
Como Melhor Implantar o Uso de Scrapeless e Navegador?
Senior Web Scraping Engineer
Scraping Browser se tornou a ferramenta mais utilizada para extração de dados diários e tarefas de automação. Ao integrar o Browser-Use com o Scrapeless Scraping Browser, você pode superar as limitações da automação do navegador e evitar bloqueios.
Neste artigo, construiremos uma ferramenta de agente de IA automatizada usando o Browser-Use e o Scrapeless Scraping Browser para realizar scraping de dados automatizado. Você verá como isso economiza seu tempo e esforço, tornando as tarefas de automação muito mais fáceis!
Você vai aprender:
- O que é o Browser-Use e como ele ajuda a construir agentes de IA?
- Como o Scraping Browser pode efetivamente superar as limitações do Browser-Use?
- Como construir um agente de IA livre de bloqueios usando Browser-Use e Scraping Browser?
O Que É o Browser-Use?
Browser-Use é uma biblioteca de automação de navegador baseada em Python projetada para capacitar agentes de IA com capacidades avançadas de automação de navegador. Ele pode reconhecer todos os elementos interativos em uma página da web e permite que os agentes interajam com a página programaticamente—realizando tarefas comuns como busca, cliques, preenchimento de formulários e scraping de dados. Em sua essência, o Browser-Use converte websites em texto estruturado e suporta frameworks de navegador como Playwright, simplificando muito as interações na web.
Ao contrário das ferramentas de automação tradicionais, o Browser-Use combina compreensão visual com parsing de estrutura HTML, permitindo que os agentes de IA controlem o navegador usando instruções em linguagem natural. Isso torna a IA mais inteligente em perceber o conteúdo da página e executar tarefas de forma eficiente. Além disso, suporta gerenciamento de múltiplas abas, rastreamento de interação com elementos, manuseio de ações personalizadas e mecanismos de recuperação de erros integrados para garantir a estabilidade e consistência dos fluxos de trabalho de automação.
Mais importante ainda, o Browser-Use é compatível com todos os principais modelos de linguagem grande (como GPT-4, Claude 3, Llama 2). Com a integração do LangChain, os usuários podem simplesmente descrever tarefas em linguagem natural, e o agente de IA completará operações web complexas. Para usuários que buscam automação de interação web orientada por IA, esta é uma ferramenta poderosa e promissora.
Limitações do Browser-Use no Desenvolvimento de Agentes de IA
Como mencionado acima, o Browser-Use não funciona como uma varinha mágica do Harry Potter. Em vez disso, combina entrada visual com controle de IA para automatizar navegadores usando Playwright.
O Browser-Use inevitavelmente vem com algumas desvantagens, mas essas limitações não se origiam do próprio framework de automação. Em vez disso, elas surgem dos navegadores que controla. Ferramentas como Playwright iniciam navegadores com configurações e ferramentas específicas para automação, que também podem ser expostas a sistemas de detecção anti-bot.
Como resultado, seu agente de IA pode frequentemente encontrar desafios CAPTCHA ou páginas bloqueadas como "Desculpe, algo deu errado do nosso lado." Para desbloquear o verdadeiro potencial do Browser-Use, são necessárias ajustes cuidadosos. O objetivo final é evitar a ativação de sistemas anti-bot para garantir que sua automação de IA funcione sem problemas.
Após testes extensivos, podemos afirmar com confiança: Scraping Browser é a solução mais eficaz.
O Que É o Scrapeless Scraping Browser?
Scraping Browser é uma ferramenta de automação de navegador baseada em nuvem e sem servidor projetada para resolver três problemas centrais na extração dinâmica de dados da web: gargalos de alta concorrência, evasão anti-bot e controle de custos.
-
Ele fornece consistentemente um ambiente de navegador headless anti-bloqueio de alta concorrência para ajudar os desenvolvedores a extrair facilmente conteúdo dinâmico.
-
Ele vem com um pool de IPs proxy global e tecnologia de fingerprinting, capaz de resolver automaticamente CAPTCHA e contornar mecanismos de bloqueio.
Desenvolvido especificamente para desenvolvedores de IA, o Scrapeless Scraping Browser possui um núcleo Chromium profundamente personalizado e uma rede de proxy distribuída globalmente. Os usuários podem executar e gerenciar perfeitamente várias instâncias de navegador headless para construir aplicativos e agentes de IA que interagem com a web. Ele elimina as limitações da infraestrutura local e gargalos de desempenho, permitindo que você se concentre totalmente na construção de suas soluções.
Como o Browser-Use e o Scraping Browser Funcionam Juntos?
Quando combinados, os desenvolvedores podem usar o Browser-Use para orquestrar operações do navegador enquanto confiam no serviço em nuvem estável e nas poderosas capacidades anti-bloqueio do Scrapeless para adquirir dados da web de forma confiável.
O Browser-Use oferece APIs simples que permitem aos agentes de IA “entenderem” e interagirem com o conteúdo da web. Por exemplo, pode usar LLMs como OpenAI ou Anthropic para interpretar instruções de tarefa e completar ações, como buscas ou cliques em links no navegador via Playwright.
O Scraping Browser da Scrapeless complementa essa configuração abordando suas fraquezas. Ao lidar com grandes sites com medidas rigorosas anti-bot, seu suporte a proxies de alta concorrência, resolução de CAPTCHA e mecanismos de emulação de navegador garantem scraping estável.
Em resumo, o Browser-Use lida com inteligência e a orquestração de tarefas, enquanto a Scrapeless fornece uma base robusta de scraping, tornando as tarefas automatizadas do navegador mais eficientes e confiáveis.
Como Integrar um Scraping Browser com o Browser-Use?
Passo 1. Obtenha a Chave da API da Scrapeless
- Registre-se e faça login no Painel da Scrapeless.
- Navegue até "Configurações".
- Clique em "Gerenciamento da Chave da API".
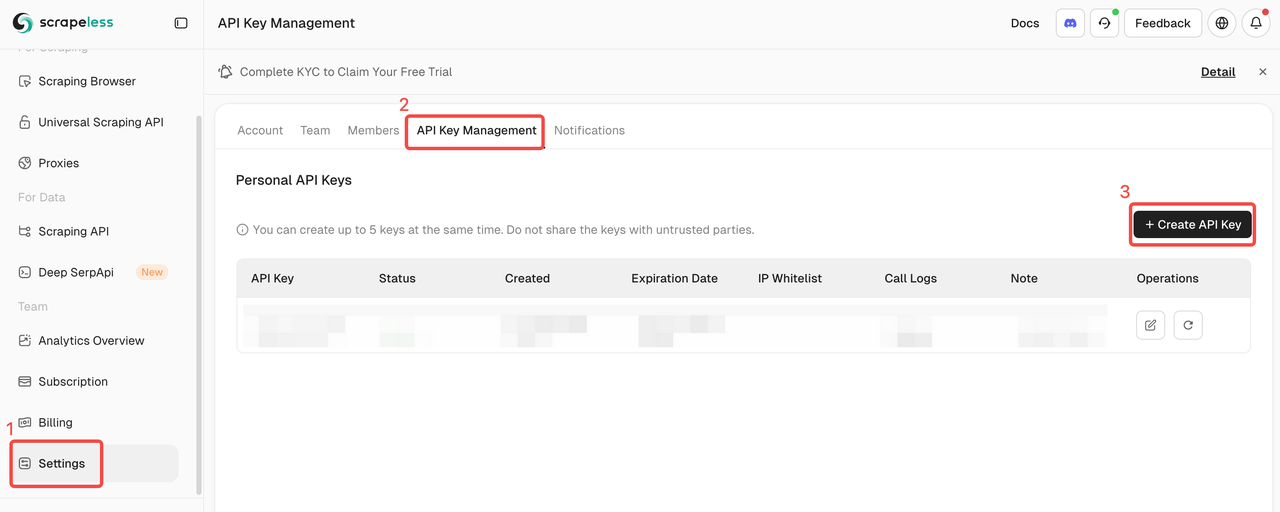
Então copie e defina as variáveis de ambiente SCRAPELESS_API_KEY em seu arquivo .env.
Para habilitar recursos de IA no Browser-Use, você precisa de uma chave de API válida de um provedor de IA externo. Neste exemplo, usaremos a OpenAI. Se você ainda não gerou uma chave de API, siga o guia oficial da OpenAI para criar uma.
As variáveis de ambiente OPENAI_API_KEY em seu arquivo .env também são necessárias.
Aviso: Os passos a seguir se concentram em como integrar a OpenAI, mas você pode adaptar o que se segue às suas necessidades, apenas certifique-se de usar qualquer outra ferramenta de IA suportada pelo Browser-Use.
.evn
OPENAI_API_KEY=sua-chave-api-openai
SCRAPELESS_API_KEY=sua-chave-api-scrapeless💡 Lembre-se de substituir a chave da API de exemplo pela sua chave de API real.
Em seguida, importe ChatOpenAI em seu programa: langchain_openaiagent.py
Plain Text
from langchain_openai import ChatOpenAIObserve que o Browser-Use depende do LangChain para gerenciar a integração de IA. Portanto, mesmo que você não tenha instalado explicitamente langchain_openai em seu projeto, ele já está disponível para uso.
gpt-4o configura a integração com a OpenAI com o seguinte modelo:
Plain Text
llm = ChatOpenAI(model="gpt-4o")Nenhuma configuração adicional é necessária. Isso ocorre porque o langchain_openai lê automaticamente a chave da API a partir da variável de ambiente OPENAI_API_KEY.
Para integração com outros modelos ou provedores de IA, consulte a documentação oficial Browser-Use.
Passo 2. Instale o Browser Use
Com o pip (Python pelo menos v.3.11):
Shell
pip install browser-usePara funcionalidades de memória (requer Python<3.13 devido à compatibilidade com PyTorch):
Shell
pip install "browser-use[memory]"Passo 3. Configure o Navegador e a Configuração do Agente
Aqui está como configurar o navegador e criar um agente de automação:
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
task = "Vá até o Google, pesquise por 'Scrapeless', clique no primeiro post e retorne ao título"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def setup_browser() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
browser = Browser(config)
return browser
async def setup_agent(browser: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # Ou escolha o modelo que você deseja usar
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=task,
llm=llm,
browser=browser,
)Passo 4. Crie a Função Principal
Aqui está a função principal que reúne tudo:
Python
async def main():
load_dotenv()
browser = await setup_browser()
agent = await setup_agent(browser)
result = await agent.run()
print(result)
await browser.close()
asyncio.run(main())Passo 5. Execute seu script
Execute seu script:
Shell
python run main.pyVocê deverá ver sua sessão Scrapeless iniciar no Painel da Scrapeless.
Além disso, a Scrapeless suporta replay de sessão, que habilita a visualização do programa. Antes de executar o programa, certifique-se de que a função de Gravação na Web esteja habilitada. Quando a sessão for concluída, você pode ver o registro diretamente no Painel para ajudá-lo a solucionar problemas rapidamente.
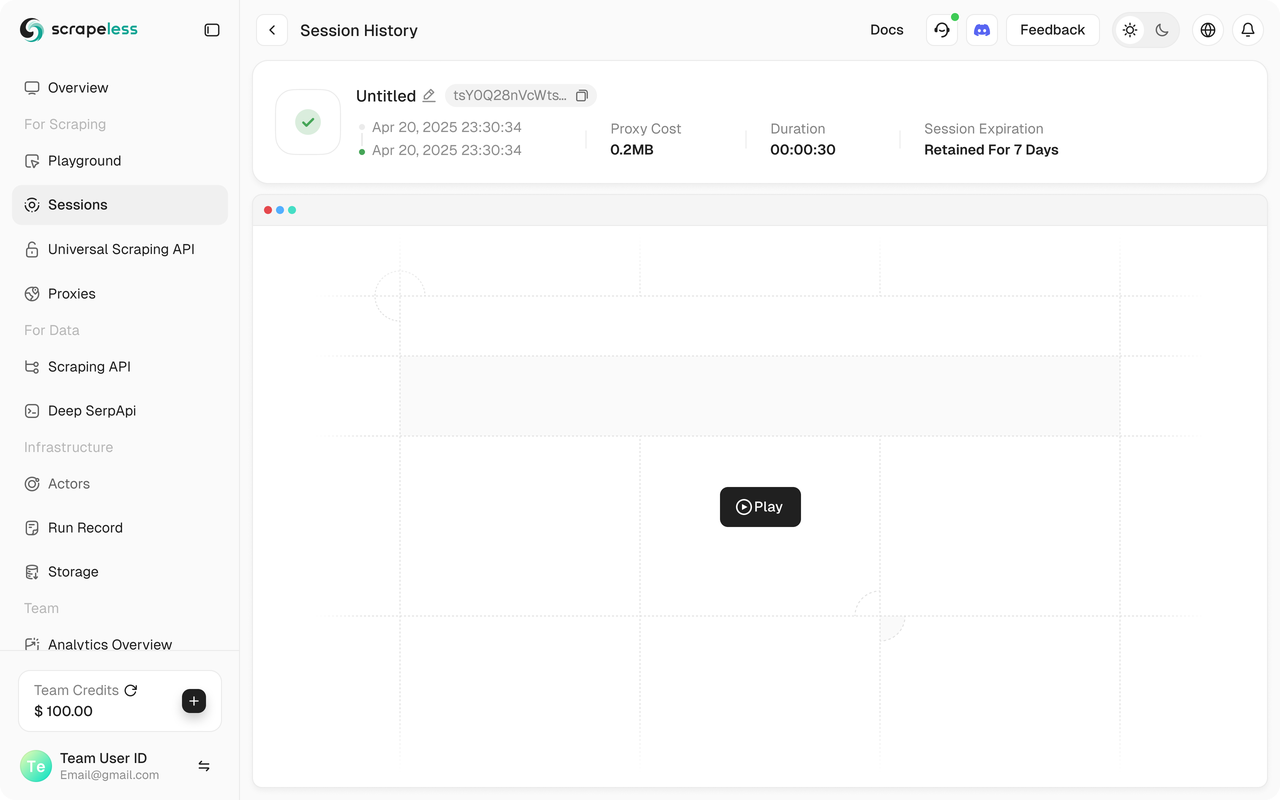
Código Completo
Python
from dotenv import load_dotenv
import os
import asyncio
from urllib.parse import urlencode
from langchain_openai import ChatOpenAI
from browser_use import Agent, Browser, BrowserConfig
from pydantic import SecretStr
tarefa = "Vá para o Google, pesquise por 'Scrapeless', clique no primeiro post e retorne ao título"
SCRAPELESS_API_KEY = os.environ.get("SCRAPELESS_API_KEY")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
async def configurar_navegador() -> Browser:
scrapeless_base_url = "wss://browser.scrapeless.com/browser"
query_params = {
"token": SCRAPELESS_API_KEY,
"session_ttl": 1800,
"proxy_country": "ANY"
}
browser_ws_endpoint = f"{scrapeless_base_url}?{urlencode(query_params)}"
config = BrowserConfig(cdp_url=browser_ws_endpoint)
navegador = Browser(config)
return navegador
async def configurar_agente(navegador: Browser) -> Agent:
llm = ChatOpenAI(
model="gpt-4o", # Ou escolha o modelo que deseja usar
api_key=SecretStr(OPENAI_API_KEY),
)
return Agent(
task=tarefa,
llm=llm,
browser=navegador,
)
async def principal():
load_dotenv()
navegador = await configurar_navegador()
agente = await configurar_agente(navegador)
resultado = await agente.run()
print(resultado)
await navegador.close()
asyncio.run(principal())💡 O uso do navegador atualmente suporta apenas Python.
💡 Você pode copiar o URL na sessão ao vivo para assistir ao progresso da sessão em tempo real, e também pode assistir a uma reprise da sessão na história da sessão.
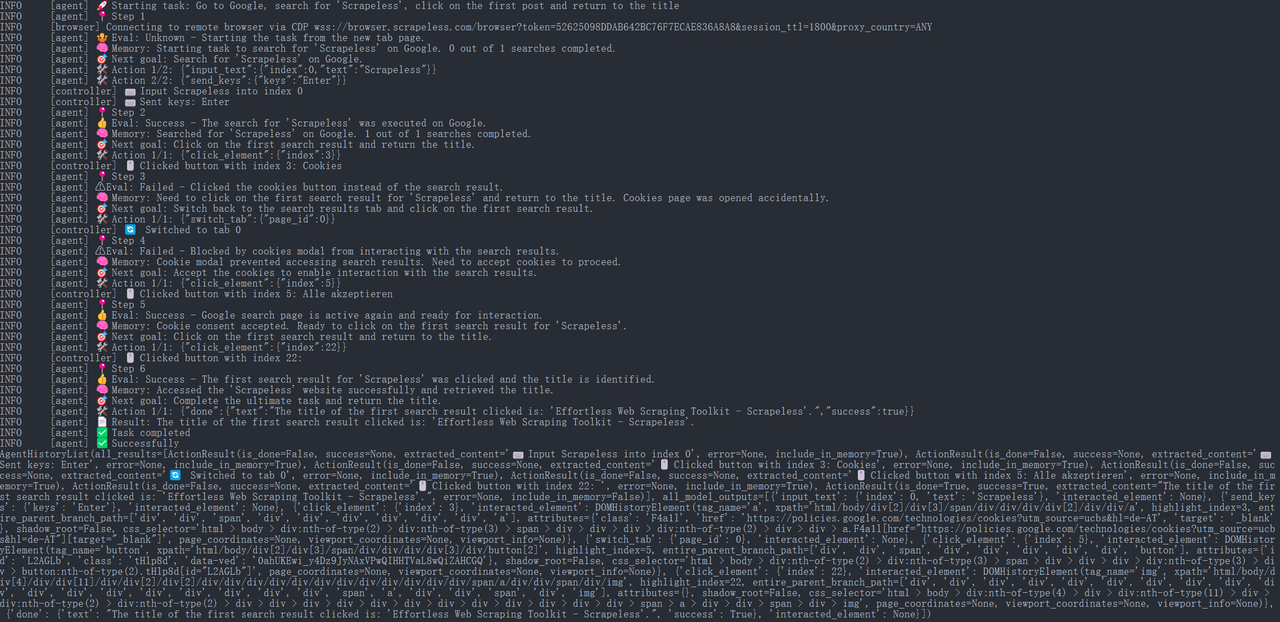
Etapa 6. Resultados da Execução
JavaScript
{
"done": {
"text": "O título do primeiro resultado da pesquisa clicada é: 'Effortless Web Scraping Toolkit - Scrapeless'.",
"success": True,
}
}
Então, o Agente de Uso do Navegador abrirá automaticamente o URL e imprimirá o título da página: “Scrapeless: Effortless Web Scraping Toolkit” (este é um exemplo do título na homepage oficial do Scrapeless).
Todo o processo de execução pode ser visto no console do Scrapeless na página "Dashboard" → "Sessão" → "Histórico da Sessão", onde você verá os detalhes da sessão executada recentemente.
Etapa 7. Exportando os Resultados
Para fins de compartilhamento em equipe e arquivamento, podemos salvar as informações extraídas em um arquivo JSON ou CSV. Por exemplo, o seguinte trecho de código mostra como escrever os resultados dos títulos em um arquivo:
Python
import json
from pathlib import Path
def salvar_como_json(obj, filename):
path = Path(filename)
path.parent.mkdir(parents=True, exist_ok=True)
with path.open('w', encoding='utf-8') as f:
json.dump(obj, f, ensure_ascii=False, indent=4)
async def principal():
load_dotenv()
navegador = await configurar_navegador()
agente = await configurar_agente(navegador)
resultado = await agente.run()
print(resultado)
salvar_como_json(resultado.model_dump(), "relatorio_atualizacao_scrapeless.json")
await navegador.close()
asyncio.run(principal())O código acima demonstra como abrir um arquivo e escrever conteúdo em formato JSON, incluindo as palavras-chave de pesquisa, links e títulos das páginas. O arquivo gerado relatorio_atualizacao_scrapeless.json pode ser compartilhado internamente por meio de uma base de conhecimento da empresa ou plataforma de colaboração, facilitando a visualização dos resultados da raspagem por parte dos membros da equipe. Para formato de texto simples, você pode apenas mudar a extensão para .txt e usar métodos básicos de saída de texto.
Conclusão
Usando o serviço Navegador de Raspagem da Scrapeless em combinação com o agente de IA de Uso do Navegador, podemos facilmente construir um sistema automatizado para recuperação de informações e relatórios.
- O Scrapeless fornece uma solução de raspagem baseada em nuvem estável e eficiente que pode lidar com mecanismos complexos de anti-raspagem.
- O Uso do Navegador permite que o agente de IA controle o navegador de forma inteligente para realizar tarefas como pesquisa, clique e extração.
Essa integração permite que os desenvolvedores descarreguem tarefas tediosas de coleta de dados da web em agentes automatizados, melhorando significativamente a eficiência da pesquisa enquanto garante precisão e resultados em tempo real.
O Navegador de Raspagem da Scrapeless ajuda a IA a evitar blocos de rede enquanto recupera dados de pesquisa em tempo real e garante estabilidade operacional. Combinado com o motor de estratégia flexível do Uso do Navegador, conseguimos construir uma ferramenta de pesquisa de automação de IA mais poderosa que oferece forte suporte para a tomada de decisões empresariais inteligentes. Este conjunto de ferramentas permite que agentes de IA "consultem" conteúdo da web como se estivessem interagindo com um banco de dados, reduzindo bastante o custo de monitoramento manual de concorrentes e melhorando a eficiência das equipes de P&D e marketing.
Na Scorretless, acessamos apenas dados disponíveis ao público, enquanto cumprem estritamente as leis, regulamentos e políticas de privacidade do site aplicáveis. O conteúdo deste blog é apenas para fins de demonstração e não envolve atividades ilegais ou infratoras. Não temos garantias e negamos toda a responsabilidade pelo uso de informações deste blog ou links de terceiros. Antes de se envolver em qualquer atividade de raspagem, consulte seu consultor jurídico e revise os termos de serviço do site de destino ou obtenha as permissões necessárias.


