
Como Raspar Resultados de Busca do Google com Python - Melhor Raspador de Busca do Google?
Specialist in Anti-Bot Strategies
O que é o Google SERP?
Sempre que se discute a extração de dados (web scraping) dos resultados de pesquisa do Google, você provavelmente encontrará a abreviação "SERP". SERP significa Página de Resultados do Motor de Busca (Search Engine Results Page). É a página que você obtém após inserir uma consulta na barra de pesquisa.
No passado, o Google retornava uma lista de links para sua consulta. Hoje, a aparência é completamente diferente - as SERPs incluem uma variedade de recursos e elementos que tornam sua experiência de pesquisa rápida e conveniente.
Normalmente, a página consiste em:
- Resultados de Busca Orgânica
- Resultados de Busca Paga
- Snippets em Destaque
- Knowledge Graph
- Outros Elementos: Como mapas, imagens ou notícias que aparecem com base na consulta.
É legal extrair dados dos resultados de pesquisa do Google?
Antes de extrair dados dos resultados de pesquisa do Google, é essencial entender as implicações legais. Os Termos de Serviço do Google proíbem a extração de dados de seus resultados de pesquisa, conforme declarado em suas políticas:
"Você não deverá raspar, rastrear ou usar qualquer meio automatizado para acessar os Serviços para qualquer finalidade."
Violar esses termos pode resultar em bloqueios de IP ou até mesmo ações legais do Google. No entanto, a legalidade da extração de dados depende da jurisdição, dos dados que você está extraindo e de como você os está usando.
Alternativas à extração de dados do Google:
- Google Custom Search API: O Google oferece uma API oficial para recuperar resultados de pesquisa, fornecendo uma maneira legal e estruturada de acessar dados sem violar suas políticas.
- Outras APIs de Busca: Se você não está decidido a usar o Google, existem outros mecanismos de busca e serviços que fornecem APIs para acessar resultados de pesquisa, como Bing e Scrapeless.
4 Principais Dificuldades para Extrair Dados do Google SERP
A extração de dados das SERPs do Google apresenta uma série de desafios, razão pela qual é considerada difícil. Estes incluem:
- Detecção de Bots: O Google emprega várias técnicas para detectar e bloquear bots, incluindo:
- CAPTCHA
- Bloqueio de IP
- Limitação de Taxa
- Conteúdo Dinâmico: Os resultados de pesquisa do Google são frequentemente gerados dinamicamente usando JavaScript, o que pode complicar a extração de dados. O conteúdo pode carregar após o carregamento inicial da página, exigindo ferramentas como o Selenium para renderizar a página completamente.
- Mudanças na Estrutura HTML: O Google muda frequentemente o layout e a estrutura de seus resultados de pesquisa, o que significa que os rastreadores precisam se adaptar rapidamente para evitar que o código pare de funcionar.
- Dados Complexos: A SERP inclui uma variedade de elementos complexos, como anúncios, imagens, vídeos e rich snippets, tornando difícil extrair dados significativos de forma consistente.
Apesar desses desafios, a extração de dados dos resultados de pesquisa do Google ainda é possível com as técnicas e ferramentas certas.
Vamos dividir o processo nas seguintes etapas para extrair dados dos resultados de pesquisa do Google com Python:
Como extrair dados dos resultados de pesquisa do Google usando Python?
Etapa 1: Enviar solicitações ao Google
Antes de começar a extrair dados, você precisará enviar uma solicitação à página de pesquisa do Google. Como o Google bloqueia a maioria das solicitações de bots, é essencial simular um usuário real definindo um cabeçalho User-Agent adequado.
Python
import requests
from fake_useragent import UserAgent
# Gera um user-agent aleatório
ua = UserAgent()
headers = {'User-Agent': ua.random}
# Consulta de pesquisa do Google
query = "How to scrape Google search results with Python"
url = f"https://www.google.com/search?q={query}"
# Envia a solicitação GET
response = requests.get(url, headers=headers)
# Verifica se a solicitação foi bem-sucedida
if response.status_code == 200:
print(response.text)
else:
print("Falha ao recuperar a página")Etapa 2: Analisar o conteúdo HTML
Depois de ter o conteúdo HTML da SERP do Google, você pode usar o BeautifulSoup para extrair os dados de que precisa.
Python
from bs4 import BeautifulSoup
# Analisa o conteúdo da página
soup = BeautifulSoup(response.text, 'html.parser')
# Encontra todos os contêineres de resultados de pesquisa
search_results = soup.find_all('div', class_='BVG0Nb')
for result in search_results:
title = result.text
link = result.find('a')['href']
print(f"Título: {title}")
print(f"Link: {link}\n")Etapa 3: Lidando com JavaScript (Usando Selenium)
O Selenium é uma ótima ferramenta para lidar com páginas que dependem de JavaScript para renderizar conteúdo. Ele automatiza um navegador e simula a interação do usuário, tornando-o ideal para extrair dados de conteúdo gerado dinamicamente.
Python
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# Configura o Selenium WebDriver
driver = webdriver.Chrome(ChromeDriverManager().install())
# Abre o Google e realiza a pesquisa
driver.get("https://www.google.com/")
search_box = driver.find_element(By.NAME, 'q')
search_box.send_keys("How to scrape Google search results with Python")
search_box.submit()
# Aguarda o carregamento dos resultados e extrai os links
driver.implicitly_wait(5)
# Obtém os resultados da pesquisa
search_results = driver.find_elements(By.CLASS_NAME, 'BVG0Nb')
for result in search_results:
title = result.text
link = result.find_element(By.TAG_NAME, 'a').get_attribute('href')
print(f"Título: {title}")
print(f"Link: {link}\n")
driver.quit()Etapa 4: Evitar Detecção
Para minimizar as chances de ser detectado e bloqueado pelo Google, você deve:
- Rotacionar User Agents: Use diferentes user agents para simular solicitações de vários navegadores.
- Adicionar Atrasos: Introduza atrasos aleatórios entre as solicitações para imitar o comportamento de navegação de um humano.
- Usar Proxies: Rotacionar endereços IP para distribuir suas solicitações e evitar detecção.
- Respeitar o Robots.txt: Sempre verifique o arquivo robots.txt do Google e siga as práticas éticas de extração de dados.
A Melhor API de Extração de Dados do Google Search - Scrapeless
Embora a extração de dados do Google diretamente seja possível, pode ser tedioso e propenso a erros, e muitas vezes resulta em bloqueio. É aí que entra o Scrapeless. Com o poderoso resolvedor de CAPTCHA, rotação de IP, proxy inteligente e desbloqueador da web, o Scrapeless é uma API poderosa projetada especificamente para ajudar os usuários a extrair dados dos resultados de pesquisa sem serem bloqueados.
Por que escolher o Scrapeless?
- Legalidade: O Scrapeless fornece uma maneira legal e compatível de acessar os resultados de pesquisa.
- Confiabilidade: A API usa técnicas sofisticadas para evitar a detecção, garantindo a coleta ininterrupta de dados.
- Facilidade de Uso: O Scrapeless oferece uma API simples que se integra facilmente ao Python, tornando-a ideal para desenvolvedores que precisam de acesso rápido aos dados dos resultados de pesquisa.
- Personalizável: Você pode adaptar os resultados às suas necessidades, como especificar o tipo de conteúdo (por exemplo, listagens orgânicas, anúncios, etc.).
API de extração de dados do Google Search do Scrapeless - usando etapas:
Para tornar os dados direcionados e específicos, rastreamos as tendências do Google neste artigo como demonstração.
Frustrado com o bloqueio na web e a extração de dados do Google Search?
Junte-se à Nossa Comunidade e obtenha a solução eficaz com Teste Grátis!
Etapa 1. Faça login no Painel do Scrapeless e vá para "Google Search API".
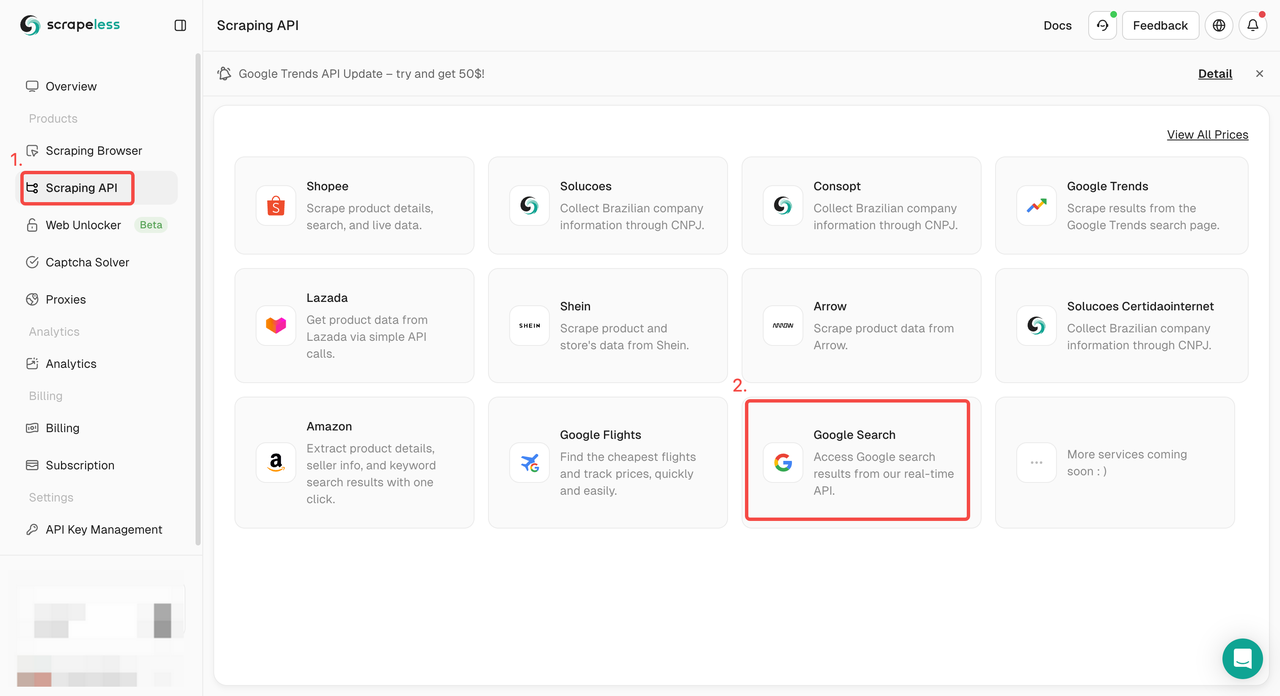
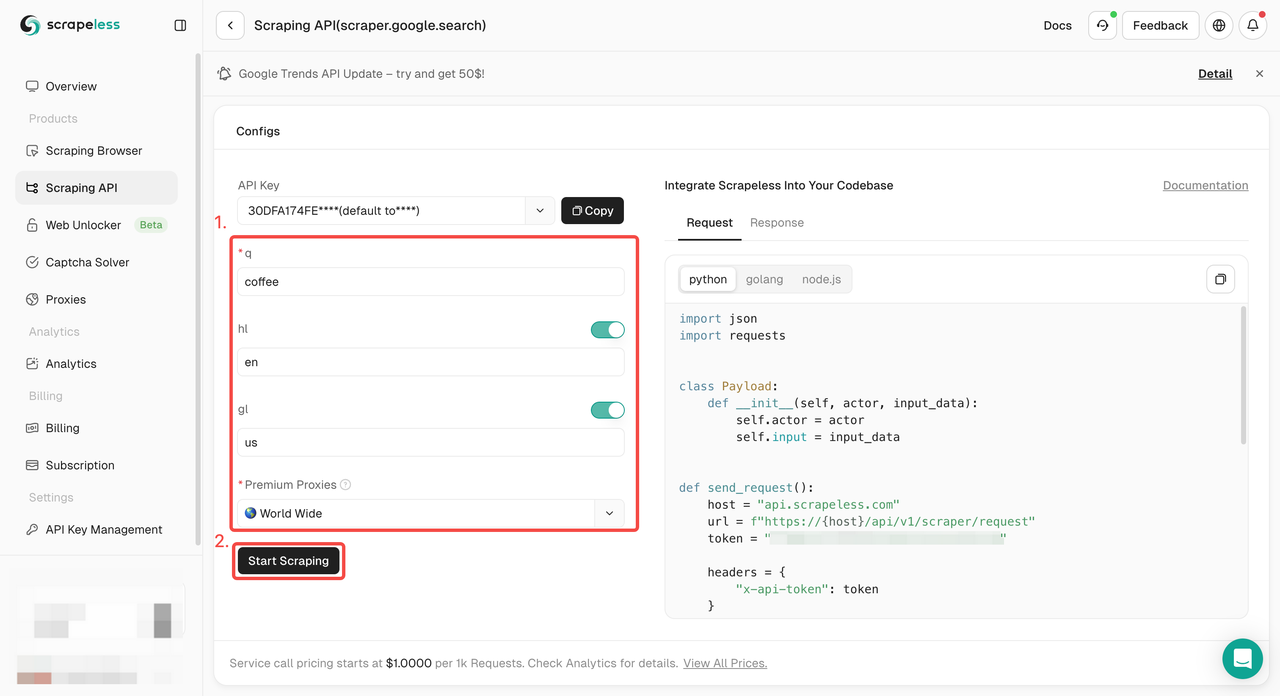
Etapa 2. Configure as palavras-chave, região, idioma, proxy e outras informações necessárias à esquerda. Depois de se certificar de que tudo está certo, clique em "Iniciar Extração de Dados".
q: O parâmetro define a consulta que você deseja pesquisar.gl: O parâmetro define o país a ser usado para a pesquisa do Google.hl: O parâmetro define o idioma a ser usado para a pesquisa do Google.
Etapa 3. Obtenha os resultados do rastreamento e exporte-os.
Precisa apenas de um exemplo de código para integrar ao seu projeto? Nós o cobrimos! Ou você pode visitar nossa documentação da API para qualquer idioma que você precisar.
- Python:
Python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))- Golang
Go
package main
import (
"fmt"
"strings"
"net/http"
"io/ioutil"
)
func main() {
url := "https://api.scrapeless.com/api/v1/scraper/request"
method := "POST"
payload := strings.NewReader(`{
"actor": "scraper.google.search",
"input": {
"q": "coffee",
"hl": "en",
"gl": "us"
}
}`)
client := &http.Client {
}
req, err := http.NewRequest(method, url, payload)
if err != nil {
fmt.Println(err)
return
}
req.Header.Add("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Println(err)
return
}
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(string(body))
}Palavras Finais
Extrair dados dos resultados de pesquisa do Google pode ser complicado, mas com as ferramentas e técnicas certas, é definitivamente alcançável! Lembre-se: não se trata apenas de escrever o código — trata-se de saber como evitar a detecção, respeitar os limites legais e encontrar alternativas quando necessário.
A API de Extração de Dados Scrapeless pode ser seu melhor amigo no mundo da extração de dados dos resultados de pesquisa do Google!
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


