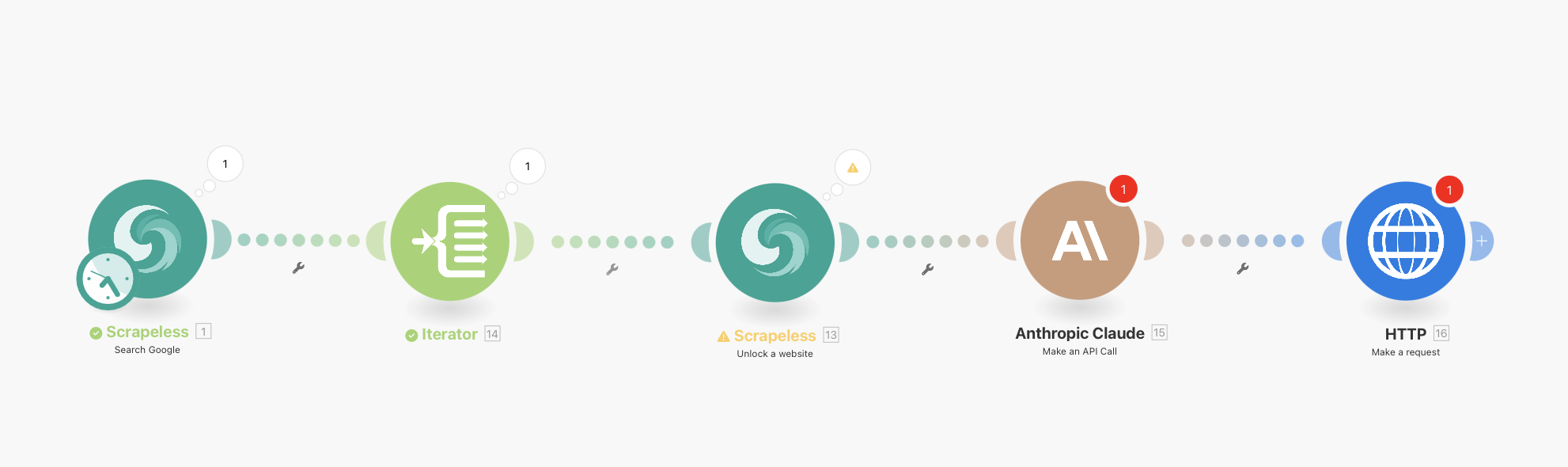
Visão Geral do Fluxo de Trabalho Completo
Seu fluxo de trabalho final será assim:
Scrapeless Google Search (com agendamento integrado) → Iterator → Scrapeless WebUnlocker → Anthropic Claude → HTTP Webhook
Passo 1: Adicionando o Scrapeless Google Search com Agendamento Integrado
Começaremos adicionando o módulo Scrapeless Google Search com agendamento embutido.
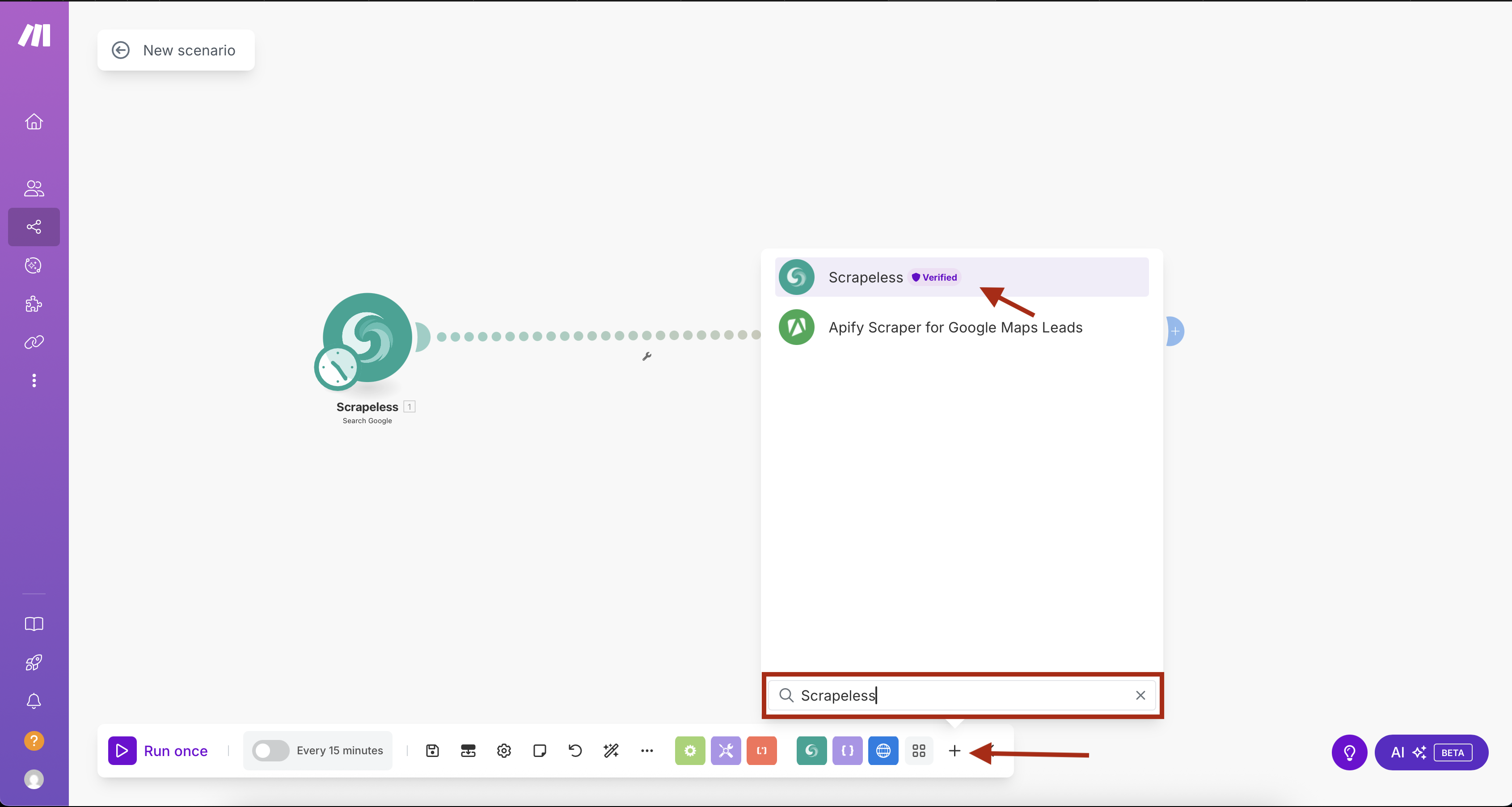
- Crie um novo cenário no Make.com
- Clique no botão "+" para adicionar o primeiro módulo
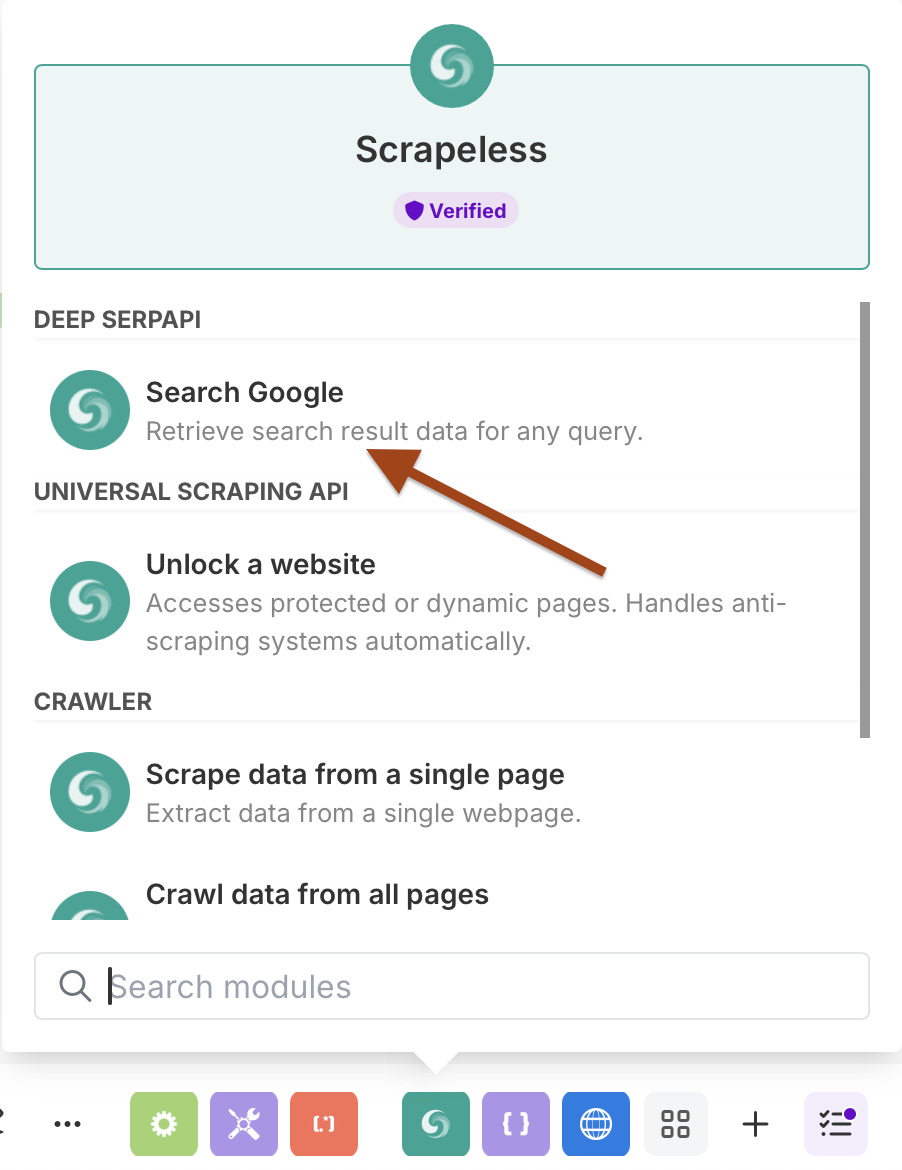
- Procure por "Scrapeless" na biblioteca de módulos
- Selecione Scrapeless e escolha a ação Search Google
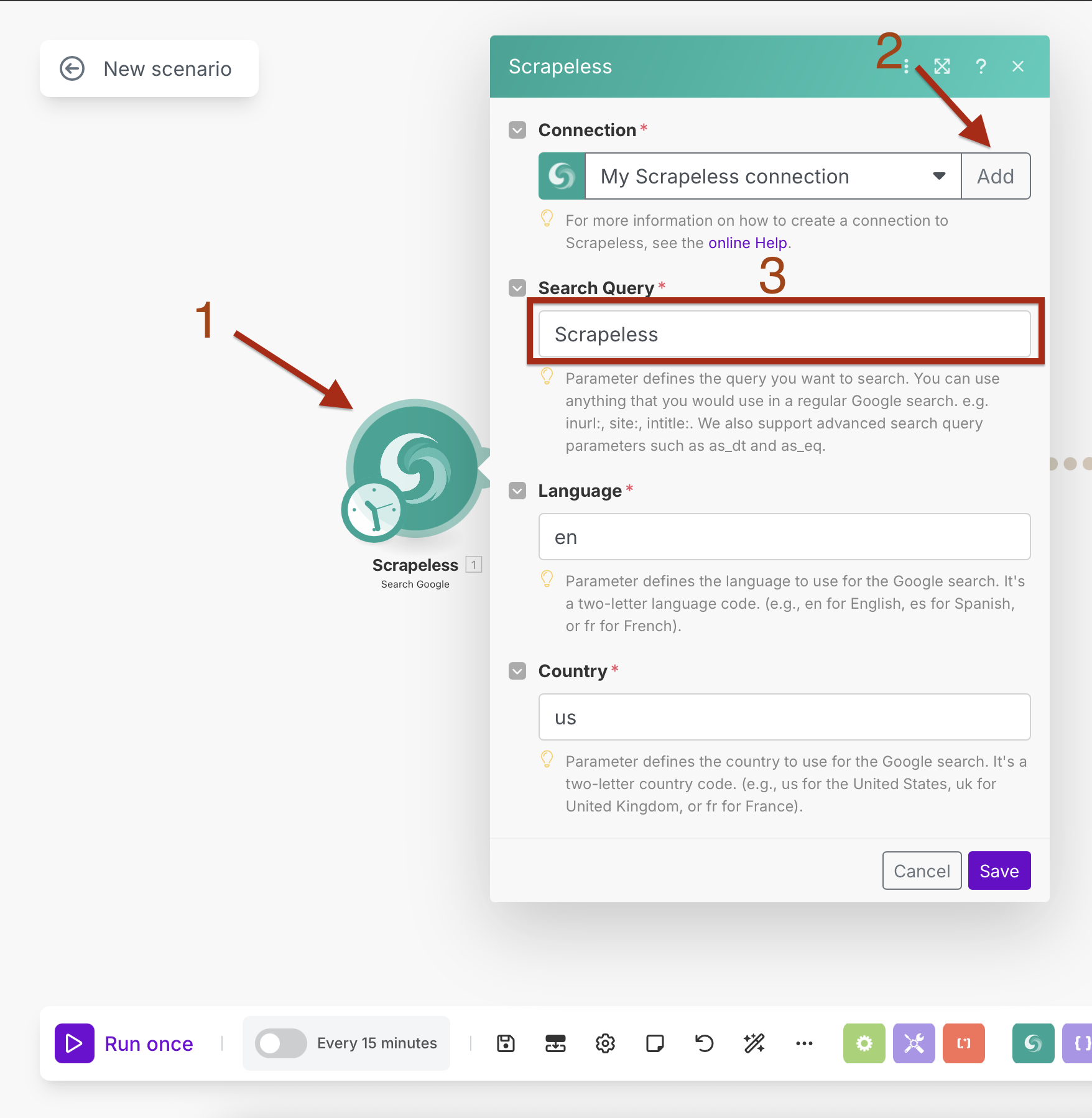
Configurando a Pesquisa do Google com Agendamento
Configuração da Conexão:
- Crie uma conexão inserindo sua chave API do Scrapeless
- Clique em "Adicionar" e siga a configuração da conexão
Parâmetros de Pesquisa:
- Consulta de Pesquisa: Insira sua consulta-alvo (ex: "notícias sobre inteligência artificial")
- Idioma:
en(inglês) - País:
US(Estados Unidos)
Configuração de Agendamento:
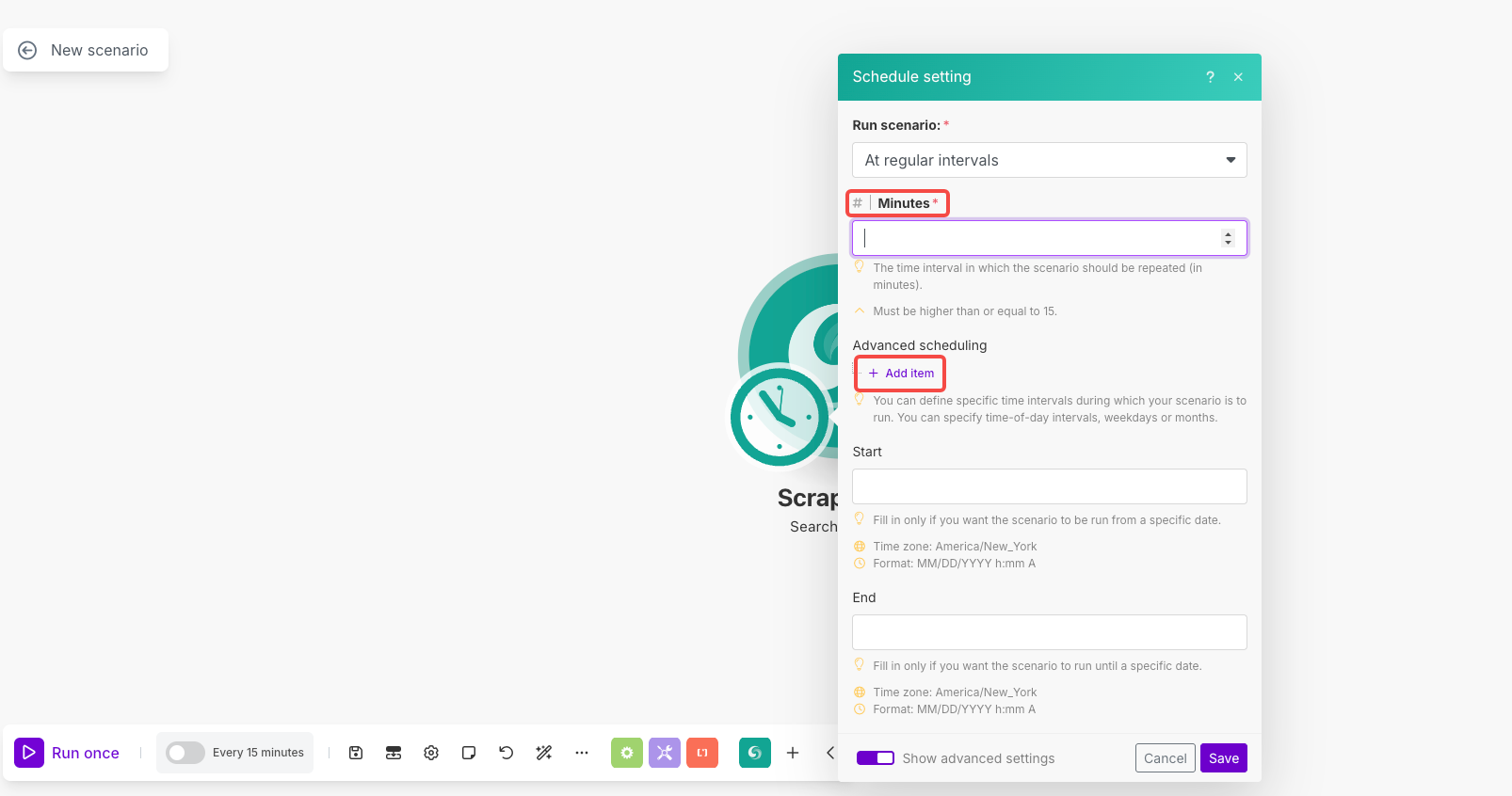
- Clique no ícone de relógio no módulo para abrir o agendamento
- Executar cenário: Selecione "Em intervalos regulares"
- Minutos: Defina como
1440(para execução diária) ou seu intervalo preferido - Agendamento avançado: Use "Adicionar item" para definir horários/dias específicos, se necessário
Passo 2: Processando Resultados com o Iterador
A Pesquisa do Google retorna várias URLs em um array. Usaremos o Iterador para processar cada resultado individualmente.
- Adicione um módulo Iterador após a Pesquisa do Google
- Configure o campo Array para processar os resultados da pesquisa
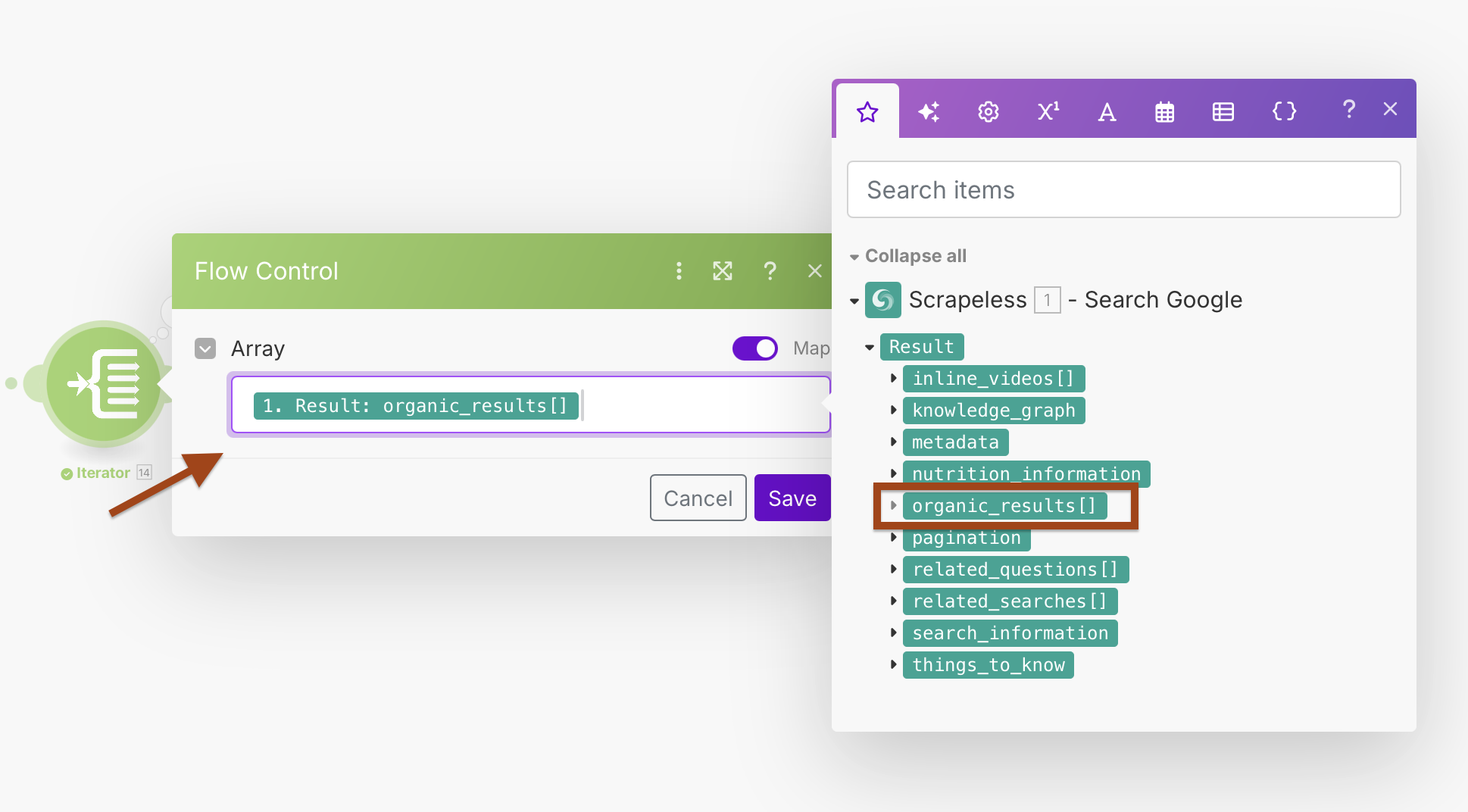
Configuração do Iterador:
- Array:
{{1.result.organic_results}}
Isso criará um loop que processa cada resultado de pesquisa separadamente, permitindo melhor tratamento de erros e processamento individual.
Passo 3: Adicionando o Scrapeless WebUnlocker
Agora vamos adicionar o módulo WebUnlocker para raspar conteúdo de cada URL.
- Adicione mais um módulo Scrapeless
- Selecione a ação Scrape URL (WebUnlocker)
- Use a mesma conexão do Scrapeless
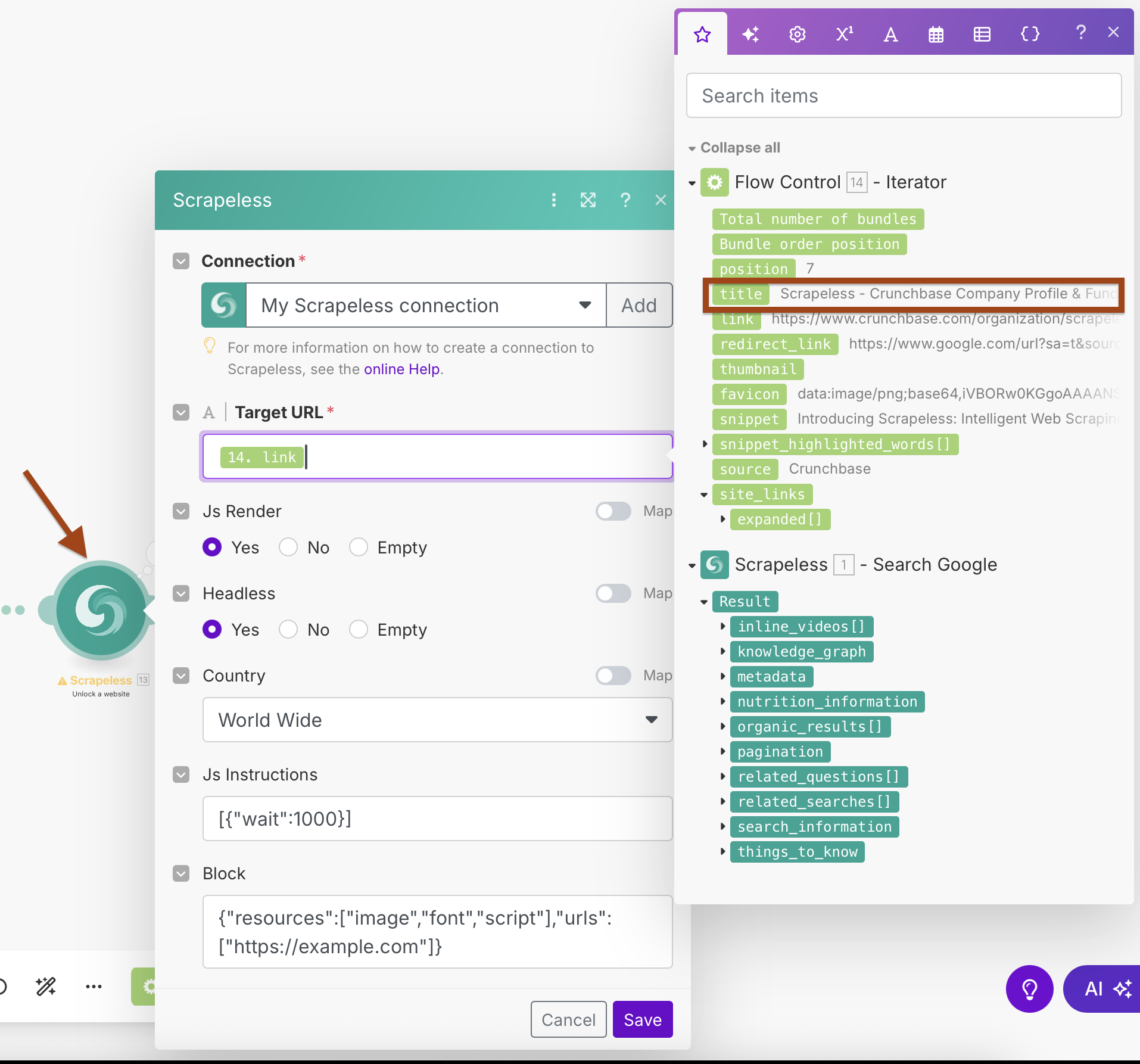
Configuração do WebUnlocker:
- Conexão: Use sua conexão Scrapeless existente
- URL de Destino:
{{2.link}}(mapeado a partir da saída do Iterador) - Js Render: Sim
- Headless: Sim
- País: Mundo Todo
- Instruções Js:
[{"wait":1000}](aguardar o carregamento da página) - Bloquear: Configure para bloquear recursos desnecessários para uma raspagem mais rápida
Passo 4: Processamento de IA com Anthropic Claude
Adicione o Claude AI para analisar e resumir o conteúdo raspado.
- Adicione um módulo Anthropic Claude
- Selecione a ação Make an API Call
- Crie uma nova conexão com sua chave API do Claude
Configuração do Claude:
- Conexão: Crie uma conexão com sua chave API do Anthropic
- Prompt: Configure para analisar o conteúdo raspado
- Model: claude-3-sonnet-20240229 / claude-3-opus-20240229 ou seu modelo preferido
- Max Tokens: 1000-4000 dependendo das suas necessidades
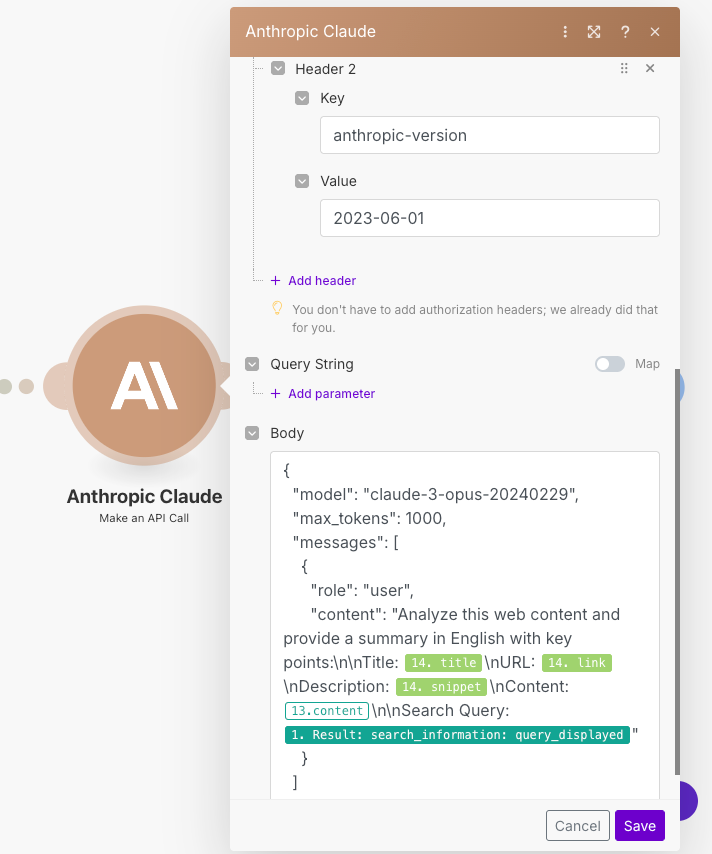
URL
/v1/messagesCabeçalho 1
Key : Content-TypeValue : application/json
Cabeçalho 2
Key : anthropic-versionValue : 2023-06-01
Exemplo de Prompt para copiar e colar no corpo:
{
"model": "claude-3-sonnet-20240229",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "Analise este conteúdo da web e forneça um resumo em inglês com os pontos-chave:\n\nTítulo: {{14.title}}\nURL: {{14.link}}\nDescrição: {{14.snippet}}\nConteúdo: {{13.content}}\n\nConsulta de Pesquisa: {{1.result.search_information.query_displayed}}"
}
]
}- Não se esqueça de alterar o número
14pelo número do seu módulo.
Passo 5: Integração do Webhook
Finalmente, envie os dados processados para seu endpoint de webhook.
- Adicione um módulo HTTP
- Configure-o para enviar uma solicitação POST para seu webhook
Configuração HTTP:
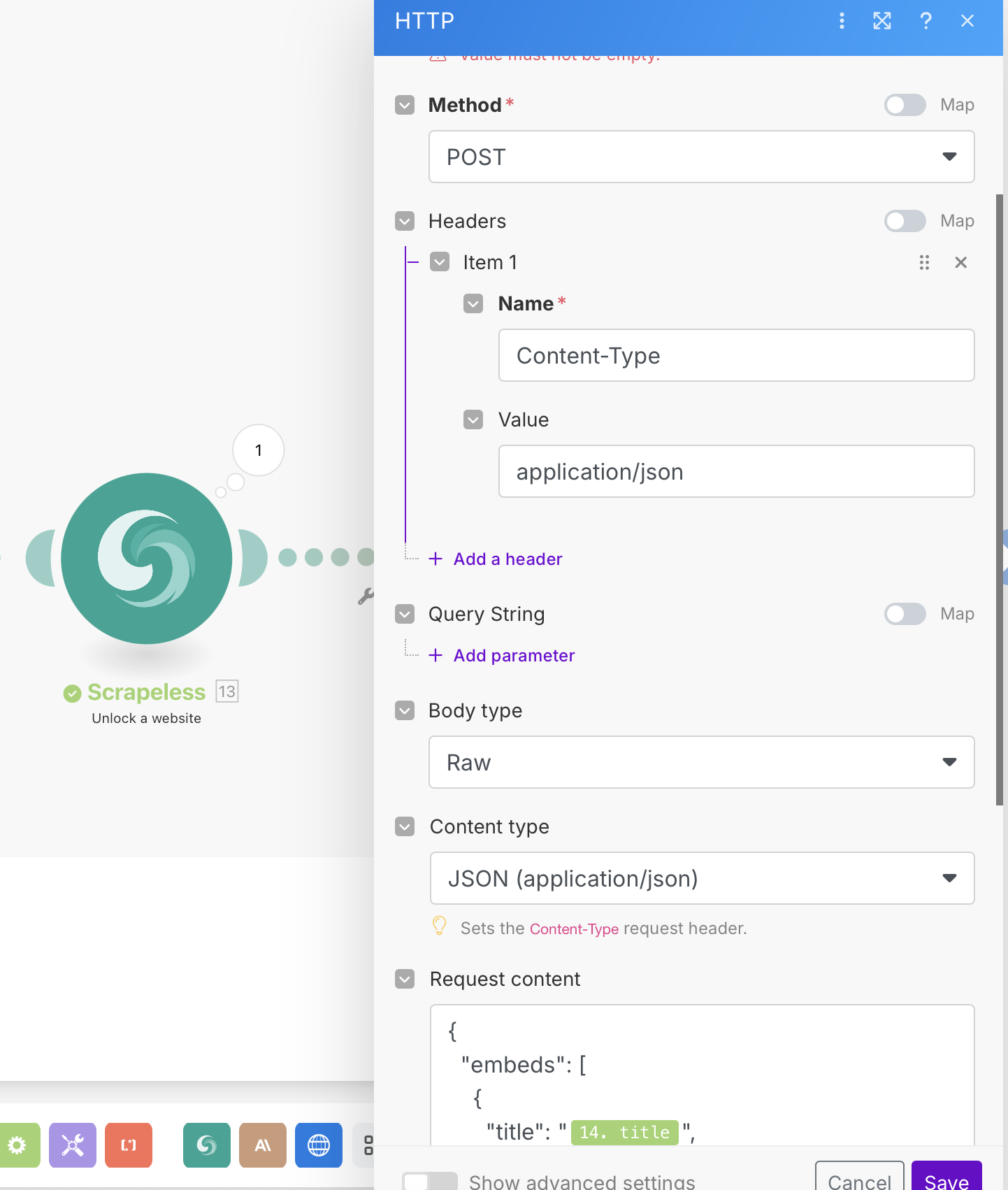
- URL: Seu endpoint de webhook (Discord, Slack, banco de dados, etc.)
- Método: POST
- Cabeçalhos:
Content-Type: application/json - Tipo de Corpo: Raw (JSON)
Exemplo de Payload do Webhook:
{
"embeds": [
{
"title": "{{14.title}}",
"description": "*{{15.body.content[0].text}}*",
"url": "{{14.link}}",
"color": 3447003,
"footer": {
"text": "Análise completa"
}
}
]
}Resultados em Execução
Referência do Módulo e Fluxo de Dados
Fluxo de Dados Através dos Módulos:
- Módulo 1 (Pesquisa Google Scrapeless): Retorna
result.organic_results[] - Módulo 14 (Iterator): Processa cada resultado, gera itens individuais
- Módulo 13 (WebUnlocker): Raspas
{{14.link}}, retorna conteúdo - Módulo 15 (Claude AI): Analisa
{{13.content}}, retorna resumo - Módulo 16 (Webhook HTTP): Envia os dados estruturados finais
Mapeamentos Chave:
- Array do Iterator:
{{1.result.organic_results}} - URL do WebUnlocker:
{{14.link}} - Conteúdo do Claude:
{{13.content}} - Dados do Webhook: Combinação de todos os módulos anteriores
Testando Seu Fluxo de Trabalho
- Execute uma vez para testar o cenário completo
- Verifique cada módulo:
- Pesquisa Google retorna resultados orgânicos
- Iterador processa cada resultado individualmente
- WebUnlocker raspa o conteúdo com sucesso
- Claude fornece análise significativa
- Webhook recebe dados estruturados
- Verifique a qualidade dos dados em seu destino de webhook
- Verifique o agendamento - certifique-se de que ele é executado nos intervalos desejados
Dicas de Configuração Avançadas
Tratamento de Erros
- Adicione rotas de Tratamento de Erros após cada módulo
- Use Filtros para ignorar URLs inválidas ou conteúdo vazio
- Defina lógica de Repetição para falhas temporárias
Benefícios deste Fluxo de Trabalho
- Totalmente Automatizado: Funciona diariamente sem intervenção manual
- Aprimorado por IA: O conteúdo é analisado e resumido automaticamente
- Saída Flexível: O webhook pode se integrar a qualquer sistema
- Escalável: Processa várias URLs de forma eficiente
- Controle de Qualidade: Várias etapas de filtragem e validação
- Notificações em Tempo Real: Entrega imediata à sua plataforma preferida
Casos de Uso
Perfeito para:
- Monitoramento de Conteúdo: Acompanhe menções à sua marca ou concorrentes
- Agregação de Notícias: Resumos automáticos de notícias sobre tópicos específicos
- Pesquisa de Mercado: Monitore tendências e desenvolvimentos da indústria
- Geração de Leads: Encontre e analise oportunidades de negócios potenciais
- Monitoramento de SEO: Acompanhe mudanças nos resultados de busca para palavras-chave-alvo
- Automação de Pesquisa: Colete e resuma conteúdo acadêmico ou da indústria
Conclusão
Este fluxo de trabalho automatizado combina o poder da Pesquisa Google Scrapeless e do WebUnlocker com as capacidades de análise da IA Claude, tudo orquestrado através da interface visual do Make. O resultado é um sistema inteligente de descoberta de conteúdo que funciona automaticamente e entrega dados enriquecidos e analisados diretamente à sua plataforma preferida via webhook.
O fluxo de trabalho será executado de acordo com sua programação, descobrindo, raspando, analisando e entregando automaticamente insights sobre conteúdos relevantes sem qualquer intervenção manual.
Hora de construir seu primeiro Agente de IA no Make usando Scrapeless!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


